
基于语义分割和像素非线性核的视频去模糊∗
2019-11-12 06:38:54马源源
计算机与数字工程 2019年10期
董 飞 马源源
(陕西铁路工程职业技术学院电气与信息工程系 渭南 714000)
1 引言
视频去模糊技术取得了显著进展并得到了广泛应用[1]。然而,大多数去模糊方法都是针对单个图像[2]开发,而对视频去模糊[3]的关注则相对较少,其中模糊是由相机抖动、物体运动和深度变化等因素造成。由于相互作用和复杂的运动,传统的均匀模糊[4]或非均匀模糊[5]模型无法很好地模拟视频去模糊。同时,由于大多数现有的视频去模糊方法都是基于捕获的静态场景[6],这些方法不能处理由突然运动引起的模糊,并且通常会产生显著伪影。
为了解决这些问题,文献[7]采用分割去模糊算法对视频模糊进行处理,但该算法需要精确的目标分割来进行核估计。文献[8]采用运动变换去模糊算法对视频模糊进行处理,但该算法在很大程度上取决于是否可以跨帧提取清晰的图像补丁进行恢复。文献[9]使用双向光流来估计像素模糊内核,但去模糊的结果仍然包含包含一些伪影。
本文在统一的框架内同时解决语义分割、光流估计和视频去模糊问题,利用语义分割来考虑遮挡和模糊边缘,以实现精确的光流估计,并提出了像素非线性核(PWNLK)模型来近似视频中的运动轨迹,其中模糊核是在非线性假设下由光流估计得到。研究表明,运动模糊不能简单地用光流来模拟,而光流的非线性假设对视频去模糊具有重要意义。
2 光流的运动模糊模型
视频去模糊的主要问题是从图像中估计像素方式的模糊内核。如图2 所示,光流反映了相邻帧之间像素的移动线性方向,其实质与运动轨迹不同。因此,单一地基于线性假设使用光流模拟运动模糊并不准确。运动模糊轨迹通常呈现平滑性,其形状可以通过二次函数来近似得到。为了模拟运动模糊轨迹t,本文使用以下参数建立PWNLK模型:

其中,f=(u,v)是相邻帧的光流估计,a,b 和c 是所要确定的参数。运动模糊轨迹可以用PWNLK模型很好地近似。将帧i 的像素x 处的每个核ki(x)参数化为双向光流的二次函数[10]:

利用模糊核ki的参数化形式,则模糊帧yi可以表示为

其中,li表示第i 个潜在帧,ε 表示噪声。基于模糊帧模型(3),本文提出了一种有效的视频去模糊方法,并对算法进行了详细的分析。
3 视频去模糊模型
基于PWNLK 模型(1),模糊帧模型(3)和标准的最大后验框架[11],本文的视频去模型定义为
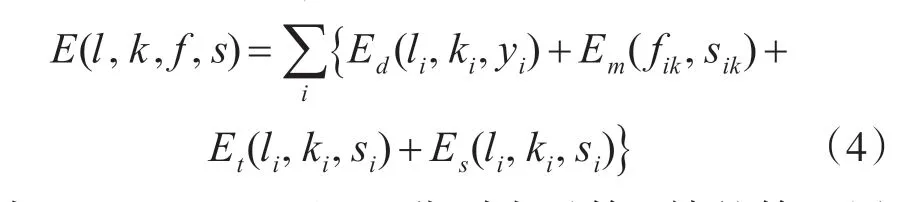
其中,fik=(uik,vik)和sik分别表示第i 帧的第k 层中的光流和分割。 Ed表示数据保真度项,即去模糊帧li应该与观察帧yi一致。 Em表示编码两个假设的运动项。首先,如果相邻像素属于相同的语义分割层,则它们应具有相似的运动。其次,来自每个层k 的像素应该共享全局运动模型f(θik),其中θik随时间变化并且取决于每个层k 的参数。 Et表示时间正则化项,用于确保相邻帧之间的亮度恒定。Es表示伪影和光流的空间正则化项。
3.1 基于PWNLK模型的数据项
文献[11]表明,在数据保真度项中使用伪影和模糊图像的梯度可以减少环形伪影。因此,本文的数据保真度项定义为

当根据式(1)中的运动模糊轨迹计算模糊核ki时,数据保真度项(5)涉及参数a,b 和c。为了获得稳定的解,本文需要调整这些运动模糊参数。Tikhonov 正则化在图像去模糊中已经得到了广泛的应用[6],然而运动模糊具有与光流类似的属性。例如,如果估计的光流具有可分割特性,则估计的运动模糊将具有相同的属性。即如果某些区域∇fi=0,则可以得到∇(aif2i +bifi+ci)=0。基于这个假设,可以得到bi=-2aifi。当∇fi=0 时,fi应为常数C 。利用此属性可对参数a 和b 使用以下正则化:

其中,β 和γ 表示正则化项中每个项的权重。
3.2 运动项
运动项应满足以下两个条件:1)像素的相同分割层sik应共享全局运动模型f(θik);2)相同分割层sik中的相邻像素应具有相似的光流。因此,本文的运动项定义为

其中,Nx表示像素x 的四个最近邻居,ρaff表示鲁棒惩罚函数,其强制相同分割中的像素具有相同的仿射运动模型。此外,δ(*)表示指示函数,即如果表达式为真,则等于1,否则,等于0。
3.3 空间正则化项
空间正则化项旨在缓解不适定的逆问题。本文假设空间正则化项应满足以下两个条件:1)约束具有相同颜色的像素使其位于相同的分割层sik内;2)在潜在帧和光流中增强空间相关性。根据这些假设,空间正则化项的定义如下:

其中,权重gi(x)表示边缘图[10],以保持边缘处光流的不连续性。此外,ωx,r是x 和r 之间相似性的权重。类似于光流估计方法[6],本文将其定义为

其中,σ 为常数。对于给定的像素x,如果知道其他相邻的像素r 具有与x 相似的颜色,则将它们设置为相同的分割。
3.4 时间正则化项
人类视觉系统对视频中出现的时间不一致很敏感。为了提高时间相关性,首先利用光流在局部时间窗口[i-N,i+N]中找到相邻帧之间的对应像素,并确保对应像素平稳变化。强制相邻帧之间的对应像素应该属于同一分割。因此,时间相关的定义是:

其中,n 表示第i 帧相邻图像的索引,μn是正则化项的权重。此外,x'=x+fi,i+n是根据运动fi,i+n的下一个第n 帧的对应像素。本文使用式(10)中的L1范数正则化对异常值和遮挡进行鲁棒估计[10]。
4 模型的算法求解
在上述分析的基础上,得到了所提出的视频去模糊模型。虽然目标函数是非凸的多变量函数,但可以使用交替最小化方法[10]来求解。
4.1 潜在帧估计
利用光流f 、分割s 和参数a,b 和c,对li进行问题优化:

与文献[10]类似,本文使用原始对偶更新方法优化潜在帧子问题式(11)。
4.2 语义分割
语义分割估计可以通过求解如下公式实现:

本文使用文献[12]中的方法优化式(12)。语义分割区域为运动模糊目标提供了潜在光流信息,其主要用于引导光流估计,而不是直接在每个分割上去模糊。
4.3 光流估计
在得到l 和s 之后,关于f 的优化问题可转化为

本文使用文献[10]和文献[13]中的方法求解公式(13)。在得到fi后,利用它来估计基于非线性假设的模糊核,而不是直接用双向光流作为模糊核。
4.4 运动模糊轨迹参数估计
对于每个模糊帧yi,可得到其相应的清晰参考li及其双向光流fi。利用每个图像对和相应的光流,分别求出运动模糊核ai、bi和ci的参数。

这是最小二乘最小化问题,本文分别对参数a、b 和c 的闭式解。
与现有方法类似,本文使用带有图像金字塔[10]的粗糙Tofine方法来实现更好的性能。算法1给出了在图像金字塔基础上进行视频去模糊的主要步骤。
算法1 提出的视频去模糊算法
输入:模糊帧y,占空比τ ,初始化光流f 和语义分割s。
从粗略到精细图像金字塔层级重复以下步骤:
1.通过最小化式(14)求解参数a、b 和c;
2.通过最小化式(13)求解光流f ;
3.通过式(2)求解基于PWNLK模型估计模糊内核k ;
4.通过最小化式(11)求解潜在帧l;
5.通过最小化式(12)求解分割s;
输出:潜在帧l,模糊核k ,光流f 和分割s
5 实验结果
本文首先分析并展示了语义分割和PWNLK模型的结果。然后在合成视频和现实世界模糊视频上评估所提出的算法。本文将所提出的算法与基于运动变换[14]、均匀核[15]、分割核[16]和像素线性核[10]的方法进行比较。
在所有实验中,本文设定参数λ=μn=250 ,β=γ=0.5λ,σ=7,N=2。将二次双向光流的参数初始化为a=c=0,b=1。为了进行公平比较,本文使用基于TV-L1的方法[17]初始化光流,具体步骤参照文献[10]所示。本文还使用最先进的语义分割方法[5]对图像进行分割,并根据所提出的算法对结果进行优化。此外,本文还使用文献[10]中的方法估算相机占空比τ。
5.1 PWNLK模型分析
文献[10]直接使用线性双向光流来恢复清晰的图像。由于视频中的运动轨迹不同于光流,因此该方法的效果较差,如图3 所示。图3(a)给出了通过仿射变换生成模糊图像的示例[16]。本文首先通过图3(c)中基于分割核的方法[16]给出了消除模糊的结果。由于分割不准确,大象边界周围存在明显的伪影。如图3(d)所示,实况光流(图3(b))使用像素线性核方法[10]生成的恢复图像含有显着的环形伪影,这表明线性双向光流不能很好地模拟运动模糊。

图3 文献[10]中线性假设的局限性
图4 给出了能够证明PWNLK 模型有效性的示例。本文使用相同的光流来估计像素方式的线性和非线性核。其中,每个像素的运动模糊的线性假设在实际图像中不成立,如图4(a)所示。对放大区域采用线性近似的运动模糊核估计几乎呈现直线,相应的去模糊结果在字母D 的直线上含有失真伪影,通过所提出的非线性近似方法估计的运动核的轨迹与实际运动模糊轨迹很好地吻合,相应的去模糊图像更清晰且伪影更少,如图4(b)所示。这表明所提出的模糊模型(1)能较好地近似真实场景中的运动轨迹。

图4 PWNLK分析
5.2 语义分割分析
语义分割以多种方式改进视频去模糊,这是因为它可用于估计模糊核的光流。首先,语义分割可提供有关目标边界的区域信息。其次,当不同目标的移动方式不同,语义分割可用于约束每个区域的光流估计。如图5(b)所示,当不使用语义分割时,估计的光流在自行车周围被过度平滑。因此,背景和道路区域的模糊结果被过度平滑。相比之下,所提出的算法的语义分割结果能够很好地描述边界,并且有助于生成准确的光流。如图5(f)所示,所提出的算法的去模糊图像清晰,且具有细分割效果。

图5 语义分割对去模糊的影响
此外,本文还进行了更多的实验来检验语义分割对光流估计的影响。尽管如图6(a)所示初始化的分割不准确,但所提出的算法可以精确地分割运动物体,如图6(b)所示,并且可为光流估计提供更准确的运动边界信息,从而有助于视频去模糊处理。

图6 语义分割的定性分析
5.3 真实数据集
本文根据文献[18,20]中关于真实序列的视频去模糊方法[14,18~20]与所提出的算法进行对比分析。首先将提出的算法与文献[14]提出的基于变换的方法进行比较。如图7(b)的第一列所示,基于变换的方法不能恢复移动自行车的模糊,这是由于物体运动较大并且附近的帧中没有清晰的图像。相比之下,所提出的算法能够处理移动物体造成的模糊,并生成清晰的图像,如图7(c)的第一列所示。基于变换的方法不能处理大型摄像机捕捉的运动模糊,如图7(b)第二列所示。这是由于这种基于转换的方法引入了不正确的补丁匹配(如果没有清晰的图像或可用补丁),因此,书本序列的恢复文本包含了显著的失真伪影。相比之下,基于估计光流的方法不需要清晰的图像或补丁,并且模糊的结果在视觉上更达到清晰分辨,尤其是对于文本。
本文将所提出的算法与基于均匀核的多图像去模糊方法进行比较[15],如图8 所示。在街道序列中,通过所提出的算法可以从去模糊图像中清晰地识别出标志牌和窗户的结构,而基于多图像的方法不能恢复这些细节。此外,所提出的算法可以恢复婴儿序列中清晰的边缘和细节。然而,基于多图像的去模糊方法不能生成清晰的图像。这是由于基于多图像的方法估计出的均匀核不考虑具有非均匀模糊的复杂场景。同时,这种多图像去模糊方法的去模糊结果取决于相邻帧的对齐是否准确。

图7 与基于变换方法的比较

图8 基于均匀核方法的比较
所提出的方法与基于分割的视频去模糊方法[16]的去模糊结果,如图9 所示。虽然基于分割的去模糊方法生成的图像很清晰,但由于分割不准确,在图像边界周围仍然包含一些失真伪像,如图9(b)中右下角的杂志边界。相比之下,图9(c)中的去模糊图像表明,所提出的方法能够恢复杂志的清晰边缘。此外,文献[16]在单词“NEW”处的恢复与所提出的算法生成的结果相比更加模糊。

图9 基于分割的视频去模糊方法比较
所提出的方法与文献[10]提出的基于像素线性核的视频去模糊方法进行比较,如图10 所示。基于像素线性核的去模糊结果包含模糊的边缘和失真伪影,如图10(b)所示。例如,由于内核估计不准确,图10(b)第二列的指示牌左下角有失真伪影。相比之下,由于所提出的运动模糊模型能够近似真实的运动模糊轨迹,恢复的图像包含了精细的细节。其中,在图10(c)中,利用所提出的算法,第一列和第二列中的去模糊字母更加清晰。

图10 基于像素线性核的视频去模糊方法比较
最后分析是否使用PWNLK模型和语义分割的去模糊结果,并与基于变换[14]、基于像素线性核[10]和基于深度学习[18]的视频去模糊方法进行比较,如图11 所示。基于变换的视频去模糊方法[14]不能生成如图11(c)和图11(e)所示的清晰图像。基于像素线性核方法[10]可以生成清晰的图像,但道路区域被过于平滑,如图11(d)所示。在图11(f)中,道路区域可成功恢复,但由于内核估计不完善,轮胎周围存在一些视觉伪影。图11(g)给出了不执行语义分割的模糊结果。虽然轮胎去模糊效果较好,但道路区域被过于平滑。与图11(h)中的图像相比,图11(f)和图11(g)的视觉质量较低,这说明了所提出的PWNLK模型(1)和语义分割正则化的重要性。


图11 是否使用PWNLK模型和语义分割的去模糊结果
5.4 局限性分析
当输入视频包含显著的模糊以及错误的初始分割时,所提出的算法表现不佳,如图12 所示。图12(c)和图12(d)分别是图12(a)和图12(b)的连续模糊帧的初始分割结果。由于式(8)和式(10)中假定的空间和时间约束在分割图像中不成立,因此,图12(e)中的最终分割结果不具有任何语义信息。此外,所提出的方法退化为文献[10]中的传统光流估计,并产生类似的去模糊结果,如图12(g)和图12(h)所示。

图12 局限性分析
6 结语
本文利用语义分割和PWNLK模型提出了一种有效的视频去模糊算法。所提出的分割算法将不同的运动模型应用于不同的目标,这可以显著改善光流估计,尤其是在目标边界处。PWNLK 模型基于非线性假设,能够模拟运动模糊与光流之间的关系。此外,本文还分析了传统的基于运动变换、均匀核、分割核和像素线性核无法模拟由相机抖动、物体运动和深度变化的组合而产生的复杂空间变化模糊。在合成视频和真实视频中进行的实验结果表明,所提出的算法在视频去模糊方面优于其他方法。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
开放教育研究(2020年2期)2020-03-31 01:54:14
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
电光与控制(2018年10期)2018-10-13 08:19:00
数学杂志(2018年5期)2018-09-19 08:13:48
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:38
中国铁道科学(2014年6期)2014-06-21 06:35:32
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
