
一种基于流媒体压缩算法的高性能集群监控系统
2019-11-12 05:12:26樊书华
计算机应用与软件 2019年11期
樊书华 王 鹏 汪 卫
1(复旦大学软件学院 上海 201203)2(复旦大学计算机科学技术学院 上海 200433)
0 引 言
随着互联网的蓬勃发展,计算机集群系统已应用在人们生活的各个方面。集群的主要作用是对系统中各个节点的使用情况进行实时的管理和掌握[1],集群监控系统也随之应运而生[2-4]。通过对集群的各项数据,包括应用负载、CPU利用率、磁盘、网络流量、内存、应用心跳等系统指标,分别进行收集存储,并在处理分析后做出相应判断,当发生异常情况时对系统管理员发送通知,从而达到实时监控的效果。但是以人工的方式对集群进行监控管理存在着各种各样的问题,比如效率过低、对系统异常的捕获不够及时等,因此集群监控系统的实现程度将直接决定集群系统是否能够平稳运行。
然而随着实际生产环境中业务的增加,集群规模逐渐扩大,服务器收到密集的高负荷请求,现有的集群监控系统如针对openstack开发的Ceilometer[5-6]、层次化监控系统Ganglia[7-9]、企业级开源系统Zabbix[10]等,在性能表现方面容易产生瓶颈。以目前应用较为广泛的主流系统为例,Ceilometer在开源集群监控系统中相对于其他几个监控系统,在完整性、轻量性等几个方面很有优势[11]。但由于其使用单层的客户端服务器模式来搭建监控系统,当集群规模扩大时,数据的种类和规模都会扩大,这样数据采集、存储就容易遇到瓶颈。
针对目前集群监控系统存在的性能问题,本文旨在设计并实现一种基于流媒体压缩算法的高性能集群监控系统。首先,对性能问题的表现和问题产生的原因进行介绍,包括监控数据量的组成分析以及监控数据帧的时间和空间冗余性分析;其次,对系统架构以及对应的功能模块进行描述;再次,分别从数据帧冗余性优化、系数量化处理等模块对系统高性能进行设计与实现;最后结合系统实验,给出性能提升具体结果与评估。
1 相关工作
当前常用的压缩算法包括LZ4、Brotli、LZF、Snappy等,接下来首先对这几种算法进行简单介绍。
LZ4算法来源于LZ77,由Yann Collet在2011年发明。该算法采用滑动窗口的原理,通过哈希表对字典进行存储,从而对匹配的字符串进行查找。其中哈希表的key值代表字符串的二进制值,value值代表字符串在文件中对应的位置。主要优势为压缩效率高,当需要压缩的数据中出现的重复项越多时,压缩效果越好。
无损压缩算法Brotli在2015年由Google提出,通过哈夫曼编码以及变种的LZ77算法等方式对数据进行压缩,主要用于处理顺序数据流。该算法不仅包含常见的滑动窗口字典,也对常见字符串字典进行了预定义,从而增强压缩效果。Brotli算法已受到绝大多数主流浏览器的支持,达到加快传输速度的效果。
LZF算法对字符串通过LZ77及LZSS的混合编码进行压缩,由入口文件、压缩和解压缩文件、配置及接口文件组成。LZF算法较为轻量,Redis中默认采用该算法,在数据存储至本地时进行压缩处理。
Snappy算法在2011年开源,来自于Zippy并由C++语言实现,该算法以压缩率和兼容性为一定代价,实现较高压缩速度以及压缩比的目标,压缩速度达到250 MB/s甚至更高。Snappy算法在Google很多内部项目诸如MapReduce以及BigTable中得到了广泛使用。
但在这些传统的数据压缩算法中,通过字符串匹配和哈希字典等方式进行压缩,虽然在单个时间片单个数据帧上效果很好,但没有考虑到集群监控系统中数据帧在时间轴上的冗余性。此外,这些压缩算法还需要在主从两个节点之间同步字典数据,这会带来额外的网络带宽开销。因此本文旨在设计一种新的基于流媒体压缩的算法用于集群监控系统中,从而对系统性能进行有效提升。
2 问题分析
集群监控系统的性能瓶颈主要表现如下,以ceilometer监控系统为例:在其余参数恒定的条件下,服务器端(即时序数据库gnocchi)单位时间内可以处理的数据量会随客户端(数据采集器collectd)的缓冲区大小(单个restful请求包含的数据量)的变化而呈线性增长,即:当缓冲区大小为100条时,单位时间可以处理的restful请求为600条,单位时间可以处理的数据量为6万条;缓冲区大小为500条时,单位时间可以处理的 restful 请求为533条,单位时间可以处理的数据量为27万条。
根据目前配置,当客户端缓冲区的大小为200条时,服务器端时序数据库在单位时间内能够处理的restful请求大概在500条,其中包括的数据条目大概为10万条。以单个被监控节点一次轮询的6 000条数据为基准,假如被监控节点数目为200台(在不考虑客户端相同数据重发的状态下,实际上随着写线程数量的增长,数据采集器缓冲队列里的内容被重发的概率也越高),在单次轮询时间10秒内会产生120万条数据,这样会使得数据库阻塞,随着写线程的增多,不到200台主机就会使得数据库发生阻塞。当然按照网络流量数据,200台主机的网络流量为100 MB/s,达到了百兆网卡极限,也是千兆网卡的10%,会给网络流量产生很大压力。
接下来,对目前集群监控系统中存在的性能方面的问题原因,分别对监控数据量以及数据帧在时间和空间上的冗余性进行分析。
2.1 数据量分析
当集群规模扩大时,服务器收到的请求密度变大,此时容易产生阻塞现象。以单台宿主机为例,在单位时间内需要向服务器发送高达0.5~1 MB的时序数据集(包括物理机信息,虚拟机信息和docker信息)。以单次轮询来看,一次性需要收集的数据就达到了几千条,当宿主机规模达到一定量以后,监控整体系统性能将会受到严重阻塞,影响监控效率。
针对采集到的监控指标,数据类型可以分为以下几个部分,包括中央处理器、进程、网络、内存、硬盘等。针对单台物理计算节点而言,监控数据量具有两个主要规律:
• 横向增长:针对单台物理计算节点而言,随着主机上搭载的虚拟机数目增加,对应的虚拟机指标,主机全体指标将随之增长;
• 纵向增长:物理机中随着CPU核数的增长,对应的各项监控数据指标,包括总使用量、steal百分比、空闲百分比、IO等待百分比、用户百分比等也呈线性增长趋势,这一规律对网卡、进程、磁盘也有效。
综上,对于集群监控系统来说,单个节点需要采集的数据指标就已非常可观,若对多个节点监控指标同时采集,数量集将是非常庞大的,并且随着监控节点数的增加数据量也会成倍增加,这无疑会给集群监控系统性能方面的表现造成影响。
2.2 数据帧冗余性分析
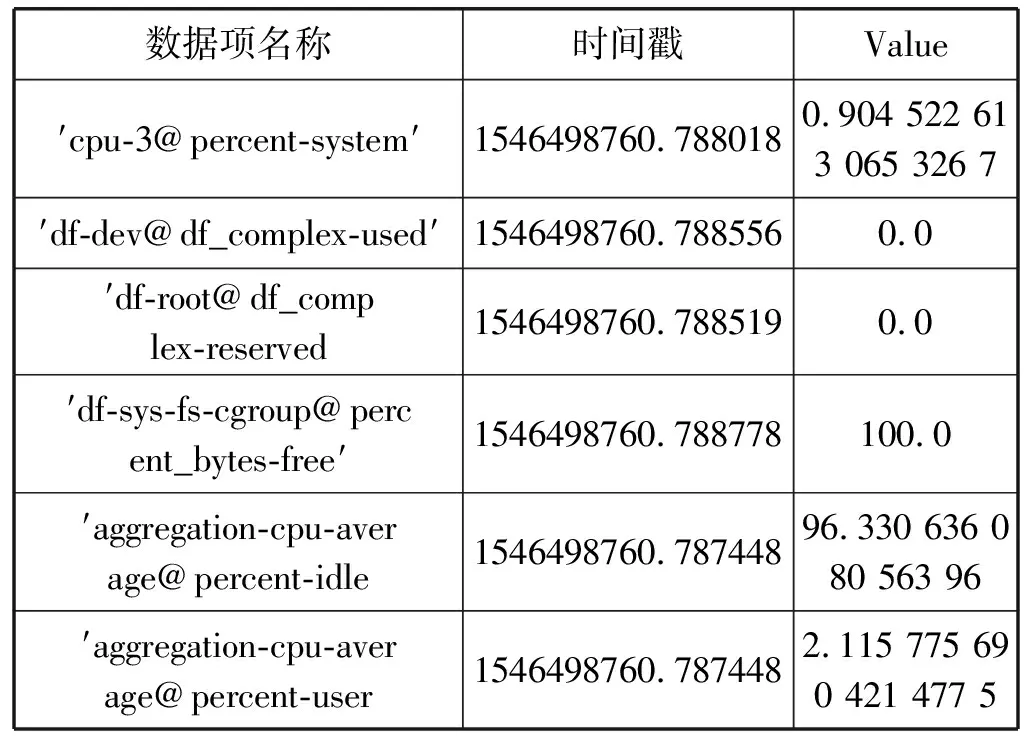
数据帧主要具有时间和空间两方面的冗余性。采集到的数据帧以哈希表(python字典)的形式进行存储,例如[{′df-sys-fs-cgroup@precent_bytes-free′: {′Timestamp′: 1546498760.7887914, ′Value′: 100.0}}],如表1所示,时空冗余性主要体现在如下两个方面:
• 空间冗余性方面,在某一个时间点t1上,所有数据项的时间戳在小数点之前(即秒级单位)都是相同的,小数点之后的差别可以忽略不计,故只保留一个时间戳即可。同时形如′Timestamp′和′Value′这样重复的键值也是产生空间冗余的原因。
• 时间冗余性方面,在两个时间点t1和t2上,两帧数据的表项名称都是相同的。因此每隔一定时间对监控数据进行采集时,总会对各个监控项的子条目名称进行高覆盖率的重复收集,这是时间冗余数据产生的原因。
续表1
3 总体架构与环境搭建
3.1 系统架构
在本文实现的基于流媒体压缩算法的高性能集群监控系统架构中,如图1所示,以数据收集、数据存储、数据分析为基本层级,之后将分析处理后的数据实现展示、报警以及自适应等功能。在数据收集层,通过给各个数据采集器collectd节点添加插件(主机监控插件,libvirt插件以及docker插件),从而定期地对系统和程序中各个指标进行收集。
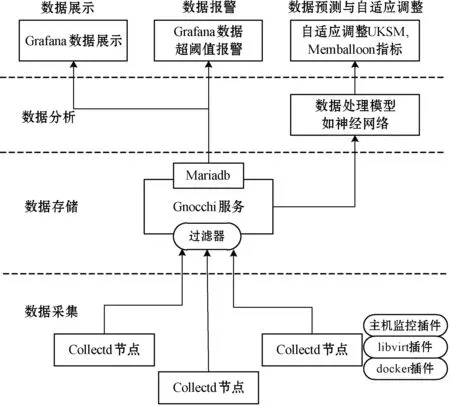
图1 集群监控系统架构
针对时序数据库,实现对物理机、虚拟机以及容器的同时监控。数据采集之后采用过滤器连接Gnocchi服务,采用最新的流式压缩算法实现高效的数据存储和传输机制,从而实现数据存储层要求。此外,数据展示层是与用户最相近的一层,对Grafana组件进行定制,以集中统一的方式实现数据的展示,给系统管理员带来便捷。
3.2 模块功能
本文实现的集群监控系统中包括数据收集、数据存储、数据处理等在内的各个功能。
在资源采集方面,数据采集阶段引入Collectd守护进程[13],并以在Collectd上实现插件的形式,完成对系统以及系统中应用程序的各类性能指标进行定期的收集任务。同时,面对海量的数据收集过程,本文在数据采集器的性能方面进行了有效的提升。首先,对Collectd所采集的大批量数据进行精简化,其次,采用压缩数据的方法,减小了网络中的带宽压力。最后,通过调整数据采集器的发送流程,当阻塞的时间超过提前设定的阈值时,对该数据进行丢弃处理。
在高效的数据传输和存储方面,采用了Gnocchi这一款开源的时序数据库。Gnocchi专门为处理大规模时序数据的存储和索引而设计,在数据存入之前就对相应数据进行了聚合操作,从而提高了数据访问效率。
在系统界面方面,随着系统中业务发展的日益复杂化,若对集群监控的过程中随时对系统中的运行情况进行掌握,监控数据的可视化展示部分是集群监控系统必不可少的组件。在与用户主要交互的数据展示层,本文通过对Grafana的组件和模板采用定制的方式,对所需要监控的集群来进行整齐统一的管理。
3.3 环境搭建
本文实现的集群监控系统整体环境为:通过Kolla Ansible对OpenStack进行部署。其中,Ansible本身是专门为分布式集群安装程序的框架,Kolla是Ansible的子项目,以Ansible为基础,专门为OpenStack提供服务。Docker作为一个开源的应用容器引擎,目标在于为操作系统的虚拟化提供轻量级的解决方案,相当于小的封闭式操作系统环境,同时具有快速的部署和交付能力,以及良好的扩容性和资源利用率。如表2所示,集群搭建的机器环境包括服务器端和客户端。

表2 集群监控环境
对监控环境Collectd以及Gnocchi来说,服务器端(数据采集端)配置与客户端(数据发送端)配置如表3所示。

表3 集群服务配置
4 系统设计与实现
针对高密度的数据请求容易产生的阻塞现象这一问题,如图2所示,本文的主要解决思路为:通过引入流式数据压缩,对传输的数据进行压缩处理。在H.264编码算法中,主要分为正在编码的帧和参考帧,参考帧即为已经编码且经过了重新解码。根据正在编码的帧得到当前宏块,同时结合参考帧进行预测,从而得到预测宏块。预测宏块作用于当前宏块获得残差宏块,并进行变换和量化处理,随后的过程主要分为两部分:变换和量化后进行熵编码,获取编码后的比特流;通过反变换和反量化产生解码残差宏块,进而获得参考帧。
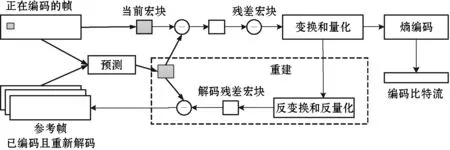
图2 流式数据压缩H.264编码算法
在具体分析如何对系统性能进行提升之前,首先需要对系统中对数据的收集过程进行了解。本文采用数据采集器Collectd及相应插件对集群系统的监控指标进行收集之后,通过Redis写入Gnocchi数据库。
如图3所示,数据采集器Collectd收集到的数据以列表的形式进行存储。每台主机上采集到的数据格式包括接口、内存、进程、网络等监控项,每类监控项又包含数个子条目。列表中的每个元素都包含监测数据项与标签两个部分,标签以0和1进行区分,0代表该项未被线程读,1则代表已读。系统中存在n个读线程read_thread worker,首先确认列表中元素的标签值,若标签为0则进行读取,并写入到队列write_queue_s的队尾处。队列write_queue_s遵循先入先出的规则,因此对于写线程write_thread worker,依照从队列头部读取数据的顺序通过write-http请求写入数据库。
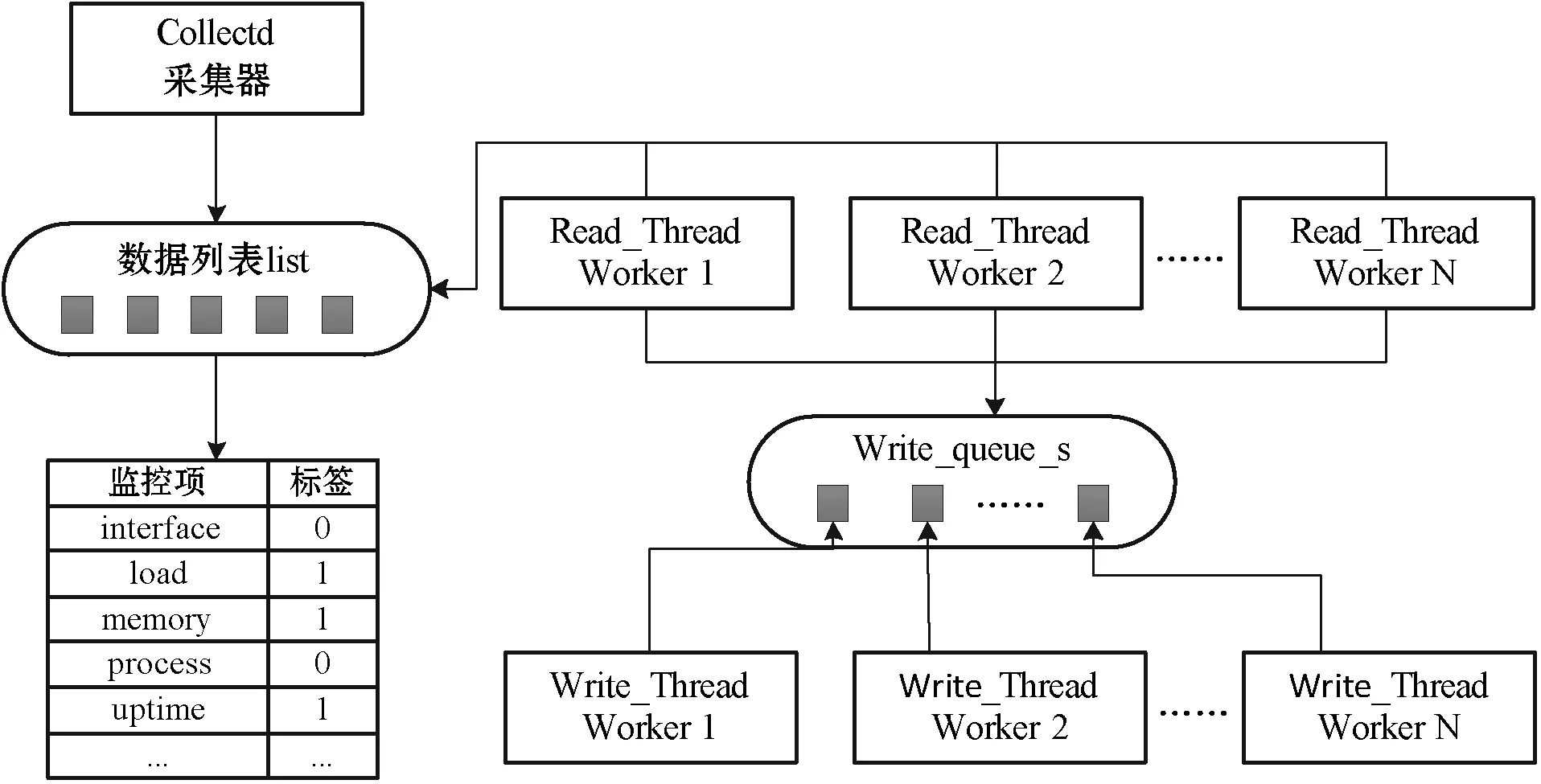
图3 集群数据读写
4.1 数据帧冗余性优化算法
在数据帧时空冗余性方面,结合第2节问题分析中的冗余性详解,优化主要分为以下步骤:
• 对采集到的监控数据项来说,列表中每个元素的时间戳属性都非常接近,因此采取将时间戳规整到同一个值的方法,并归并到数据帧外达到有效压缩的效果,从而大大减少同一次收集的数据帧中时间戳出现的频率。
• 在数据集的Value项中,未经优化的值小数点后取到了十几位以上。因此本文通过对较低位,即无效位数进行裁剪,达到对系统性能实现优化的目标。
在数据帧的时间冗余性优化方面,首先数据采集器Collectd对节点采集监控指标数据,同时对不同的时间点来说,采集到的两段计算资源的数据项名称大部分时间都是相同的。如磁盘的子条目包括df_complext_reserved、df_complex_used,CPU的子条目为percent system、percent interrupt。因此,每隔一定时间对监控数据进行采集时,各个监控项收集的相应子条目名称重复率也非常高。
为了提升系统性能,本文设计了运行在数据采集器Collect的与数据库Gnocchi之间的数据帧同步协议(Datagram Synchronization Protocol)。数据采集器Collectd在对监控数据处理进入Gnocchi数据库之前,使用Redis的缓存设计,在写入Gnocchi之前,首先进入Redis缓冲区,从而达到加快读写速度的效果。同时,采集到的监控先将所有的监控条目名记录到缓存中,然后将压缩后的值写入到对应条目的值中。
如图4所示,数据库Gnocchi与数据采集器Collectd之间的数据帧同步协议的整体流程为:
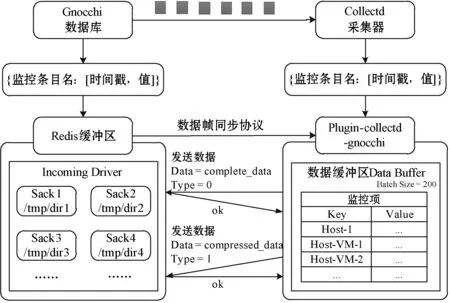
图4 数据帧同步协议
• 首先数据采集器Collectd对需要监控的指标进行数据收集,数据帧格式为包含哈希表的列表,即{监控条目名: [时间戳,值]}。同时,一个写线程write-thread对应一个plugin-collectd-gnocchi。
• 进入到数据缓冲区Data Buffer后,本文对监控数据项使用字典结构(Dictionary),字典中的key存储监控项的名称,value为该监控项的对应值。
• Redis缓冲区中含有Incoming Driver,其中包含各个目录,如temp/dir1、temp/dir2等,之后每个目录节点将各自由一个metricd worker进行处理。Redis缓冲区中先存储监控条目名,即字典中的key,随后每个条目名的对应值等待下个步骤传输。
• 数据采集到服务器端,而数据的预处理过程放到客户端进行。在数据采集缓冲区中保留最新数据帧,当产生新的数据帧时,与缓冲区中已有的数据帧作对比,检测两个数据帧是否高度相似,假如两者数据相似度非常高,则不再进行发送操作。
• 在本文提出的数据同步协议中,数据分为两种类型,对于完整数据complete_data来说,以类型为0标记,调用函数0写入Redis缓存中对应条目名的value值,对于压缩数据compressed_data来说,以类型为1进行标记,通过函数1写入Redis缓存。
• 两个缓冲区中的内容保持同步,假如发现了新的数据,在数据缓冲区Data Buffer与Incoming Driver两个缓冲区都没有保存,则认为该数据为complete data,类型为0,发送完整数据包,并在缓冲区中生成对应的数据帧;若发送的数据帧中条目比缓冲区中的条目少,则多出来的条目对应值保持原始值不变。
下面对算法进行定义:
算法1数据帧冗余性优化算法
输入:来自于单个数据采集节点的日志log={log_msgi|i=1,2,…,N},其中单位子日志log_msgi以字典的形式进行存储,具体格式如下:log_msgi=[{Entryname:{Timestamp,Value}}]。
输出:基于流媒体压缩的日志数据。
1) 数据帧原有序列中的key值,即监控项名称,转换为对应序列号;
2) 合并数据帧中的时间戳,并抽取Timestamp中的公共部分进行统一;
3) 消除数据帧条目中的冗余表项名;
4) 当产生新数据时,与缓冲区已有数据作对比,检测是否高度相似,若相似度较高则不再进行操作。
4.2 系数量化处理
针对时序数据中因为数据过大而占资源过多的性能问题,本文对数据系数进行了量化处理。找出一系列数据中尽可能接近的公因子进行提取,从而使提取后的数据值变小,来达到减少传输数据量的目标。
系数量化之前,取原数据序列{18, 9, 46, 27, 35}中各个数据最为接近的公因子9作为公共系数,在提取该系数之后,产生新序列:9{2,1,5,3,4}。通过量化处理,能够减少数据存放空间,对系统的表现性能产生优化作用。为了还原原始数据,可以通过量化后的数据序列与系数结合,产生{18, 9, 45, 27, 36}。
4.3 系统实现
集群监控系统中的数据收集依赖于各个Collectd节点,数据存储结合Gnocchi服务。首先对以下几个主要组件进行说明。Collectd_gnocchi作为一种插件,帮助Collectd发送给Gnocchi的数据接口。Gnocchi_metricd是单独的线程Thread Worker,从Gnocchi的前端Sack中取任务节点,并存储到Gnocchi的后端数据。gnocchiClient为Collectd_gnocchi调用的发送数据包的接口。Gnocchi_api负责接受数据包。
数据压缩与解压缩流程如图5所示。首先Collected_gnocchi将Collectd收集的数据发送到Gnocchi的数据接口Client,数据压缩完毕之后通过网络中的http请求与post请求,随后数据进行解压缩后,Gnocchi_api负责接收数据包,Gnocchi_metricd中的线程将分别从Gnocchi的前端目录中调取任务节点。
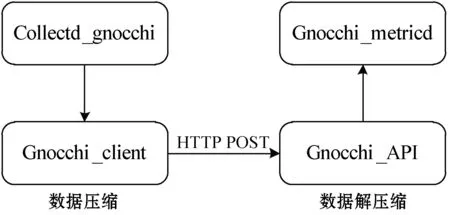
图5 数据压缩与解压缩
客户端和服务器端的部分代码如下:
# 客户端部分代码
Def preparePost(self, typeV)
refreshCache(raw[‘key’])
if data[type] == 0
data[key] = cacheDictionary
else if data[type] == 1
data[key] = valueList
# 服务器端部分代码
Def processData(request)
getType_Data_Hostname_Timestamp
# 从Redis缓存中提取对应数据,然后还原数据帧
if data[type] == 1
myDictionary = loads(redisGet(HostName))
myDataList = loads(Data);
getResultDictionary
# 存入Redis缓存
else if data[type] == 0
redisSet(myHostName, myData)
客户端的核心代码实现思路为:
1) 初始化函数定义整体数据帧缓存,并定义处理后的数据列表;
2) 当新数据产生时,通过refreshCache函数起到刷新数据帧的作用;
3) 根据最新数据帧,generateData函数提取数据,并保留两位小数;
4) 当数据类型为0时,发送完整数据帧,当数据类型为1时,发送压缩后的数据帧。
服务器端的核心代码实现思路为,通过Process_data函数,对两种数据类型分别进行处理:
1) 针对压缩过的数据帧,从Redis缓存中提取相应的数据,然后还原数据帧;
2) 针对未压缩的数据帧,直接存储Redis缓存。
5 系统实验与评估
5.1 实验环境
系统实验采用1台物理机搭载18个虚拟机的形式,具体实验配置如表4所示。
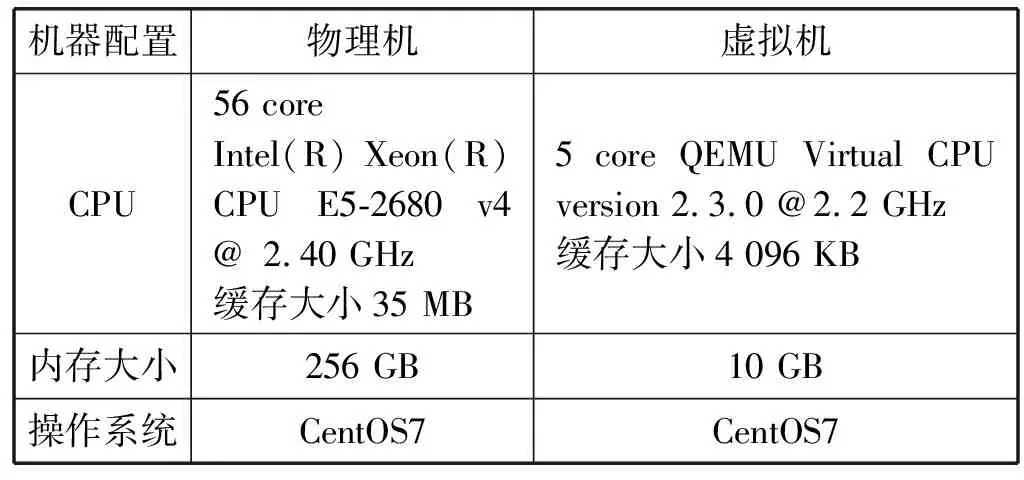
表4 集群监控系统高性能实验配置
5.2 实验结果
在分别对采集的监控指标进行时间冗余性数据压缩、空间冗余性数据压缩、量化数据压缩等一系列步骤后,数据压缩前后对比如表5所示。

表5 监控数据压缩前后对比
本节对压缩效果进行了实验测试,在时间间隔为10秒的前提下,每隔10秒对节点进行监控数据收集,为了比较多次实验下相应的压缩效果,本文分别在时间轴10、20、30、40和50 s对节点取了5次监控指标数据,得到了数据在各个阶段优化后相应压缩结果。从表6中可以看出,压缩的数据比例平均为原始数据的88.68%,压缩后数据大小为原始数据的11.32%,其中时间冗余与空间冗余优化的提升效果最为明显,多次实验平均优化结果分别为35.33%和52.60%。
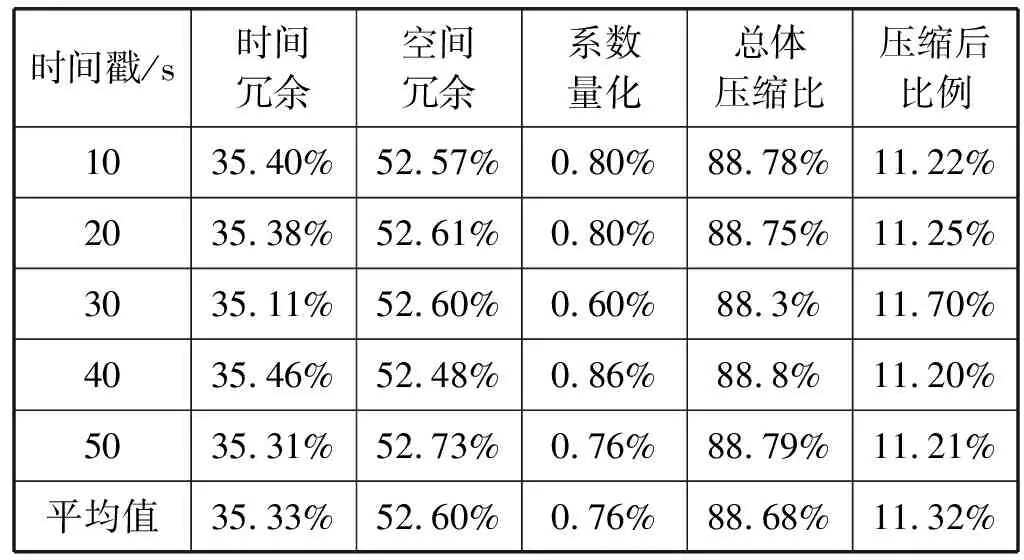
表6 监控数据各流程压缩比
同时本文将实现的流式高性能压缩算法与当前包括LZ4、Brotli、LZF、Snappy等在内的主流日志压缩算法进行效果对比,具体结果如表7所示。可以看到在这些算法中,本文实现的流式算法达到了最好的压缩效果,在两组实验测试数据中,压缩后的数据对原始数据大小的比例分别为11.22%以及11.25%,其余四种传统算法分别在14.86%到18.8%之间,说明本文设计的基于流媒体压缩算法在实际数据采集中也有着可观的性能表现。
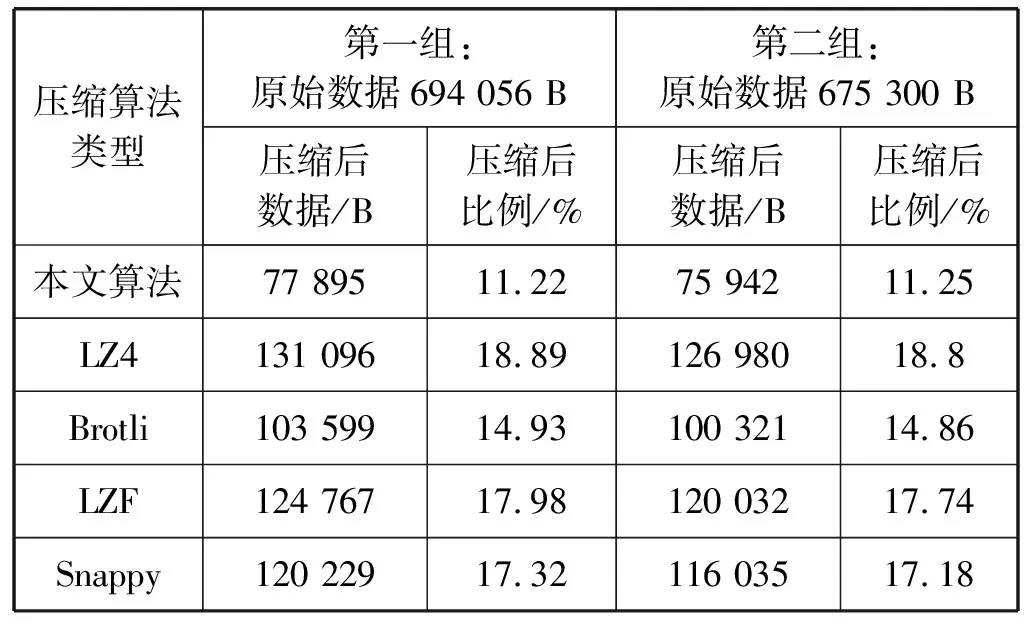
表7 本文算法与LZ4、Brotli、LZF、Snappy算法效率对比
本文提出的基于流媒体压缩算法在性能方面优于其他主流压缩算法的主要原因为:针对流式数据的时间冗余性与空间冗余性两大特征,基于流媒体的压缩算法通过信息同步的策略使得重复数据不再进行传输;同时针对两个时间节点来看,假如数值相近,本文减少一次信息的发送,从而进一步减少信息的冗余。与传统的数据压缩算法相比,对数据帧在时间轴上的冗余性做出了良好的优化。此外,这些压缩算法会带来额外网络带宽开销的,本文算法计算大多分布在从属节点上,因此不会对主节点带来额外的计算开销。
6 结 语
针对目前主流集群监控系统在性能方面的问题,本文旨在对一种基于流媒体压缩算法的高可用集群监控系统进行设计与实现。首先针对系统产生问题的原因,如监控数据量在纵向层面和横向层面的相应增长规律,数据冗余性体现,结合从实际节点采集的数据帧格式进行展示与分析。为了解决该问题,本文设计了运行在数据采集器Collect的与数据库Gnocchi之间的新的数据帧同步协议,并先后从数据帧空间冗余性优化、数据帧时间冗余性优化、系数量化处理等步骤进行实现。
在系统实验中,每隔一段时间对实际节点进行数据采集,经过系统高性能设计与实现之后,数据优化效果明显,其中对数据帧的时间冗余性和空间冗余性的提升效果最为突出,压缩比分别在35%与52%左右。从实验结果可以看出,本文实现的高性能集群监控系统在实际应用场景中具有很大的发展潜力。
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
现代仪器与医疗(2021年1期)2021-06-09 05:53:54
铁道通信信号(2019年9期)2019-11-25 01:44:54
计算机测量与控制(2017年6期)2017-07-01 16:24:05
计算机测量与控制(2017年6期)2017-07-01 16:24:04
电讯技术(2017年4期)2017-04-16 04:16:03
项目管理技术(2015年3期)2015-04-23 08:44:29
电测与仪表(2015年14期)2015-04-09 11:55:56
电子设计工程(2014年12期)2014-02-27 11:58:12
计算机工程与设计(2012年3期)2012-07-25 11:05:00
