
基于Python的新浪微博用户信息爬取与分析
2019-11-01 09:10邓文萍
数字技术与应用 2019年7期
邓文萍


摘要:本文设计并实现了一个微博用户信息爬取与分析系统,利用Cookie实现了用户的模拟登录,使用Python语言的Rquests、lxml等函数库,爬取、处理了该微博用户数据,并以“央视综艺国家宝藏”为例,从微博发布动作偏好、微博信息特征、微博关键词等方面展开了分析,获取了一些有趣的发现,为进一步用户分析与画像打下基础。
关键词:新浪微博;爬取分析;Python
中图分类号:TP393 文献标识码:A 文章编号:1007-9416(2019)07-0096-03
0 引言
新浪微博是目前我国最大的短消息社交平台,据新浪微博2017年全年财报称,截至2017年12月,微博月活跃用户增至3.92亿。社交用户的增多,意味着信息的极具爆炸,基于微博数据的社交用户行为分析与画像引起了人们的关注[1]。该技术能够对用户进行画像,用于社交群体发现[2]、个性用户发现[3]等。
本文使用Python语言,通过模拟用户登录,实现一种针对新浪微博的爬虫,并对获得的数据进行有效地分析。该文设计并实现了新浪微博爬虫程序,以微博用户“央视综艺国家宝藏”为例,对他发布的微博内容进行了全部抓取,并从微博发布行为、微博信息特征、微博关键词等方面,进行了数据分析,为用户分析与画像打下基础。
1 爬虫系统设计
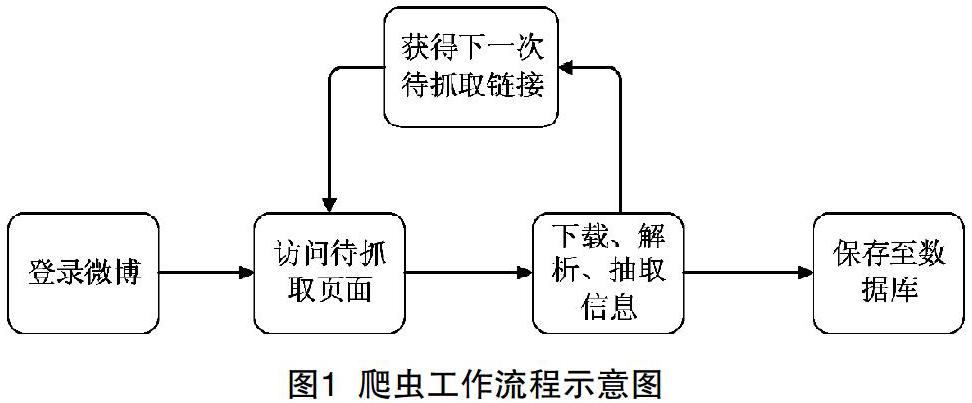
该爬虫程序的工作流程如图1所示,主要步骤为:
(1)登录微博:新浪微博要求用户访问微博数据之前必须登录,那么爬虫程序面临的首要任务是模拟登录。本文利用Cookie的特性,事先通过浏览器的方式,登录新浪微博,并正确输入用户名、口令,从而事先浏览器的登录;当成功登陆后,新浪微博服务器会记录登录的状态,经加密后,使用Response的方式,发送给客户端,从而存储于本地客户端的Cookie中。当本文编写的Python爬虫,需要登录新浪微博时,首先读取已存储于本地的Cookie,并发送给新浪微博服务器。而该服务器检查这个Cookie,可以认定客户端的合法身份,从而实现用户对新浪微博的成功登录。(2)访问待抓取页面:该模块访问被抓取微博用户的各类信息界面,利用Requests库下载待抓取页面的html代码。(3)下载、解析、抽取信息:使用lxml等python库解析页面,并根据预先定制的规则,抽取有关信息。(4)根据第(3)步骤的信息提取结果,如若信息内具有下一次待抓取的页面链接,则回至网页下载模块,重新进行下载、解析。(5)保存至数据库:待抓取完毕后,将所有信息保存至数据库。
2 微博用户数据分析
本文针对新浪微博用户“央视综艺国家宝藏”进行研究分析,抓取了其全部微博内容。该微博用户ID号6339534350,2017年8月22日第一次发布微博消息;截至2019年7月29日,它已发布了1490条信息,转发了339条消息,有粉丝2260078人,累计获得1481948点赞数、2360089转发量、462758评论数。
2.1 微博发布行为分析
该部分主要研究“央视综艺国家宝藏”发布微博信息的次数和时间等因素,深入分析它的微博发布行为特征。如图2中所示,该图为随时间变化的微博发布次数,其横坐标轴为日期,范围为2017年8月22日至2019年7月29日;纵坐标轴则为微博消息的发布次数。
从图中可以看出,该微博用户发布微博消息有明显的规律性,它几乎每天都发送微博消息,但有两个明显的高峰期,分别为2017年12月至2018年2月期间和2018年12月至2019年2月。这两个高峰期是与《国家宝藏·第一季》和《国家宝藏·第二季》的播出时间是重合的,其中《国家宝藏·第一季》自2017年12月3日起在中央电视台播出,共有十期节目,每周日播出一期,于2018年2月11日结束;同样地,《国家宝藏·第二季》自2018年12月9日起播出,共有十期节目,每周日播出一期,于2019年2月2日结束。在这两个节目播出周期内,平均每日微博发送量分别为8.69、6.57,远高于其他时期。
如图3所示,横坐标轴为发表时间,纵坐标轴为微博发布的次数。从图中可以看出,该微博用户发布微博信息的时间集中在每日的9时到22时,而在在23时至次日8时的时间段内没有发表任何内容。同时,还可以看出整点是发布微博的高峰,12时、14时、16时、18时、20时、22时各发表了60次、69次、65次、73次、49次和46次。
2.2 微博信息分析
2.2.1 点赞数分析
通过按照微博发布的先后,给微博消息进行排序,列出每条微博的点赞数,如图4所示。微博消息的总点赞数均值为994.60,总体标准差为1868.26,显示着各微博点赞数极不均衡。从图4可以看出,个别微博的点赞数极高,高于2万点赞数的微博数目为6个,高于1万低于2万点赞数的微博数目为3个,而点赞数低于1000的微博占总体的74.77。
为了直观地观察这一现象,本文将微博序号按照点赞数大小进行排序,如图5所示。从图可以看出,该图形从横坐标一开始时,占据较高纵坐标,接着极具下降,形成拖着长长尾巴的形状。这说明微博点赞数服从幂律分布[4],即少数高赞微博受到人们的极大关注,而大部分微博受关注度一般。该分布的一个通俗解释就是马太效应,即穷者越穷富者越富。
2.2.2 评论数分析
图6中,横坐标为按时间排序的微博序号,纵坐标为该微博对应的评论数。微博消息的总评论数均值为310.58,总体标准差为3091.64,显示着各微博评论数极不均衡。从该图可以看出,评论数高于1万的微博数目为1个,高于5千低于1万的微博数目为4个,而评论数低于300的微博占总体的84.56%。这说明微博评论数同样服从幂律分布。
图7中,横坐标为按时间排序的微博序号,纵坐标为该微博对应的转发数。微博消息的总转发数均值为1583.95,总体标准差为22209.09,显示着各微博评论数比点赞数和评论数更不均衡。从该图可以看出,转发数高于10万的微博数目为3个,高于1万低于10万的微博数目为30个,而转发数低于1500的微博占总体的91.07%。
从微博的点赞数、评论数和转发数分析,我们可以看出微博的平均值还是比较高的,说明”央视综艺国家宝藏”用户的影响力巨大,同时也能看到这三个值极不均衡,服从幂律分布。
2.3 微博关键词分析
为了更好地分析微博内容,本文对抓取到的微博内容进行关键词抽取与展示。本文使用了jieba分词技术[5],处理得到微博内容的所有词组,并去除停用词,接着使用wordcloud函数库,制作了词云。如图8所示,主要的关键词有“国家”、“宝藏”、“CCTV”、“国宝”、“博物馆”、“频道”、“中国”、“视频”等词。
3 结语
该文设计并实现了针对新浪微博用户的爬虫程序,并对抓取到的信息进行分析,以“用户为例,从微博发布行为、微博信息特征、微博關键词等四个方面,进行了数据研究与分析。经过数据分析,本文得到如下信息:(1)微博用户发布的有着较为明显的整点发布偏好;(2)博主的微博的点赞数、评论数以及转发数服从幂律分布;(3)博主发布的微博内容的关键词主要有“国家”、“宝藏”、“CCTV”、“国宝”、“博物馆”、“频道”、“中国”、“视频”等。这些发现将为用户画像打下基础。
参考文献
[1] 曾鸿,吴苏倪.基于微博的大数据用户画像与精准营销[J].现代经济信息,2016(16):314-316.
[2] 解,汪小帆.复杂网络中的社团结构分析算法研究综述[J].复杂系统与复杂性科学,2005,2(3):1-12.
[3] 邓胜利,杨丽娜.用户个性特征对信息行为影响的研究进展[J].情报理论与实践,2014,37(5):119-123.
[4] 罗斌,陈翔.幂律特性在新浪微博个性化推荐中的应用研究[J].计算机工程与科学,2018,40(04):165-173.
[5] 杜雷,垂直搜索引擎网络爬虫的研究与设计[D].北京邮电大学,2015.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
娃娃乐园·综合智能(2021年11期)2021-12-06
小哥白尼(神奇星球)(2021年9期)2021-11-19
趣味(作文与阅读)(2021年3期)2021-07-19
现代信息科技(2021年21期)2021-05-07
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
高原山地气象研究(2016年1期)2016-11-10
浙江大学学报(工学版)(2016年9期)2016-06-05
中学生(2015年21期)2015-03-01
