
基于LSTM与孪生网络的序列图像视觉定位技术
2019-10-25 06:29:50梁欣凯宋闯郝明瑞赵佳佳郑多
现代防御技术 2019年5期
梁欣凯,宋闯,郝明瑞,赵佳佳,郑多
(复杂系统控制与智能协同技术重点实验室,北京 100074)
0 引言
随着时代的发展,军事领域对精确定位的需求越来越迫切。一般而言,明确自身和敌方位置,是完成路径规划、避障、精确打击、群体协同等任务的基础。因此,定位技术是一项基本技术,关系着军事领域多方面的应用与发展。
过去以及现在,全球定位系统(GPS)、北斗系统、伽利略系统凭借其能够提供高精度的定位与授时信息,已经在越来越多的领域发挥着重要的作用。然而在复杂的野外环境或室内环境,由于建筑物或障碍物等遮挡影响,GPS等定位系统[1]无法有效工作,因此需要寻求其他的定位方式,但是最近提出的射频定位技术,如基于WiFi或蓝牙,却存在需要前期部署的局限。
为了克服上述困难,研究人员借助图像这种信息量丰富的载体,提出了视觉定位技术。传统的视觉定位技术从给定的图像中提取线索或特征如SIFT[2]匹配寻找地理参考系图像库中具有相近特征的图像,来输出对应的位置和姿态信息。其进一步延伸出视觉同时定位与地图构建技术(visual simultaneous localization and mapping,vSLAM[3])和运动恢复结构技术(SFM[4]),这些技术广泛应用于室内机器人如扫地机器人等。但是该类技术存在两方面问题:一方面,并不是所有的线索或特征都对定位有效,尤其当光照、天气环境等发生重大变化,或出现大范围遮挡、小范围高动态变化、重叠或运动模糊等,以上方法提取的特征随之发生严重畸变,造成图像间特征匹配错误,最终导致定位失败;另一方面,传统视觉定位技术往往需要构建场景地图,而地图的大小与场景范围相关,所以包含数以百万计的特征元素大场景地图下的特征匹配的实时性遭遇严重考验。因此需要提取跟定位更密切相关的局部特征与全局特征,增强对非位置信息参数变化的鲁棒性。
近些年,借助卷积神经网络对数据高级抽象特征提取的优势和循环神经网络对序列数据间关系的理解,深度学习技术在目标检测、语音识别等领域取得巨大成功。基于此,部分研究人员将深度学习技术与视觉定位相结合,提出了基于位姿回归的PoseNet[5]及其基于贝叶斯网络的改进[6];为了解决PoseNet中全连接层计算效率低下的问题[7],利用LSTM处理卷积网络输出1 024维向量间的关系信息,进而预测位姿;为了将视觉定位技术应用于序列图像[8],将双向long short-term memory(LSTM)应用于PoseNet改进。尽管以上的深度学习定位算法对环境变化和大场景表现出良好的适应性,并且能够利用序列图像位姿关系进行位姿约束,但是其缺乏图像间运动视差信息、图像间位姿信息、图像间像素关系信息相互的耦合,进而缺乏场景三维结构特征的约束,其定位精度提高存在天然瓶颈。
为了解决以上所提到序列图像视觉定位面临的问题,本文研究了基于LSTM与孪生网络的序列图像视觉定位技术,利用CNN对目标特征识别的优势与LSTM能良好提取时序信息的优势,通过孪生网络获得图像间运动视差信息与LSTM获得图像间位姿关系信息的耦合,依靠端对端方式,学习图像像素特征、图像对应场景三维结构特征与图像对应的位姿信息的映射关系。最终,通过开源数据库Microsoft 7-Scenes和仿真生成的协同跟踪样本与卫星图像样本,验证了所提出算法的准确性与有效性。
1 视觉定位基本原理
视觉定位的任务就是确定任意坐标系下一张图像所对应的位姿信息。视觉定位技术[5-10]首先建立带有未知参数θ的模型f(x,θ),然后通过最小化代价函数获得参数θ值,最后通过参数已知的模型预测目标图像位姿信息。

(1)
式中:dp和dq分别是预测位置值、姿态值与真实值之间的距离函数,通常为L1或L2范数;β是一个平衡位置与姿态误差的手工权值。
2 基于LSTM的序列图像视觉定位技术
LSTM是一类特殊的循环神经网络(RNN),其适合于处理与预测时间序列中间隔和延迟相对较长的重要事件;孪生网络能够解析2张图像间的对应关系,广泛地应用于双目立体匹配[11],运动视差[12]、光流[13]等方面。基于此,本文所构建深度神经网络的主要目的是通过运动视差信息与位姿时序信息的相互耦合,进而利用图像间位姿关系信息的一致性缩小图像回归六自由度位姿的误差,进而实现精确的视觉定位。
2.1 网络结构

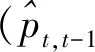
2.2 损失函数
PoseNet[5]指出分别训练位置与姿态的效果远远不如位姿耦合训练,因此本文将位姿耦合起来作为损失函数(参考式(1))。由式(1)可知,存在起平衡位置损失与姿态损失作用的超参数β。由于不同应用场景β的选择不同,因此为了避免费时遍历选择合适的β数值[5],针对如何人工选择β值进行了经验归纳,但是该基于专家知识的方案难以直接应用于实际场景,因此需要一类β值的自动学习策略。

图1 基于LSTM的六自由度位姿回归网络结构Fig.1 Six-degree-of-freedom pose regression network structure based on LSTM

图2 基于孪生网络的图像间位姿变换回归网络结构Fig.2 Image reconstruction regression network structure based on siamese network
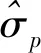

(2)
式中:D为连续图像的帧数;
(3)
(4)
虽然式(2)解决了β自动寻优的问题,但是该损失函数依然没有包含关于图像间关系信息,因此借助基于孪生网络的图像间位姿变换回归网络输出量,建立如下的损失函数:

(5)
式中:
loss_var(t)=var_pos(t)+var_att(t);
3 仿真实验
本节分别在开源数据库Microsoft 7-Scenes和仿真数据库验证所提出的基于LSTM与孪生网络的序列图像视觉定位方案的有效性和准确性,并与其他主流的深度学习视觉定位算法进行了比较,表现了本文所提出算法的优势。
3.1 数据库样本
Microsoft 7-Scenes:该数据库包含了7类典型室内办公室场景的RGBD图像数据,该数据库由手持Kinect采集,像素分辨率为640×480。由于手持采集再累加室内因素,因此该数据库包含大量运动模糊、重叠、纹理缺失的图像数据,所以该数据库是进行视觉定位与跟踪性能评价的常用数据库之一。
仿真数据库:包含红外SE-Workbench-IR仿真软件生成的协同跟踪图像与基于卫星图像的机场数据如图3、图4,像素分辨率为640×480。以不依赖通信的协同编队定位为出发点,通过前视摄像头以相距目标150~650 m(采样间隔10 m),相对俯仰角、滚转角、偏航角在-20°~20°(采样间隔为3°)进行采样,预测目标与自身的位姿关系;以无人机自主降落为出发点,依靠距机场直线距离9 km左右的卫星图变化得到不同距离不同角度机场图像。图3、图4分别为以上2种数据库的典型样本。

图3 红外SE-Workbench-IR生成的协同跟踪图像Fig.3 Collaborative tracking image generated by SE-Workbench-IR
3.2 网络训练
为了强算法的鲁棒性,对原始图像进行如下增广处理:如增加高斯与椒盐噪声,左右上下翻转,亮度对比度变换等操作,最终为了适应于网络结构输入的像素条件,将图像裁剪成224×224,作为输入量。

图4 基于卫星图像的机场数据Fig.4 Airport data based on satellite imagery
本文利用ADAM求解器进行优化处理,其中ADAM的权值β1=0.9,β2=0.999,ε=10-10。将初始学习率设置为0.000 2,并根据训练迭代次数分阶段将学习率进行指数下降。此外,本文基于tensorflow框架实现所提出的算法,在NVIDIA Titan X GPU训练120 000次,批处理量为32。
3.3 性能分析
本文所提出算法在以上提到的数据库进行定位验证,其实验结果如表1、表2与图5所示。
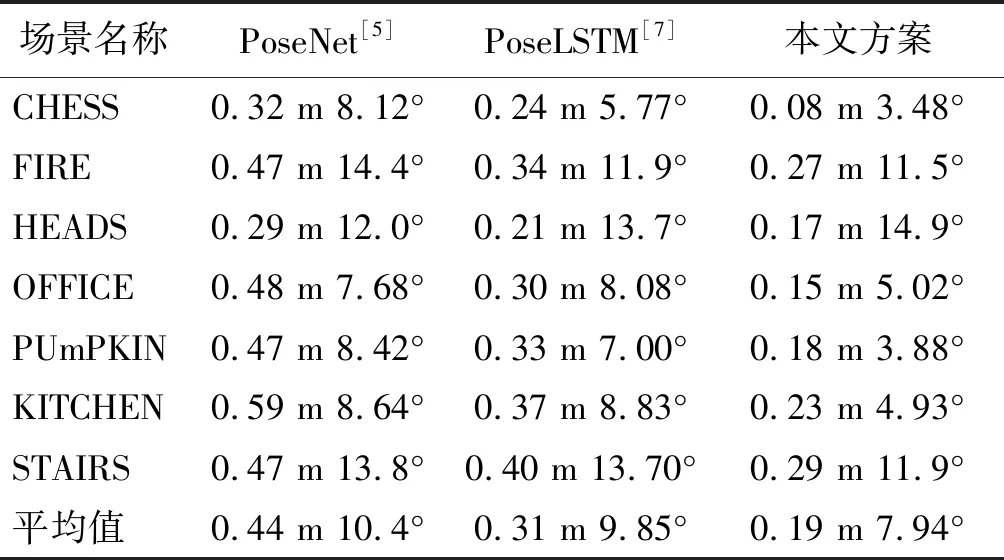
表1 本文算法与其他基于深度学习视觉定位算法在Microsoft 7-Scenes的定位误差均值的对比Table 1 Comparison of the median value of the algorithm in this paper with other depth-based learning visual positioning algorithms in Microsoft 7-Scenes

表2 本文算法在仿真数据库的定位性能Table 2 Positioning performance of the algorithm in the simulation database

图5 基于LSTM与孪生网络的视觉定位算法在 7-Scenes的定位效果(红圆点为真实位置、蓝×为预测位置、绿方块为定位误差)Fig.5 Positioning effect of visual positioning algorithm based on LSTM and siamese network in 7-Scenes (Red dot is the real position,the blue × is the predicted position,and the green square is the positioning error)
通过表1可以看出,本文提出的基于LSTM与孪生网络的视觉定位技术无论在位置回归方面还是姿态回归方面均超过了之前的基于深度学习的视觉定位性能。
通过图5可以看出,左图分别为预测的位姿信息和真实的位姿信息,坐标分别为x,y,z,单位为m,右图为位姿误差坐标系与单位与左图一致。虽然7-Scenes数据库自身具有运动模糊,光照剧烈变化等对于视觉定位精度产生影响的特性,但是该方案体现的定位效果已经可以满足室内应用需要,进一步验证了本文方案的有效性与可靠性。
通过表2可知,在大范围场景下,本文提出的视觉定位依然具有良好的定位性能,同时其运算时间并没有随着场景范围的扩大而增加,其运算时间在百毫秒量级,远远优于传统视觉定位方案。(因为机场数据没有真实的姿态角度信息,因此没有进行评判。)
由于协同跟踪图像背景始终发生变化,在没有经过严格前后景分割的基础下,SIFT算法始终无法准确估计目标对象相对于自身的位姿关系,该试验进一步证明基于LSTM与孪生网络的视觉定位技术不仅仅能够克服场景变化的影响而且能够在捕获图像中的感兴趣显著区域具有优势。
4 结束语
针对军事领域迫切需求的视觉定位技术,基于LSTM与孪生网络的序列图像视觉定位技术,继承了深度学习提取高级特征的优势,突破了遮挡,纹理不清晰,重叠等传统视觉定位技术的桎梏,达到良好的定位精度,满足实际应用基本要求。此外,该算法在仿真数据库的应用,也为飞行器编队协同飞行、精确制导打击等方向应用奠定了基础。
猜你喜欢
导航定位与授时(2020年5期)2020-09-23 03:05:00
铁道通信信号(2020年9期)2020-02-06 09:16:06
知识经济·中国直销(2018年3期)2018-04-12 06:43:37
财经(2017年2期)2017-03-10 14:35:35
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
财经(2016年6期)2016-02-24 07:41:51
