
基于改进YOLOv3-LITE轻量级神经网络的柑橘识别方法
2019-11-11 06:48吕石磊卢思华洪添胜薛月菊吴奔雷
农业工程学报 2019年17期
吕石磊,卢思华,李 震,洪添胜,2,4,薛月菊,吴奔雷
基于改进YOLOv3-LITE轻量级神经网络的柑橘识别方法
吕石磊1,2,3,卢思华1,李 震1,2,3※,洪添胜1,2,4,薛月菊1,2,3,吴奔雷1
(1. 华南农业大学电子工程学院,广州 510642;2. 国家柑橘产业技术体系机械化研究室,广州 510642;3. 广东省农情信息监测工程技术研究中心,广州 510642;4. 华南农业大学工程学院,广州 510642)
柑橘识别是实现柑橘园果实自动采摘、果树精细化管理以及实现果园产量预测的关键技术环节。为实现自然环境下柑橘果实的快速精准识别,该文提出一种基于改进YOLOv3-LITE轻量级神经网络的柑橘识别方法。在采摘机器人领域,果实识别回归框的准确率直接决定了机器手的采摘成功率,该方法通过引入GIoU边框回归损失函数来提高果实识别回归框准确率;为便于迁移到移动终端,提出一种YOLOv3-LITE轻量级网络模型,使用MobileNet-v2作为模型的骨干网络;使用混合训练与迁移学习结合的预训练方式来提高模型的泛化能力。通过与Faster-RCNN以及SSD模型对比在不同遮挡程度的测试样本下模型的识别效果,用1值与AP值评估各模型的差异,试验结果表明:该文提出的模型识别效果提升显著,对于果实轻度遮挡的数据集,该文提出的柑橘识别模型的1值和AP值分别为95.27%和92.75%,Average IoU为88.65%;在全部测试集上,1值和AP值分别为93.69%和91.13%,Average IoU为87.32%,在GPU上对柑橘目标检测速度可达246帧/s,对单张416×416的图片推断速度为16.9 ms,在CPU上检测速度可达22帧/s,推断速度为80.9 ms,模型占用内存为28 MB。因此,该文提出的柑橘识别方法具有模型占用内存低、识别准确率高及识别速度快等优点,可为柑橘采摘机器人以及柑橘产业产量预测提出新的解决方案,为柑橘产业智能化提供新的思路。
神经网络;果树;算法;柑橘;YOLOv3-LITE;混合训练;迁移学习;GIoU边框回归损失函数
0 引 言
随着农业机械化与信息化的兴起,计算机视觉以及深度学习技术的不断突破,果实识别、机器人自动采摘、果实产量预测是近年来的研究热点[1]。在智慧农业方面[2],人们通过对果实的识别来实现果树的精细化管理。柑橘产业是我国南方水果产业的重要支柱[3],由于我国柑橘果园环境复杂,果实密集度高、叶片遮挡严重,且柑橘果树树冠较低,果实阴影程度较高,为实现柑橘果树的自动采摘,柑橘果实的精准识别研究至关重要。
近年来,针对于自然环境下柑橘目标识别问题,国内外相关文献基于传统机器视觉技术提出了多种解决方法。Hussin等[4]和谢忠红等[5]分别使用圆形Hough变换进行柑橘目标检测,检测精度较低,且在柑橘密集、重叠的情况下,容易导致错误检测。熊俊涛等[6]提出利用K-means聚类分割法结合优化Hough圆拟合方法实现柑橘果实分割,利用直线检测确定柑橘采摘点,但误检率会随目标密集度变化而增加。卢军等[7-9]提出遮挡轮廓恢复的方法进行柑橘识别,利用LBP特征的识别准确率可达82.3%,之后利用水果表面光照分布的分层轮廓特征进行树上绿色柑橘的检测,但在图像采集过程中需要人工采集光源且场景适应性不高。Zhao等[10]提出一种SATD匹配方法对潜在的水果像素点进行检测,使用支持向量机(support vector machine,SVM)进行分类,识别准确率达到83%以上,但该方法随着目标数的增加,检测的复杂度和难度随之增加,从而影响检测精度。Dorj等[11]提出利用颜色特征来预测柑橘产量,首先将RGB图像转换为HSV图像,再对图像进行橙色检测,利用分水岭分割法对柑橘进行计数,但该方法的检测准确率受距离和背景变化的影响较大。Liu等[12]提出一种基于成熟柑橘区域特征的识别方法,利用特征映射表来降低特征向量的维数,但该方法在阴影情况下的识别效果较差。
另外,在传统机器视觉领域,针对苹果、桃子、番茄等常见水果的检测方法也相继被提出。马翠花等[13]提出基于密集和稀疏重构[14](dense and sparse reconstruction,DSR)的未成熟番茄识别方法,识别准确率为77.6%。张春龙等[15]使用基于SVM分类器和阈值分类器的混合分类器来实现近色背景中绿色苹果的识别与计数,平均识别准确率为89.3%,但该方法对单张图片检测时间过长,对重叠果实识别精度较低。Peng等[16]提出利用形状不变矩等方法综合果实的颜色和形状特征,利用SVM分类器对提取的特征向量进行分类识别,但该方法在复杂环境下适用性较低。Wajid等[17]提出基于决策树分类的成熟柑橘、未成熟柑橘识别方法,但受决策树特性影响,该方法的识别准确率稳定性有待进一步提高。以上对不同水果的识别方法主要是基于颜色特征和纹理特征,都受限于自身算法的局限性,无法找到通用的特征提取模型,无法同时识别所有类型的水果,而且受光照以及环境的影响较大,泛化性较差,很难满足实时检测的要求,算法没有得到很好的推广。
由于传统机器视觉方法在复杂场景下鲁棒性差,很难满足采摘机器人在复杂场景下的工作需求。近年来,卷积神经网络[18]在目标检测领域不断完善,体现出巨大的优越性,其主要分为两类,一类是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类,代表有RCNN[19]、Fast RCNN[20]和Faster RCNN[21];一类直接将目标边框定位的问题转化为回归问题处理,不需要产生候选框,标志性算法包括SSD[22]、YOLO[23]等。傅隆生等[24]提出基于卷积神经网络的田间多簇猕猴桃图像识别方法,该方法对相邻果实和独立果实的识别率分别为91.01%和94.78%,但对遮挡、重叠果实识别准确率较低。Sa等[25]和熊俊涛等[26]分别采用Faster R-CNN深度卷积神经网络来识别甜椒和柑橘,但模型训练速度较慢,检测时间较长。彭红星等[27]提出基于SSD深度学习模型对4种不同水果进行识别,平均检测精度可达89.53%,有较好的泛化性和鲁棒性。薛月菊等[28]提出基于YOLOv2[29]的未成熟芒果识别方法,识别速度和识别精度可显著提升。以上研究的开展为卷积神经网络应用于果实识别提供了参考和可行性依据,且能避免传统机器视觉方法中特征提取过程的不足。
该文结合SSD网络以及YOLO系列网络的优点,通过改进YOLOv3网络模型[30],使用一种新的IoU边框回归损失函数,并提出一种混合训练[31]与迁移学习[32]结合的方式将模型在COCO数据集中学习到的知识迁移到柑橘图像识别过程中,提出一种基于GIoU[33]的YOLOv3-LITE轻量级神经网络的柑橘识别方法。在不损失精度的情况下,该方法较传统YOLOv3网络的检测速度提升了近4倍,模型占用内存缩小近8倍。
1 材料与方法
1.1 试验数据的采集
柑橘图像的采集地为广东省梅州市柑橘果园,使用数码相机、高清手机等多种设备拍摄距离1 m左右的自然光照下柑橘树冠图像,拍摄角度朝东南西北4个方向,并采集树冠下方含阴影的果实,共采集原始图片500张,图像包括阴天、晴天、雨天,涵盖顺光、逆光等所有光照情况。为保证柑橘图像数据的多样性,通过网络爬虫获取200张柑橘照片,挑选出120张,所得数据集为620张。
1.2 数据增强
使用Matlab工具对原始数据集进行数据扩增,对原始图像进行旋转,旋转角度随机取-30°、-15°、15°、30°;对原始图像随机进行镜像翻转、水平翻转、垂直翻转;通过裁剪以及缩放等方式进行扩展数据集;通过调整饱和度和色调、直方图均衡化、中值滤波等图像处理技术对数据进行增强。考虑到数据增强会导致图片中图像形状变化以及质量变化较为严重,对每张图片随机采用以上一种方式进行扩增,得到1 240张,筛选出符合试验的数据作为最终的数据集,最终数据集为1 130张。
1.3 数据集准备
将上述数据集使用labelImg工具对检测目标进行标记。考虑标签和数据的对应关系以及确保数据集分布统一,使用Matlab工具将数据集按照70%、10%、20%的比例随机拆分为训练集、验证集、测试集,其中训练集含边框标注样本为7 148个,验证集含边框标注样本为1 006个,测试集含边框标注样本为2 243个。将最终数据集按照PASCAL VOC数据集的格式存储,再将测试集分为2部分:目标平均遮挡程度小于30%的数据集(轻度遮挡,用A表示)、目标平均遮挡程度大于30%且较密集的数据集(重度遮挡,用B表示)。其中,测试集A包含标注样本682个,测试集B包含标注样本1 561个,最终数据集如表1所示。
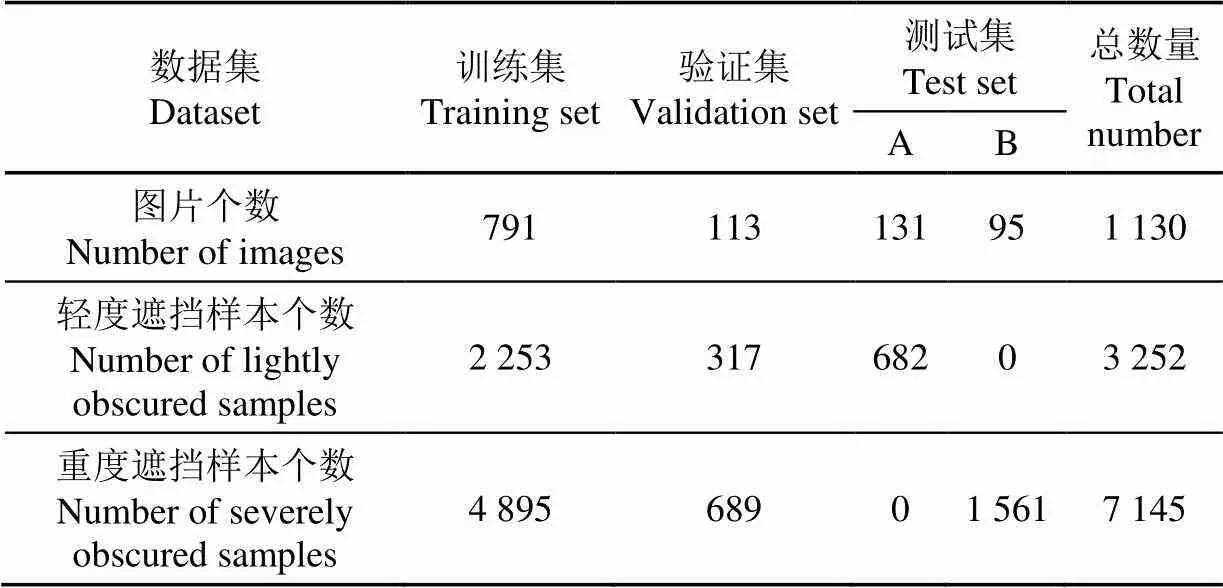
表1 数据集及其数量
2 改进的YOLOv3-LITE柑橘识别网络
2.1 YOLOv3网络模型
YOLO网络模型是一种one-stage的方法,YOLO将输入图像分成S×S个格子,如果一个物体的中心落在某个网格内,则对应的网格负责检测该物体。其中,YOLOv1将输入图像的尺寸改为448×448,然后送入CNN网络训练,采用非极大抑制算法进行预测,YOLOv1对小目标检测效果不好,定位也不够精确。Redmon等[29]提出的YOLOv2吸收了Faster R-CNN中RPN的思想,去掉YOLOv1中的全连接层,加入Anchor Boxes,提高了召回率,且提出k-means聚类计算Anchor Boxes,Average IoU也提升了,但对小目标检测效果一般。YOLOv3在YOLOv2的基础上进行了一些改进,加深了网络,提出了多标签分类预测,使用逻辑回归(logistic regression)对方框置信度进行回归,同时提出了跨尺度预测,使用类似FPN(feature pyramid networks)的融合做法,在多个尺度的特征图上进行位置和类别预测,对小目标的检测效果提升明显。在类别预测中,YOLOv3不使用Softmax函数对每个框分类,而是对每个类别独立地使用逻辑回归,在训练过程中,使用二元交叉熵损失(binary cross-entropy loss)来进行类别预测,可以更好地处理多标签任务。YOLOv3目标检测网络损失函数如式(1)所示。


2.2 改进的YOLOv3-LITE轻量级神经网络模型设计
2.2.1 基于GIoU的边框回归损失函数
IoU为预测框与原来图片中标记框的重合程度,目标检测领域常使用边框回归IoU值作为评价指标。但是,大部分检测框架没有结合该值优化损失函数,IoU可以被反向传播,它可以直接作为目标函数去优化。考虑到优化度量本身与使用替代的损失函数之间的选择,最佳选择是优化度量本身。作为损失函数,传统IoU有两个缺点:如果2个对象不重叠,IoU值将为零,则其梯度将为零,无法优化;2个物体在多个不同方向上重叠,且交叉点水平相同,其IoU将完全相等,IoU无法精确的反映两者的重合度大小,如图1所示,3个不同的方法重叠两个矩形具有完全相同的IoU值,但他们的重合度是不一样的,最左边的图回归的效果最好,最右边的回归效果最差,其中最右边的图预测边框为旋转候选边框[34]。因此,IoU函数的值并不能反映两个对象之间如何发生重叠。在柑橘采摘机器人的果实识别中,回归框位置的精确度直接决定了机器手采摘的成功率。因此,该文提出通过引入GIoU来解决IoU的缺点。IoU取值[0,1],而GIoU有对称区间,取值范围[-1,1],在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1。因此,GIoU是一个非常好的距离度量指标,与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度,GIoU Loss可以替换掉大多数目标检测算法中边框回归的损失函数,如式(2)-(5)所示。
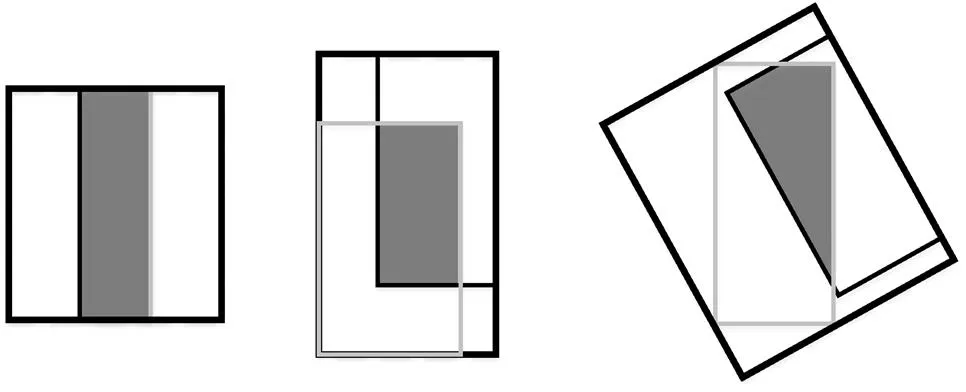
注:黑色矩形代表预测的边界框,灰色矩形代表原始标记的边界框。
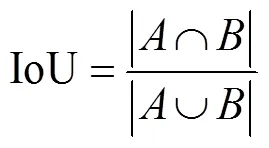

猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
幼儿教育·父母孩子版(2020年6期)2020-07-27
数位时尚(幼儿教育)(2018年10期)2018-10-30
摄影之友(影像视觉)(2018年1期)2018-03-22
摄影之友(影像视觉)(2017年11期)2017-11-27
小雪花·成长指南(2016年9期)2016-10-12
世界热带农业信息(2016年4期)2016-05-03
