
基于独立成分分析的fMRI数据分类
2019-11-12 05:01张芳芳
计算机应用与软件 2019年11期
张芳芳 李 楠
(太原理工大学信息与计算机学院 山西 太原 030024)
0 引 言
fMRI是神经影像学中一种重要的脑成像方法,通过磁振造影可以清晰探测神经元活动触发的血液动力改变,在此基础上得到包含大量信息脑成像数据,为人类解码大脑的工作机制提供了一种有效的方法[1]。大脑结构和功能的变化与大多疾病的产生有关[2]。这些微小的变化在病发初期通过肉眼是无法直接察觉到的。近年来人们通过在脑科学领域的积极探索,fMRI技术逐渐成为研究大脑运行机制的一种重要方法。模式识别作为机器学习中的一种重要技术目前已成为抑郁症、精神分裂症等精神或神经性疾病的诊断工具[2]。
fMRI是用于捕捉脑活动图像的神经成像技术,这些图像具有很高的空间分辨率,因此具有很高的维数。每一次扫描包括超过10万的体素,容易使分类器产生过拟合现象,影响分类器的泛化性能不利于对数据进行分类,所有被扫描的体素都不是针对每个刺激被激活的。因此,寻找与刺激有关的信息体素成为任何机器学习分析fMRI数据的先决条件[3]。特征提取方法是创建与刺激相关的激活体素样本的关键。文献[4]提出了使用多体素的模式进行fMRI数据分析,其使用互信息及偏最小平方回归行特征提取;文献[5]使用遗传算法进行特征提取,研究发现利用遗传算法进行特征选择比其他方法具有更好的一致性和可预测性;文献[6]采用t-test的特征选择方法、峰值所在时间点的特征提取方法和SVM分类算法对fMRI的思维数据进行分析。上述这些文献需要较大的计算量来进行特征提取,且特征的描述能力有限,选取过程较复杂且过分依赖于专家知识。文献[7]利用ICA能够获得具有更强的独立性和更好的空间对应性的受试者特异性成分。由于ICA算法不需要先验知识,适应环境变化能力强,噪声可以看作是独立成分,避免了去噪的问题,且ICA不需要假设源信号的数学模型,避免了模型假设过程中的误差,更能揭示脑功能数据所反映的人脑活动的本质,是分析脑成像数据非常有效的工具[8]。所以本文采用ICA算法提取激活体素创建样本特征。
机器学习算法可以通过不断的学习来模拟人类的学习行为,是人工智能领域很重要的一个分支,由于具有较高的识别性能和较强的鲁棒性现已被广泛应用于分析fMRI数据,探索大脑的运行机制。文献[9]比较了6种机器学习算法在fMRI数据上的分类性能,其中决策树的分类精确度为87%,K最近邻为86%,SVM为84%。然而使用单个分类器的方法解码特征间的信息识别效果不佳。Adaboost算法作为一种典型的机器学习算法实现了由弱分类器到强分类器的转换,文献[10]基于Adaboost框架提出了一种弹性网型正则化多核学习算法,获得分类精度较高的分类器;文献[11]利用Adaboost算法集成多个SVM分类器以此来判别被试正在观看的图像类别取得了较好的效果。
综上所述,利用ICA算法可以有效提取fMRI类别间信息,避免噪声干扰,Adaboost分类算法在一定程度上可以克服fMRI数据维数高容易过拟合的问题,所以本文利用ICA算法分别提取全脑和感兴趣区内的类别信息,再将得到的fMRI数据变换成低维空间时间序列,利用这些数据来训练Adaboost分类模型。
1 实验过程
实验采用事件相关数据集,首先对数据进行预处理,如果直接用预处理的数据创建样本,样本维数会非常高从而导致分类模型产生过拟合。本文采用ICA算法提取预处理后的数据感兴趣区类别间的有效信息,进而创建样本用于训练Adaboost分类模型。实验流程如图1所示。
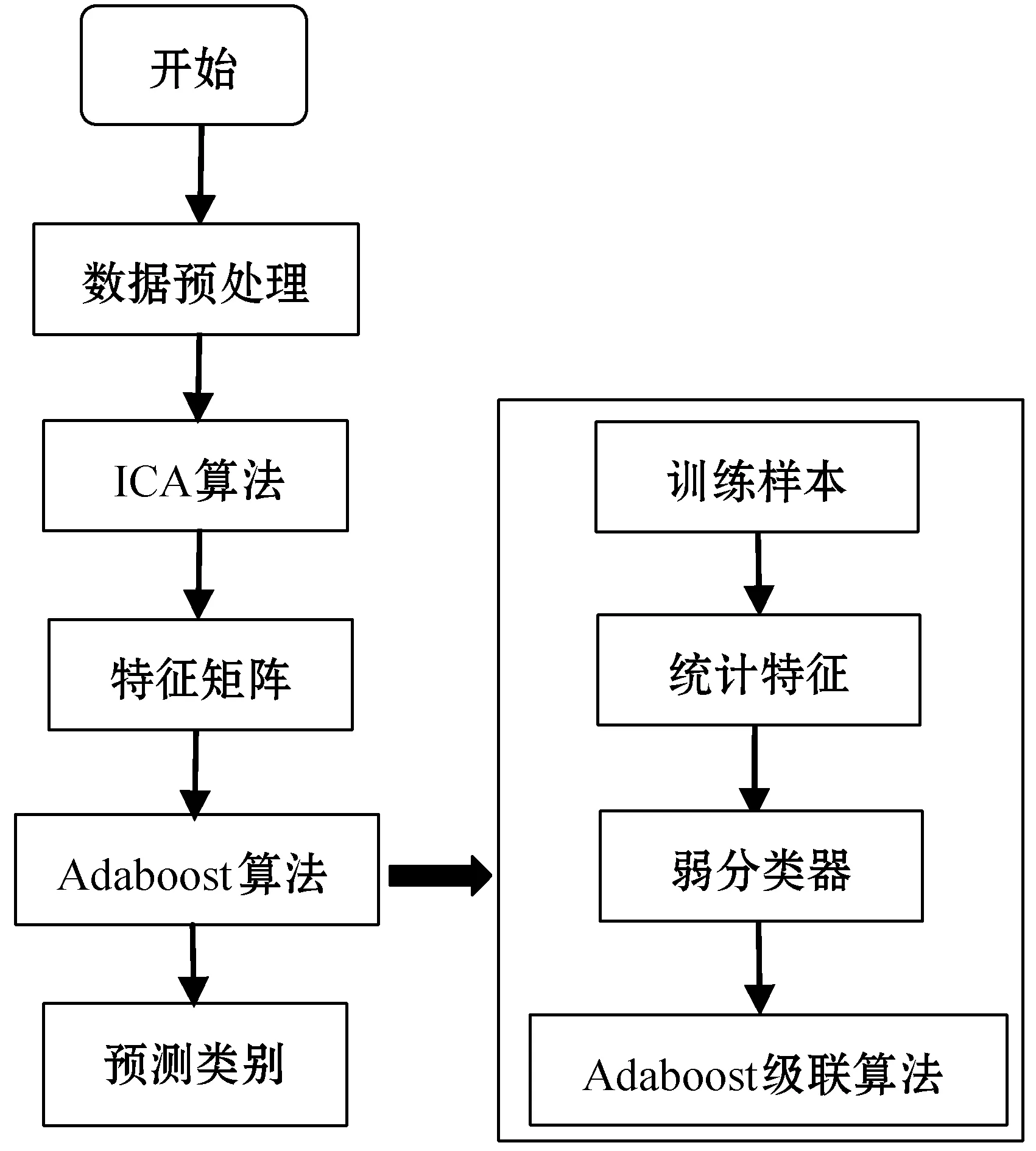
图1 算法流程
1.1 实验数据及预处理
本文采用haxby数据集,该数据集是haxby等在一次研究任务中采集到的数据(http://data.pymvpa.org/datasets/haxby2001),是fMRI实验设计中最常用的数据集之一。该实验数据集由6个被试构成,实验过程为被试提供8种不同类别的图片刺激,让每位被试分别观看这8类图片,每类图片中包含有48幅图像。采用多组块试验设计:先保持12 s的静息状态,接着为8任务刺激块,每个刺激块持续24 s,在各刺激块间有12 s的静息状态,每个刺激块有12个样本,每个样本中包含从4个不同角度拍摄的图片,每个图片的刺激时间为500 ms,刺激间隔为1 500 ms。由于数据集中第5个被试的第9个样本数据损坏,故研究时舍弃该组数据[12]。fMRI数据集经过预处理,改善了时间序列数据的空间对齐性,并且抑制了时间序列数据的噪声,包括运动校正、线性去趋势、对数据进行标准化[13]。
1.2 独立成分分析
ICA按照统计独立的原则将观测数据分解为若干独立分量,利用其独立成分作为样本数据。通过线性变换将体素信息分解成统计独立的信号的线性组合其原理如图2所示。假设fMRI数据为x(t),独立分量s(t)通过混合构成混合系统A,若要使解混矩阵B得到的y(t)接近s(t),矩阵B必须满足无限接近矩阵A的逆这一条件。
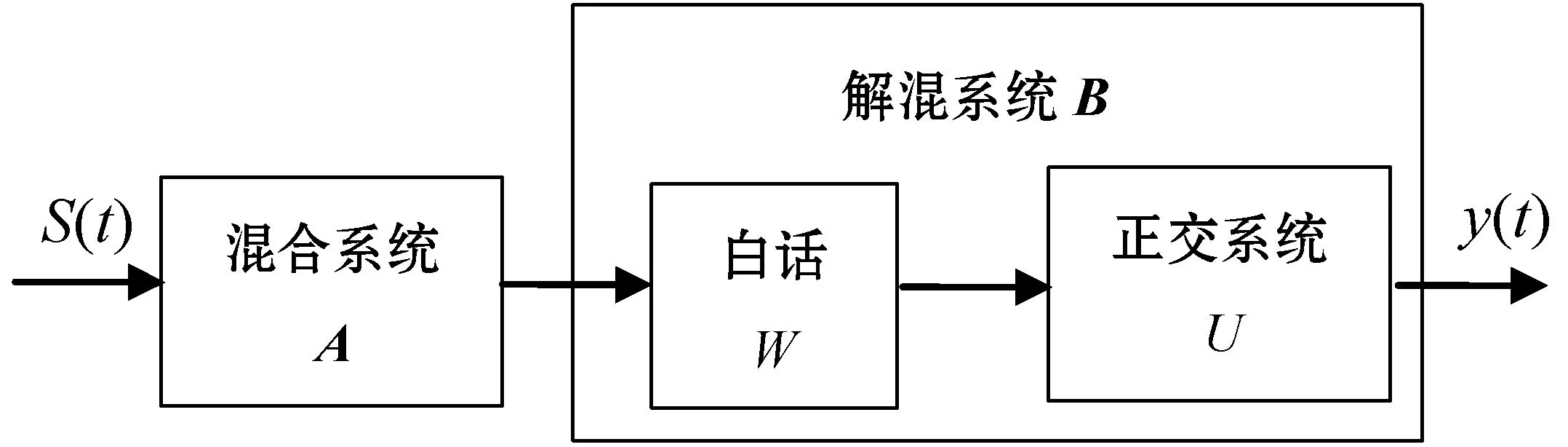
图2 ICA数据处理过程
ICA能够提取脑组织边缘变化的特征信息。运用相关的ICA算法将观测数据矩阵分解为一组统计上两两独立的成分,其标准的数学模型形式为:
X=A×S
(1)
式中:X为N×M的fMRI数据矩阵,N代表被试样本样本数,M表示被试观察图片时采集到的体素个数,观察的图像类别映射为X中的行向量,其中的N个样本分别表示为X1,X2,…,XN;矩阵A为混合系数矩阵,维数为N×L,L表示分解后独立分量的数目,矩阵A的行向量中包含每个对象所有独立分量的组合信息,而A每一列元素则包含单个独立成分对所有对象的组合信息;矩阵S是L×M的源信号矩阵,Si(i=1,2,…,L)分别代表各个独立成分,由于包含每类图片的体素信息,也称之为图像基。fMRI影像的ICA模型如图3所示。
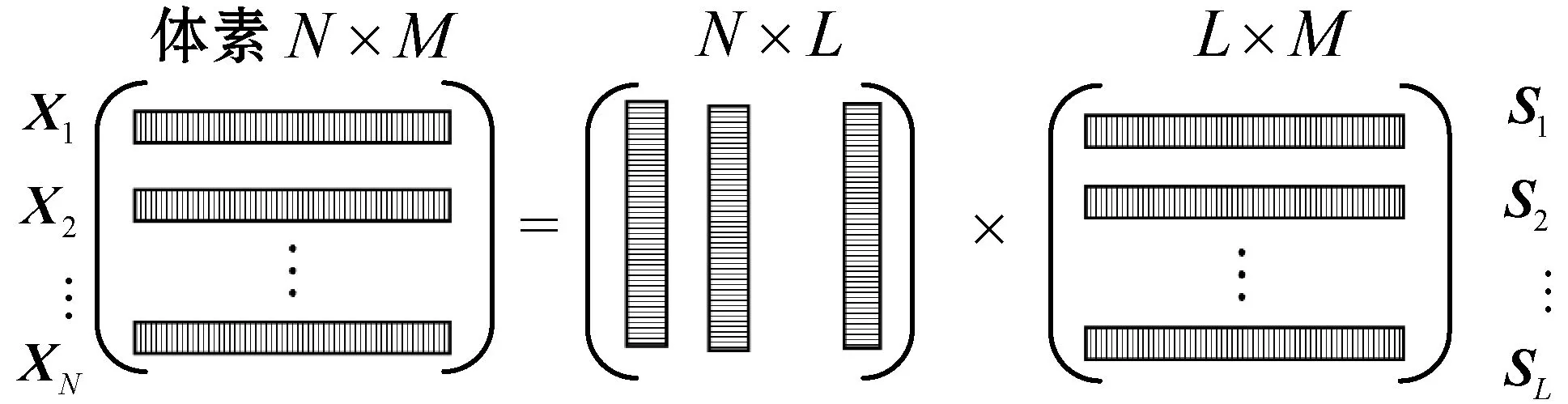
图3 ICA算法
ICA算法流程如下:
(1) 将数据中心化使均值为零;
(2) 随机生成分离矩阵B和初始化yi,设置学习率μ及收敛准则;
(3) 计算y=Bz;
(4) 若非线性函数没有事先确定:
yi=(1-μy)yi+μy[E(-tanh(yi)yi+(1-tanh(yi)2))]
如果yi>0,取gi(yi)=-2tanh(yi),否则
gi(yi)=tanh(yi)-yi;
(5) 更新分离矩阵B←B+Y[1+g(y)yT]B;
(6) 若未收敛,返回步骤3。
利用ICA算法提取出与视觉认知相关的腹侧颞叶皮层区域的相关三维脑成像(x,y,z)体素如图4所示,其中一个被试在观看8幅图片过程中提取的体素对应的fMRI数据时间序列如图5所示,通过ICA算法提取的体素个数X=[22 422],将其输入Adaboost分类模型。
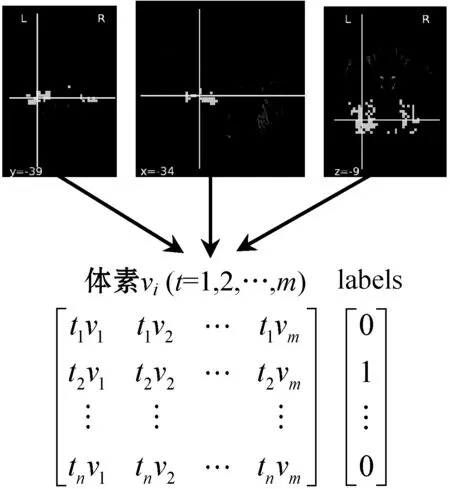
图4 腹侧颞叶皮层三维脑成像
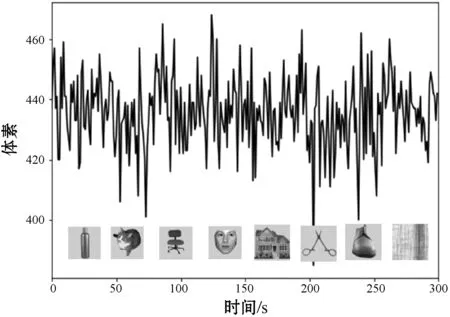
图5 时间序列
1.3 Adaboost分类算法
Adaboost分类器是利用相同的样本集训练不同的弱分类器,通过集成弱分类器构造一个强分类器。具体实现步骤如下:
步骤1给定训练样本集{(x1,y1),(x2,y2),…(xm,ym)},其中m为样本数,xi为训练样本,yi为样本标签。
步骤2初始化样本xi的权重。
步骤3选取的弱分类器的个数为T,实验选取T=20。
(1) 权重归一化:
(2)
(2) 训练每个弱分类器cf,计算该特征的弱分类器的加权错误率:
(3)
将错误率最小的εf弱分类器cf加入到强分类器中。
(3) 更新样本权重:
(4)
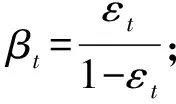
(4) 强分类器为:
(5)
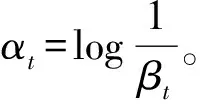
2 实验结果及分析
实验选取与视觉信息相关的感兴趣区(腹侧颞叶皮层)与全脑体素分别训练Adaboost分类器,特征提取的方法影响分类器的识别性能,PCA算法常用于去除数据中的冗余特征,降低数据维度,实验对比了PCA特征选择方法来验证本文方法的有效性。因为haxby数据集包含的fMRI数据样本数有限,本文采用留一法进行交叉验证来评估Adaboost模型的分类性能,实验结果如表1所示。
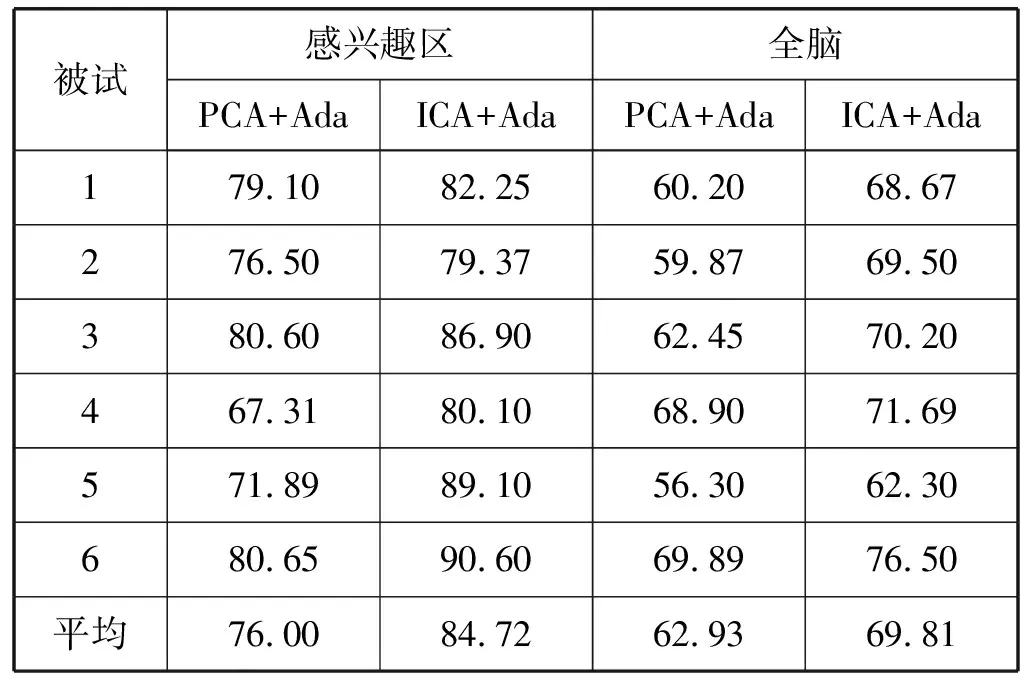
表1 不同特征选择方法的比较 %
由表1可知,在全脑采用PCA算法与Adaboost算法相结合的方法得到的平均分类准确率为62.93%;采用ICA算法与Adaboost算法相结合的方法得到的平均分类准确率为69.81%。本文方法分类效果较好,其平均分类准确率相比PCA+Adaboost算法提高了6.88%,在与视觉信息相关的感兴趣区采用PCA算法与Adaboost算法相结合的方法得到的平均分类准确率为76.00%,采用ICA算法与Adaboost算法相结合的方法得到的平均分类准确率为84.72%,其平均分类准确率相比PCA+Adaboost算法提高了8.72%。由表1可知,无论是以全脑还是以感兴趣区体素作为特征,采用本文方法更能有效解码视觉信息,选择全脑体素进行实验,其中包含的体素的平均活跃程度不同,有的脑区体素处于正激活状态,有的处于负激活状态,处于负激活状态的体素就会对携带有用信息的正激活体素产生干扰,从而影响分类性能。选择感兴趣区进行实验可进一步减小冗余信息的干扰,通过ICA算法能将体素之间的相互作用和空间分布关系考虑在内,有助于分析fMRI数据。
分析fMRI实验数据有单一分类器和集成分类器两种方法,由于fMRI 实验中的样本数少但特征维度高,会使分类器产生过拟合,影响分类器的泛化性能,导致分类器对大脑认知状态的变化不敏感。为了验证Adaboost分类算法的有效性,本文选取ICA算法提取的感兴趣区体素特征训练,与SVM、Bagging、Boosting三种分类器进行实验对比。图6显示了Adaboost分类方法与其他三种方法在haxby数据集上的分类识别率。
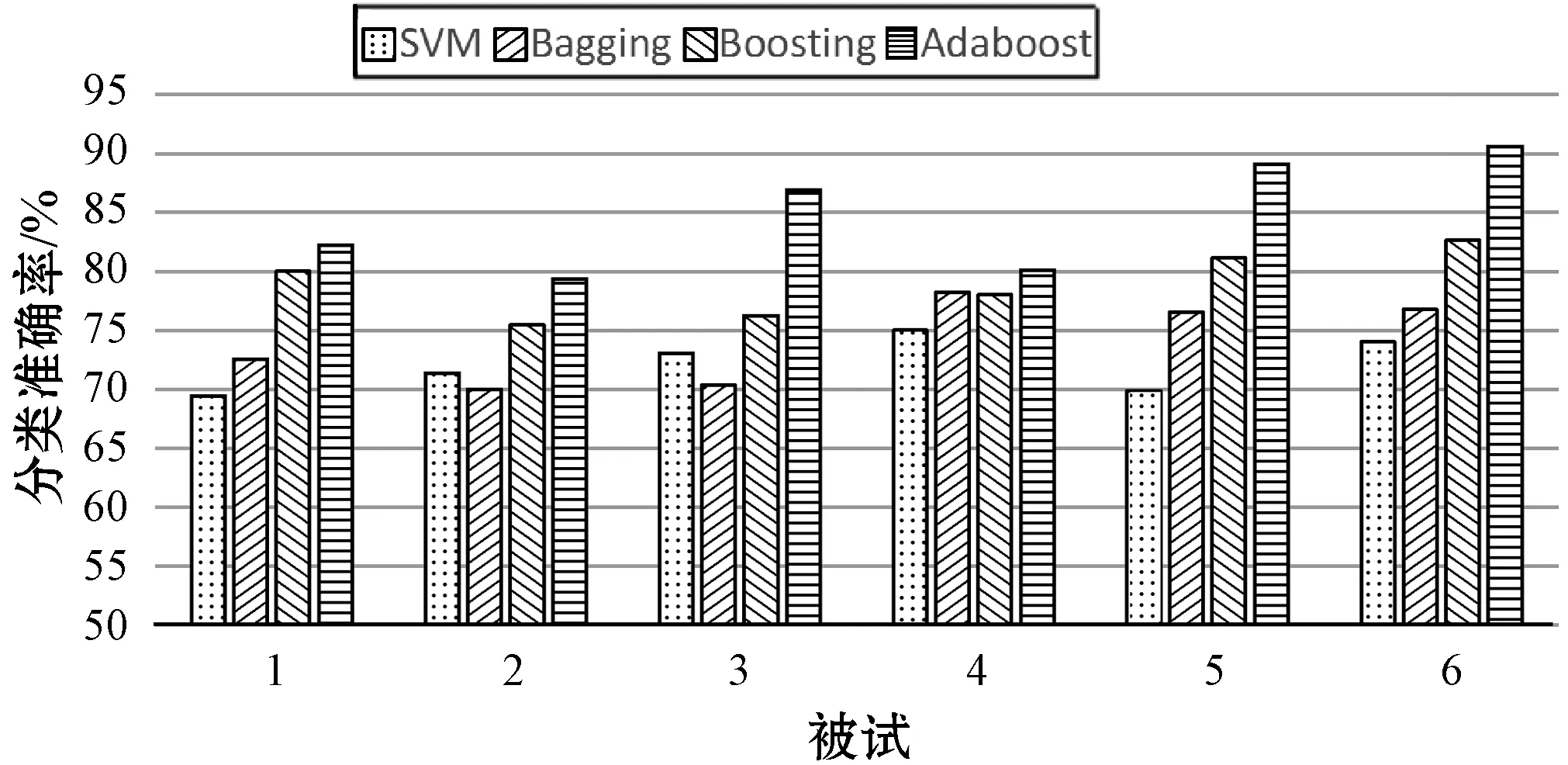
图6 四种分类算法在haxby数据集上的分类准确率
由图6可知,在被试2和被试3中,SVM分类准确率高于Bagging分类算法,在其余被试中SVM分类准确率均低于集成分类算法。在6个被试中,SVM分类识别率最高为75.01%,Bagging算法的识别率最高为78.23%,Boosting算法的识别率最高为82.67%,Adaboost算法的识别率最高可达90.60%。在fMRI数据的解码中,相较于分类效果较好的SVM单分类器,集成算法对视觉图片刺激的分类性能得到很大的提升,在一定程度上克服了过拟合现象的影响。其中与其他两种集成策略相比,Adaboost利用自适应迭代算法并结合弱分类器之间的差异性,不断更新分类器的权重,进而提高集成策略的分类性能,有效识别大脑认知状态间的差异。
为了进一步验证本文算法的有效性,表2对比了本文算法与文献中的分类结果。
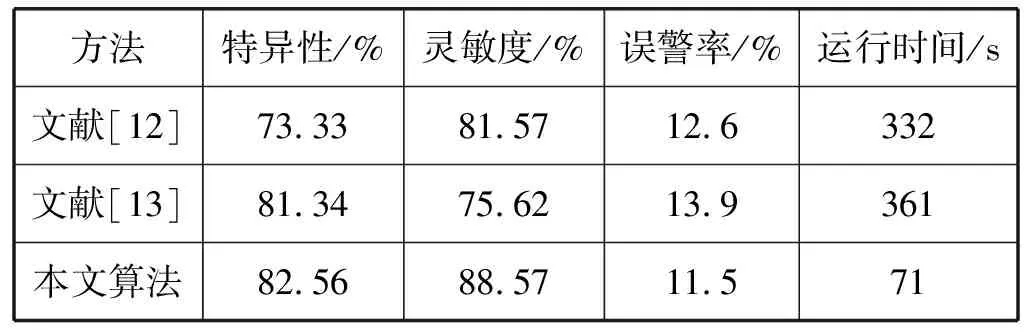
表2 本文与其他方法分类结果对比
各个性能指标的计算方法如下:
式中:SN为灵敏度,也称真阳性率(ture positive rate,TP rate),定义为被正确分类的正类样本(其中正类指一类图片样本)与所有正类样本数的比例,表征了分类器对正类样本的识别能力;假阳性率(false positive rate,FP rate)定义为负类样本(负类指其余图片样本)被错误分类为正类的样本数与所有负类样本数的比例,SP为特异性,定义为1-FP rate,表征了分类器对负类样本的识别能力;TP为真阳性个数,即其中一类fMRI图片被正确分类的个数;TN真阴性个数,即其余图片被正确分类的个数;FP假阳性个数,即其余图片错误分类的个数;FN假阴性个数,即其中一类fMRI图片错误分类的个数。
从表2可以看出:文献[12]通过引入受限玻尔兹曼机模型,提出基于卷积神经网络的fMRI数据分类模型,利用该模型可以有效提升fMRI 数据分类的准确率,但是网络结构和参数选取过程复杂且只是针对局部特征运行时间较长;文献[13]针对现有分类模型未充分利用fMRI 数据时序特性的缺陷,引入循环神经网络模型,并将无标注数据加入到模型训练过程中,提出了一种基于循环神经网络的时序fMRI数据分类模型,但构建神经网络模型较复杂需要耗费较多时间,且提取的特征收敛不稳定,分类灵敏度不高;本文提出的机器学习算法通过独立成分分析去除了实验中预测变量以及实验噪声,通过Adaboost模型利用自适应迭代算法结合弱分类器之间的差异性用于分析fMRI数据的分类模型构造简单、分类灵敏度较高、误警率低,在稳定性方面优于神经网络模型,并且大大缩短了运行的时间。从以上分析可知,本文方法从稳定性、运行时间、准确率等方面来看都有助于分类fMRI数据,为解码fMRI数据提供了一种方法。
3 结 语
本文运用独立成分分析对全脑及感兴趣区体素进行特征选择,充分考虑了各体素间的相互作用和空间分布,使得选择出的特征更具有针对性和代表性,去除了实验中冗余的预测变量和实验噪声。使用这些特征创建样本训练Adaboost分类模型可以克服fMRI数据维数高容易过拟合的问题,Adaboost分类算法集成多个弱分类器构造的强分类器进一步提高了对fMRI数据的解码能力,本文通过将ICA算法与Adaboost分类算法相结合为解码fMRI视觉信息提供了一种新方法。本文旨在分析大脑对视觉刺激的判决情况,使用本文方法无法有效识别大脑中的异常区域。因此,在以后的学习研究中,将重点探索大脑中与视觉相关的感兴趣区,利用脑网络连接功能在感兴趣区建立效应连接,识别出脑区差异进而判断大脑病灶区域。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
家庭医学(2022年3期)2022-04-07
贵州大学学报(自然科学版)(2021年5期)2021-09-26
电子技术与软件工程(2021年8期)2021-06-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
现代计算机(2021年8期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
