
基于遗传神经网络和舌根癌Radiomics 特征的生存期预测∗
2019-11-12 06:38:38潘晓英杨清萍
计算机与数字工程 2019年10期
潘晓英 杨清萍
(西安邮电大学 西安 710061)
1 引言
对癌症患者科学准确地预测生存期,不仅是患者及家属关心的问题,也是制定治疗方案的重要依据。长期以来生存期预测的讨论都集中在使用基因组学和蛋白质组学技术。它们需要活检的侵入式手术取出一小部分肿瘤的组织进行分析[1]。然而,由于肿瘤空间和时间的异质性,活检不能全面评估肿瘤的信息,而且病人很难承受连续多次的活检[2]。医学影像可以无创地提供整个肿瘤的信息,并且借助图像分析监测疾病的发生、发展及对治疗的反应[3]。因此医学影像在指导治疗上有很大的潜力,从医学影像出发可以为癌症的生存期预测提供一种新的方法。
影像组学(Radiomics)是一个新兴领域[4],是从医学图像中提取定量影像学特征并进行分析,找到疾病的影像学标识物,从而实现对疾病的精准预测、诊断及预后评估等[5]。Radiomics方法的应用在于追求个体化的精准医疗,在尽早时间内给患者做出一个正确的疾病预测,并提出治疗方案。
本文针对舌根癌的Radiomics 特征数据,提出了人工神经网络生存期预测模型,同时为了解决BP 神经网络权值和阈值受初始值影响大、收敛速度慢、有局部极小点等缺点,本文运用遗传算法对神经网络的权值和阈值进行优化,建立了基于遗传神经网络和舌根癌Radiomics特征的生存期预测模型。
2 数据和特征提取
2.1 数据的选择
本文的研究数据是来自美国经过10 年收集的59例舌根癌患者的Radiomics特征数据以及相对应患者的生存期。其中男性48例,女性11例;发病年龄22~89 岁,中位发病年龄56 岁。Radiomics 特征可以分为强度特征、形状特征、纹理特征、小波特征四个方面,一共有1386维。
2.2 特征提取
Radiomics 特征数据一共有1386 维,然而患者仅有59 例。如果直接用这组数据构建模型,一方面既耗时又浪费空间资源,另一方面由于特征维度过高研究数组过少极容易照成过拟合,所以必须对Radiomics 特征数据进行降维。分析Radiomics 特征数据发现,强度、形状、纹理、小波特征又可分为熵、体积、集群趋势、群阴、集群突出、自相关等22个种类,而每个种类又包含若干个特征,比较同一种类的若干特征可以发现,这些特征的特征值很接近仅有细微的变化,故同一种类的数据可以用主成分分析进行降维。
主 成 分 分 析(Principal Component Analysis,PCA),又称主分量分析,是将多个变量通过线性变换选出几个重要变量的一种多元统计方法[6]。其基本方法就是通过降维技术将原来具有一定相关性的变量,根据贡献大小,重新组合成一组新的且相互独立的、少数几个能充分反映母体信息的综合指标以替代原来的指标,进而在保证主要信息的前提下,以避开变量之间线性相关,以便于进一步分析。
假设有n 个样本,每个样本有p 个数据,则构成原始数据矩阵Xn×p,主成分分析步骤如下:
1)原始数据标准化
为消除原变量的量纲不同,数值差异太大带来的影响,首先对原始数据进行标准化处理,即

式中,i=1,2,…n;j=1,2,…p。
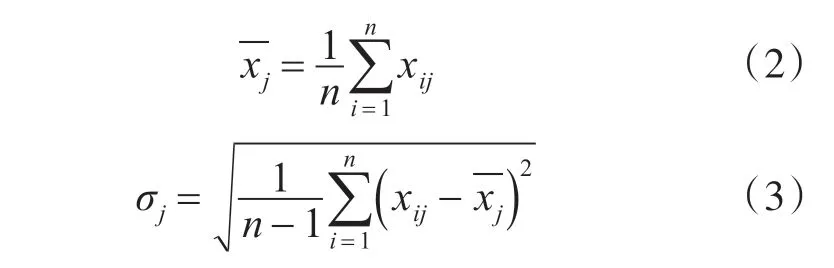
2)建立相关矩阵R,并计算特征值和特征向量

式中,Y 为标准化后的数据矩阵。求得R 的特征值 为 λ1≥λ2≥…≥λp及 相 应 的 特 征 向 量 为αi=( αi1,αi2,…,αip)T,i=1,2,…,p。
3)计算方差贡献率βk和累积方差贡献率β( k)

4)求出主成分Z=Yα
若∀α ∈( 0,1) ,且当β( s )≥α,则Z1,Z2,…Zs为样本X1,X2,…XP的显著水平为α 的主成分。其中β( s )为第s 个主成分累贡献率。 β( s )根据实际问题确定,一般选取80%以上。在本文中由于种类较多,故贡献率应该取高一些,本文取95%。Radiomics特征经降维之后变成200维。
3 遗传神经网络建模
3.1 BP神经网络建模
多层BP神经网络可以实现任意的线性和非线性函数的映射,克服感知器和线性神经网络的局限性,但是在训练过程中容易陷入局部最小点,且对于BP 神经网络而言,其搜索空间为整个网络结构中的极小子空间,并且无法准确确定神经网络隐层的神经元数,建立BP神经网络时容易形成网络“欠适配”和“过适配”的情况[7]。
BP 人工神经网络模型的基本结构[8]:

式中:Y 为BP 网络的输出向量;purelin 为隐层到输出层之间的传递函数;IW1、LW2分别为输入层到隐层、隐层到输出层的网络连接权值;B1、B2分别为输入层到隐层、隐层到输出层的网络连接阈值;Pn为BP 网络的输入向量;Tansig 为输入层到隐层之间的传递函数。
输入层和输出层之间的激活函数采用Sigmoid 函数,其形式为

隐层节点和输出层节点的连接函数采用线性函数(purelin)。
BP 神经网络虽然具有很强的非线性映射能力,但是网络的连接权值及阈值很大程度依赖于初始权值和初始阈值,初始权值的优劣直接影响模型的预测精度。而遗传算法参考自然选择和遗传机制,具有强大的全面优化性,能容易得到全局最优解,可以通过引入遗传算法来对BP 神经网络的权值和阈值进行优化改进。
3.2 遗传神经网络建模
3.2.1 遗传算法
遗传算法是一种新的全局优化搜索算法,其基本思想是基于Datwin 的进化论和Mendel 的遗传学说[9~11]。该方法鲁棒性强,适用于并行处理,广泛应用于计算机科学、运输问题、优化调度、组合优化等领域。
GA算法可以形式化描述如下:

式中:O(0)=a1( 0),a2( 0),…,aN( 0 ))∈IN,为初始种群;I=B1={0,1}为L 的二进制串全体;N 为种群中含有的染色体个数;L 为二进制串的长度;s:IN→IN表示选择策略;g 表示遗传算子,通常包括繁殖算子Qr:I →I ,杂交算子Qc:I×I →I×I 和变异算子Qm:I →I ;p 表示遗传算子的操作概率,包括繁数;殖t概:I率N→pc{ 和0,变1}异为概终率止准pm则;。f:I →R+代表适应函
3.2.2 神经网络拓扑结构
网络的泛化能力是指经样本学习后的网络对学习样本外的数据做出正确反应的能力。影响网络泛化能力的主要因素为网络的拓扑结构、单元结点间的连接权值和训练样本的预处理。这3 个因素对于所建立的BP神经网络模型是判定其网络优劣性的主要标准,根据指导原则,最好的选择位能与给定样本符合的最简单(规模最小)的网络是最好的选择,即为逼近一个连续函数,只有一个隐层的网络已足够。选用单隐层前馈神经网络结构,运用VC维确定隐层神经元数,VC维可以测试系统复杂度对学习能力的影响[12~13]。设定VC 维的维度d为

如果用m 个样本进行训练,其泛化误差以很高的置信度小于e 。其中e 满足:e ≤O((d n)⋅ln(m d)),M、N、P 分别为输入层、隐层、输出层的神经元数。M 和P 为已知,可在样本数目允许的范围内改变m,并取不同的N 值,N 的取值范围可根据下式[14]:

式中a 为1~20之间的常数。
通过选择合适的m 和N 值以使得e 尽可能小,使得获得最优网络拓扑结构和最适合该网络的训练样本数目m。
3.2.3 遗传神经网络算法
应用遗传优化BP神经网络,对BP 神经网络的初始权值和阈值进行优化,通过遗传和变异操作使得网络的权值和阈值不断更新换代,使得网络的系统总误差(Sum Square Error,SSE)趋于最小[15]。遗传算法优化BP网络的步骤如下(图1):
1)种群初始化
个体包含了整个BP 神经网络的所有权值和阈值。本文对个体采用实数编码的方式进行编码。编码长度为

其中,m 为隐含层节点数;n 为输入层节点数;l 为输出层节点数。
2)适应度函数
根据个体得到BP 神经网络的初始权值和阈值,用训练数据训练BP神经网络后预测系统输出,把预测输出和期望输出之间的误差绝对值和E 作为个体适应度值F ,计算公式为
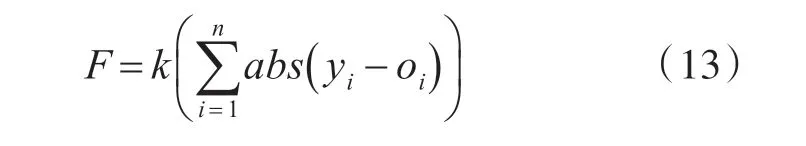
式中,n 为网络输出节点数;yi为BP 神经网络第i个节点的期望输出;oi为i 节点的预测输出;k 为系数。
3)选择操作
个体的选择可以使用轮盘赌法,即基于适应度比例的选择策略,每个个体i 的选择概率pi为

式中,Fi为个体i 的适应度值,由于适应度越小越好,所以在个体选择前对适应度值求倒数;k 为系数;N 为种群个体数目。
4)交叉操作
由于个体采用实数编码,所以交叉操作方法采用实数交叉方法,第k 个染色体ak和第l 个染色体al在j 为的交叉操作:

式中,b 是[0 ,1] 间的随机数。
5)变异操作
选取第i 个个体的第j 个基因aij进行变异,变异操作如下:
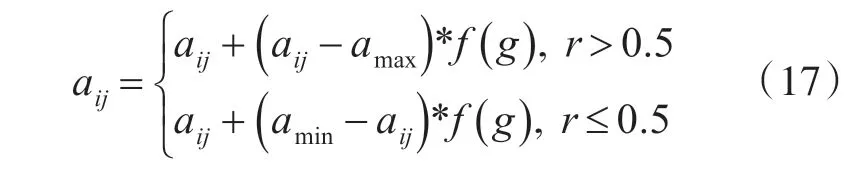
式中,amax为基因aij的上界;amin为基因aij的下界为一个随机数;g 为当前迭代次数;Gmax为最大进化次数;r 为[0 ,1] 间的随机数。

图1 遗传算法优化BP网络流程图
4 仿真结果
采用Matlab R 2010b 编制程序,利用Matlab 神经网络工具箱实现网络预测模型的构建、训练和仿真。BP 神经网络参数:本文采用3 层BP 神经网络结构,输入节点个数为200,输出节点个数为1,隐含层节点为30,隐含层传递函数为S 型函数tansig ,输出层函数为 purelin ,训练函数为traingdx 函数,性能函数为mse 函数。最大训练次数为1000 次,学习速率为0.01,目标误差为0.00004。遗传算法参数:种群规模为10,进化次数50 次,交叉概率0.8,变异概率为0.2。将经主成分分析降维后的特征数据中的47 例(80%)用于构建预测模型的训练集,12例(20%)用于测试集。各模型预测结果如表1。

表1 三种模型预测结果比较
从表1 中我们可以看出,三种预测模型中,逻辑回归预测结果最差,有两个异常预测值,预测值相对实际值有较大误差,BP 神经网络比逻辑回归预测结果稍有改进,仅有一个异常预测值,预测值相对实际值偏差减小,BP 神经网络预测值相较于逻辑回归预测值更加稳定,但由于BP 神经网络训练方法简单还是产生了稍大的偏差,遗传神经网络预测结果最好,预测结果最为稳定,没有异常预测值,预测值相对于实际值最接近。从相对误差来分析,逻辑回归预测产生了比较大的误差,而BP神经网络对比逻辑回归误差减小,但还是误差还是稍大,而遗传神经网络由于其方法的先进性相较于其他预测方法误差大大减小。
5 结语
我们证明了癌症Radiomic 特征数据在神经网络模型中的应用。对于高维小样本特征遗传神经网络能够更好地预测生存期。肿瘤的综合性防治规划包含4 个方面:预防、早期诊断、根治性治疗和姑息性治疗,确定预后特性可以设计出适合的个性化治疗方式,尽可能地改善临床结果。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
人民珠江(2019年4期)2019-04-20 02:32:00
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
自动化学报(2017年7期)2017-04-18 13:41:02
统计与决策(2017年2期)2017-03-20 15:25:24
智能系统学报(2015年4期)2015-12-27 09:38:39
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
