
基于知识图谱的电信欺诈通联特征挖掘方法
2019-11-12 05:02凡友荣孔华锋彭如香姜国庆
计算机应用与软件 2019年11期
凡友荣 杨 涛 孔华锋 彭如香 姜国庆
1(公安部第三研究所 上海 201204)2(武汉商学院 湖北 武汉 430056)
0 引 言
大数据及其相关技术在案件侦破、社会治理等公安业务领域发挥着巨大的作用,能够辅助公安各级侦查人员进行情报收集及线索发现[1]。目前电信诈骗案件中积累的通话数据(Call Detail Records, CDR)的数据量庞大,能反映出人们的通话习惯、社会关系、社会属性等重要信息,然而这些数据的应用仍停留在查询层面,数据之间的关联还未被充分挖掘和使用[2]。
Google公司于2012年5月重金收购Metaweb公司,并向外界正式发布其知识图谱,自此,知识图谱正式走入公众视野[3]。知识图谱是结构化的语义知识库,描述了物理世界中的概念及其相互关系,其基本组成单位是“实体-关系-实体”三元组,以及实体与其相关属性的“属性-值”,实体间通过关系相互联结,构成网状的知识结构[4]。知识图谱能将数据之间的关联关系构建起来,从而更利于深层知识的挖掘,提高数据的利用率[5]。
本文从仿真通话数据的角度出发,使用知识图谱、分布式计算等大数据技术构建知识挖掘模型,为电信诈骗案件的数据利用及线索挖掘提供技术支持。首先基于通话数据构建知识图谱,然后基于图算法和分布式图计算引擎,构建通联特征挖掘模型,挖掘出通联网络中的核心人物、联系链路等隐藏线索,并且提取出通话记录中的9个关键特征,建立支持分布式计算的混合高斯模型,挖掘出其中的5类社会关系,以及涉案人员之间的通联特点,从多个维度为电信欺诈案件的线索挖掘提供技术支持。
1 技术路线
本文的技术路线如图1所示。
本文的研究内容以主流的大数据技术为基础,使用Python语言对各类存储格式的数据进行预处理,并存储在基于Hadoop的Hive数据仓库中,为知识图谱的构建提供数据基础;将处理完成的图结构数据存储在基于JanusGraph的图数据库中,完成知识图谱的构建;结合Gremlin和GraphX可进行实时的图遍历及全局的图数据分析,构建基于通联特征挖掘模型。综上,本文的技术架构将浅层知识发现和深层知识挖掘相结合,从而实现电信欺诈案件的线索探查和挖掘。
2 知识图谱构建
本文采用自底向上的方式进行知识图谱的构建。从多源异构的数据中抽取实体信息、链接和融合实体,推理补全属性,识别语义并建立关系,最终将知识存储于知识图谱数据库中。此过程是一个迭代更新的过程,每一轮更新包括信息抽取、知识融合、知识加工这三个步骤[3],如图2所示。
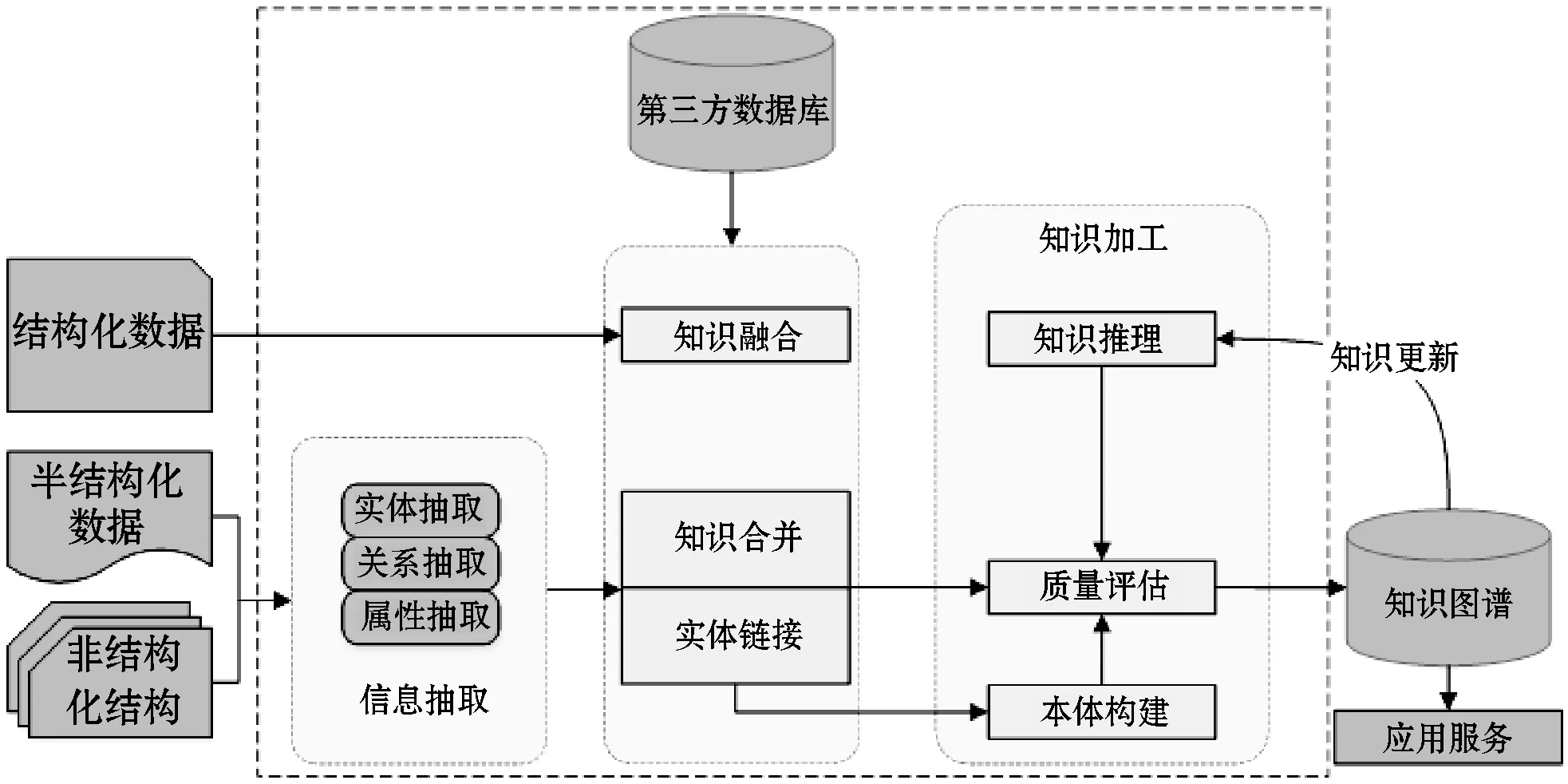
图2 知识图谱构建步骤
3 通联特征挖掘模型
在知识图谱的基础上,通过图的深层遍历及图算法进行信息挖掘,能够识别特定人员相互之间的通话交互模式。本文基于最短路径算法(Shortest Path algorithm)、PageRank算法、Centrality算法、混合高斯模型(Gaussian mixture model,GMM)构建通联特征挖掘模型,模型设计如图3所示。

图3 通联特征挖掘模型
3.1 最短路径算法
最短路径算法计算一对点之间的最短路径,此路径在连通这对点的所有路径中边数最少,本文实验中中使用的是经典的Dijkstra算法[6]。在基于通话数据的知识图谱中,通过计算两个手机号之间的最短路径,可以挖掘其相互联系的所有链路。例如,两名涉及同一案件的欺诈人员可能没有直接联系,但通过最短路径计算,可发现其隐藏的联系链路,并挖掘出重要的中间联系人,提供关键的案件线索。
3.2 Betweenness Centrality算法
Betweenness Centrality算法基于图中的所有最短路径,计算经过每个点的最短路径数量,当某点的Betweenness Centrality值很高,则说明很多点之间的最短路径都经过此点。因此Betweenness Centrality值的大小反映了每个点在图中的必要性,此算法可用于发现社交圈中的必要人物。计算公式如下[7]:
(1)
式中:CB(pi)为点pi的Betweenness Centrality值,gjk为连接点pj和点pk的所有最短路径的总数量,gjk(pi)是这些最短路径中经过点pi的数量。
3.3 PageRank算法
PageRank算法是著名的Google网页排名算法,其关键假设是网页越重要,则指向此网页的链接越多[8]。在本文中,PageRank算法用来计算图中每个点的重要程度,从而挖掘通联网络中的核心人物,其计算公式如下:
(2)
式中:页面T1至T2指向页面A,PR(A)为页面A的PageRank值。参数d为阻尼因子,取值区间为[0,1],在本文实验中取值为0.85。C(A)为页面A指向的页面数量。
3.4 混合高斯模型
混合高斯模型(GMM)是用高斯概率密度函数(正态分布曲线)精确地量化事物,将一个事物分解为若干基于高斯概率密度函数形成的模型[9]。该算法能高效地得到聚类结果。本文在Spark中实现该模型,主要代码如下:
#import data
data=spark.sql(′select * from tablename)
#generate vectors of features
vector=data.rdd.map(lambda
line:(line[0],line[1],Vectors.dense(…)))
dataFrame=
spark.createDataFrame(vector,[″main_phone″,″contact_phone″, ″features″])
#normalize the data
normalizer=Normalizer(inputCol=″features″,
outputCol=″normFeatures″, p=1.0)
l1NormData=normalizer.transform(dataFrame)
#running GMM model
gmm=GaussianMixture(featuresCol=″normFeatures″)
model=gmm.fit(l1NormData)
#generate the clustering result
transformed=model.transform(l1NormData).select(″main_phone″,
″contact_phone″, ″features″,″prediction″)
4 实验设置与分析
4.1 实验数据
本文使用仿真的通话数据和电信诈骗案件数据。通话数据格式为CSV,电信诈骗案件数据为文本格式,首先根据电信诈骗案件数据在通话数据中进行标注,即标注各手机号是否涉案。将数据进行预处理后的数据描述如表1所示。

表1 数据集成后的数据示例
本实验使用的测试数据量如表2所示。
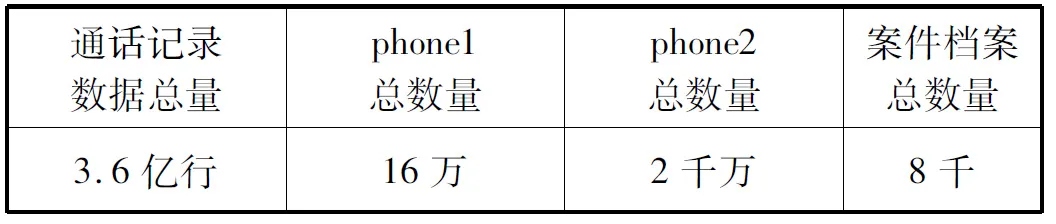
表2 测试数据概览
4.2 实验分析
4.2.1知识图谱构建
以表1所示数据为基础,使用图4所示的步骤进行知识图谱的构建。将源数据经过实体抽取、关系抽取、知识融合,得到点数据集和边数据集,其中:案件档案的点数据示例如表3所示;CDR的点数据示例如表4所示;案件档案的边数据示例如表5所示;CDR的边数据示例如表6所示。将点边数据导入至Janusgraph中形成知识图谱。
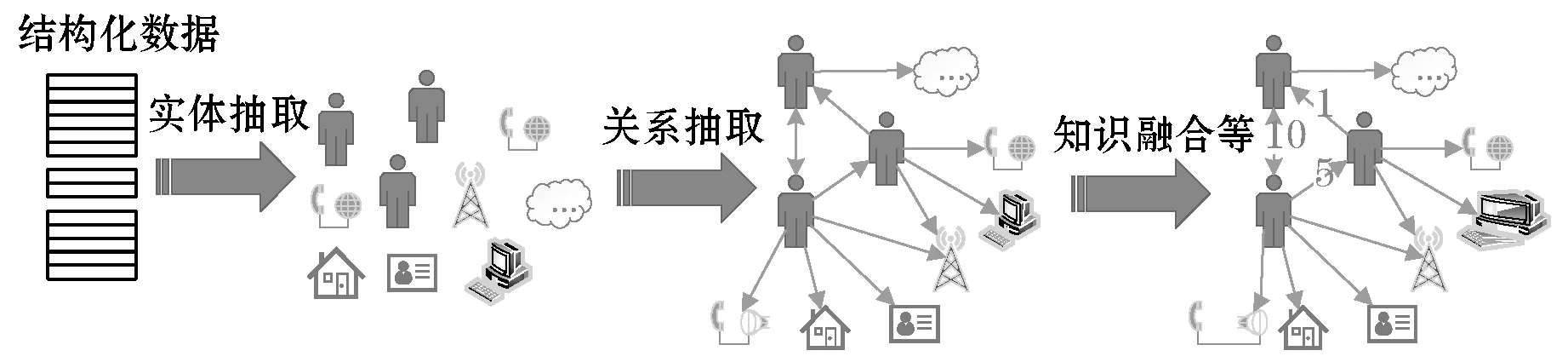
图4 通联数据知识图谱构建

fileId:IDfile name:LABELB310∗∗∗∗∗∗5fraudfile
表4 CDR点数据示例

表5 案件档案边数据示例

表6 CDR边数据示例
如图5所示,知识图谱中包含案件、人员两类实体的网络结构,包含案件与人员的关系,人与人之间的通话关系。基于该知识图谱,可进行多维度的应用分析,例如联系链路的拓展、团伙发现、关键人员发现等,从而为电信欺诈案件提供浅层和深层的破案线索。
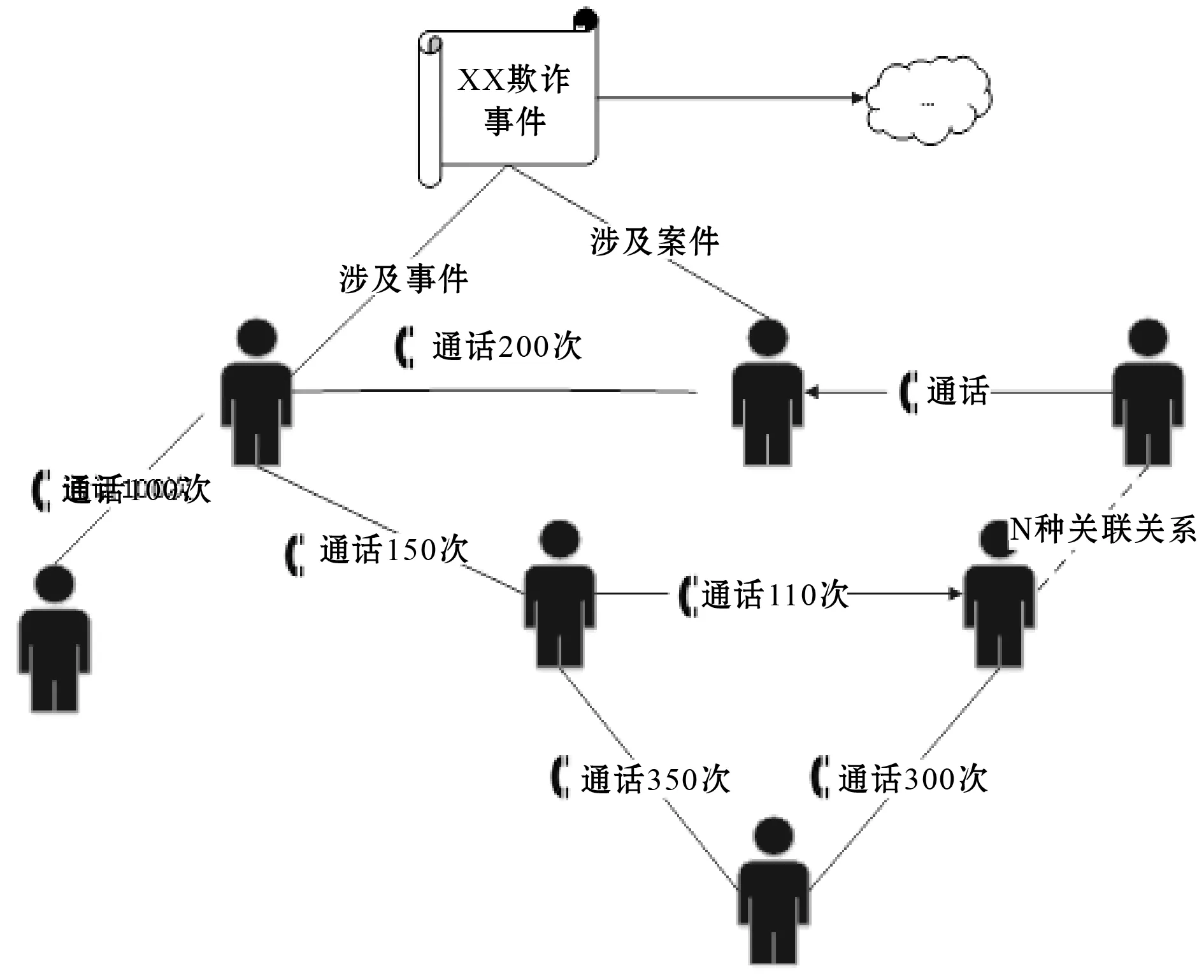
图5 基于通联数据的电信欺诈案知识图谱
4.2.2通联特征挖掘
1) 联系链路发现。通过以下代码调用最短路径算法,计算并返回两个欺诈人员之间的联系链路。
MATCH Paths=allShortestPaths((suspect1: Person
{ Phone:″1312***″})-
[:contacts*..]-(suspect2: Person
{ Phone:″1305***″}) )
RETURN Paths;
上述代码的返回结果如图6所示,涉及同一案件的人员“suspect1”和“suspect2”之间的联系链路只包含图中的5个实体,且实体之间的联系较为紧密,这些中间联系人可能是隐藏的作案团伙,能为案件侦查提供重要线索。

图6 最短算法的实验结果
2) 必要人物发现。通过以下代码调用Betweenness Centrality算法,计算并返回子图中Betweenness Centrality值最高的点。
MATCH(suspect2:phone {name:″15317***″})
CALL apoc.path.subgraphAll(suspect2,
{maxLevel:5}) YIELD nodes
WITH collect(nodes) AS nodes
CALL apoc.algo.betweenness([′contacts′], nodes, ′BOTH′) YIELD nodes, score
RETURN nodes, score
ORDER BY score DESC
计算欺诈人员suspect1和suspect2的通联子图中每个节点的Betweenness Centrality值,按值的高低排序可发现其中的关键人员。如图7所示, 点a和点b为该子图中Betweenness Centrality值最高的两个点,其在两名欺诈人员的联系链路中起着桥梁作用,每条联系路径都必须经过点a和点b,因此这两个点为该子图的必要节点,即这两名人员是该通联网络中不可或缺的关键人物。

图7 Betweenness Centrality算法的实验结果
3) 核心人物发现。在团伙欺诈案中,需查找该团伙的核心人员。在一个团伙的联通子图中计算每个节点的PageRank值,该值的大小代表指向该点的边的多少,反映了该点在子图中是否具有核心地位。调用代码如下:
MATCH(n:phone) WHERE n.name=″15317***″
CALL apoc.path.subgraphAll(n, {maxLevel:2}) YIELD nodes
CALL apoc.algo.pageRank(nodes) YIELD node, score
RETURN node.name AS name, score
ORDER BY score DESC
LIMIT 10;
计算结果如表7所示,可视化结果如图8所示。PageRank值最高的点a、b、c在图中处于核心位置,说明这三人在此社交圈中为核心人物,是抓获该团伙的关键线索。

表7 PageRank计算结果示例
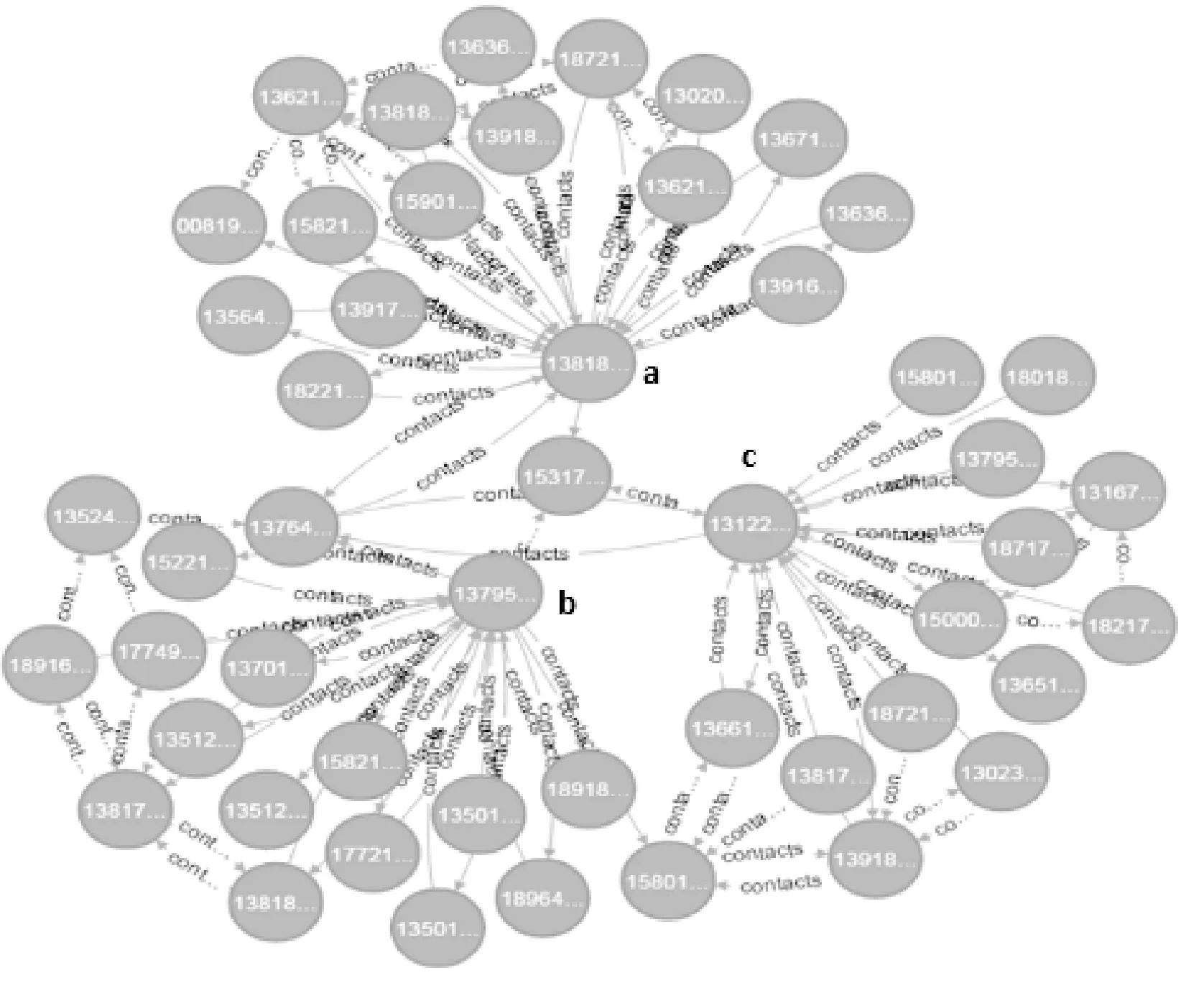
图8 PageRank算法可视化结果
4) 社会关系识别。欺诈案件中的人员社会关系是重要线索,本实验从通联数据中提取特征并构建聚类模型,从通话模式聚类的角度来识别不同的社会关系。
(1) 特征提取。不同的社会关系具有不同的通话特征,例如大部分工作同事之间的通话行为发生在工作时间,并且保持联系的时间较长,而家庭关系中大多数的通话发生在业余时间,并且通话的频率相对较高。本文从通话记录中提取具有代表性的通话特征。5种典型的通话模式如图9所示,代表了5种社会关系。

图9 五种典型通话模式
图9中包含5种通话模式在12天中的通话记录,每一天被均分为48个时间片段,每个片段为30分钟。其中:标注a的数据为涉及同一案件的两个人之间的通话记录,其通话行为仅发生在凌晨0点至6点之间,且通话频率较高;b为两个同事之间的通话记录,通话多发生在工作时间,且通话频率较高;c为暂时的工作关系,通话发生在工作时间,且仅发生一次;d为两个朋友之间的通话记录,通话发生在工作时间或者休息时间,通话频率相对较低;e为一对情侣的通话记录,通话均发生在休息时间,且通话频率很高。从这5个典型的通话模式中可以发现,当通话双方均涉及案件,其通话模式区别于其他社会关系的明显特征为通话多发生在凌晨。
将一天划分为3个时间段,凌晨时段(0点至6点)、工作时间(7点至18点)、休息时间(19点至23点)。通过计算这三个时段的通话时间占比,可以从通话时间段的角度分析不同社会关系的通话特点。
基于上述计算及分析过程,从通话数据中提取出9个特征,根据这些特征构建能区分不同社会关系的聚类模型。这9个特征的具体描述如表8所示。
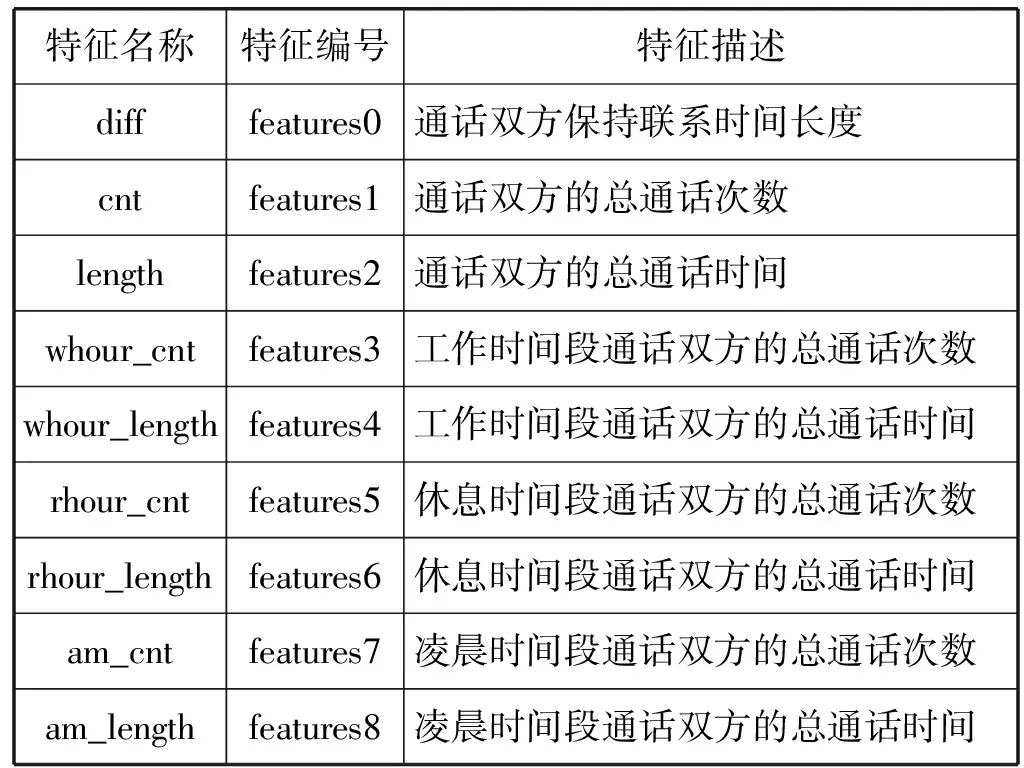
表8 通话记录中的九大特征
(2) 聚类分析。将特征数据导入到GMM模型中进行计算。为提高计算效率,本模型在基于Hadoop 2.7.3和Spark 2.0.1的分布式环境中运行。
聚类结果如图10所示,从9个维度来显示聚类结果,从而能体现上述9个特征对聚类产生的影响,所有通话数据被聚类为5个簇。

图10 聚类结果的可视化
对每簇的特征进行分析,总结如下:
0簇:通话双方保持联系时间长,通话次数最多,通话时长较长,并且通话行为常发生在凌晨。
1簇:通话双方保持联系时间较短,通话次数较少,通话时长很短,通话行为多发生在凌晨。
2簇:通话双方保持联系时间较长,通话次数较少,通话时长相对较短,通话行为多发生在休息时间。
3簇:通话双方保持联系时间较长,通话次数较多,通话时长相对较长,通话行为多发生在工作时间。
4簇:通话双方保持联系时间最短,通话次数最少,通话时长最短,通话行为多发生在休息时间。
诈骗团伙在聚类中分布在0簇和1簇,说明这两簇中的通话双方是一种特殊的社会关系;2簇的通话双方是家人关系或者关系紧密的朋友关系;3簇的通话双方是工作同事关系;4簇代表的是一种短暂关系,例如推销电话、泛泛之交等。因此,此聚类分析方法能辅助分析人员从通话模式的角度发现欺诈人员,并为社会关系的识别提供技术支持。
综上,本实验在通话数据的知识图谱之上,从联系链路发现、必要人物发现、核心人物发现、社会关系识别这4个维度进行分析挖掘,为电信欺诈人员和团伙的发现提供了重要线索。
5 结 语
结合仿真的通话数据和电信欺诈案件数据,本文使用知识图谱、分布式计算等大数据技术构建通联特征挖掘模型,挖掘出了通联网络中的联系链路、必要人物、核心人物等隐藏线索;提取出了通话记录中的9个关键特征,聚类得到了5类典型的社会关系,并且发现涉案人员之间的通话模式具有一定的特殊性,即通话次数多且多发生在凌晨、通话时间较长且保持联系的时间较长。
综上,本文提出的通联特征挖掘方法能辅助挖掘电信欺诈案的重要线索。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2021年5期)2021-11-27
少先队活动(2020年12期)2021-01-14
中华诗词(2018年5期)2018-11-22
新城乡(2018年6期)2018-07-09
金山(2017年11期)2017-12-06
领导科学论坛(2016年9期)2016-06-05
爆笑show(2015年3期)2015-05-08
通信产业报(2009年1期)2009-06-09
小学生·多元智能大王(2006年5期)2006-05-10
