
基于深度学习的SAR目标检测方法
2019-11-07 10:46
雷达科学与技术 2019年5期
(长沙理工大学电气与信息工程学院, 湖南长沙 410114)
0 引言
合成孔径雷达(Synthetic Aperture Radar, SAR)有分辨率高、能全天时、全天候实时工作的特点,广泛应用于军事侦察和遥感领域。随着SAR技术不断成熟、成像分辨率不断提高,使得通过SAR图像的目标检测技术[1-2]受到越来越广泛的关注。传统的SAR图像目标检测方法一般由滤波、分割、特征提取等多个相互独立的部分组成,复杂的流程限制了检测的速度,同时多个独立步骤很难整体优化,提升检测精度。
近年来,基于深度卷积神经网络[3]的目标检测算法相比于传统的方法显现出了巨大的优越性,主流的算法主要分为两大类,一类为基于候选区域的two-stage检测方法,该种方法首先通过卷积神经网络产生候选区域(region proposals),然后对候选区域分类和定位,如Faster-RCNN[4]、RFCN[5]等;另一类为基于回归的one-stage方法,在实现目标分类的同时直接对目标画框定位。因此前者精确度较高,后者速度较快。2017年以来,one-stage方法得到迅速发展,残差网络等方法的提出,使其速度不仅有提升,精确度上也比主流的two-stage方法高,如YOLOv3[6]、RetinaNet[7]、SSD[8]等。但上述算法的检测结果都是基于传统光学图像的检测。然而高分辨率SAR图像中不同目标的尺寸区别很大以及目标特征不明显的问题,导致了深度学习卷积神经网络的目标检测算法在SAR图像目标检测上进展缓慢。
本文针对如上问题,基于YOLOv3的研究成果,提出了SAR-YOLO-960检测算法。本方法通过分析城镇和电塔在目标中的尺寸,提出了输入为960×960像素的大图检测模型;手工制作了数据集;采用K-Means[9]方法聚类选取初始候选框;并将YOLOv3的残差网络[10]、批规范化(BN)[11]、多尺度训练与多尺度检测等融入新形成的网络结构,整体采用了64倍降采样,使得其速度不落后于主流的算法,最后基于SAR图像特征改进了损失函数,进一步提升检测精度。
1 数据集生成与预处理
1.1 数据集制作
利用PS软件,手工从原始的10张SAR图像(像素大约为20 000×20 000,分辨率大小约为1 m)中,截取了包含目标的2 308张960×960像素的图像。并利用labellmg工具进行voc数据集格式标注,其中含城镇目标6 374个、电塔目标3 745个。
1.2 数据集增强
在图像的深度学习中,训练样本过少,网络模型容易过拟合。训练样本的增强可提高样本的多样性,提升网络的泛化能力。在制作数据集时考虑到原始图像中电塔朝向性单一、颜色过浅,城镇目标大部分集中在样本正中央。故本文对原始数据集进行了±90o旋转、饱和度、曝光度变化以及向上平移150像素操作。若平移后样本中目标消失,则放弃标注。
经增强后,生成27 696张图像,44 096个电塔,73 418个城镇从中随机挑选19 387张作为训练集,8 309张作为测试集。数据集处理结果如表1所示。

表1 数据集以及数据量
1.3 K-Means聚类候选框
聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。在训练深度学习目标检测网络时,需要设置网络的初始候选框大小以及数量,随着网络的正向传播,在最后,网络通过标签对比候选框与真实框的差距,计算损失,再通过反向传播更新候选框参数,然后网络不断的迭代,最终使得候选框接近真实框。
为了加快网络的收敛速度,提升检测精度,本文采用K-Means算法对训练图像中目标标注框的长与宽进行聚类,得到与图像中目标最接近的初始候选框参数,用来代替传统的初始候选框。候选框(ab,anchor boxes)与真实框(gt,ground truth)所在位置的面积交并比(IOU)是反应差异的重要指标,如式(1)所示,IOU越接近1,表明差异越小。
(1)
综上所述,因此K-Means聚类函数式(2)为
(2)
式中,k为聚类的候选框个数,n为训练样本中真实框个数,ab[k]为对应的候选框规格,gt[n]为对应的真实框规格。通过不断迭代,更新候选框参数,当Smin收敛到最小值时,记录此时的ab[k]规格,用以代替初始候选框规格。其候选框聚类结果如表2所示。

表2 K-Means聚类结果
2 SAR-YOLO-960网络结构
2.1 YOLOv3多尺度检测
YOLOv3目标检测方法是目前最先进的检测方法之一,在检测速度和精确度上都比以往的主流算法SSD,Faster-RCNN等有大幅提升。其分类网络为Darknet-53,由53个卷积层和21个残差层组成。基本结构为残差模块(resnet),用以解决网络的梯度弥散或者梯度爆炸的现象。其中还采用了BN、多尺度训练等方法提升精度和网络的泛化能力。
如图1所示,YOLOv3检测方法采用多尺度检测目标(类FPN[12])。网络首先输入大小为416×416的像素图;然后通过Darknet-53网络,整体进行32倍的降采样;接着通过多层卷积生成13×13大小的第一尺度特征图作检测,该特征图图中每个像素对应原始输入32×32个像素的单元格,若某物体的中心落入该单元格中,则由该单元格中的候选框负责检测目标,该尺寸主要负责检测大目标;紧接着把13×13的深层特征图进行上采样,再与26×26的浅层特征图进行拼接,生成26×26的特征图,使得网络能够更好地获得细粒度特征以提升检测精度,最后进行多次卷积生成26×26的第二尺度特征图,图中每个像素对应原始尺寸16×16个像素的单元格,负责中型目标检测;以上述方法进一步类推,最后生成第三尺度为52×52的特征图负责小型目标检测。

图1 YOLOv3检测流程图
其检测目标原理为:
1) 首先候选框在3种尺度的特征图上分别判别目标存在的置信度conf (object),以及预测单元格中目标的类别概率。其中conf(object)公式(3)如下:
Pr(object)∈{0,1}
(3)

W×H×[B×(X,Y,w,h,conf(object),P)]
W,H表示特征图的长宽,B表示每个单元格中候选框的个数,X,Y为候选框的中心坐标,w,h为候选框的长宽,P为候选框中目标的类别概率。
2) 然后网络通过非极大值抑制(NMS)算法,选择置信度最高的候选框检测目标。
3) 最后网络通过与标签对比,计算整体损失,通过反向传播BP算法[13],更新网络的权重参数。
图2为YOLOv3在第一尺度特征图上作检测。

图2 YOLOv3在第一尺度特征图上作检测
2.2 SAR-YOLO-960网络结构
初始标注416×416像素数据集训练YOLOv3网络进行检测时发现效果不理想,达不到预期检测精度,其中部分城镇和电塔有漏检、误检现象出现。如图3所示,图3(a)、图3(b)、图3(c)为测试原图,图3(d)、图3(f)、图3(g)为分别对应的YOLOv3检测图,其中黄色方框标记为电塔,绿色方框标记为城镇。检测图3(d)、图3(f)、图3(g)中手工标注的红色圆圈为漏检部分,可看出图3(d)中出现了城镇漏检,图3(e)中出现了电塔漏检;蓝色圆圈标记为误检测部分,可看出图3(d)中将电塔误检测为城镇,图3(f)中两个靠近遮挡的电塔误检测为一个电塔。则说明其检测精度还有很大提升空间。

图3 YOLOv3漏检、误检现象
通过观察训练样本发现,城镇目标尺寸过大,大部分充满整个训练样本。因为原始SAR图像中城镇分辨率大,416×416像素图只能获取局部信息,学习到的特征有限,最终训练出的候选框也接近于图像大小,没有训练意义;同时电塔的重叠、尺寸较小与特征的不明显也导致了漏检、误检现象的出现。
上述问题的常规解决方法为先截取高分辨率图再下采样成416×416小像素图作为输入训练。但电塔目标本身就较小,特征不明显,下采样后很容易失真,网络学习不到目标特征。因此针对综上所述问题,本文提出了一种SAR-YOLO-960检测网络,如图4所示。该网络能充分学习到城镇与电塔的特征,使得检测精度上有大幅提升,改善了漏检、误检现象。

图4 SAR-YOLO-960 检测网络
该算法对比原始YOLOv3算法改动为:
1) 选取960×960像素尺寸作为输入,能完整地包含城镇与电塔目标。
2) 修改了网络层结构:首先搭建了一个Dark- net-SAR网络,改变了Darknet-53网络中的卷积和残差层构造,为避免高分辨率图像带来的计算量,整体采用64倍降采样最后得到特征图的大小为15×15,使得中心像素对应输入图像的中心单元格,能更好地检测大目标,因为大目标一般集中在图片中央。然后采用YOLOv3的方式融合低层次特征图,形成3种不同尺度的特征图进行检测。
3) 结合Focal Loss思想改进了损失函数,提升检测精度。
2.3 损失函数改进
传统的YOLOv3损失函数,采用误差平方和(sum-squared error),由3部分求和组成:候选框与真实框的坐标误差、置信度误差以及分类误差。其公式(4)如下:

但在实际检测中,样本类别数量的不均衡,以及样本中目标的识别难易会影响模型的训练。如本文中城镇数量多于电塔;电塔特征不明显较难识别。训练中希望模型更关注于难以识别的目标和样本中类别数量较少的目标。而传统的平方差分类损失并不能很好地解决此问题。因此本文借鉴了Focal Loss损失函数的思想,对YOLOv3损失函数的分类误差部分作出了改进,其公式(5)如下:
(5)
式中,At为样本均衡权重。因本文为2分类检测,则定义At=[a,1-a], 当标签(label)为城镇时定义At=a,当label为电塔时定义At=1-a,通过调节a的大小平衡样本的不均衡问题。其次易分类样本的(1-pi(c))接近于0,难分类样本的(1-pi(c))接近1,则可以使得模型更注重于难以分类的样本训练。
3 实验结果与分析
3.1 实验环境与评价标准
本文实验环境如下:CPU Intel Core i7-6800k;GPU(单)NVIDIA TITAN Xp;操作系统:64位 Ubuntu 16.04 LTS;内存:16G DDR4;图形加速:CUDA 8.0.44,cudnn 5.0。在该实验环境下,SAR-YOLO-960在测试集上的检测速度达32.8 fps。
设置初始学习率为0.001,学习率策略为steps,总共迭代80 000次,在40 000次与60 000次时学习率分别乘以0.1;动量系数0.9;一批训练16张图片;采用多尺度训练,图片大小从640×640~1 216×1 216,每隔16张图片尺寸变化64×64大小。若检测出的标记框与真实标记框的IOU大于0.75,则认为检测出了该物体。
本文使用公式(6)准确率(Precision,P),公式(7)召回率(Recall,R),公式(8)F1值(平衡准确率和召回率的函数),以及检测速度fps来评价高分辨率SAR图像检测的性能。准确率、召回率越高,fps越大,表明性能越好。
(6)
(7)
(8)
式中,TP为预测为正、实际为正的目标个数,FP为预测为正、实际为负的目标个数,FN为预测为负、实际为正的目标个数。
3.2 实验结果与对比
SAR-YOLO-960网络训练损失与迭代次数关系如图5所示。从图5(a)可以看出该网络收敛迅速,在100~200次迭代时迅速下降;从图5(b)可以看出最终损失趋于0。经测试集验证效果,最终选取第70 000次迭代结果作为最终权重模型。


图5 网络迭代损失变化图
为了综合评估本文算法的有效性,本文选取了当前主流的深度学习目标检测算法进行试验作对比,包括Faster-RCNN,SSD,RetinaNet,YOLOv3,也与损失函数未改进前的SAR-YOLO-960作对比,结果如表3所示。
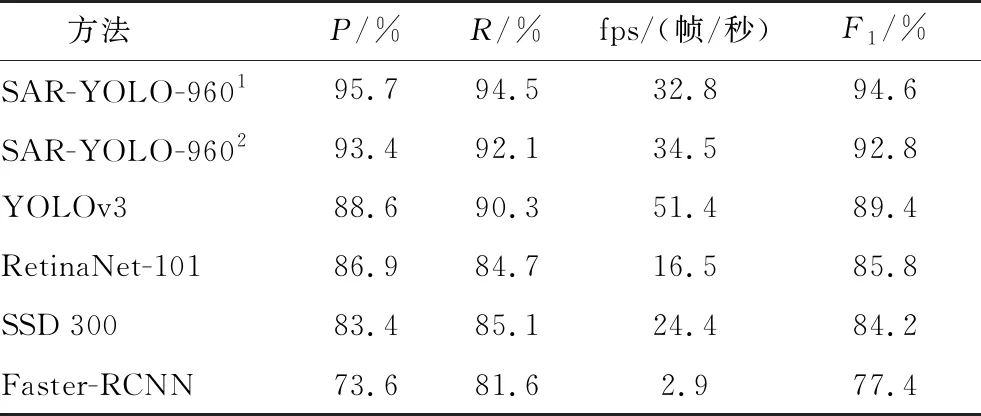
表3 SAR图像目标检测算法性能对比
其中SAR-YOLO-9601为损失函数改进后的网络,SAR-YOLO-9602为损失函数改进前的网络。从表3可以看出,本文算法在损失函数改进后与改进前,其在准确率和召回率上分别有2.3%和1.4%的提升;同时SAR-YOLO-9601对比主流中最好的YOLOv3 算法在准确率和召回率上分别有7.1%和4.2%的提升;其速度上也比Faster-RCNN、SSD、RetinaNet快很多,但比YOLOv3慢1.5倍左右。原因为本算法输入大小为960×960像素比YOLOv3的输入416×416像素大5倍左右,中间也新增了卷积层和残差层,但速度上32.8帧/秒也可达到实时检测,不影响检测性能。综合分析下,其性能对比于目前的主流算法有了很大的提升。
为了更好地证明本文算法性能的优越性,可以改善漏检和误检的现象。本文利用该算法对 2.2节图3中的原图重新作检测,并将结果与其2.2节图3中YOLOv3的检测图作对比,结果如图6所示。图6(a)、图6(b)、图6(c)为YOLOv3的检测图,其中绿色方框标记为城镇,黄色方框标记为电塔,蓝色圆圈标记为误检现象,红色圆圈标记为漏检现象;图6(d)、图6(f)、图6(g)为本文算法分别对应的检测图,其中绿色方框标记为电塔,粉红色方框标记为城镇。从图中可以看出,图6(a)、图6(b)、图6(c)中出现大面积城镇的漏检;图6(a)中将电塔检测成城镇的误检;图6(c)中重叠电塔的误检都在本文算法的检测图中都得到了改善,并准确检测。因此可以看出该算法有效地改善了城镇和电塔的漏检、误检现象。

图6 YOLOv3与SAR-YOLO-960检测对比图
4 结束语
本文针对SAR图像的特点,结合原有的YOLOv3算法和Focal Loss损失函数,提出了一种基于深度学习卷积神经网络的SAR-YOLO-960算法用于高分辨率SAR图像检测。本文实验表明该算法在高分辨率SAR图像目标检测上比目前的主流算法SSD,RetinaNet等速度快、准确度高。在方法设计时,为了增强其检测性能,对原始数据集进行了增强;采用K-Means对网络候选框进行聚类;修改了YOLOv3网络结构;改进了损失函数。然而,本文仅仅是基于深度学习卷积神经网络在SAR图像2分类检测方法上的初步探索,如何进一步提升准确率、泛化能力,让SAR图像在多分类检测上以及在超高像素的图像上也有良好的表现等仍是下一步探索的方向。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
活力(2021年4期)2021-07-28
中华民居(2020年6期)2020-06-09
红领巾·萌芽(2019年8期)2019-08-27
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
运动(2016年7期)2016-12-01
CHIP新电脑(2016年3期)2016-03-10
阅读(中年级)(2009年11期)2009-04-14
