
基于多尺度残差网络的CT图像超分辨率重建
2019-11-11 08:11:04吕国强盛杰超冯奇斌
液晶与显示 2019年10期
吴 磊,吕国强,赵 晨,盛杰超,冯奇斌
(1.合肥工业大学 特种显示技术国家工程实验室 现代显示技术省部共建国家重点实验室 光电技术研究院,安徽 合肥 230009;2.合肥工业大学 电子科学与应用物理学院,安徽 合肥 230009;3.合肥工业大学 仪器科学与光电工程学院, 安徽 合肥 230009)
1 引 言
医疗影像技术如CT、MRI和X射线等是医生获取病人信息的常用途径,高分辨率(High Resolution, HR)的医疗影像可以使医生更精确地识别病变部位,因此它的清晰度直接影响医生对病人诊断的准确度,但是由于现有医疗成像技术的局限性以及图像采集设备的固有限制,往往无法给医生提供理想的高分辨率医学图像[1]。超分辨率(Super Resolution, SR)重建技术[2-3]就是仅从计算机算法层面入手,将图像采集设备获取到的低分辨率(Low Resolution, LR)图像提升为高分辨率图像的方法,因此采用超分辨率重建技术提高医学图像的分辨率对医学诊断具有重要意义。
近年来学者们在自然图像上的超分辨率研究取得了诸多成果,开发了一系列的重建算法,按照算法的基本思想,目前超分辨率重建技术可以分为基于插值[4-5]、基于重建[6]和基于学习[7-8]的方法。基于插值的方法一般是通过基函数估计相邻像素点之间的连接像素,来填充高分辨率图像中的未知点。该方法虽然高效直观,但无法保证估计像素的精度,因此其重建图像往往存在伪影、模糊等问题;基于重建的方法一般是根据信号处理理论,以LR图像为约束条件,利用图像的先验信息估计HR图像,但是由于先验信息的不足,该类方法重建的HR图像往往也存在细节缺失等问题。 为了突破前两种方法的局限性,相关学者将学习的思想引入了SR领域,基于实例学习[9]、基于稀疏编码[10]以及固定邻域回归[7]等SR算法相继被提出,将图像的SR质量又提升了一个层次。2016年,Dong等人[11]率先开始了卷积神经网络在图像SR领域的应用研究,提出了基于卷积神经网络的图像超分辨率方法(SRCNN),SRCNN采用3个卷积层分别对图像进行特征提取、非线性映射以及图像重建等操作,得到了明显优于传统算法的重建效果。为了加快重建速度,Dong等人[12]又将反卷积与原算法进行结合,提出了基于反卷积的快速图像超分辨率重建(FSRCNN)。随着研究的深入,学者们发现深层网络可以取得较好的超分辨率效果,但是层数的加深往往会导致网络梯度弥散或梯度爆炸等问题,使其无法收敛。由此,文献[13]借鉴残差网络(ResNet)的思想,利用深层残差网络加速网络学习,提出了基于深度卷积神经网络的超分辨率重建算法(VDSR)。
虽然上述基于学习的算法在自然图像上取得了较好的超分辨率效果,但是应用于CT图像仍然存在一些问题:VDSR的单一尺度网络结构无法充分提取CT图像的主要特征;仅有3层网络的SRCNN恢复出的CT图像清晰度不足,且其算法复杂度较高,无法满足医学图像对处理速度的需求;FSRCNN虽然进行了改进,但其网络深度仍然不够提取医学图像的细节信息,同时一个网络只能应用于一种放大倍数更限制了上述两种算法在医疗影像领域的应用。
针对以上问题,本文从CT图像特征出发,结合残差学习思想,提出了基于多尺度残差网络的SR重建算法,通过搭建多尺度网络模型,更充分地提取了低分辨率CT图像的各种特征,引入残差学习的同时相应采取Adam优化算法[14]加快了模型的收敛,同时训练前期在多种放大倍数下处理训练集,使得本文模型能够同时支持多种倍数的分辨率提升。
2 本文算法
2.1 网络结构
针对CT图像独有特征,结合残差学习思想,提出了基于多尺度全局残差网络的SR重建模型,网络结构如图1所示。该模型由11层多尺度残差块级联而成,每层残差块包含一组3种尺度的卷积核。网络运算前期,采用双三次插值算法先将原始低分辨率CT图像插值放大到目标分辨率,再将放大后的图像输入到网络中,逐一经过每个残差块进行特征提取、融合、映射以及全局残差学习,最终将学习到的残差图像与输入的低分辨率图像融合,输出高分辨率的CT图像。

图1 本文网络结构图Fig.1 Network structure diagram of our algorithm
2.2 多尺度残差块
在现有的超分辨率重建算法中,研究人员通常只在一个维度上提取低分辨率图像的细节特征,但CT图像特征复杂、结构多样,单一的提取尺度往往会忽略掉其部分纹理信息,导致网络无法恢复足够清晰的高分辨率图像,因此本文在VDSR算法的基础上对其单一的深层网络进行改进,构造了多尺度卷积的残差块,结构如图2所示,最终通过级联多层残差块的方式搭建了全局残差学习的网络模型。
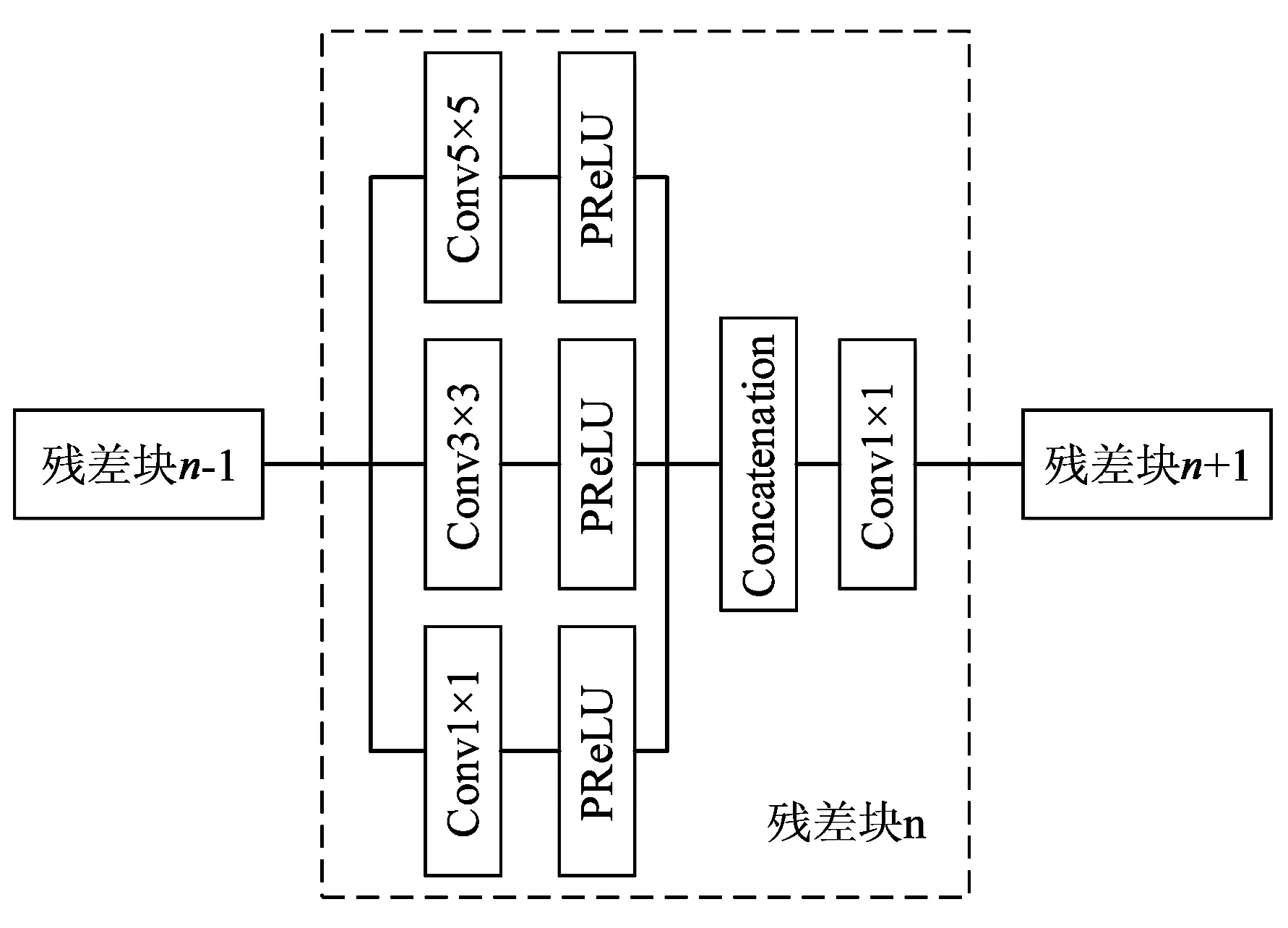
图2 多尺度残差块结构图Fig.2 Structure diagram of multi-scale residual block
该残差块主要采用1×1,3×3,5×5的3种尺度卷积核对低分辨率CT图像进行特征提取,每种尺度的卷积核对应生成16,64,16幅卷积特征图,然后采用Concatenation操作将上述特征图合并,在一个维度上进行重组。为了降低算法复杂度,同时提高网络的训练速度,采用1×1×16的卷积核对合并后的多尺度特征信息进行特征映射及数据降维,最终将该残差块提取到的多尺度特征信息输出到下一残差块。为了保证多尺度特征提取的有效性,我们在特征提取层后设置了激活层,激活函数选用PReLU。残差块的计算公式表示如下:
(1)
(2)
φ(x)=max(ax,x),
(3)

由于池化操作降低了图像的分辨率,与恢复高分辨率医学影像的目的相悖,因此本文网络不设置池化层。同时为了充分保留CT图像的边缘信息,我们在卷积计算前统一对图像进行边界零填充,从而固定输出图像的尺寸。
3 实验设置及结果分析
3.1 实验设置
3.1.1 实验环境
算法测试所用计算机CPU为Intel Core i7-3770U@3.40 GHz,同时搭载了NVIDIA GeForce GTX 1060 GPU,配置16GB内存,软件环境有64位的Windows 7操作系统、Matlab R2016a、CUDA Tookit 8.0、Cudnn 5.0和caffe框架模型。
3.1.2 数据集
所用数据集全部来自于癌症影像档案(The Cancer Imaging Archive, TCIA)网站公开的医学影像资料,该网站包含CT、MRI和X射线等各类医学图像,选用CT图像作为本次实验测试的主要图像。根据不同病患情况,我们下载了TCGA-ESCA食道癌、TCGA-STAD胃腺癌和TCGA-COAD结肠腺癌等系列的CT图像数据集,分别如图3所示。
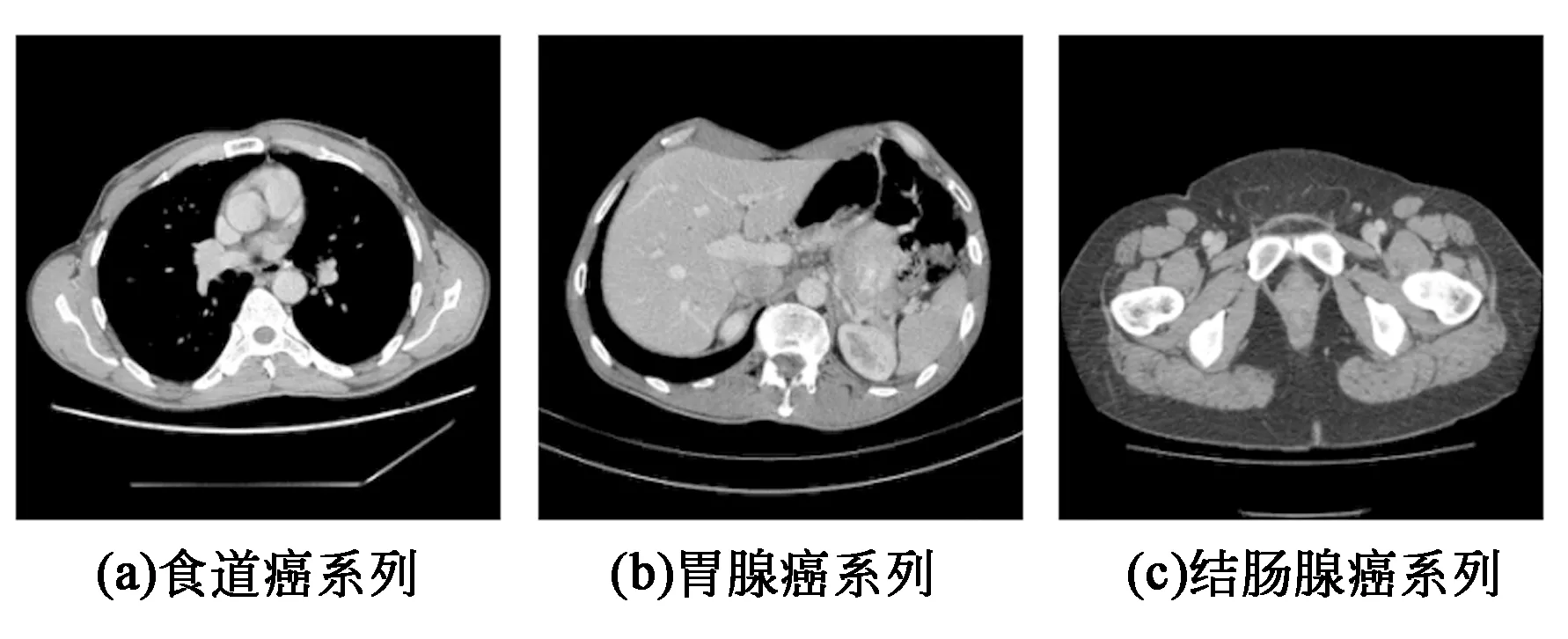
图3 数据集示例Fig.3 Dataset example
从3个系列数据集中分别选取200幅作为网络模型的训练集;再从每个系列剩下的图像中随机选取20幅,共计60幅,组成验证集;测试集则随机从每个系列中选取5幅图像,打乱后均分成3组,组成3个测试集。由于人眼对图像亮度分量最为敏感,因此以下操作只在图像亮度分量上进行。对训练集中的600幅高分辨率CT图像先进行多倍数的下采样处理,为了便于实验测试,分别做了2,3,4倍的下采样处理,接着采用双三次插值算法将下采样后的图像插值到目标分辨率,然后再将放大后的低分辨率图像不重叠地裁剪成41×41像素大小的图像块,以此增大网络的感受野,同时按照相同的方式对高分辨率CT图像进行裁剪,最后将图像块对应组成高低分辨率数据对,送入网络进行训练。
3.1.3 参数设置
网络训练阶段使用Adam算法优化模型参数,该算法可以依据损失函数针对参数的梯度一阶矩估计和二阶矩估计动态改变对应的学习速率,从而加速网络模型的收敛。用公式可表示为:
st=ρ1st-1+(1-ρ1)gt,
(4)
rt=ρ2rt-1+(1-ρ2)gtgt,
(5)
(6)

网络训练过程中动态调整学习率,也可以加速模型的收敛。首先采用高斯法初始化网络权重,动量和权值衰减分别固定为0.9和0.000 1,然后采用较大基础学习率0.01,使模型尽快找到收敛方向,一段时间训练后观察损失函数,当损失函数趋于平稳时,降低学习率继续训练,如此循环,直到学习率降至0.000 1时,模型基本收敛。
3.2 实验结果
3.2.1 客观评价标准
为了更客观地描述不同算法的效果差异,采用通用的图像质量评价标准:峰值信噪比(Peak Signal to Noise Ratio, PSNR)和结构相似性(Structural Similarity Index, SSIM)对每个算法恢复的高分辨率医学图像进行质量评价[15]。
PSNR是根据两幅图像对应像素点间的误差对图像质量进行评价的方法,其值越高表明输出图像的失真越少,图像重建质量越好。SSIM是对比两幅图像相似度的评价标准,其值越接近于1表示重建图像越接近于原始的高分辨率图像。它们的计算公式分别如下所示:
(7)
式中:KMSE表示均方误差,n为图像色彩位数,这里为8。
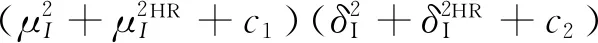
(8)
c1=(k1L)2,c2=(k2L)2,
(9)

3.2.2 结果对比与分析
在上述两种客观评价标准下,利用构造好的3个测试集分别对所搭建的网络模型进行实验测试,并将测试结果与Bicubic、SRCNN[11]、FSRCNN[12]以及VDSR[13]等主流算法在2,3,4等放大倍数下进行对比,PSNR和SSIM数据对比如表1和表2所示,表中的数据是每个测试集的所有图像分别经过对应算法处理后的平均值,加粗的数据为最优结果。综合分析表1、表2可以看出,与传统的双三次插值算法相比,所提模型重建的CT图像质量大幅提升,每个测试集的PSNR结果平均提升都在5 dB以上。与基于深度学习的SR先进算法相比,本文算法同样取得了较好的成绩,测试集2的PSNR数据相较VDSR和FSRCNN算法平均提升了1.01 dB和2.21 dB,测试集3的SSIM数据相较SRCNN算法平均提升了0.006。

表1 PSNR数据对比Tab.1 Comparison of PSNR data

表2 SSIM数据对比
为了更直观地对比不同算法的重建效果,图4至图6分别给出了不同算法在2,3,4放大倍数下的重建图像,测试图像分别选自3个测试集。由效果图可以看出传统的双三次插值算法重建结果最不清晰;SRCNN和FSRCNN的处理效果虽然有了一定提升,但在CT图像的纹理区域仍有不足,且有伪影现象出现;VDSR算法虽然在肉眼上与我们的算法看不出多大差距,但从客观数据及网络的尺度结构对比,本文算法仍略胜一筹。因此综合对比上述5种算法,所提模型能够更准确全面地提取低分辨率CT图像的原始特征,更清晰锐利地重建其细节纹理,同时重建的图像边缘信息有很好的连续性,并且没有出现伪影现象。

图4 2倍放大倍数下测试集1中图像的主观效果对比Fig.4 Comparison of subjective effects of images in test set one at two times magnification

图5 3倍放大倍数下测试集2中图像的主观效果对比Fig.5 Comparison of subjective effects of images in test set two at three times magnification

图6 4倍放大倍数下测试集3中图像的主观效果对比Fig.6 Comparison of subjective effects of images in test set 3 at four times magnification
4 结 论
本文提出了一种用于CT图像超分辨率重建的网络模型,用以解决现有模型网络结构单一以及实用性低等问题。借鉴残差网络思想,将全局残差学习与多尺度卷积神经网络相结合,构造多尺度残差块,通过级联多层残差块循环学习低分辨率图像的残差特征,最后融合输入重建高分辨率图像。由实验数据分析可知,在3种放大因子下,该模型重建的CT图像PSNR平均较VDSR算法提高了0.87,0.83,1.16 dB。由主观评测可以看出本文模型能够更清晰地恢复CT图像中人体器官的细节纹理,同时支持多倍数的超分辨率重建,提升了算法的实用性。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
雷达学报(2020年3期)2020-07-13 02:27:16
自动化学报(2019年6期)2019-07-23 01:18:32
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
太空探索(2015年8期)2015-07-18 11:04:44
河南科技(2015年8期)2015-03-11 16:23:52
