
车辆移动云可靠性任务调度
2019-11-12 05:01李晓静马海英
计算机应用与软件 2019年11期
李晓静 马海英
1(济源职业技术学院 河南 济源 459000)2(南通大学计算机科学与技术学院 江苏 南通 226019)
0 引 言
在物联网IoT时代背景下,城市道路上的车辆通常配置有数量众多的小规模处理能力的车载计算资源与设备。目前,大量研究正集中于如何利用车辆Ad Hoc网络VANET应用实现更安全更智能的驾车体检[1-2]。车载传感器生成的大量数据催生了车辆云计算(Vehicular Cloud Computing,VCC)的产生,它使得车辆间可以协作地为用户应用提供感知、计算和存储服务[3-4]。不同于传统的云计算,车辆云计算中的资源不固定于具体的物理位置,其形成的VANET拓扑结构会发生动态改变,车辆间的连通关系也无法可靠地持续连接。而车辆云计算技术充分利用邻居车辆的多余空闲计算能力,使服务需求可以持续供应,保证应用执行的连续性。其中关键问题在于如何选择邻居计算资源,以确保用户应用可以在截止时间内可靠执行并完成,并满足用户的服务质量需求。
目前,车辆环境下的云服务可分为三类[5]:1) 车辆利用传统云服务,即车辆可提交作业至云端,从传统的云数据中心获取服务;2) 车辆云,即车辆间可将低效利用资源以云服务的形式共享至其他车辆;3) 混合云,即传统云和车辆云混合提供计算服务。目前的车辆云研究多集中于第二种云环境。该环境下,车辆可形成临时的服务集群,并从集群worker中获取云服务。每个集群选择一个集群首CH,CH的作用是决定何时何地如何以分布式方式执行车辆用户提交的作业。文献[6]提出一种TSBIP算法。该算法利用二进制整数规化模型建立了车辆云下的应用调度模型,以并行方式执行任务调度,但由于车辆云中的车辆可能随时远离云环境,其应用的服务复制机制显得代价太大。文献[7]提出了一种BSS算法用于任务调度时车辆服务器的选择。该算法考虑了服务的执行能力,利用蜂群算法思想建立适应度函数选择最优的车辆,但没有考虑车辆移动环境下任务调度的可靠性,此时车辆间的连通对调度结果也具有重要影响。文献[8]为了解决车辆云计算中车辆的高度动态性对调度问题中失效检测性能的影响,设计了一种基于共享机制的失效检测方法,针对错误发生率和车辆负载指标的定量分析,对车辆节点进行分组,实现了高度动态车辆移动环境下的失效检测。此外,目前多数的车辆云中的任务调度多采用集中式调度方法[9-10]。然而,集中式调度在面对车载数据量剧增时显得效率不高,且已有研究在关注作业执行时未考虑可靠性问题,这在时间敏感型应用中极其不利。
基于以上分析,本文设计了一种面向车辆云计算环境的满足可靠性的任务调度算法OTS-VC,算法假设道路上拥有相对较低速度的车辆可以集群的方式构成群组,每个集群首CH利用MapReduce计算模型以快速分布式的方式进行数据处理,CH已知其所有worker成员节点的信息,包括若作业中的一个任务调度至成员节点时的期望执行时间和调度可靠性。将任务调度问题形式化为混合整型线性规化问题,提出一种启发式方法求解了任务至不同worker节点的最优映射策略。最后在网络仿真环境对算法的性能进行了有效性评估。
1 车辆移动云模型
考虑一个车辆移动云模型,车载单元可与邻近的车辆相互间提供传感与计算服务,允许具有相对较低速度的同向车辆组成车辆集群,集群首CH基于MapReduce分布式计算模型负责管理任一成员节点的作业发送任务[11]。
1.1 车辆集群形成
道路车辆通常在高速移动,导致车辆间的拓扑结构快速变化、通信不稳定,且新的拓扑信息在所有车辆间交换时开销增大。为了改善车辆间的信息流通,增加车辆移动云中的服务质量交付,同向移动的车辆可组成集群,集群首CH负责管理集群成员节点,并负责成员worker间的中继访问、流量控制、作业分解、集群worker间的任务分配、执行结果收集与返回。CH的选择考虑车辆的可用处理资源及吞吐量性能(信道带宽、车辆移动模式和MAC协议决定)。本文将拥有最高吞吐量与可用资源之积的车辆选择为集群首CH。
1.2 作业执行模型
在每个集群中,利用MapReduce大数据处理模型进行任务处理。MapReduce是处理大量原始数据的分布式计算模型,它简化了计算并行性、工作分布及机器可靠性,有助于车辆云计算应用开发者集中于具体的目标优化。
模型中,Map函数执行输入任务的预处理,并产生中间结果(key,value),表示为:
(1)
Map函数对输入数据进行分类并将其置为就绪状态。Reduce函数在中间结果ilist(key,value)上产生的输出结果为:
(2)
车辆云计算的MapReduce框架如图1所示。CH(簇首)可视为MapReduce框架中的master节点,其他成员节点可将其作业执行请求发送至CH节点。CH节点将作业分割为多个Map任务,Map任务为原子任务,即仅可成功完成执行或完全失效。Map任务在作为worker的车辆资源集合上进行调度。以上Map任务的结果被发送至另一worker资源集合,并在Map任务结果基础上执行Reduce任务。Reduce任务的结果最终被发送至CH,并最后将结果发送至请求的车辆。

图1 车辆云的MapReduce框架
在一个集群Cluster中,每个成员车辆的可用资源需要发送至CH节点。当车辆连接至一个CH节点时,需要广播其传感与计算资源信息至CH节点。被连接的车辆也需要周期性地发送其当前可用资源信息至CH节点,同时需要在CH上执行虚拟化过程以满足云任务执行环境,并持续追踪当前worker的所有可用资源信息。
图2是车辆云计算结构模型和CH及其worker成员的系统组成。不在本地资源上执行的应用可发送至CH,利用车辆云计算系统进行任务执行。
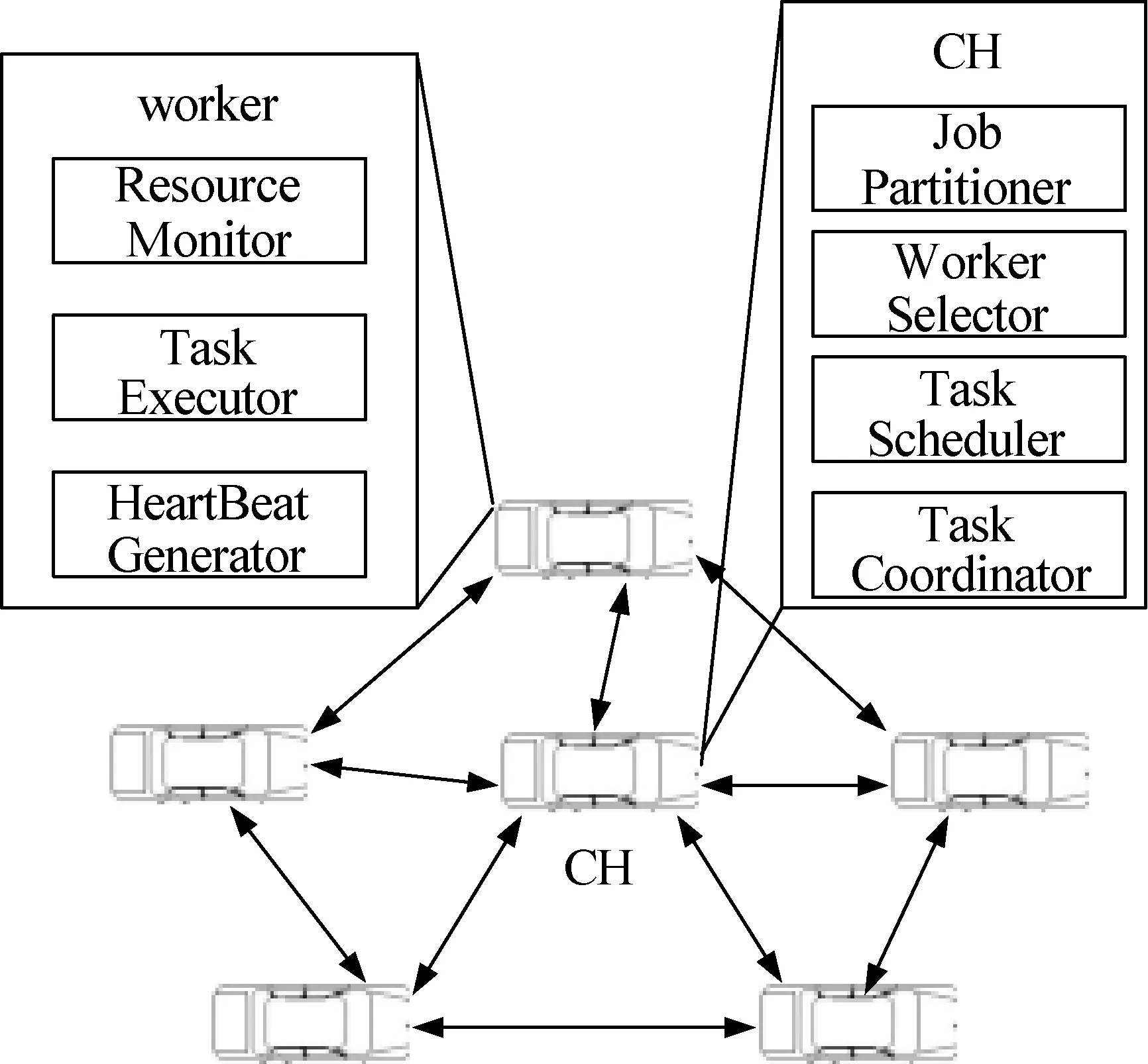
图2 基于MapReduce的车辆云系统
在作为CH的车辆中,Task Scheduler根据每个worker的能力分派任务至所选worker,worker的能力定义为其包含的时隙数量,一个时隙表示车辆上物理资源的可用性。在每个车辆上的Map与Reduce时隙数量是固定的,其时隙与内核比例由系统决定。每个时隙在给定时间内仅可运行一个任务。CH上的Task Coordinator需要周期性地检查每个worker的连通性和可用性,并重新调度运行至集群外的worker任务,增强系统的可靠性。每个worker节点需要监测其拥有的可用时隙,并周期性地通过Heartbert消息告之CH,信息格式如下:
Heartbeat Genertor周期性产生包含可用时隙数量、当前速度、位置和加速度的Heartbeat消息,并发送至CH。Resource Monitor检查时隙可用性、每个时隙中的任务队列、每个时隙的负载及处理器负载以决定可用时隙的数量。Task Executor从每个时隙的输入队列中载入任务并追踪每个任务的状态。
本文相关符号说明如下:
J:车辆的一个作业请求;
M:车辆集群中所有成员worker集合;
Sm:workerm∈M的可用时隙集合;
B:无线信道的bit速率,单位bps;
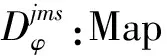
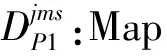


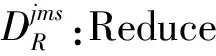
vm:workerm∈M的指令执行速率;
δm:workerm∈M与CH间互连周期;

σm:workerm∈M与CH间互连周期;
pm(t):workerm∈M与CH的连接概率;

α:响应时间与执行成功率间的相对权重因子。
2 车辆云中的最优任务调度算法OTS-VC
任务调度最优化问题即是以提高可靠性和降低任务响应时间为目标,进行任务执行worker群组的选择。若任务执行结果在截止时间前返回,则认为所选worker与CH间未失去连通性,是可靠的。响应时间定义为任务提交至worker与任务结果返回的时间间隔。worker拥有越多数量的Map和Reduce时隙,越可以降低共享中间结果的通信延时。worker处理单元越快,响应时间也越快。基于以上分析,本文设计一种目标函数用于选择最优的worker集合,实现任务的执行并满足预定约束。以下先给出响应时间和作业执行成功率的计算方法。
2.1 响应时间计算
作业响应时间由以下几个部分组成:1) Map任务的传输时间;2) Map任务的执行时间;3) 发送Map任务结果至Reduce任务的时间;4) 执行Reduce任务的时间;5) 收集结果的时间。不同子任务的通信和计算时间在不同集群成员worker上是不同的,如:Reduce任务的处理在得到Map任务的结果后即可开始,无需等待所有其他Map任务完成。因此,传输与处理子任务的最大时间之和给出了作业响应时间的最差值。令M为可用worker集合,Sm为workerm∈M的可用时隙集合,二进制变量Ajms=1表明任务j∈J执行于workerm∈M时隙s∈Sm中,否则,Ajms=0。
CH将作业J分割为j′个子任务,通过Map时隙执行,并将执行结果发送至J-j′个Reduce任务。函数f′()和f″()分别表明执行Map和Reduce任务时的指令。因此,所有Map和Reduce任务集合可表示为:
J={x1,x2,…,xj|(∀j>j′,∃j″≤j′)xj=f′(xj″)}
(3)
选择worker中合适可用时隙数量j调度Map和Reduce任务。令Y为Map和Reduce任务的输出成分集合,表示为:
Y={y1,y2,…,yj|(∀j>J)yj=
f′(xj|j≤j′)∨f″(xj|j>j′)}
(4)
f′(xj)和f″(xj)的执行时间取决于不同的应用类型。每个worker发送带有其邻居worker的连接列表至CH。根据接收的连接列表,CH创建一个二维连接矩阵C,其元素定义为:
(5)
式(5)的条件1表明Map和Reduce任务可在同一worker的不同时隙中执行。最优任务调度方法在分配不同的Reduce任务至worker的可用时隙时需要最小化Cmn值。假设所有worker与CH间的所有信道拥有相同的bit速率,为了计算Map任务和Reduce任务的传输与执行时间,任务中花费传输与执行时间最长即为总执行时间(由于不同worker的传输与执行可并行)。令B为无线信道的传输bit速率,workerm接收Map任务的传输延时为:
(6)
由于车载计算单元拥有不同的计算能力,任务xj的执行延时在不同worker上是不同的。对于任一j∈J|j≤j′,workerm处理Map任务时计算任务xj的延时为:
(7)
任意worker完成Map任务后,传输结果至|J|-j′个Reduce任务的延时为:
(8)
对于任一j∈J|j>j′,workerm处理Reduce任务时计算任务xj的延时为:
(9)
最后,Reduce任务结果传输至CH的传输延时为:
(10)
综合式(6)-式(10)涉及的所有延时,作业的总体响应时间为:
(11)
若作业中的任务在本地完成,需要的时间为:
(12)
式中:vo为单个时隙中的指令执行速率,So为可用时隙数量,vo×So则表示所有可用时隙中指令的执行速率;f′()表示执行Map任务的指令数,f″()表示执行Reduce任务的指令数;J为任务集合,j′为任务分割点,即j≤j′为Map任务,j>j′为Reduce任务。分子即代表所有Map任务和Reduce任务的总指令数,总指令数除以执行速率即可得到作业的执行时间。
2.2 调度成功率计算
与CH连接概率越高,车辆worker在截止时间内执行任务的可靠性越高。由于worker的位置与速度具有高度动态性,选择worker时必须考虑可靠性,从而避免失效与延时增加。若作业请求者脱离集群或应用执行发生逾期,则任务的截止时间T也将逾期。在截止时间T内完成任务概率越高的worker,选择为计算目标的概率也越高。该概率利用车辆worker与CH的连接率进行计算。workerm的连接率定义为δm=1/E[σm],σm为workerm与CH间的互连周期。
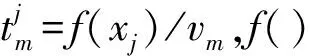
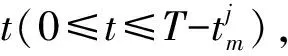
(13)
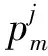

(14)
式中:二进制变量ζm表示worker m的时隙可用性。若worker m至少拥有一个空闲时隙,则ζm=1;否则,ζm=0。为了增加作业执行成功率,在进行任务分配时需要最大化所有任务的执行成功率。作业J的所有任务的整体执行成功率可表示为:
(15)
2.3 最优化问题的形式化
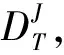
(16)
式中:α表示权重因子,给出作业完成时间和执行成功率的相对优先性。一些应用可容忍延时,但需要更高的执行成功率,一些实时应用则侧重作业完成时间而忽略执行成功率。作业发送至CH时,请求方可具体描述执行作业的响应时间Ir和成功率Is,并通过下式计算权重因子:
(17)
2.4 优化约束
1) 分配约束:
Ajms={0,1} ∀j∈J,m∈M,s∈Sm
(18)
(19)
式中:Ajms表示分配因子。若Ajms=1,则表明任务j∈J执行于workerm∈M时隙s∈Sm中;否则,Ajms=0。式(18)说明对于给定时间内,一个任务至多只能分配至一个worker的特定时隙中,式(19)则确保一个任务仅能在单个worker的单个时隙中执行,不能进行任务分割。
2) 作业完整约束:
(20)
式(20)确保作业中的每个任务必须分配至worker中任一时隙中执行,不可丢弃任务或不对任务分配时隙。
3) 能力约束:
(21)
式(21)确保分配至worker的任务数量不可超过其能力。
4) 时隙可用约束:
|J|≤∑∀m∈M|Sm|
(22)
式(22)确保所有worker中的总体可用时隙总量需大于或等于作业中的任务数,否则,作业执行不可行。
5) QoS约束:
(23)
(24)
式(23)确保车辆移动云中的作业执行时间需小于作业本地执行的时间,式(24)确保所有任务需在截止时间内完成。
2.5 启发式任务调度算法
本节设计一种启发式算法以更低的时间复杂度得到任务调度的最优解。算法可确保所选worker具有如下属性:对于给定的任务j,所选worker需满足最小执行成功率阈值pj,且得到的任务执行时间最小,从而得到最小化Z。即对于所有worker,以下不等式成立:
(25)
对于每个任务j的最小执行成功率阈值pj计算为:
(26)
式中:
(27)
算法1启发式任务调度算法
Input:J,M,Sm,α
Output:Ajms
[1]SΩ←∅
[2]Ajms=0|j∈J,m∈M,s∈Sm
[3]foreach taskj∈J
[4] calculateαusing Equ.17
[5]foreach workerm∈M
[7]endfor
[8] calculatepjusing Equ.26
[10]ifMp=∅then
[11]exit
[12]endif
[13]foreach slots∈Sm|m∈Mpdo
[16]foreach slotwinSΩdo
[18]endfor
[19]endfor
[21]Sm←Smsj
[22]SΩ←SΩ∪sj
[23]Ajms=1|s=sj&sj∈Sm
[24]endfor
算法时间复杂度分析。步骤3-步骤24的循环需要迭代J次,步骤5-步骤9拥有相同时间复杂度O(M),步骤13-步骤19在最差情况下迭代Sm次,其内层步骤16-步骤18迭代SΩ次,SΩ⊆Sm。因此,算法的总体时间复杂度为O(JM+JSm2)≈O(JSm2)。
3 仿真实验
3.1 实验环境
利用Hadoop MapReduce仿真器MRPerf[12]和车辆移动仿真软件SUMO[13]进行车辆云计算中的任务调度模拟。MRPerf可生成Map和Reduce任务的数据和流量,SUMO可仿真城市车辆移动和车辆行为,模拟道路负载。两种仿真器可并行运行于网络仿真器NS3中。
实验设置每公里道路区域内有20~50辆车,速度为36~90 km/h,每辆车的传输范围为100 m,利用SUMO生成城市环境为500 m×500 m的正方形区域,每条道路的250 m处有一个转弯道。利用WAVE(IEEE802.11p)实现车辆间的数据传输,该环境下拥有7条无线信道,信道速率为6 Mbit/s。每个数据包大小为1 024 bytes,每辆车拥有2~6个Map或Reduce任务,每个Map时隙和Reduce时隙分别配置1 500 MIPS和2 000 MIPS。每个worker包含1 GB或2 GB RAM和40~100 GB的存储。实验中每分钟生成2~8个应用,每个应用包含10~20个任务。每个任务的指令不同,故其执行周期也不相同。设置Is=6,Ir=4,heart-beat消息发送间隔分别设置为80 ms和40 ms,对应两种版本算法OTS-VC-80和OTS-VC-40。选择同为车辆云中的调度算法TSBIP[6]和BSS[7]作为性能对比算法。
3.2 性能指标
1) 作业的平均执行时间:个体作业的执行时间定义为作业发送时间与接收返回结果的时间间隔,平均值为所有作业的执行时间的均值。2) 调度成功率:当CH接收到执行任务的所有worker的返回结果时,即认为作业执行是成功的。那么,成功执行作业的比例可用成功完成的作业数量与仿真期间的总作业数量的比值得到。3) 系统吞吐量:单位时间内执行的作业数量。4) 任务执行开销:表示Map和Reduce时隙中的实际任务执行时间与总体响应时间的比例,定义如下:
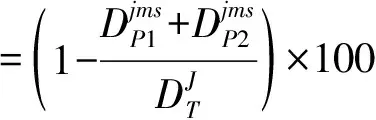
(28)
3.3 实验结果
1) 车辆密度的影响。增加worker数量会增加可用资源量,降低作业执行时间,但同时会增加worker间的数据传输干扰,导致数据传输时间增加。图3-图4是改变车辆密度时的性能表现,此时令作业到达率为6 jobs/min。图3表明所有算法的作业平均执行时间会随车辆密度增加会剧烈下降,这是由可利用的worker资源增加导致的。同时,车辆密度到达40后,执行时间趋于稳定。本文算法在平均作业执行时间方面优于TSBIP和BSS,这是由于OTS-VC所选车辆可以降低执行时间,提高可靠性,进而导致任务执行、任务重调度重处理及数据重传输的平均时间大幅降低。由于OTS-VC-40拥有更高的heart-beat消息传输频率,导致网络中消息冲突会随着车辆密度增加,这也解释了该算法为何得到了相对更低的可靠性和更高的作业执行时间。作业执行成功率随着车辆密度呈指数级增加,达到稳定点后略成下降趋势,原因在于:系统在车辆数量、数据传输量和控制信息数据包增加到一定程度时会出现拥塞,降低系统性能。本文算法拥有更高的任务执行成功率、更低的任务执行与数据传输延时,以及成功执行作业比例。由于OTS-VC-40算法中heart-beat消息传输频率更高,数据包冲突会随着车辆密度增加,导致其作业执行成功比例下降。图4表明,任务调度的吞吐量增加到一定程度后会开始缓慢下降,原因同上。本文算法得到的吞吐量仍高于另外两种算法,这是由于OTS-VC选择的worker拥有最小的数据处理和传输代价,这样可以降低任务的重处理代价。TSBIP和BSS的吞吐量性能随着车辆密度的增加出现了交叉,前者利用分布式方法,后者利用了集中式调度方法,开销更高,车辆规模会对其产生更大影响。
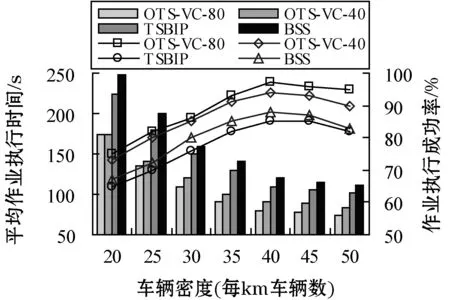
图3 车辆密度对平均执行时间和执行成功率的影响

图4 车辆密度对吞吐量的影响
2) 作业到达率的影响。图5-图6是车辆密度为30时作业到达率对算法性能的影响。图5表明,任务执行延时会随着作业到达率的增加呈指数级增加,这是由于车辆资源上增加的计算负载会导致更多的任务重调度、重处理、数据传输时间,用于任务处理的时间则相对较少。OTS-VC相比另外两种算法拥有更低的任务执行时间,由于前者在邻居节点中选择了可靠性更高的计算资源,使得可以一定程度降低任务处理、重处理及重调度的时间。此外,任务重处理重调度数量增加也会导致消息传输更加频繁,进而导致更大的任务执行延时。同时,作业执行成功比例会随着作业到达率的增加呈指数级下降,这是由于增加的系统负载会迫使系统选择能力较差的节点执行任务。本文算法在选择worker时考虑了任务执行成功率,因此拥有相对更高比例的任务成功执行量。OTS-VC-40性能较差,由于控制数据包的冲突会随着作业到达率增加而变得更加剧烈。图6表明,本文算法的吞吐量更高,由于算法在单位时间内可执行更多的任务,将任务重调度、重处理与数据重传输时间降低止最小。
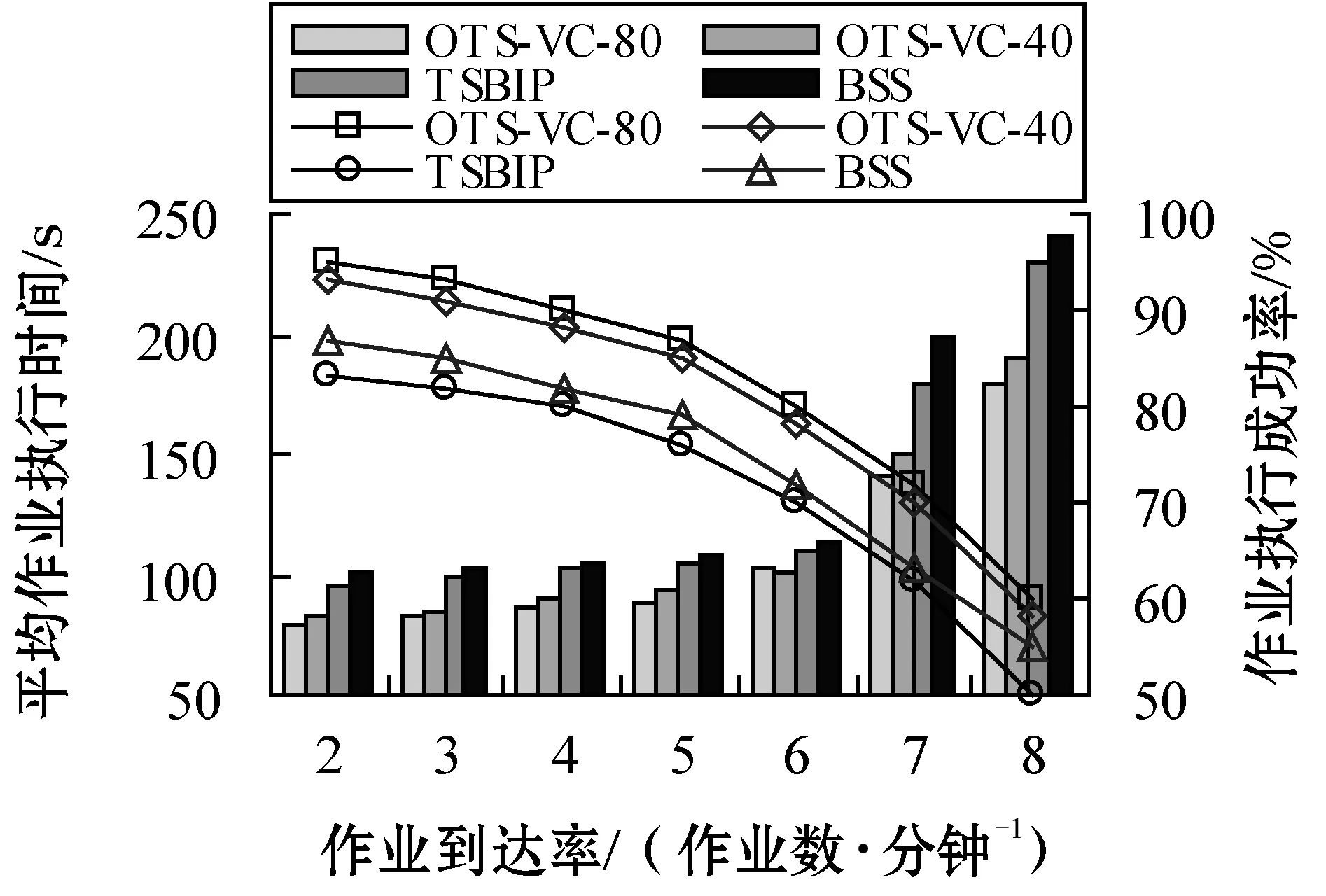
图5 作业到达率的影响
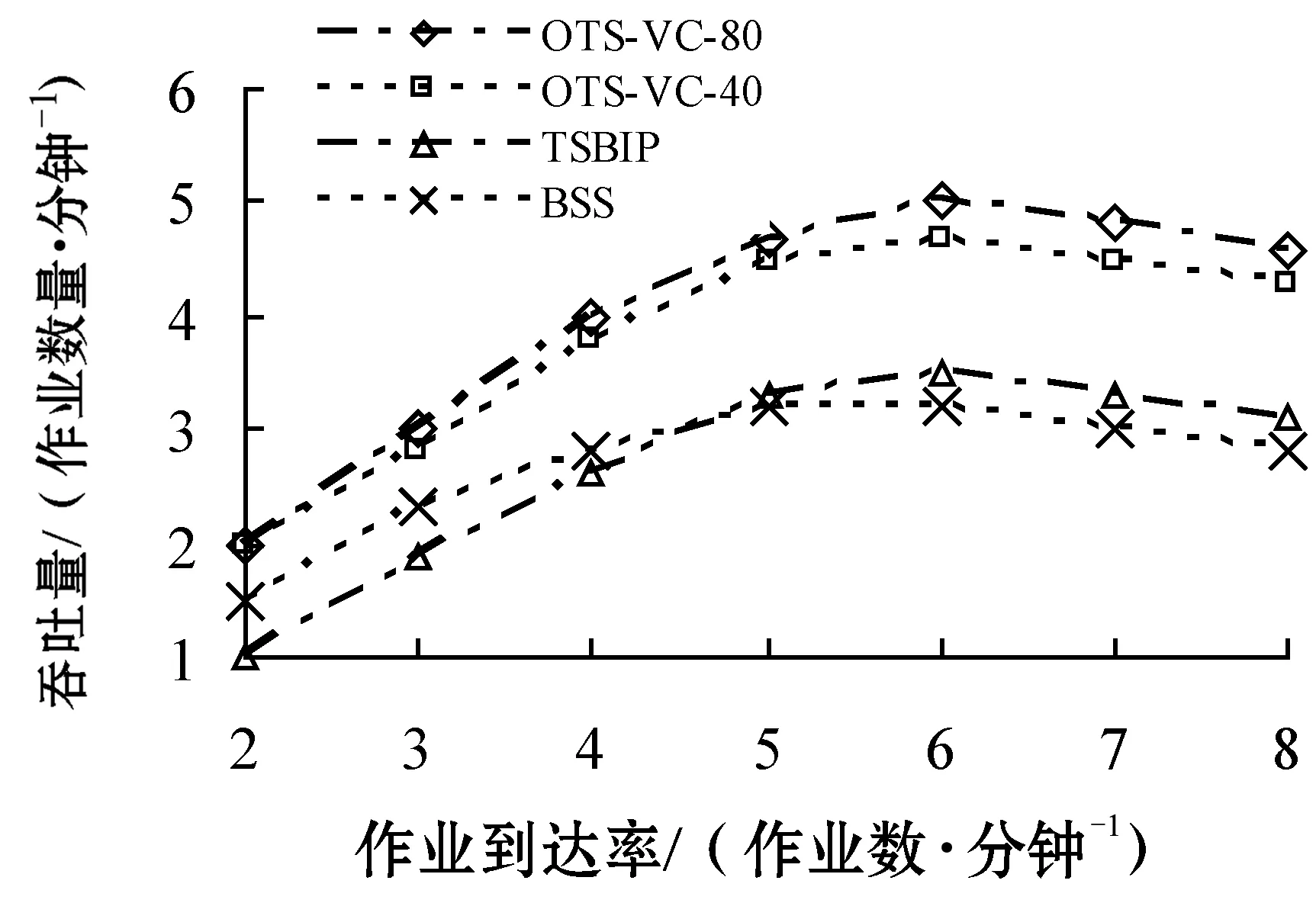
图6 作业到达率对吞吐量的影响
3) 任务执行开销。图7-图8研究了车辆密度和作业到达率对任务执行开销的影响。图7表明,车辆密度增加时系统开销呈指数级增长。本文算法执行开销更小,由于算法可以避免任务重调度和重处理,系统的管理开销相对更小。OTS-VC-40相比OTS-VC-80开销更高,由于前者在消息传输失效时需要进行任务重调度。图8表明,系统开销会随着作业到达增加呈指数级增长。本文算法执行开销更小,由于算法选择的worker是传输延时最小的,这样任务重处理的概率将大幅减小。
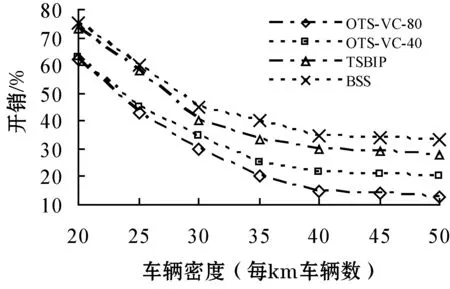
图7 车辆密度对开销的影响

图8 作业到达率对开销的影响
4 结 语
为了实现车辆云计算环境中任务的可靠性调度,本文提出了一种满足截止时间的任务调度算法。算法为了同步优化任务调度时间和任务调度可靠性两个目标,将任务调度的最优车辆选择问题形式化为混合整型线性规化问题,并设计了一种低时间复杂度的启发式任务调度方法对该问题进行求解。基于多种仿真平台的结合对车辆云计算的任务调度进行了仿真模拟。实验结果表明,该算法在调度时间和调度成功率方面均优于比较算法。
猜你喜欢
天天爱科学(2022年9期)2022-09-15
吉林大学学报(信息科学版)(2022年2期)2022-08-15
数字技术与应用(2022年7期)2022-08-03
当代水产(2022年6期)2022-06-29
计算机测量与控制(2022年2期)2022-03-30
水上消防(2020年4期)2021-01-04
舰船电子对抗(2020年2期)2020-06-23
科学与技术(2018年23期)2018-06-17
山东工业技术(2016年5期)2016-03-04
海峡姐妹(2015年5期)2015-02-27
