
古籍缺字数据库建设与可视化项目管理研究
2019-10-26 05:23:54吴志勇韩小荆
图书馆理论与实践 2019年9期
吴志勇,韩小荆
(1.湖北大学新闻传播学院;2.武汉大学文学院)
词汇是语言和语言学的基础。房山石刻经文(以下简称“房山石经”)作为古籍的重要组成部分,其中的汉字与悉昙梵文为宗教学、汉语言文字学、艺术等领域提供了多种研究视角。根据古文字字形与现代汉字的对应关系,古文字大致可以分成三类:已识字、歧释字和未识字。本文研究对象为第三种,即尚未得到考释、无法隶定且没有对应的现代汉字的古文字。[1]本文沿用台湾学界整理古籍的惯用,称其为缺字。在整理房山石经过程中,尽管有大量文字可通过现有字库表现出来,但仍有一些缺字游离于各种字库之外。本文以校勘、整理《大佛顶陀罗尼》个案为突破口,探讨古籍缺字数据库的内容建构与流程管理的一些思路与视角,期望引起学界对项目流程管理的更多关注。
1 研究现状
1.1 字库研究
学界和业界把汉字字库和相应的输入法认为是衡量古文字数字化处理水平的一项重要参考指标。古籍整理过程中会遇到大量生僻汉字,可通过方正超大字符集、SuperCJK超大字符集,或日本“今昔文字镜”等字库进行查询,但异常现象时有发生。尉迟治平等根据《广韵》《集韵》《汉语大字典》等古籍,对五千多个中文汉字字符进行了造字处理,并开发了汉字超大字符集输入法,[2]弥补了ISO10646字符国际编码标准与Unicode统一编码方案中的缺陷。华中科技大学创建了13个甲骨文子字库和24个金文子字库的通用古文字字库。[3]业界和学界的共同努力,为古籍数字化进程起到了重要的推动作用。
1.2 古籍缺字造字研究
《说文解字》将9,353个正篆分别归入540部首下,实现了汉字字形与字理的初步规范化管理。现代汉字构形学理论主张从部件功能和组合方式等方面来分析汉字的构造。李晶认为,基于字型结构的汉字造字数据库中最基本的信息是汉字结构描述信息、部件描述信息以及汉字索引信息。[4]赵彤通过分析小篆的结构特征,按照设计的汉字构造的关系模型和部件位置与功能的描述方式,使用数据库软件Microsoft Acess尝试建立一个汉字字形数据库的样本。[5]台湾“中央研究院”提出以部件为基本构型单位的“汉字构型资料库”,中华电子佛典协会CBETA提出用大五码(BIG5)为构字部件,[6]这两种“组字式”纪录方式都在一定程度上完善了现有字库。
1.3 项目流程资产管理
项目流程管理主要涉及项目与任务的流程分配、进度跟踪、人员安排等,同时也能对数字资产进行数据存储、查询、版本控制与安全管理。20世纪90年代起,CBETA开始佛典数字化,他们首创的佛典古籍的数字化流程[7]具有重要的指导意义。北京大学释法幢[8]从作业流程、技术规范与技术研发角度对这个流程进行了拓展。北京大学叶少勇先生对梵巴文献校勘中的信息处理提出了有意义的写作规范。中华书局下属的“籍合网”平台被认为是目前国内权威的古籍数字化与古籍整理门户网站,该平台提供有标点、注释、校勘、翻译等在线编辑模块,能极大提高项目管理的效率。
近年来,生产管线(pipeline)的理念在数字媒体行业中引起了极大关注,一些影视节目制作开始有意识地运用项目管理思维与相关技术组织生产,部分公司已经开始部署相关商业软件平台。[9]工作流按应用领域主要分为专业的Alienbrain(Avid)等商业流程处理系统,以及Taverna、Kelpler、VisTrails、DimStiller等科学工作流系统,也包括Project(微软)、丁丁(阿里巴巴)等民用项目管理系统。工作流管理本质是多个用户之间按照某种预置规则传递文档、信息或任务的自动过程,[10]其需求目标是效率的最大化。对于小型工作室而言,在古籍缺字整理中,通过借鉴国外数字媒体行业中数字资产管理平台以及流程管理平台,完成项目流程的建构与相关的海量数字资产管理,能够将所有的缺字建档纪录,将缺字的注音、笔画、部首、通用字等相关信息,形成一个完整的缺字数据库,最终汇集到“汉字资料库”中。
2 古籍缺字数据库建设的可视化项目管理原则
2.1 可视化项目流程管理中的团队衔接,任务迭代
《大佛顶陀罗尼》中的疑难汉字并不多,但是如果把整个房山石经中的未被收录的汉字累积起来,将是一个较小型的数据库了,因此需要采用更高效率的项目管理方式来完成这个庞大的任务。本项目主要基于云平台的项目管理软件Ftrack完成。
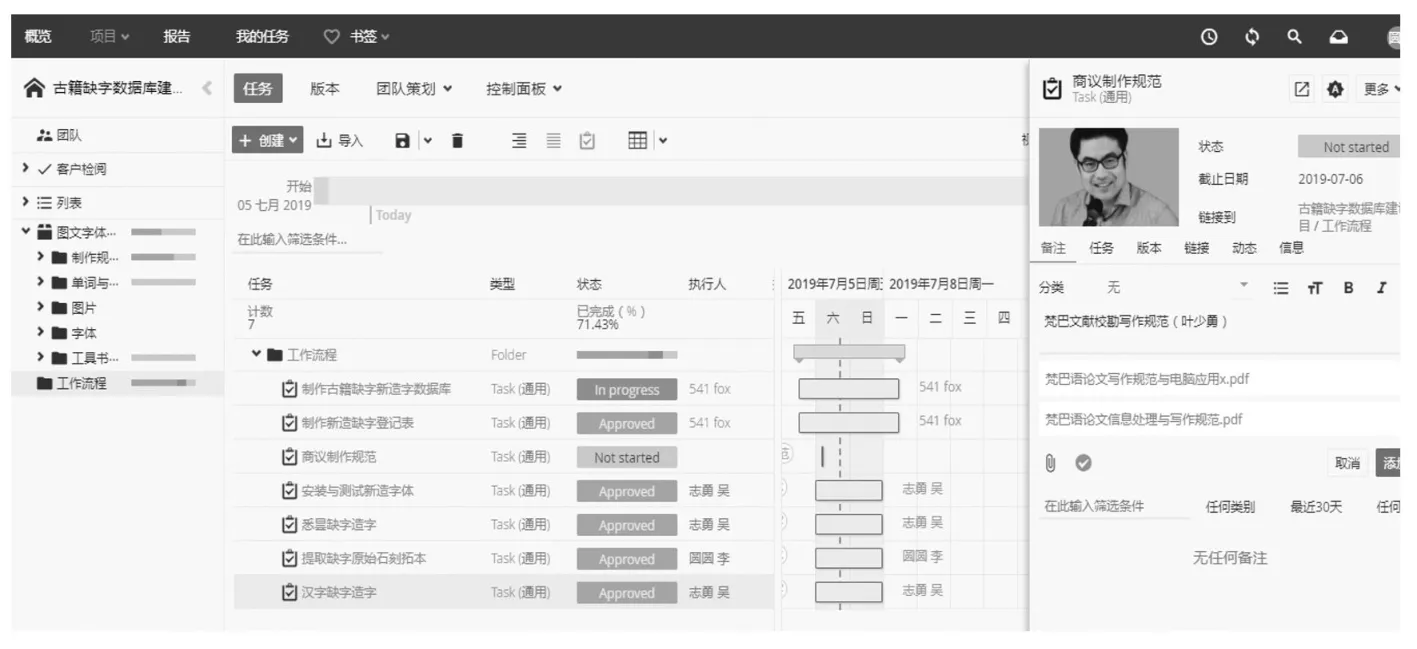
图1 缺字造字的项目管理
图1 所示是可视化项目管理中的计划任务部分截图,左边列表部分可看到主要任务清单以及完成进度(工作状态、人员分配、任务描述、到期日期、工作时间);中间任意的任务都可创建子项目、为项目组成员远程审阅提供相关资源文件,也可调用本地的相关应用程序下载相关数字资产;表格的右边是工作日程甘特图等内容运用项目管理系统,可通过对数字资产、计划任务、人员分工等主要目标的可视化跟踪与调度,形成一个“资产更新,团队衔接,任务迭代”的工作流。
古籍缺字数据库建设可通过纵向和横向两个视角来完成。第一,横向视角,或称为数字资产管理视角。对拓本图片、汉字缺字字体、悉昙缺字字体等每一种文件类型,都会从案例与规范、需求与原型、模板与设计3个管线步骤进行。收集学界、业界对于该拓片或字体的处理方法,通过借鉴,了解行业规范与标准,制定出适合本项目的规范。图片或字体的需求确定后,形成一个原型草图,并设计出该类文件制作的通用模板。用于进行后续的设计、开发等环节。如图1中的“缺字登记表”,通过版本收集,获得一手资料,在整理中研究、制定规范和标准,发现疑难,联系相关专家进行解答,最终形成一个规范化的表格文档。第二,纵向视角,或称为流程管理视角。本数据库以学界公认的487句的《大佛顶陀罗尼》为蓝本,研究其文字、读音,将正确的悉昙梵文与缺失的悉昙梵文字体以及字库中缺失的汉字重新造字,还原完整的悉昙、汉字对照版本,提炼汉字、悉昙对照数据库,以便于后续的查询检索。作为一种典型的过程管理,必然存在诸多管线环节的衔接与交替。从面向对象的角度来说,信息、文件夹、数字资产、任务、里程碑都是对象,存在着“新的”“进行中的”“审阅的”“暂缓的”“关闭的”“提醒的”“丢弃的”“完成的”“通过的”等工作状态。对于不同的环节,设定有不同的任务,每个任务中分别由不同的管线组成,常见的设计、测试、除错、讨论与审核等等共同任务,也会有面对特定目标的具体任务,如数据库开发部分,将任务分解为:数字资产分类、软件界面设计、交互脚本设计、预览发布等目标。同时每个任务又将不同的管线分配到不同的人,他们需要使用甘特表关联到具体的日程等。
在研究过程中,通过提出问题、制定计划、调研考察、信息反馈、专家论证、制定方案等途径,对现有系统进行总结,提取合理框架,并对本系统架构、功能与接口等等进行合理化规划。力图用最接近目标需求的方法来规划文献整理工作与各项任务。以上项目完全通过Ftrack在线系统来完成,从用户体验的视角来看,该平台能够满足古籍缺字整理的所有环节。
2.2 数字资产管理中的标准统一,格式规范
古籍缺字数据库建设过程中元数据转换涉及到图文采集、元数据编目、数据存储、信息发布等方面,必须严格遵循统一标准才能确保数据库建设的质量和项目管理平台的规范性和可用性。如,对于字库,计算机编码采用的是“一字一码”的方法,无论采用何种字体,区位码都是唯一的,如“子”的unicode都是uni5851,造字时将新造的不同风格的字体的序号保证与ISO10646字符国际编码标准与Unicode统一编码方案等一致。①检索规范。吸取了各类汉语词典与梵文词典的优点,无论是汉译,还是罗马转写都必须可进行汉字检索(按照悉昙18章次序进行检索)或梵文检索(按照Monier-Williams Sanskrit-English Dictionary、梵和大辞典等梵文词典的次序进行排列)。本数据库也配有专门的检索表,用于快速定位到相关词条。②图文规范。本数据库区别于传统词典的最大特色是收录了拓本图片,因此编写规范与传统的梵汉词典有很大的不同。如图4所示,在数据库制作中,图文的版式设计采用表格方式,并且数据库第2列(石刻梵文)、第5列(石刻汉字),分别收录了《房山石经》中石刻拓本中的汉字与梵文拓本,保留了原始石刻的雕刻风格的字迹风貌。为了节约版面,我们删掉了重复的或者略有差异的字型。③词语典型规范。在词条制作规范上,本数据库中第6列(所在例句),选用了《大佛顶陀罗尼》中的典型词语,并采用“悉昙回译—罗马转写—汉语”三行上下对照,符合传统古籍整理的规范。第7列(序号页码)给出了该词语在原始石刻拓本中的序号和页码,便于查询。④释义规范。选用《梵和大辞典》中的释义,个别未收录词语则选用《佛光词典》的解释,便于对照学习。
3 古籍缺字数据库建设的基本流程
从大佛顶的记载来看,经文于公元898年由行琳大师收集,公元1147年刻经。石刻为梵汉对照,但主要是汉字音译,梵文只有580多个。为了准确还原原始的汉字,古籍缺字数据库的建设流程主要分为以下几个步骤。
3.1 提取缺字原始石刻拓本
从字符范围看,石刻中绝大部分字体都可以在宋体字库、SuperCJK字库中找到,少数偏僻的字体,上述字库都没有收录。根据石刻拓本,通过检索、核对,将石刻中超出SuperCJK超大字符集的27个汉字的拓片剪裁下来(如图2),将这些文字汇总后作为造字的依据;从编码方式看,对于同一文字不同写法,刘根辉等人采用“不同的字形设立不同的字库,建设不同的子字库”的办法。这种办法符合“一字一码”的基本要求,也可以形成一个容纳同一个字的不同字形的古文字数据库,从而便于后期的检索和使用。从图2中可以看到,有些文字字形略有不同,但基本可归为同一字体,推测原因为本拓本为同一时期石刻,因此不必创建“子字库”。

图2 拓本疑难字符(部分)
3.2 缺字造字
由于汉字的独特性,几乎所有字库建设都要对偏旁部首或者是部件进行事先规划,从而为后续文字制作提供便利(即使是小型字库也需要6,000多个汉字)并保持风格一致。目前的字库都是以整个汉字为存储单位的,不论是点阵字库还是曲线字库(如TTF字体),基本制作方法都是基于位图的扫描、勾线两个环节,即需要对每个汉字进行整体扫描,使用工具软件对位图文件进行描边修整、调整结构、设置属性、分配区位等。这里涉及到两个关键的问题。①字体的存储方式。林光明先生制作的悉昙字符,将20多位不同的书法家的作品统统放在同一个字库下,这种方式虽然便于集中管理,但是给输入法也带来了诸多不便。本文主要采用刘志基先生曾提出的“将各个类别的古文字字形分出层次,依层次再建立较小的字库”方案来完成,即对于同一unicode码的异体字,另行做一个单独的子字库。②字样选取标准,有专家以毛泽东书古诗词手迹、题词系列手迹为样本,提取有效不重复字一千六百余个,再运用文字学研究中的构形理论、字源理论、字族理论和模块理论,分离出草书偏旁符号和字根符号,并对其进行有机组合,形成6,000多个字符的“草檀斋毛泽东字体”。[11]图2中的异体字,如何选用代表性的字符,需要从字形结构标准、笔形标准、笔画标准、字形标准、字体演变、字符流通性等视角来考察。
基于以上考虑,最终确定使用造字程序,将图2中的27个汉字中的24个字符制作成标准的ttf字体,命名为:大佛顶陀罗尼难字.ttf。为了交流的方便,我们采用标准的宋体部件。当然,如果有必要,也可以根据其他字体的已有部件完成相对应的字体。
3.3 安装与测试新造字体
将新造的“楞严咒难字.ttf”字体安装或拷贝到c:windowsfonts中;在word等文本编辑器中使用新造的字体,若没有正确拷贝造字文件,在doc文档中对应的位置会显示出一块空白。
3.4 制作新造缺字登记表
为了准确核对新造字体与原版拓本之间的差异,制作“新造缺字登记表”。在尚未拷贝造字文件到c:windowsfonts中的情况下,可通过bmp图片(含新造汉字以及所对应的梵文)查看造字情况;在已经拷贝造字文件的情况下,可通过Word文本版,采用《大佛顶陀罗尼》中的例句作为案例,查看造字情况。二者内容完全相同。
3.5 制作古籍缺字数据库项目管理E-R模型
在传统的计算机领域,E-R模型往往用于描述数据结构和数据走向,对该模型的深入研究有助于古籍缺字数据库的功能模块设计。常见的字体信息包括:字体名称、家族名称、版本号、版权信息、创建时间、修改时间、版权信息。而对于拓本重建字符,还需要补充字体本身的一些信息,如:序号(unicode或id)、石刻梵文拓片(图片)、新造悉昙字符、罗马转写、石刻汉字拓本、新造汉字、所在例句、字符来源等等。数据表是古籍缺字数据库建设和管理的基础,通过合理规划各种数据表的关联关系,设计出项目管理平台的功能模块。
Ftrack部署在CentOS服务器上,使用MariaDB作为其数据库。资产元数据采用多个具有实体、属性、值(EAV)的传统数据表(资产内容、编码解码方法、源文件出处、所有者、权限等等)来完成,既兼顾了固定流程,也留出了让用户自定义的余地。各种数据表多视角呈现工作流程,功能细分复杂。本文结合实践设计的部分古籍缺字数据库建设E-R关系模型见图3。
3.6 古籍缺字新造字数据库
对佛经文字中的生僻字、疑难字、同形字进行归纳,建立“异体字表”,[12]对匡正订补部分缺字具有直接的借鉴意义。秉承此理念,本数据库制作过程中将字形(汉字石刻拓本、对应的梵文拓本)、读音、例句、词义等按照数据库的方式进行组织(见下表),形成词典的原型,为后续相关研究提供图像、文本等数字资产,其强大的检索功能也可为后续研究提供更多便利。
图3 古籍缺字数据库E-R关系模型(部分)
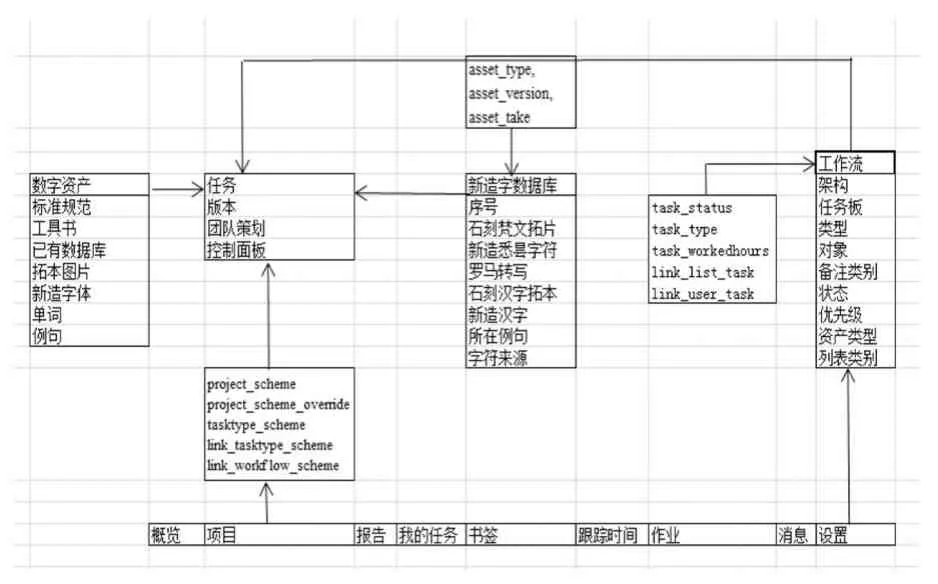
表 缺字新造字数据库(部分)
4 结论
印刷出版、广播电视、影视制片等行业正迈向以工作流管理为核心的数字化、网络化的历史新阶段。文章通过可视化项目管理确保文件安全、计划任务和小组分工的无缝融合,以《大佛顶陀罗尼》为案例,通过商业协同编辑平台由项目组成员在教学科研过程中不断积累、修改、完善,其流程中包含的各类子环节,通过成员的技术素养的融合与作业流程的规范化,可以形成高效率的流程管线,较好地对字体、图片、文档等数字资产进行系统化整理,形成完善的数据库。古籍缺字新造字数据库直接弥补了现有字库与汉语词典的不足。此外,从可视化项目管理视角对古籍数字化建设进行研究具有重要的实践意义。可作为古籍数字化可视化的参照样本,从而引起更多学者关注这个领域。
猜你喜欢
中国书法(2023年4期)2023-08-28 06:02:08
汉字汉语研究(2021年1期)2021-06-11 01:14:52
汉字汉语研究(2020年3期)2020-12-14 08:00:04
销售与市场(营销版)(2020年9期)2020-11-25 13:38:24
辽宁省博物馆馆刊(2020年0期)2020-08-13 09:16:06
黄河·黄土·黄种人(华夏文明)(2018年11期)2018-12-05 03:19:12
电子世界(2018年7期)2018-04-26 08:51:35
小学阅读指南·低年级版(2017年1期)2017-03-13 19:59:56
警察技术(2015年4期)2015-02-27 15:37:36
电子知识产权(2013年5期)2013-04-14 06:18:12
