
面向未知数据流的数据中心网络调度算法研究
2019-10-24 05:40陈金鱼
长春师范大学学报 2019年10期
陈金鱼
(厦门软件职业技术学院,福建 厦门 361024)
数据中心网络承载着大量应用程序流量。一部分应用有着严格的限期,因此最小化数据流的完成时间是数据中心网络的主要目标[1]。对于有着严格截止时间的应用,错过数据流的截止日期会使应用性能急剧下降[2-4]。数据中心网络是一个具有混合数据流的环境,具有严格截止时间的数据流需要在其限期前完成任务,而普通数据流(即没有严格截止时间的数据流)则需要尽快地完成任务。现有关于混合数据流调度的研究是基于完整的数据流先验知识(如流的大小),但是在大多数实际应用场景中,并不能直接获得这些先验知识。本文提出一种实用的数据中心网络信息无关流调度算法(DCIA),该算法能够在没有先验知识的情况下最小化数据流的完成时间。
1 系统模型
DCIA算法的核心思想是利用数据中心网络交换机中的多优先级队列,并实现多级反馈队列,以减少短数据流的完成时间。对于缺乏先验知识的流调度,LAS策略是最小化平均流完成时间的有效算法之一[5]。由于数据中心网络的流量具有长尾分布的特征(即短数据流的数量较大),因此LAS策略尤其有效。但是LAS策略需要直接在交换机上比较每个流传输的字节数,然而现有的交换机却不支持这一操作。另外,虽然数据中心网络流量分布符合长尾理论,但数据流在时间和空间上的表现都是不同的。例如,多个长数据流可能在某时刻经过某一交换机的端口,采用LAS策略会引起“护航效应”,使流调度算法的性能变差。本文算法根据优先级调度不同队列中的数据流,根据先入先出算法调度同一队列中数据流。当某数据流所传输的数据量大于预设阈值,该数据流会从当前队列i降级到队列i+1,直到进入最后一个队列(即优先级最低的队列)。
由于短数据流具有更少的完成时间,因此本文算法优先调度短数据流。这样一来就能降低算法的平均数据流完成时间。同时通过将长数据流降低到优先级较低的队列,能有效地避免护航效应,有助于最小化长数据流的响应时间。
DCIA算法在终端主机上进行分布式的数据包标记。假设有K种优先级Pi(1≤i≤K),有K-1个降级阈值θj(1≤j≤K-1)。当一个新的数据流在终端主机初始化时,算法将其标记为最高优先级P1。当该数据流所传输数据包的数量大于等于阈值θ1,该数据流会被降级到优先级P2。DCIA算法的难点在于如何设计合理的降级阈值,以最小化平均的流完成时间。
2 问题建模
本研究目的是最小化平均流完成时间的最优降级阈值,将问题建模为线性组合问题,并求解出最优阈值的解析解。降级阈值取决于网络负载和流量大小分布,阈值会随着流量大小分布和负载在时间和空间上的变化而变化。假设在K种优先级队列Pi(1≤i≤K)中,队列P1具有最高的优先级,阈值θK=以及θ0=0,数据流i的大小为si。数据流大小分布的累计密度函数为Ω(s),用pj表示数据流大小在区间[θj-1,θj)内的百分比。其中,定义pj=Ω(θj)-Ω(θj-1)。第j个队列的平均时延为Dj。因此,数据流的平均完成时间是其中,su是被标记为最低优先级的数据流的剩余大小,即su=s-θmax(s),θmax(s)是比s小的最大降级阈值,jmax(s)是阈值的索引。我们有以下的最优化问题:
(1)
为了简化问题,将θ替换为p。根据排队论的相关理论,第l个队列的平均等待时间为Dl,计算公式如下所示:
(2)
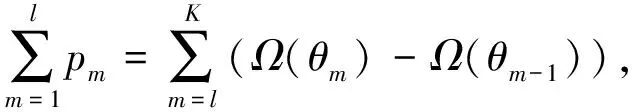
(3)
由问题(3)可知,平均流完成时间的上界与数据流的分布无关,且只与p有关。一般来说,问题(3)是NP-hard。即在给定一组pj的值的情况下,很容易就能计算到问题(3)中的目标函数值。但要想找到是函数值最大的一组pj的值,就可能需要穷举出所有pj的可能值。因此本研究通过分析问题的性质来推导出问题的解析解。
在优化问题(3)中,由于流量负载β是小于等于1,于是有以下关系:
(4)
由(4)可以得到以下关系:
(5)
3 算法模块与仿真实验
3.1 算法模块
标记模块负责维护每个数据流的状态,并根据数据流的优先级来标记数据包的优先级。该模块实现在系统的内核模块中,位于TCP/IP协议栈和系统流量控制模块之间。系统流量控制模块包括了过滤器、哈希表以及修改器3个主要部分。过滤器拦截所有传出的数据包,并将它们导向哈希表。哈希表的每一个表项是一个5元组(即源/目的地IP地址、源/目的地端口以及协议类型),该5元组定义了数据包所属的数据流类型。当接收到数据包时,首先为该数据包创建一个哈希表项(或识别它所属的数据流),并增加发送的字节数。修改器根据数据流的优先级来设置数据包的优先级。为了计算标记模块的开销,将算法实现在联想工作站ThinkStation P920上,并测量了处理器的使用情况。该工作站配置了一个英特尔至强Gold 5122处理器、一个华硕XG-C100C 10G网卡。结果表明,与没有使用该标记模块相比,使用该模块所引入的额外处理器开销小于0.5%。
交换机执行严格的优先队列机制,并根据优先级对数据包进行分类。采用了基于即时队列长度的拥塞标记。除了交换机的排队时延外,网卡的时延也是不可忽略的。由网卡等硬件带来的时延会严重降低应用程序的性能。为了解决这个问题,以线路速率对传输速率进行限速。
3.2 仿真实验
仿真实验首先采用一个由16台工作站组成的网络拓扑,这些工作站均连接到华为S1720-52GWR-4P 48口全千兆以太网络交换机。交换机的每个端口最多支持8个服务队列,工作站均为联想工作站ThinkStation P920。服务器安装了CentOS 7操作系统,内核的版本为3.10.0,往返时延为100 μs。还设置了一个较小的网络拓扑,用于测量高速网络中终端主机的排队时延。该拓扑由3个服务器和1个交换机组成。
本算法默认使用8个优先队列,并在每个端口启用拥塞标记。将拥塞标记的阈值设置为推荐的30 kB。使用两个真实的流量数据集:网页搜索流量和数据中心网络数据挖掘流量。
本实验开发基于客户端/服务器的通信模型,根据真实的数据集生成动态的流量,在应用层测量数据流的完成时间。安装在1台工作站的客户机应用程序定期向其它工作站生成请求以获取数据,请求服从泊松分布;运行在另外15台工作站上的服务器应用程序用相应的数据对请求进行响应。将本算法与数据中心网络数据传输协议(DTCP)进行对比。图1和图2分别是不同算法在小数据流和大数据流下的平均数据流完成时间。小数据流中数据包的大小在区间(0,1 MB]范围内,小数据流中数据包的大小在区间(1 MB,10 MB]范围内。由实验结果可知,本算法在小流量和大流量下均能获得较好的性能。
接下来评估本算法在延迟敏感应用程序下的性能。在16台工作站中,1台工作站用作客户端,15台用作服务器。客户端向15个服务器发送一个查询,每个服务器对查询进行响应。只有当客户端从所有服务器接收到响应时,一次查询完成。将查询完成时间作为性能度量。图3是两种算法查询完成时间的实验结果。由于交换机上启用了动态缓冲区管理和拥塞标志,因此两种算法均没有发生TCP超时。随着流量负载的增加,DTCP的平均查询完成时间也在增加。与DTCP相比,DCIA算法的性能相对稳定,并实现了低平均查询完成时间。
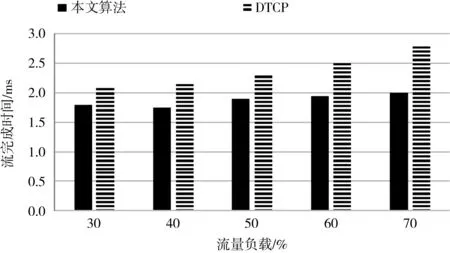
图1 两种算法在小数据流下的流完成时间
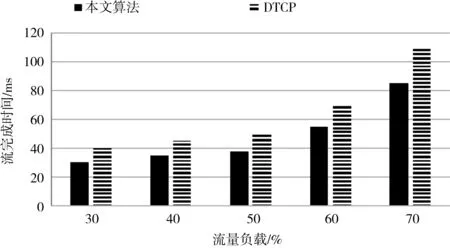
图2 两种算法在大数据流下的流完成时间
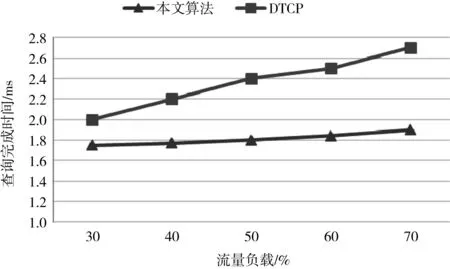
图3 两种算法的查询完成时间
4 结论
在一个信息不可知的数据中心网络中,DCIA算法利用商品交换机来最小化数据流的平均完成时间。通过仿真实验进行性能评估,实验结果表明,与现有方法相比,DCIA算法具有较好的性能。未来的工作将集中于利用不同的大规模网络,设置不同的真实场景,对该算法进行深入地分析评估。
猜你喜欢
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
电子制作(2019年24期)2019-02-23
军营文化天地(2018年2期)2018-12-15
网络安全和信息化(2018年6期)2018-11-07
网络安全和信息化(2017年8期)2017-11-07
产品可靠性报告(2017年7期)2017-09-05
西北工业大学学报(2015年3期)2015-12-14
