
大学生英语分级阅读智能文库构建研究
2019-10-31 04:14杨江曹欣雨
科教导刊·电子版 2019年24期
杨江 曹欣雨

摘 要 该文主要从研究背景、设计理念、文本收集、指数测量等方面介绍了英语分级阅读智能文库的构建过程。智能文库基于中国大学生不同的阅读动机,涵盖了以需求为导向的四种英语阅读材料类型,借助国外的蓝思文本分析器,实现了学生的阅读水平与读物的阅读难度之间的匹配,为大学生提供智能测试、智能选书和智能推荐服务,帮助其选择符合其阅读水平和阅读兴趣的英文读物。
关键词 英语分级阅读 文库建设 文本难度
中图分类号:G642文献标识码:A
0引言
英文阅读是学生英语学习的重要环节,也是学生获取信息的方式之一。然而,随着高等教育的普及,中国大学生英语水平也参差不齐,传统的英语课堂中的教材难以适应每个学生的英语水平,也难度满足学生个性化的阅读需求。因此,学生有必要考虑适当的课外英文读物,以适应和满足其发展目标。本研究团队通过调研发现学生在选择英文读物时存在一定困难,即无法选择难度适宜的阅读材料。一旦选择不合适的材料,尤其是难度过大的材料,学生可能会产生不断查阅生词、边读英文边读中文、放弃阅读等不良阅读习惯。本研究以这一现实问题为出发点,试图建设一个英语阅读文库,帮助中国大学生学生找到难度合适的阅读材料,同时兼顾其个性化的阅读需求。
分级阅读(Leveled Reading)是按照读者的阅读水平、兴趣爱好等要素为不同读者提供不同读物的阅读策略和方法。早在19世纪,美国著名的应用语言学家Stephen D. Krashen在“语言输入假说”和“情感过滤”理论就体现了分级阅读理念,他认为人类只有在获得可理解性的语言输入时,才能习得语言。“语言输入假说”中的“i+1”理论认为,“i”表示学习者当前的语言水平,“1”则表示的是略高于学习者当前语言水平的语言知识。输入的语言材料高于或低于其现有水平,都不利于其语言学习。他还认为要真正产生良好的二语习得效果,输入的语言材料中的语言成分必须尽可能可被学习者理解。他提出的情感过滤是学习者在二语习得过程存在的影响语言吸收的消极因素,即动机、自信心和焦虑感。学习者只有在学习动机强烈,有自信,无焦虑感的条件下才能有效地进行二语习得。
随后这一理念在国外、尤其在欧美国家被广泛接受并不断发展。现今欧美地区普遍使用的分级阅读标准体系主要有蓝思分级阅读框架、发展性阅读评估分级体系、指导性阅读分级体系、阅读能力等级体系等。但国外的分级体系并不适合中国学生,尤其是中国大学生这一阅读需求特殊的群体。他们普遍面对着升学应试、专业研究、职场工作等现实压力,且时间和精力十分有限,所以他们需要更有针对性的阅读材料辅助其英语学习。
在本研究领域或相关课题中,诸多国内学者对我国学生的英语分级阅读模式已进行了一定教学实践与探索,这对中国英语阅读教学范式变革产生了重要影响。但绝大部分学者更关注中小学生的英语分级阅读,对大学生的英语分级阅读方面研究甚少,且目前研究也大都存在构建该模式的教学理论上,极少能最大程度地提供一套精准量化的分级阅读方案并实践。
因此,在国内大学生英语阅读水平参差不齐、国外的分级阅读体系的局限性和专门面向中国大学生阅读需求的量化分级阅读方案尚为空白的背景下,我们完成了中国大学生分级阅读智能文库的建设,并以网站的形式呈现。其特点如下:
(1)根据情感过滤理论,阅读材料的选择以大学生的特殊阅读需求为导向,收集的材料致力于涵盖各专业领域、场合和用途,并蕴含深厚人文思想。
(2)根据输入假说理论,文库的智能推荐遵循自行建立的 “量化分级体系”,学生的推荐读物难度控制在一定可理解范围内,但比当前的阅读水平高。
(3)智能文库经过多次测试与改进,进一步完善文库的用户体验。
1构建思路
智能文库的设计思路遵循我们自主构建的“量化分级体系”。“量化分级体系”将Krashen语言输入假说和“情感过滤”理论作为分级的理论基础,以中国大学生的英语阅读实际为现实导向,试图将读者的阅读水平与读物的难度进行量化,为大学生提供可理解的输入材料,同时兼顾大学生的阅读需求,精心选择符合其现实需求的阅读材料,激发学生强烈的阅读动机。
该体系的量化分级对象由两部分构成。一是中国大学生的不同的阅读水平。二是各种英文阅读材料的难易程度。为了衡量和衔接这两个量化对象,我们借鉴了美国蓝思分级阅读框架体系,使用了一个统一的度量单位——蓝思值(Lexile,简写“L”)。蓝思值可以用来标记材料的阅读难度,也可以表示学生的当前阅读水平。
借助蓝思文本分析器(The Lexile Analyzer),可以直接测量并确定英文阅读材料的难度指数,即蓝思值,也可以间接衡量学生的阅读水平指数。衡量学生阅读水平的原则是学生在自身能力范围内所能胜任的难度最大的阅读材料。学生所能胜任的阅读材料难度的最大值,即代表该学生的阅读水平值。确定学生阅读水平指数的实现途径是搭建一个阅读测试平台,制定灵活的测评机制,学生通过进行一系列阅读理解测试,获得阅读水平指数。
学生阅读水平测试平台以“量化分级体系”为参照标准,其所有试题都应保证其来源的权威性和可靠性,试题应标记难度指数,并尽量保证试题的难度范围足以涵盖中国大学生的阅读水平,且各个难度区间数量均衡。量化分级体系规定的难度指数范围为500L-1900L,每个难度区间试题的数量应不少于100道,便于系统随机抽题进行测试,保证测试结果的可靠性。其次,测试平台应遵循我们制定的“预估+調整”的测评机制。小组将测试材料根据考试类别和难度区间两个方面进行了精确划分,首先,读者应根据自己的阅读动机,选择进行的英语考试类型,然后系统在此基础上从该考试类型的题库中随机抽取1道阅读理解,如果学生的答题准确率低于60%,可以选择换题重测或选择降低试题难度等级,系统为其随机抽取难度指数区间降低100L的试题;若学生的准确率介于60%-80%,学生的阅读水平数值即为该阅读材料的难度指数;若学生的准确率高于80%,学生可选择加大测试难度,即为其随机抽取难度指数升高100L的试题,该生的阅读水平指数等于能够胜任的阅读材料的难度指数最大值。
“量化分级体系”下的智能书库由三大模块构成:智能测试、智能选书和智能推荐。这三个模块是学生体验系统功能的步骤,也是研究者进行系统研究和开发的过程。智能测试模块是一个学生英语阅读水平测试平台,制定测评机制,提供一系列阅读理解试题,通过测试的学生可以准确评估自身阅读水平,确定阅读水平指数,为之后的系统推荐提供参考依据。
智能选书模块中,基于对学生的多元阅读需求的深度挖掘,我们为学生提供种类齐全、主题丰富的英文材料,学生可以给自己的需求订阅不同种类的阅读材料,或选择自己感兴趣的文章、书籍类型或主题。智能推荐模块中,系统会根据参照平台提供的学生阅读水平数值,结合学生已选择的阅读材料类型或主题,自动从书库中推荐符合其水平、满足其需求的阅读材料,帮助大学生选择合适的英文阅读材料。
系统的建设的出发点是竭力实现面向中国大学生的英语阅读智能推荐。各个模块的建设都是为了这一总目标服务。其中测试平台模块将帮助学生对自己的阅读水平认知更加清晰明确,避免盲目选择阅读材料难度过大或过小;帮助学生通过具体的阅读水平指数的变化找到进步空间、树立阅读目标、制定阅读计划等;激发阅读学生的阅读主观能动性,促进阅读习惯养成。
2构建过程
大学生英语分级阅读智能书库是一个由5万多篇英语文章、2万多本英文原著和1000套测试题组成的庞大的数据库。主要的建设过程包括文本收集、文本预处理、文本标注、指数测量和系统开发。
2.1文本收集
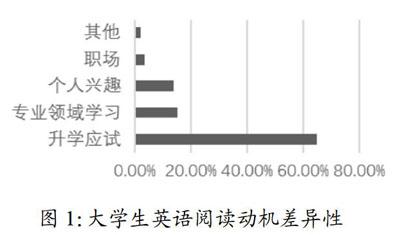
文本收集的依据是选择与中国大学生阅读动机紧密相关的英文材料,有针对性地满足大学生的阅读实际需求。基于这一思路,我们首先对全国大学生的英语阅读动机进行了抽样调查,研究了大学生阅读动机的差异性(见图1)。其次,根据大学生的实际阅读需要,我们确定了文本选择的四种类型,包括升学应试类、专业学习类、职场工作类和文学素养类。拟定文本类型后,使用网络爬虫技术大批量获取文本。
2.1.1动机研究
研究小组通过问卷调查的方式调查了来自全国各地的高校大学生3000名的英语阅读动机。其中接近65%的大学生的英语阅读动机是顺利通过英语考试,如大学英语四六级、考研、出国留学考试等。一部分学生是为了更好地进行专业领域学习,如阅读国际教材、了解国际新闻等。一接近15%的学生的阅读动机是提升文学素养,他们以个人兴趣为出发点尔,喜欢阅读英文小说,认为阅读小说是一种思想交流、情感共鸣。研究表明,学生长期坚持阅读英语原版小说,活的文化语境更有利于阅读习惯的养成,有利于学生在语言表达时更加地道。极少数学生阅读英文材料是为了更好的适应将来的工作环境,主要体现在面试求职、国外出差时的正常交际、特定场合下的谈判沟通等。
2.1.2文本收集类型
根据调查结果,我们面向大学生的英语显示阅读需求,以实际需求为导向,确定了智能书库需要收集的四种文本材料类型:英语考试类、英语学习类、职场英语类和原版小说类。其中英语考试类材料以阅读理解的形式纳入测试题库中,作为测试学生英语水平的材料来源。
英语考试类文章的具体类别为大学英语、英语专业、考研英语、出国留学等,文章来源是各种考试阅读真题。英语学习累文章的具体类别是英文刊物、新闻时讯、学科基础和专业教材等,文章来源是China Daily及各种外刊、VOA等新闻广播、各学科的英文原版教材等。英语职场类文章包括精英演讲、面试英语、外贸英语、商务会话等,文章来源是各专业领域的名人演讲稿、面试和外贸相关的教材等。英语原版小说的主题有金钱、权利、爱情、犯罪、惊悚、悬疑、成长、友谊、人生、宗教、动物、讽刺等40余种。英语原版小说将近1万本,一本小说同时标注有2-4个主题,为学生创造了更大的选择空间。收集过程尽量保持各个分类中材料类型和数量上的平衡。
2.2文本预处理
文本预处理包括对收集到的4万多篇文章、近1万本小说进行文本核对、格式检查和信息标注。信息标注在Microsoft Office Excel电子表格软件中进行,标注完成后利用程序将SVC格式文件转换成SQL语句文件,将其导入数据库中。
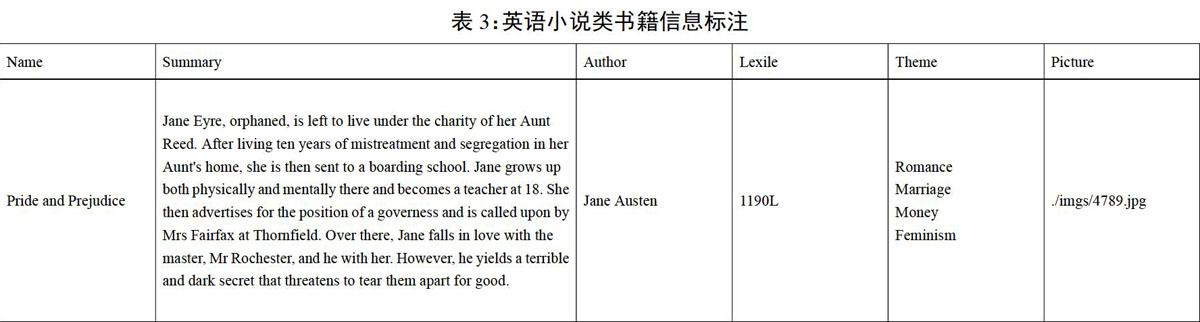
标注内容由材料类型决定。文章类标注内容包括:文章标题、适用类型、字数和难度指数。书籍标注内容包括:书名、封面图片、作者、主题、摘要、目录和难度指数。其中文章类中的适用类型,和书籍类中的主题、摘要部分由小组查阅资料、反复讨论确定。表1和表2列举了部分英语文章和小说的详细标注信息。
2.3指数测量
指数测量是英语智能文库构建过程中的重要环节,直接关系到读物难度与读者阅读水平的匹配。根据测量的对象,指数测量划分为两个部分:读物难度测量和学生阅读水平测量。针对读物难度的测量,我们使用的工具是由国外MetaMetrics研发的蓝思分级阅读框架下的蓝思文本分析器(Lexile Analyzer)来获得读物难书指数;针对学生阅读水平的测量,我们遵循了“分级量化体系”的原则之一:即学生的阅读水平指数直接等于其能胜任的最大难度的测试文章的难度指数。
2.3.1测量工具
该分析工具主要从两个维度来衡量读物难度,即语义难度(Sematic Difficulty)和句法难度(Syntactic Complexity)(Lennon&Burdick,2004)。文本复杂度的测量单位是Lexile值(Lexile mesurement,L)。
蓝思文本分析器衡量语义难度的基本理念是词汇频率。一个词汇在阅读中出现的頻率越高,即越常出现,读者就会越熟悉,相应阅读起来的难度就会越低,反之亦然。词汇频率是通过大型语料库计算得出的频率。具体计算方式为:在6亿词汇量的语料库中,计算出某一词汇在每五百万词中出现次数的对数(Log),并以此对数作为词汇频率。
分析器测量文本的句法难度是通过易读性公式进行计算的。计算一篇文章的难度时会先将文章分成125到140个不等的单词分段,通过一个代数公式(Lexile equation),把该片段的词汇频率和句子长度综合运算,得出每一片段的蓝思值,最后再根据对所有片段的蓝思值进行平均,从而计算出这篇文章的蓝思值。
2.3.2文本难度指数
经过文本收集和预处理,小组人工将4万多篇英语文章和近1万本英语小说一本本导入蓝思文本分析器,测量每一本的蓝思值,并将该指数标注在预处理表格中的文本难度的空白部分。由于篇幅有限,该论文仅列举部分英文文章和小说的信息标注结果,英语文章以CET4阅读和China Daily为例,英语小说以简·奥斯汀的代表作《傲慢与偏见》(Pride and Prejudice)为例。在测量所有读物的蓝思值后,我们统计了这些读物所在的蓝思值区间,为了符合预计要求的文本读物难度,即文库中的读物难度指数均控制在500L-1900L之间,该指数区间外的文本将被剔除。
2.4系统开发
2.4.1网站技术分析
本项目建设的大学生英语分级阅读智能文库以网站形式呈现,网站在Ubuntu操作系统环境下运行,利用Mysql数据库软件创建数据库,主要开发语言是PHP,图片的处理工作使用了Adobe Photoshop CC 2019,并对网页进行不断优化,提升用户体验。由于PHP的执行网页速度较快,开发性和延展性良好,所以我们选择了的网站后台开发语言是PHP。数据库管理系统我们使用了MySQL,可视化操作界面是PhpMyAdmin,直接通过网页远程操作位于云服务器上的数据库。网站框架使用了CSS、HTML5和JS。CSS框架简化了web前端开发的工作,提高了工作效率。HTML5框架可以让用户拜托对平台的依赖,用户打开浏览器,直接就可以访问到所需的信息;用户可以离线使用,也能对页面文档进行缓存,下次访问时更加快捷;并且HTML5具有跨平台的特性;JS框架安全性高,不被允许访问本地的硬盘,且不能将数据存入服务器,不允许对网络文档进行删除和修改,从而有效地防止数据的丢失或对系统的非法访问。
2.4.2建设策略
网页的设计和网页的制作涉及多方面的专业知识,因此在开发时我们先进行了全面规划,根据网站的内容与功能写好了需求计划书、确定了网站的主题,对网站进行整体的规划。另外对于网站相关素材的收集、开发和测试网站、网站域名空间的申请与备案提前写好了网站策划书。
网站以橘色和桃红色、白色为主色调,页面布局以简洁明了为主,在网站上方设置导航栏方便学生页面跳转。网站主要针对在校大学生阅读需求展开设计,保证网页的主题简洁和使用方便时网站建设的主要切入点,进行网站整体系统架构的规划。本网站主页面框架图如图2所示。
后台建设:
(1)阅读测试题库后台。阅读测试题库包含三个数据表:阅读题表、选项表和答案表,它们之间通过唯一的ID相联系,并且阅读题表含有不同的等级分类。通过MySQL的图形化界面PhpMyAdmin将经过处理的题库数据导入到数据表中,为题库后台提供数据支持。阅读测试题库后台处理流程主要有五个步骤::第一,接受浏览器返回的用户预估阅读水平情况信息;第二,题库中随机抽取相应试题;第三,将抽取到的土木转换为HTML文件;第四,将HTML页面文件发送到用户浏览器病显示给用户;第五,用户开始答题。
(2)读物后台。阅读文库为用户提供电子书的阅读和下载,它的实现过程不同于题库。电子书是以PDF和TXT文本方式保存在云服务器端的,我们用了一个浏览器显示PDF文件的脚本文件PDF.js,利用该脚本文件将位于云服务器上的PDF文件显示给用户。分级文库包含了一个阅读材料信息表,保存了所有文章和书籍的标注信息。智能文库的后台处理主要有五个步骤:第一,接收到通过用户测试得到的蓝思值区间和选择的某一读物类型;第二,通过算法将符合条件的书籍信息从书籍信息表中提取出来;第三,将提取出来的信息进行处理添加到HTML页面,并返回给用户;第四,如果用户选择阅读或下载该书籍,则通过书籍名计算出书籍文件的路径,然后根据书籍文件路径将书籍内容利用PDF.js显示给用户。
3测试效果与改进
为了发现网站存在的不足,研究小组在本校招募了由不同年级、不同学院的25名被试。经测试与分析,我们发现网站中存在的一些问题,并且在问题发生处增加质量控制措施。测试内容包含两个部分,即用户体验测试和网站测试。
用户体验测试中,我们获得了宝贵的用户反馈,如网站页面美观整洁,功能齐全;读物种类齐全,且自行下载,离线阅读;英语水平测试比较灵活,测试结果较为精准。值得改进的地方是文库下载的阅读材料中,遇到生词时不支持点击查词功能,我们的改进方法是试图开发英文字典词库链接技术,比如欧陆词典、朗文词典等,读者遇到生词可以点击查询。
网站测试中,我们主要进行了功能测试,弱网测试和性能测试等。负载测试,测试对象分别在一天中四个不同时间段登录网站,测试网站速度,同时通过相应的软来测试负载,能允许多少个用户同时在线。兼容性测试,测试对象在不同的浏览器下登录网站,观察网站页面外观是否一致,检测网站兼容性。测试结果是测试结果:网页能在多个浏览器中使用,页面布局整齐协调,界面分辨率合格,能夠显示全部功能,能在不同浏览器中使用,但低版本浏览器比高浏览器中的性能要差一些,需要使用滚动条才能显示所有界面。其他功能正常。我们提出了改进方案,即优化网站内部页面布局,精简页面,以方便用户能够快速的找到所需要的页面。
4结论
中国大学生分级阅读智能文库的建设遵循了我们自行构建的“分级量化体系”,是专门面向中国大学生的现实阅读需求的量化分级阅读方案。在国内这一研究尚为空白的背景下,大学生英语分级阅读智能书库构建要解决的难题很多,包括对如何将读物的阅读难度进行量化,学生的阅读水平如何测试,选择何种阅读材料以满足大学生的现实阅读需求,收集到的文本处理,以及后期的系统开发等。这一智能书库结合了中国读者的实际阅读需求,帮助读者测量自己的阅读水平,找到适合自己水平和兴趣的读物,促进了大学生养成持续良好的英语阅读习惯,提高英语阅读能力。
参考文献
[1] Krashen,S.D.Principles and Practice in SLA[M].Oxford:Pergamon Press,1982.
[2] 王连双.大学英语阅读教学中的分级阅读模式研究[J].吉林广播电视大学学报,2016.
[3] 胡凤娟,程宁宁,王宏宇.从“双面假设”理论谈英语阅读分级教学[J].教学与管理,2010.
[4] 章辞.英语易读性研究:回顾与反思[J].湖南工程学院学报,2010.
[5] The Lexile Framework for Reading[J].Popular Measurement,1998.
[6] 罗德红,余婧.美国蓝思分级阅读框架:差异化阅读教学和测评工具[J].现代中小学教育,2013.
