
盲去模糊的多尺度编解码深度卷积网络
2019-10-31 09:21贾瑞明邱桢芝崔家礼王一丁
计算机应用 2019年9期
关键词:卷积神经网络
贾瑞明 邱桢芝 崔家礼 王一丁
摘 要:针对拍摄场景中物体运动不一致所带来的非均匀模糊,为提高复杂运动场景中去模糊的效果,提出一种多尺度编解码深度卷积网络。该网络采用“从粗到细”的多尺度级联结构,在模糊核未知条件下,实现盲去模糊;其中,在该网络的编解码模块中,提出一种快速多尺度残差块,使用两个感受野不同的分支增强网络对多尺度特征的适应能力;此外,在编解码之间增加跳跃连接,丰富解码端信息。与2018年国际计算机视觉与模式识别会议(CVPR)上提出的多尺度循环网络相比,峰值信噪比(PSNR)高出0.06dB;与2017年CVPR上提出的深度多尺度卷积网络相比,峰值信噪比和平均结构相似性(MSSIM)分别提高了1.4%和3.2%。实验结果表明,该网络能快速去除图像模糊,恢复出图像原有的边缘结构和纹理细节。
关键词:盲去模糊;多尺度结构;跳跃连接;编解码;卷积神经网络
中图分类号:TP391
文献标志码:A
Deep multi-scale encoder-decoder convolutional network for blind deblurring
JIA Ruiming*, QIU Zhenzhi, CUI Jiali, WANG Yiding
School of Information Science and Technology, North China University of Technology, Beijing 100144, China
Abstract:
Aiming at the heterogeneous blur of images caused by inconsistent motion of objects in the shooting scene, a deep multi-scale encoder-decoder convolutional network was proposed to improve the deblurring effect in complex motion scenes. A multi-scale cascade structure named “from coarse to fine” was applied to this network, and blind deblurring was achieved with the blur kernel unknown. In the encoder-decoder module of the network, a fast multi-scale residual block was proposed, which used two branches with different receptive fields to enhance the adaptability of the network to multi-scale features. In addition, skip connections were added between the encoder and the decoder to enrich the information of the decoder. The Peak Signal-to-Noise Ratio (PSNR) value pf this network is 0.06 dB higher than that of the Scale-recurrent Network proposed on CVPR(Conference on Computer Vision and Pattern Recognition)2018; the PSNR and Mean Structural Similarity (MSSIM) values are increased by 1.4% and 3.2% respectively compared to those of the deep multi-scale convolution network proposed on CVPR2017. The experimental results show that the proposed network can deblur the image quickly and restore the edge structure and texture details of the image.
Key words:
blind deblurring; multi-scale structure; skip connection; encoder-decoder; Convolutional Neural Network (CNN)
0 引言
圖像去模糊是计算机视觉及图像处理中一个重要任务,在交通安全、医学图像、军事侦察等领域都有广泛应用。图像模糊中运动模糊是最见的一种,由相机晃动、多个目标物体的运动等造成,具有重要的现实研究意义。去模糊的目的是从退化的模糊图像中恢复出其对应的清晰图像。数学上模糊图像由清晰图像和模糊核卷积加上噪声形成,根据模糊核是否已知,去模糊可分成非盲去模糊和盲去模糊[1]。多数情况下模糊核是无法提早获得的,所以盲去模糊应用更广泛也更具挑战性。盲去模糊是一个不适定的逆问题,为了解决这个问题,许多学者将模糊核和清晰图像的信息作为先验知识来提高复原图像的质量,其中包括正则化强度和梯度先验[2]、数据驱动判别先验[3]等。上述方法能够改善去模糊质量,但都需要复杂的模糊核估计步骤,模糊核估计不正确会使恢复的图像存在肉眼可见的伪影。
近年来,人们将基于卷积神经网络的方法应用于图像去模糊任务,采用端到端的方式直接恢复清晰图像,避免了模糊核估计带来的相关问题,取得很好的去模糊效果。大多数卷积神经网络的方法主要消除由简单的平移或相机旋转引起的运动模糊,这些方法假设模糊是均匀的或在整张图片中是空间不变的。然而,由于场景深度的变化和目标物体的运动,真实图片通常为非均匀模糊[4]。Sun等[5]用卷积神经网络去除非均匀运动模糊。但所用数据集中的模糊图像是由模糊核与清晰图像卷积合成,这与真实场景中的模糊有很大不同,当把它们应用在真实去模糊问题中,不能得到很好的恢复结果。为此,Nah等[1]提出一个大规模更接近真实的模糊清晰图像数据集对,并用一种深度多尺度卷积网络,以端到端的方式直接去除动态
场景模糊。Kupyn等[6]用条件生成对
抗网络和内容损失函数去除运动产生的图像模糊。Tao等[7]用多尺度循环网络以“从粗到细”的方式逐渐恢复清晰图像,实现了更好的去模糊结果。然而,这些方法仍然存在速度慢、恢复图像纹理不清晰等问题。
针对上述研究,本文提出一种多尺度编解码深度卷积网络,以端到端的方式直接去除动态场景中的运动模糊,实现快速、高效的图像复原。本文主要工作包括以下三个方面:
1)提出快速多尺度残差块(Fast Multi-scale Residual Block, FMRB),作为网络的重要组成模块,使网络对不同尺度的模糊输入有更强的适应能力。同残差块[8]、Inception模块[9]、多尺度残差块(Multi-scale Residual Block, MSRB)[10]等相比,FMRB去模糊效果更优。
2)提出新的多尺度编解码深度卷积网络用于非均匀图像盲去模糊。网络采用“从粗到细”的多尺度结构逐渐恢复清晰图像,每个尺度均使用相同的参数设置。在不同尺度间进行参数共享,不仅能够降低参数量,还能防止过拟合。同时各尺度均使用编解码加跳跃连接的结构,能加速网络收敛,更好地恢复图像的纹理信息。
3)将提出的网络模型在GOPRO數据集[1]和Khler数据集[11]上进行实验,并与最先进的去模糊算法比较,得到了更优的去模糊效果。用自行拍摄的模糊图像实验,恢复出可视化效果较好的清晰图像。同时,验证了本文方法除运动模糊外,对其他类型模糊的去模糊效果,并对大尺图像去模糊的运算速度和性能进行实验分析。
1 多尺度编解码深度卷积网络
1.1 网络结构
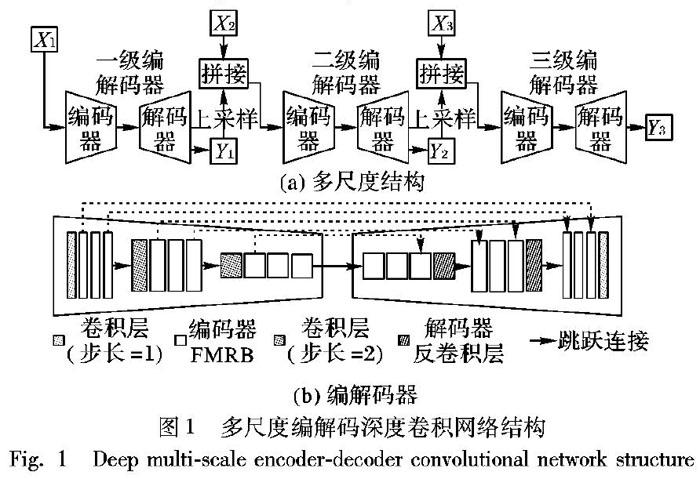
本文将提出的模型称为多尺度编解码深度卷积网络,如图1所示。网络整体为“从粗到细”的多尺度结构,即从粗糙的低分辨率模糊图像逐渐恢复精细的高分辨率清晰图像。各尺度使用相同的编解码器,如图1(b)所示。编解码模块由多个快速多尺度残差块(Fast Multi-scale Residual Block, FMRB),卷积层和反卷积层堆叠而成。FMRB如图2所示,是一种局部多尺度结构。
1.1.1 多尺度结构
多尺度结构在传统最大后验概率优化的方法[3]和近期深度学习的方法[1,7,12]等都有广泛应用,并表现出突出性能。本文提出的多尺度结构如图1(a)所示,网络的输入为3个分辨率不同的模糊图像Xk(k=1,2,3),它们由原始模糊图像下采样形成。下标k代表尺度层级,图像的分辨率随着k的增大顺序增加,尺度间隔比率为0.5。首先将尺度最小最容易恢复的模糊图像X1输入,恢复出其对应大小估计的清晰图像Y1。然后将估计的中间清晰图像上采样到更大的尺度,与模糊图像X2一同作为下一尺度的输入,进一步引导更大尺寸的图像恢复。同理,可以获得最后的高分辨率输出图像Y3。这种直接学习由输入到输出端到端的映射方式,避免了模糊核估计带来的相关问题。此外,多尺度结构可以降低网络的训练难度,使恢复的图像更清晰。
各尺度具有完全相同的网络结构和参数配置,这样在不同尺度间可以共享网络的权重,不仅可以减少训练的参数,而且能提升网络性能,防止过拟合。网络具体的参数配置如表1所示。
1.1.2 编解码结构
编解码结构在计算机视觉任务[7,13-15]中的有效性已被证明。本文提出一种新的编解码结构,如图1(b)所示,由多个FMRB以及卷积层和反卷积层组成。步长为2的卷积层将特征图尺寸降为原来的一半,同时将通道数增加一倍;相反,步长为2的反卷积层则将特征通道数减半,特征图尺寸提升一倍。编码块的主要任务是进行特征提取,抽象图像的内容信息,并且消除模糊。解码块的作用是恢复图像的高频细节信息。图像去模糊任务中,需要足够大的感受野来恢复严重模糊的图像。目前加深、加宽网络已经成为一种增加网络感受野的设计趋势,然而简单地增加深度会使网络变得更难训练,出现梯度消失、梯度爆炸等现象[8]。本文网络较深,为了防止上述问题的出现,在编码部分和对称的解码部分添加了跳跃连接,每隔1个FMRB添加1条跳跃连接。这种连接不仅可以将编码部分的图像信息传递到解码部分,帮助恢复原始的清晰图像。在反向传播中还有助于将梯度传到底层,加速网络收敛,提升去模糊性能。
1.1.3 快速多尺度残差块
快速多尺度残差块(FMRB)如图2所示。模块的输入传给两个分支,右边的分支首先经过一个3×3卷积层,左边的分支经过两个3×3的卷积层。两个3×3卷积层与一个5×5卷积层的感受野相同[9],但是计算量更小非线性变换更强。由于两个分支的感受野不同,所以能检测不同尺度的信息。最后拼接意味着不同尺度的特征融合,这种信息交互可以使后面的层共享两个分支之间的信息,使网络对多尺度输入有更强的适应性。
图2中S为相邻卷积层卷积核的数量,Cn-1和Cn分别为模块输入、输出的通道数,这里Cn-1=Cn=S。尽管两个3×3卷积与一个5×5卷积的感受野相同,但FMRB计算量(由于其他部分计算量相同,为了简便,只考虑虚线框内的计算量)由170MNS2减少为135MNS2(这里通过像素填充使模块输入到输出的特征图分辨率保持M×N不变,为了方便,省略了偏置计算)。FMRB在深度加深的同时,时间复杂度更低,运算速度更快。
由于深度网络能提取更丰富的特征,所以网络深度对其性能有至关重要的影响。但是深度网络很难训练,为了缓解这个问题,FMRB采用了残差学习,在模块的输入到输出之间添加1个恒等映射。这种局部残差学习能加速网络收敛,防止梯度消失,提升网络性能。FMRB中的1×1的卷积层,实现特征通道降维,使模块的输出和输入保持相同的维度,同时可以保留有用的图像信息,剔除冗余信息。
1.2 损失函数
本文将均方误差(Mean Squared Error, MSE)作为该网络的损失函数。如式(1)所示:
L(Θ)=1KN∑Kk=1∑Ni=1‖F(Xik,Θ)-Yik‖(1)
其中:N为训练样本对的个数,K为网络最大尺度层级,Θ为网络权重。
通过训练实现该损失函数最小化,使网络在尺度层级k对第i张图像的去模糊结果F(Xik,Θ)与真实清晰图像Yik的欧几里得距离最小。
2 实验结果与分析
2.1 数据集
GOPRO数据集[1]是2017年提出的大型去模糊数据集,与以往数据集中用模糊核与清晰图像卷积合成模糊图像不同,它是用高速摄像机捕捉连续短曝光的清晰帧,并进行整合平均来模拟长曝光的模糊帧。这样形成的图像更接近真实,能够模拟复杂的相机抖动和场景中多个目标运动带来的非均匀模糊。GOPRO数据集总共包含3214对模糊清晰图像,图片大小为720×1280,其中2103对图像用来训练,其余1111对图像用来测试。
Khler数据集[11]是一个评估和比较盲去模糊算法的基准数据集。作者通过记录和分析真实相机的运动,然后用机器人载体进行回放,通过在6D相机的运动轨迹上留下一连串清晰的图像,形成数据集。Khler数据集由4张图片组成,对每张图片用12个不同的模糊核对进行模糊,最后形成48张模糊图像。
2.2 实验细节
本文实验在CPU为i5-3470,内存16GB,GPU为NVIDIA 1080Ti的计算机上进行。除FMRB中的卷积层,网络中其他卷积层均使用5×5大小的卷积核,反卷积核尺寸为4×4,在卷积层和反卷积层后面均使用ReLU激活函数。此外,使用像素填充保持特征图的输出和输入尺度不变。训练时将训练集中的模糊清晰图像对随机裁剪成256×256大小的图像块,测试时保持图片原有大小不变。训练阶段多尺度层级的输入/输出分辨率为{64×64,128×128,256×256}的图像块,本文用双线性插值来采样图片。初始学习率设置为 1E-4,然后使用指数衰减法逐步减小学习率,衰减系数为0.3。用Adam优化器来优化损失函数,实验中批尺寸设为2,网络训练直至收敛。
2.3 结果与分析
2.3.1 质量评估
传统去模糊算法通常假设整幅图像的模糊是均匀和不变的。然而,运动模糊图像的模糊通常是动态变化的和非均匀的。为了公平比较,本文没有与传统的均匀去模糊算法对比,只与最先进的非均匀去模糊算法进行比较。表2为不同去模糊方法在GOPRO测试集上的质量评估结果。用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和结构相似性(Structural SIMilarity index, SSIM)两项指标作为性能衡量的标准。图3是在GOPRO测试集上可视化对比的示例图。在Khler数据集上,本文与多种方法的客观质量评估对比结果见表3,用PSNR和平均结构相似性(Mean Structural SIMilarity, MSSIM)作为评价算法性能的标准。
从表2的GOPRO测试集部分可以看出,本文去模糊图像得到了最高的PSNR和SSIM值。表中前三种方法[5,16,17]不能有效去除图像中的模糊。Nah等[1]和Zhang等[18]的去模糊效果相较前面三种方法有了很大的提升,但还没达到最佳。Tao等[7] 在2018年CVPR上提出的多尺度循环网络(Scale-Recurrent Network, SRN-DeblurNet),被证明是有效的去模糊方法。本文结果较Tao等[7]的PSNR值提高了0.06dB,SSIM也有所提高,说明本文算法复原图像质量要优于其他方法。从图3(b)左图可以看出,Tao等[7]去模糊结果的车牌出现多余信息,圆圈中的数字存在结构变化。对于图3(b)右图复原后的图像存在严重伪影,且没能恢复出车完整的轮廓。本文去模糊的可视化图像没有明显的伪影,不仅去除了图像的模糊,还保持了清晰的纹理和边缘细节,更接近真清晰图像。
各算法在Khler数据集上的测试结果见表2Khler测试集部分,本文的PSNR和MSSIM均高于其他算法,与Nah等[1]的深度多尺度卷积网络相比,两项指标分别提高1.4%和3.2%。 综上可得,本文的去模糊效果要优于其他方法。
2.3.2 多尺度结构分析
为了检验多尺度结构的有效性,本文分别对单一尺度、2个和3个尺度模型进行测试,即式(1)中的最大尺度层级K分别为1、2和3。均在GOPRO数据集上进行训练和测试。以PSNR、SSIM以及在测试集上的平均测试时间作为图像质量的客观评价标准。不同尺度性能比较如表3所示,在测试集上去模糊结果的局部可视化效果为图4。
在表3中,当K=2时,PSNR和SSIM值比K=1分别提高0.49dB和0.0056。从图4(左)也可以看出网络为1个尺度时,去模糊效果不好,恢复的字体扭曲并严重失真。2个尺度较单一尺度有较大的提升,能改善图像模糊,且没有出现扭曲变形现象。K=3与K=2比较,平均的PSNR和SSIM值分别提高0.28dB和0.0039,进一步提升了去模糊效果。从图4(右)能看出,尺度层级为2的去模糊图像地面纹理不清晰,而3个尺度的复原图像边缘更清晰,细节较丰富,与清晰图像最为接近。K为3性能更好,测试时间与K为2相近,所以本文的网络结构使用3个尺度。综上,多尺度结构对于图像去模糊任务是非常有效的。
2.3.3 快速多尺度残差块分析
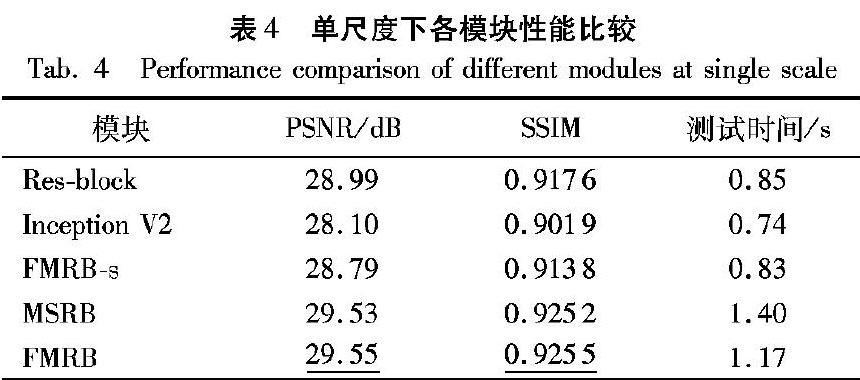
本文提出一个新的模块——快速多尺度残差块(FMRB)。为了验证FMRB的有效性,基于本文的网络结构,分别用经典的残差块(Res-block)[8]、Inception V2模块[9]、MSRB[10]以及FMRB-s(FMRB的简化版本)替換 FMRB,在相同的平台下实验,不同模块结构如图5所示。为了快速验证,我们使用单一尺度结构在GOPRO数据集上进行实验。测试结果见表4。
表4中结果表明,使用FMRB模块的PSNR和SSIM值最高,在所有对比模块中,本模块有一定优势。FMRB较MSRB模块计算量更少,在测试时间上,速度提升16%,实时性更好。综上,模块FMRB对于图像去模糊任务是非常有效的,它用更少的计算量实现了更优的性能。
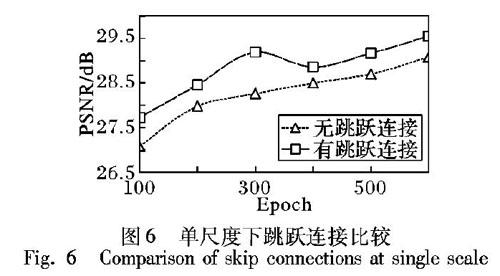
2.3.4 跳跃连接分析
随着网络深度的增加,图像信息会丢失。本文的网络中,编码部分特征图的空间信息可以通过跳跃连接传送到解码部分,帮助解码器恢复更清晰的图像。本文分别对有跳跃连接和无跳跃连接的两种网络结构(网络其他结构保持不变)在GOPRO数据集上实验,为了简便,两种结构都使用单一尺度。图6给出两种模型的盲去模糊质量评估散点图。由图可以看出,在100~600个Epoch之间,有跳跃连接的曲线均落在无跳跃连接曲线的上方,即有跳跃连接模型的去模糊结果得到了更高的PSNR值。所以,对于深度编解码网络,跳跃连接具有较大的优势。
2.3.5 自行拍摄图像去模糊
GOPRO数据集的模糊图像是合成的,与真实模糊图像有很大不同。许多方法将训练好的模型运用到实际情况中,不能得到很好的去模糊结果。为了验证本文模型的实用性,将手机自行拍摄的模糊图片在训练好的模型上进行去模糊实验,结果如图7所示。
从图7的两组图像可以看出,多尺度编解码深度卷积网络能够去除实际拍摄图片的运动模糊,去模糊图像得到了较高质量的视觉效果。本文所提网络的泛化能力较强,能广泛应用于日常生活中。
2.3.6 其他模糊图像复原
模糊图像类型不同,但其形成过程都可以通过清晰图像与模糊核的卷积来描述,去模糊过程具有相似性,本质上都是一个求反卷积的过程。理论上,本文用于处理运动模糊的方法也能用来去除其他模糊。
物体运动、镜头聚焦不准、光学系统的衍射等都会造成图像模糊,但最常见的模糊分为运动模糊和离焦模糊两大类型。本文所用GOPRO数据集中图像的模糊是由相机抖动和拍摄场景中多个物体的快速运动共同产生的,包含全局模糊和局部模糊,所以本文不只是处理简单的匀速直线运动模糊,本文的模糊核是空间变换和非均匀的,覆盖范围更广;离焦模糊是由聚焦不准、景深、成像设备质量等形成,目前有高斯模型和圆盘模型来近似离焦模糊的模糊核[19],高斯模型具有规律性,圆盘离焦模型为弥散状且均匀分布的圆盘形,与运动模糊的模糊核相比更为简单。为了验证本文方法的对于去除其他模糊的可行性,对离焦模糊的图像进行测试,实验结果见图8。
从图8可以看出去模糊图像中铁架和台阶的纹理比模糊图像更为清晰,本文方法能够改善离焦模糊图像的质量。验证了上述理论的正确性,所提方法具有普适性,对于其他模糊图像的复原也具有较好的效果。
2.3.7 大尺度图像去模糊
本文的多尺度编解码深度卷积网络在图像去模糊性能和实时性方面都具有一定的优势,但是随着图片尺度的增加,去模糊的速度逐渐减慢。为提升大尺度图像在所提方法中的计算速度,作了以下处理。取1000对GOPRO测试集中的图像拼接成250对空间分辨率为1440×2560的图像,称为GOPRO-L数据集。分别用直接输入法和三种不同处理方法在此数据集上进行测试:第一种是下采样法,即用双三次插值将模糊图像下采样成低分辨率图像作为网络的输入,然后将去模糊结果用同样的方法上采样到原图大小;第二种方法是分块法,将模糊图像分成多个小块分别去模糊,然后将测试后的图像拼成输入对应的图像;第三种方法是将前两种方法结合使用,将分块后的图像下采样进行去模糊。表5为不同方法对大尺度图像的去模糊结果,括号中的值分别为下采样后图像与原输入图像的尺寸比例和分块个数,用PSNR和平均测试时间作为评价标准。
由表5可知,在下采样法中,随着输入图像尺寸的减小,测试时间大幅降低,但是PSNR值逐渐减小。下采样图像尺寸为原图0.4倍时的测试效率比直接输入法提升83.47%,
但PSNR值降低7.23%。随着分块数量的增加,PSNR值逐渐降低,测试时间也在增加。当分块数为2×2个小块时,测试时间比直接输入法增加4.58%,但PSNR值提升了0.86%。下采样法对于提高大尺度图像的计算速度是非常有效的,在去模糊性能的要求不是太高時此方法非常有效。分块数量较少的分块法能提升去模糊的性能。将两种方法结合使用, 如表5中的最后一种方法,较单一分块法(2×2块)测试效率提升82.86%,较单一下采样法(0.4倍)的PSNR值提升0.97%,在提升性能的同时也保证了运算速度。
3 结语
为去除非均匀运动模糊,并解决早期去模糊算法计算复杂、运算速度慢、恢复图像存在重影等问题,本文提出一种多尺度编解码深度卷积网络,以端到端的方式快速实现模糊图像的盲去模糊。实验结果表明本文方法优于目前先进的去模糊方法,恢复图像纹理更清晰;同时,多尺度结构能减少图像重影,保持图像的边缘结构;编解码加跳跃连接的结构对于提升去模糊性能是有效的;提出的快速多尺度残差块用更少的计算量实现了更优的性能。实验还表明本文方法对去除真实拍摄图像的模糊和其他类型的模糊也均是有效的。对于大尺度图像去模糊,在保持运算速度的同时,如何进一步提升图像复原的质量,并将提出的网络用于其他图像复原任务是接下来的研究方向。
参考文献
[1]NAH S, KIM T H, LEE K M. Deep multi-scale convolutional neural network for dynamic scene deblurring [C]// CVPR 2017: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017, 1:257-265.
[2]PAN J, HU Z, SU Z, et al. Deblurring text images via l0-regularized intensity and gradient prior [C]// CVPR 2014: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 2901-2908.
[3]LI L, PAN J, LAI W-S, et al. Learning a discriminative prior for blind image deblurring [C]// CVPR 2018: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 6616-6625.
[4]ZHANG X, DONG H, HU Z, et al. Gated fusion network for joint image deblurring and super-resolution [C]// BMVC 2018: Proceedings of the 2018 British Machine Vision Conference. Berlin: Springer, 2018: 153.
ZHANG X, DONG H, HU Z, et al. Gated fusion network for joint image deblurring and super-resolution [EB/OL]. [2019-01-05]. https://arxiv.org/pdf/1807.10806.pdf.
[5]SUN J, CAO W, XU Z, et al. Learning a convolutional neural network for non-uniform motion blur removal [C]// CVPR 2015: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 769-777.
[6]KUPYN O, BUDZAN V, MYKHAILYCH M, et al. DeblurGAN: blind motion deblurring using conditional adversarial networks [C]// CVPR 2018: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 8183-8192.
KUPYN O, BUDZAN V, MYKHAILYCH M, et al. DeblurGAN: blind motion deblurring using conditional adversarial networks [EB/OL]. [2019-01-05]. https://arxiv.org/pdf/1711.07064.pdf.
[7]TAO X, GAO H, WANG Y, et al. Scale-recurrent network for deep image deblurring [C]// CVPR 2018: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 8174-8182.
TAO X, GAO H, WANG Y, et al. Scale-recurrent network for deep image deblurring [EB/OL]. [2019-01-05]. https://arxiv.org/pdf/1802.01770.pdf.
[8]KRIZHEVSKY A, SUTSKEVER I, HINTON G, et al. ImageNet classification with deep convolution neural network [C]// NIPS ‘12: Proceedings of the 25th International Conference on Neural Information Processing Systems. North Miami Beach, FL, USA: Curran Associates, 2012, 1: 1097-1105.
[9]LOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// ICML ‘15: Proceedings of the 32nd International Conference on Machine Learning. New York, NY: ACM, 2015:448-456.
LOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [EB/OL]. [2019-01-05]. http://de.arxiv.org/pdf/1502.03167.
LOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// ICML ‘15: Proceedings of the 32nd International Conference on Machine Learning. [S.l.]: JMLR.org, 2015: 448-456.
[10]LI J, FANG F, MEI K, et al. Multi-scale residual network for image super-resolution [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11212. Berlin: Springer, 2018: 527-542.
[11]KHLER R, HIRSCH M, MOHLER B, et al. Recording and playback of camera shake: benchmarking blind deconvolution with a real-world database [C]// ECCV 2012: Proceedings of the 2012 European Conference on Computer Vision. Berlin, German: Springer, 2012:27-40.
KHLER R, HIRSCH M, MOHLER B, et al. Recording and playback of camera shake: benchmarking blind deconvolution with a real-world database [EB/OL]. [2019-01-05]. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=4F605BF966AB6B236B6591E377AC8243?doi=10.1.1.379.1398&rep=rep1&type=pdf.
[12]LAI W, HUANG J, AHUJA N, et al. Deep Laplacian pyramid networks for fast and accurate super-resolution [C]// CVPR 2017: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017, 1: 5835-5843.
[13]MAO X-J, SHEN C, YANG Y-B, et al. Image restoration using convolutional auto-encoders with symmetric skip connections [C]// NIPS 2016: Proceedings of the 2016 Conference on Neural Information Processing Systems. New York, NY: Curran Associates, Inc, 2016:2802-2810.
MAO X-J, SHEN C, YANG Y-B, et al. Image restoration using convolutional auto-encoders with symmetric skip connections [EB/OL]. [2019-01-07]. https://arxiv.org/pdf/1606.08921.pdf.
[14]SU S, DELBRACIO M, WANG J, et al. Deep video deblurring for hand-held cameras [C]// CVPR 2017: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017, 1: 237-246.
[15]RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation [C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Berlin : Springer, 2015: 234-241.
[16]KIM T H, LEE K M. Segmentation-free dynamic scene deblurring [C]// CVPR 2014: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014, 1: 2766-2773.
[17]GONG D, YANG J, LIU L, et al. From motion blur to motion flow: a deep learning solution for removing heterogeneous motion blur [C]// CVPR 2017: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017, 1: 3806-3815.
[18]ZHANG J, PAN J, REN J, et al. Dynamic scene deblurring using spatially variant recurrent neural networks [C]// CVPR 2018: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 2521-2529.
[19]于春和,祁奇.離焦模糊图像复原技术综述[J].沈阳航空航天大学学报,2018,35(5):57-63.(YU C H, QI Q. A survey of defocusing image restoration techniques [J]. Journal of Shenyang Aerospace University, 2018, 35(5): 57-63.)
This work is partially supported by the National Natural Science Foundation of China (61673021).
JIA Ruiming, born in 1978, Ph. D., research assistant. His research interests include computer vision, deep learning, pattern recognition.
QIU Zhenzhi, born in 1994, M. S. candidate. Her research interests include computer vision, deep learning.
CUI Jiali, born in 1975, Ph. D., research assistant. His research interests include image processing, pattern recognition.
WANG Yiding, born in 1967, Ph. D., professor. His research interests include image processing, image analysis and recognition.
猜你喜欢
电子技术与软件工程(2017年3期)2017-03-22
电脑知识与技术(2016年33期)2017-03-21
科技创新与应用(2017年5期)2017-03-16
电脑知识与技术(2016年30期)2017-03-06
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
软件(2016年5期)2016-08-30
电脑知识与技术(2016年10期)2016-06-16
