
去除光流中冗余信息的动作预测方法*
2019-10-24 07:45:34石祥滨代海龙张德园刘翠微
计算机与生活 2019年10期
石祥滨,代海龙,张德园,刘翠微
1.沈阳航空航天大学 计算机学院,沈阳110136
2.辽宁大学 信息学院,沈阳110036
+通讯作者E-mail:sxb@sau.edu.cn
1 引言
动作预测是在只给出部分观测的视频条件下预测正在进行的动作[1]。在分析视频中人的动作的方法中,光流是常用并且有效的特征。
光流主要的优势在于:其一,光流可以有效反映动作信息,包括运动物体的外形特征、运动物体的运动方向以及运动物体运动的快慢;其二,光流具有表观不变性,表现在视频中人的服装、外貌等不会影响光流的表现形式。
但是光流极易受外界环境的影响而引入无关的冗余信息。光流中的冗余信息主要可以分为三类:其一,背景中的冗余信息。无关背景区域的运动会引入冗余信息,例如背景中树叶的晃动等。其二,相机的运动。在实际场景中,相机是无法保持绝对静止的,相机的运动会给光流的计算带来冗余信息。其三,视频中人静止的光流信息。很多人都没有在意视频中人静止部分对动作分类的影响,在视频中,人并不是时时刻刻处于运动状态,人静止部分的光流数据对分类来说是一种冗余信息。
近年来出现了很多使用光流的深度学习方法[2-5],但是这些方法都没有考虑光流中冗余信息的影响,而光流中的冗余信息会降低动作预测的精度,因此研究去除光流冗余信息的深度学习方法很有必要性。
本文的主要贡献在于:
(1)提出了一种衡量光流中冗余信息的方法。
(2)检测视频中静止的部分,去除视频中静止部分对动作预测的负面影响。
(3)通过选取运动区域去除光流中无关背景中的冗余信息。
(4)评估相机的运动,消除因相机的运动带来的冗余信息。
(5)提出了一种基于深度学习的动作预测框架。
2 相关工作
Ryoo提出了积分词袋模型(integral bag-of-words,IBoW)和动态词袋模型(dynamic bag-of-words,DBoW)来解决动作预测的问题。在他的方法中,首先提取视频的时空特征,然后对这些时空特征建立词袋模型并以概率的形式求解动作预测问题。在他的方法中使用Hof(histograms of oriented optical flow)作为视频的时域特征,Hof特征是对光流方向进行加权统计,可以有效反映运动信息,但是Hof 特征忽略了光流的结构性信息。Wang等人[6-7]在动作识别中引入了MBH(motion boundary histograms)作为分析视频的特征描述子,MBH即为运动边界直方图,运动边界是对光流的微分,MBH 是对光流微分的一种统计。Wang 等人的工作证明了MBH 特征在动作识别中的重要作用,类似于Hof特征,MBH是一种统计量而忽略了光流的结构性信息。MBH反映的是光流图中的边缘信息的统计,CNN(convolutional neural networks)可以有效地检测图片中的边缘等信息而不失其结构信息,使用CNN 对光流图片提取特征成为了近几年的研究热点。Simonyan 等人[2]在动作识别中首次使用了双流CNN结构,其中一个CNN用来处理原始视频序列,另一个CNN用来处理连续的光流图片,最后融合两个网络的输出结果作为动作的最终分类结果。由于结合了光流特征使得识别效果大为提升。Carreira 等人[8]提出Two-Stream I3D 在动作识别取得惊人的效果,值得注意的是,他们Flow-I3D的结果已经非常接近Two-Stream I3D了,再次证明了光流在分析视频中的动作的重要作用。Ke等人[3]提出了深度时间特征来解决动作预测的问题,仅使用光流作为分析动作的特征。在其文章中,通过CNN 提取光流的特征作为深度时间特征,该工作说明了光流特征对视频中人的动作分析的准确性。
但是光流中存在冗余信息,而其他人的工作并没有考虑光流中冗余信息对动作预测的影响,因此本文从去除光流中冗余信息的问题着手,从而达到更准确的动作预测的目的。
3 总体框架
针对光流中的冗余信息,本文提出的框架如图1所示。对于输入的视频序列,首先提取视频序列的光流,然后去除光流中的冗余信息。针对去除冗余信息后的光流图,首先使用空间卷积网络提取光流图的特征,然后融合多帧光流图的空间特征作为时间卷积网络的输入,最后通过基于时间权重的多数表决法给出动作的预测结果。
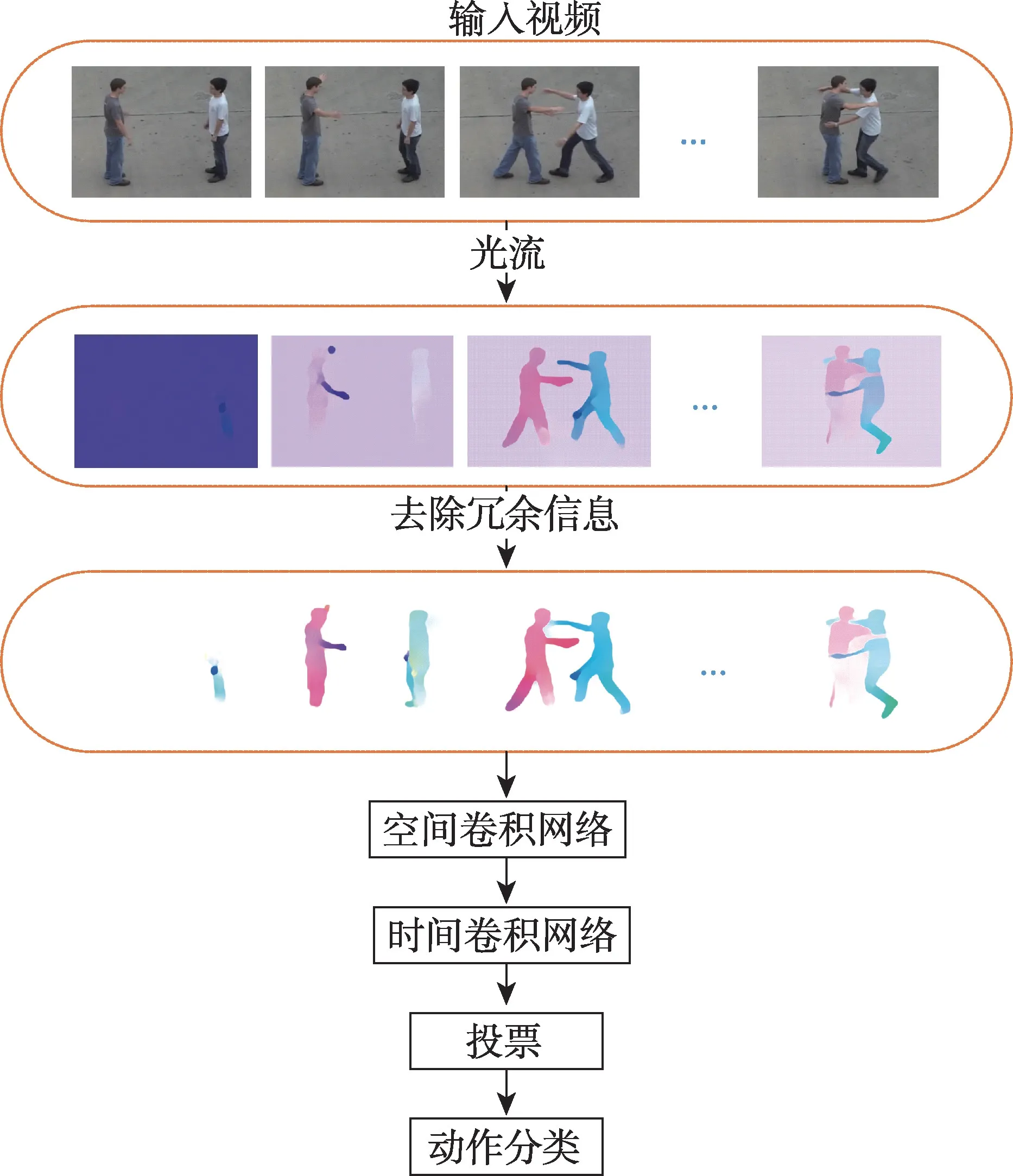
Fig.1 Framework in this paper图1 本文框架图
4 光流中冗余信息的度量
传统光流的计算是建立在两点假设上的:
(1)相邻图片对应像素点的位移很小;
(2)相邻图片对应像素点亮度保持恒定。
光流的大小可以表示为:

其中,vx、vy表示光流x、y方向的速度分量。
光流的方向可以表示为:

为了更直观地表示光流,可以用彩色光流图来表示光流,如图2(c)所示。每一个光流依据光流的方向和大小(如图2(a))分配一个对应的颜色(如图2(b))。颜色代表光流的方向,饱和度代表光流的大小。本文采用Flownet2[9]提取视频中的光流。

Fig.2 Instance of color flow image图2 彩色光流图示例
光流图可以有效反映动作信息,但是光流图中的冗余信息会对动作分类造成影响,为了评估光流图中的冗余信息,本文提出了冗余信息率(redundant information ratio,RIR)来衡量光流图中的冗余信息数据的含量。

其中,∑valid为光流图中有效信息的区域,∑all为整张图片的区域,1()为指示函数,rx,y代表坐标为x、y光流的大小,thresh为阈值,当rx,y>0时认为该点是具有信息的,在没有任何冗余信息时RIR=0,RIR越大意味着冗余信息越多。
5 光流中的冗余信息去除
5.1 静止动作部分光流冗余信息去除
视频中的人处于静止状态时,对应的光流就成为了无效信息会降低动作分类的精度,视频中静止部分的光流可以看作光流数据在时间尺度上的冗余信息。虽然在实验环境下,视频数据大多是经过处理过的,仅含有运动部分,但在实际应用场景中,人不可能永远处于运动状态,而其他文献都还没有对视频中静止部分的光流进行分析,本文对视频中静止的部分进行分析。首先检测视频中静止的部分。视频中静止部分的光流由于其含有的有效信息近乎为零,因此冗余信息率接近1。当光流图的RIR大于threshRIR时,可以认为视频为静止的。通过统计视频中静止部分光流的冗余信息率,通过大量实验,threshRIR设为0.9。
5.2 光流中的背景冗余信息去除
光流中背景带来的冗余信息主要来源于背景区域存在的运动,例如背景中树叶的晃动等引入的冗余信息,如图3(1)右上角的深蓝色区域。选取合理的运动区域可以有效去除背景带来的冗余信息。理想情况下运动区域是人体的轮廓曲线,如图3(2)中黑色曲线围成的区域,但是在实际应用中很难得到人体的轮廓曲线,因此可以用人体的外接矩形框来近似人体的轮廓曲线。本文采用Liu等人[10]的物体检测框架首先检测图像中的人位置,由x1p:x2p,y1p:y2p构成的矩形区域,如图3(3)中的红色矩形框,然后确定运动区域的范围,如图3(4)中的绿色矩形框,由xmin:xmax,ymin:ymax所构成的矩形区域。其中:

选取运动区域可以消除无关的背景因素带来的冗余信息,如图3(5)选取运动区域后RIR=0.139 3,图3(1)由于受到背景冗余信息的干扰RIR=0.267 5,说明选取运动区域可以去除背景中的冗余信息。

Fig.3 Selecting moving region图3 运动区域选取示例
5.3 相机运动评估
视频在拍摄的过程中,相机难免会产生运动,相机的运动会产生全局的背景光流,因此会带来额外的冗余信息。如图4(a)所示,相机在外界干扰的情况下产生了运动。光流图背景的蓝色区域说明相机具有水平向左的运动,当相机的运动方向与视频中人的运动方向相反时,会削弱视频中人的光流,此外还会引入额外的冗余信息。针对相机的运动带来的干扰,首先评估相机的运动vc。相机的运动可以通过计算全局背景的光流得到。首先统计背景中的光流直方图,当时,其属于直方图b个bin,其中,B=360,相机运动的方向为θc=bmax,bmax表示最大的bin,相机运动速度大小为,rx,y为背景中坐标为x,y位置光流的大小,n为背景中像素点数。因此相机的运动vc方向为θc,大小为rc。在得到vc后,修正光流,消除相机运动,对每一像素点的光流进行修正,vi,j=vi,j-vc。
算法如下:


其中,height为图像的高度,width为图像的宽度,vi,j为对应i、j位置的光流。如图4(a)为相机有一个水平向左的运动的光流图,图4(b)为消除相机运动后的光流图。
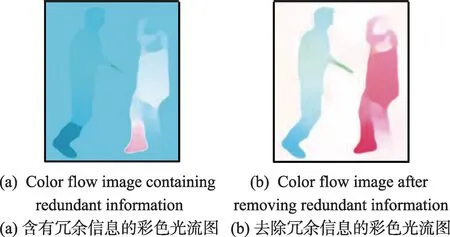
Fig.4 Result of removing camera motion图4 去除相机运动效果图
6 基于深度学习的动作预测框架
本文动作预测结构如图5 所示。卷积神经网络可以有效处理图像识别的任务,但是视频不同于图像,视频除了具有空间上的维度还具有时间上的维度信息,因此2D卷积网络无法很好地处理视频序列,3D卷积网络[11]是2D卷积网络的延伸,可以有效处理视频序列,但是3D卷积网络参数量巨大,训练时容易出现过拟合的现象。针对这样的问题,本文将3D卷积网络分解为空间上的2D卷积和时间上的1D卷积,而空间上的2D卷积操作可以有效利用现有的大型图片数据集如ImageNet 等预训练好的模型,这样将大大减少模型需要训练的参数量,降低过拟合的风险。本文方法如下,首先使用预训练的CNN模型作为空间卷积网络提取光流图的空间特征,然后堆叠K帧空间卷积网络提取的特征作为时间卷积网络的输入。时间卷积网络由两层时间卷积,一个由512个单元的全连接层和一个Softmax层构成(如表1所示)。时间卷积如图6 所示,卷积核大小为1×3,卷积核个数为6。本文使用CNN-M-2048[12]作为空间卷积网络,网络结构如表2所示。

Fig.5 Structure of action prediction network图5 动作预测网络结构

Table 1 Structure of temporal convolution network表1 时间卷积网络结构
视频最终的时空特征采用堆叠多张光流图的CNN特征,如式(8)所示。

其中,xi为预测网络的输入的时空特征,vi为第i张光流图片的空间特征,k是光流图片的张数。
在视频中,处于不同时间阶段的视频片段对动作分类的重要性显然是不同的,越接近动作完成时的视频片段往往更能描述动作。因此本文提出基于时间权重的多数表决法来对动作预测,如式(9)所示。

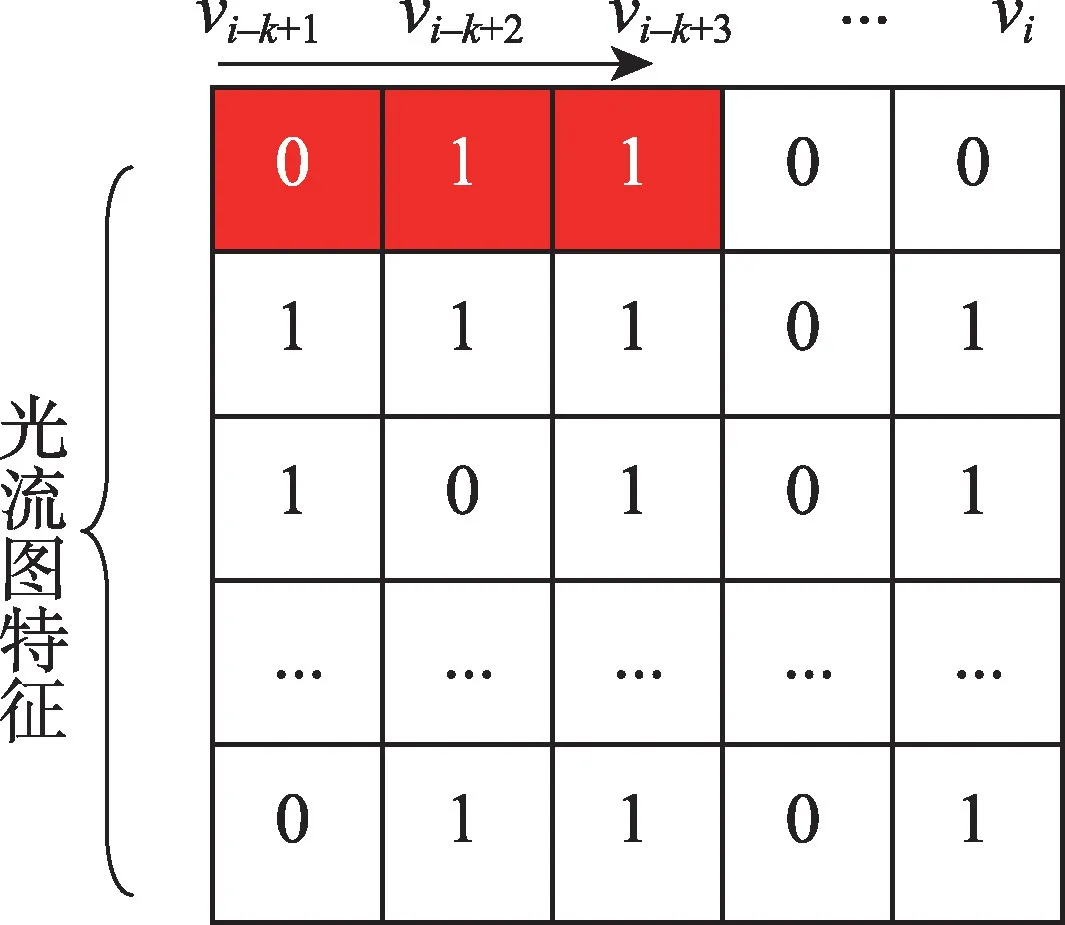
Fig.6 Graphical representation of temporal convolution图6 时间卷积图示

Table 2 Structure of spatial convolution network表2 空间卷积网络结构

其中,c(x)表示对于输入视频x最终的预测结果,ωt为权重,ct(x)表示对于输入视频x第t帧的分类结果,1()为指示函数,T表示视频总帧数,Z为规范化因子。
7 实验
7.1 数据集和实验细节
本文使用UT-Interaction[13]数据集来进行评估。UT-Interaction 被分成两个数据集set1 和set2。每个数据集包含6种动作,分别是握手、拥抱、踢、指、拳击和推。set1 是在一个停车场拍摄的,背景几乎静止,背景明亮,辨识度较高。set2 是在草坪上拍摄的,由于是在有风的天气下拍摄的,因此相机存在晃动,背景也比较阴暗,辨识度低,故set2 更具挑战性。采用一折交叉验证来评估本文的方法。本文将数据分成10 组,对于每组数据,每类动作选取1 个视频用来测试,剩下的9个视频用来训练,每组数据由54个视频作为训练数据,剩下的6个视频作为测试数据。实验时,k设为5。本文采用SSD(single shot multibox detector)[10]来检测图像中人的位置。本文采用ILSVRC-2012 预训练的CNN-M-2048 来提取光流图的特征。本文的动作预测网络采用随机梯度下降法训练,batchsize为128,动量为0.9,学习率为10-3。
测试时,每个视频由0.1 到1.0 十个观测率构成,例如观测率0.3 意味着从第1 帧到round(0.3×d)帧用来测试。其中d是测试视频的总帧数。
7.2 实验结果
7.2.1 冗余信息对预测精度对比实验
图7 为去除冗余信息与不去除冗余信息操作的实验结果对比,在观测率为0.5时,UT-Interaction set1会带来6.67%的精确度提升,在观测率为1.0 时会带来6.67%的精确度提升。去除冗余信息的效果在UTInteraction set2上尤为显著,在观测率为0.5时,如图8所示,UT-Interaction set2 会带来10%的精确度提升,在观测率为1.0时,提升的精度高达16.7%。set2精确度相对set1提升更为显著有两个原因:一是set2数据集的背景干扰因素更多;二是set2数据集相机运动更剧烈。
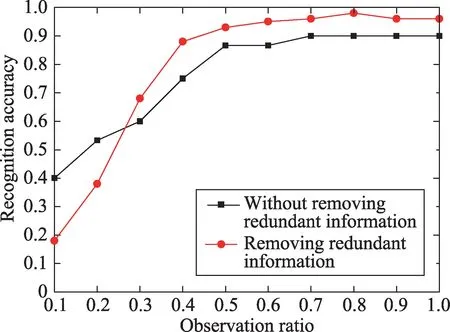
Fig.7 Comparison of experimental results of prediction accuracy with redundant information on UT-Interaction set1图7 UT-Interaction set1冗余信息对预测精度对比实验结果
7.2.2 本文框架有效性对比实验

Fig.8 Comparison of experimental results of prediction accuracy with redundant information on UT-Interaction set2图8 UT-Interaction set2冗余信息对预测精度对比实验结果
为了证明本文框架的有效性,本文实验结果与当前主流方法进行了比较,包括Integral BoW、Dynamic BoW[1]、SC(sparse coding)、MSSC(multiple segments sparse coding)[14]、TGTW(temporally-weighted generalized time warping)[15]、MMPAM(max-margin action prediction machine)[16]、Ke[3]。
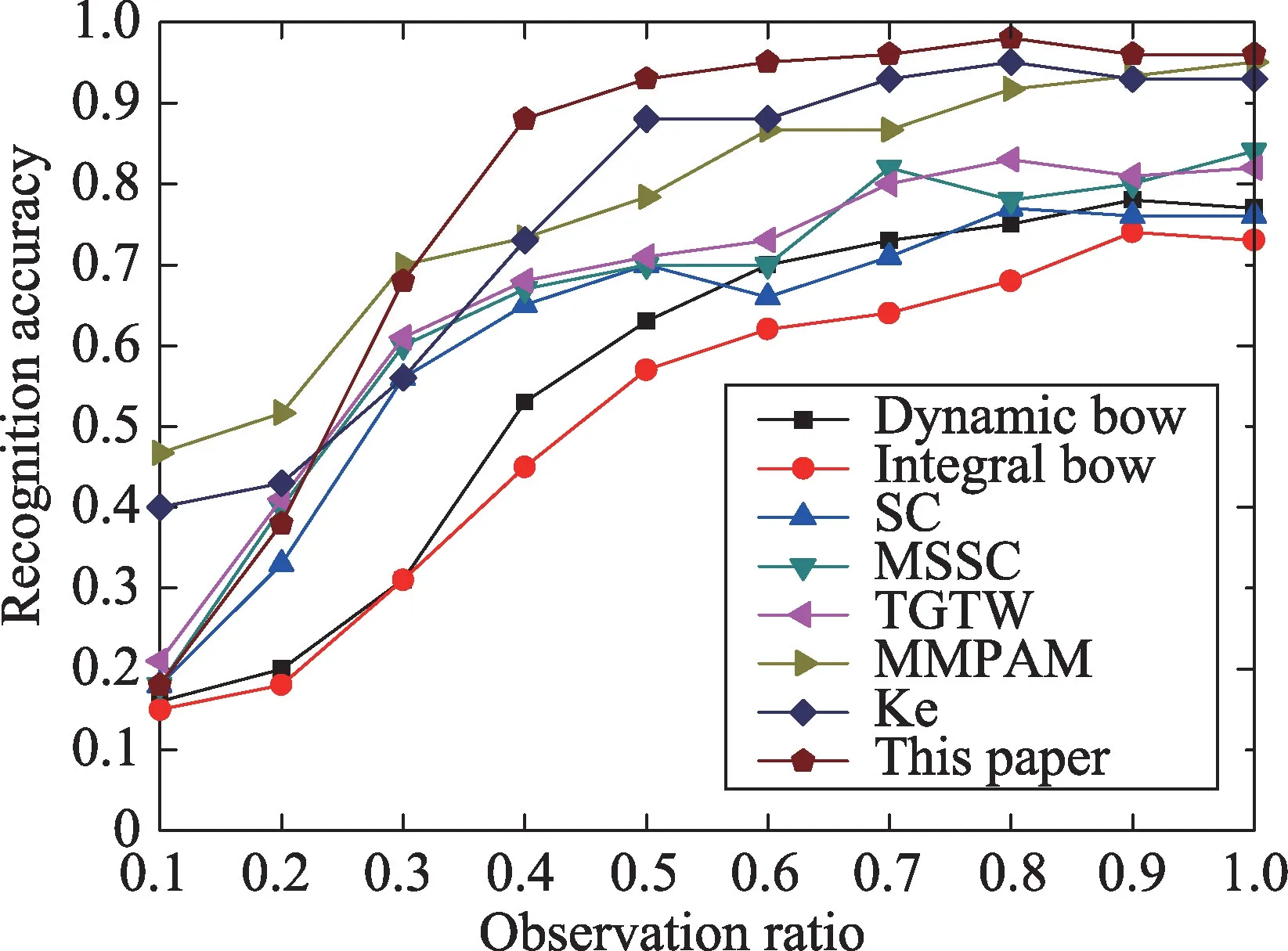
Fig.9 Experimental results of UT-Interaction set1图9 UT-Interaction set1实验结果
图9 展示了在UT-interaction set1 数据集本文方法的实验结果。在set1上,在观测率为0.5时,本文方法达到了0.933 的正确率,在观测率为1.0 时即完整的动作时,本文方法达到了0.967的正确率。对应观测率为0.5的混淆矩阵如图10所示,从混淆矩阵中可以看出踢和拳击这两个动作在早期容易被分错,可能是因为踢和拳击这两个动作需要更长的准备动作,视频的初期信息还不足以判定出这两个动作。set2的结果如图11所示,在观测率为0.5时,准确率为0.867,在观测率为1.0时,正确率为0.917。相较于set1,set2的正确率有明显的下降,其中的主要原因是set2的背景比较复杂,比较阴暗,其中set2 是在多风的环境下拍摄的,因此存在相机的抖动。set2对应观测率为0.5的混淆矩阵如图12所示,其中仍然是踢和拳击的识别率较低,原因猜测如前面所讲是踢和拳击需要更长的准备时间,早期的信息还不足以识别动作。

Fig.10 Confusion matrix of UT-Interaction set1 at observation of 0.5图10 观测率为0.5时UT-Interaction set1混淆矩阵
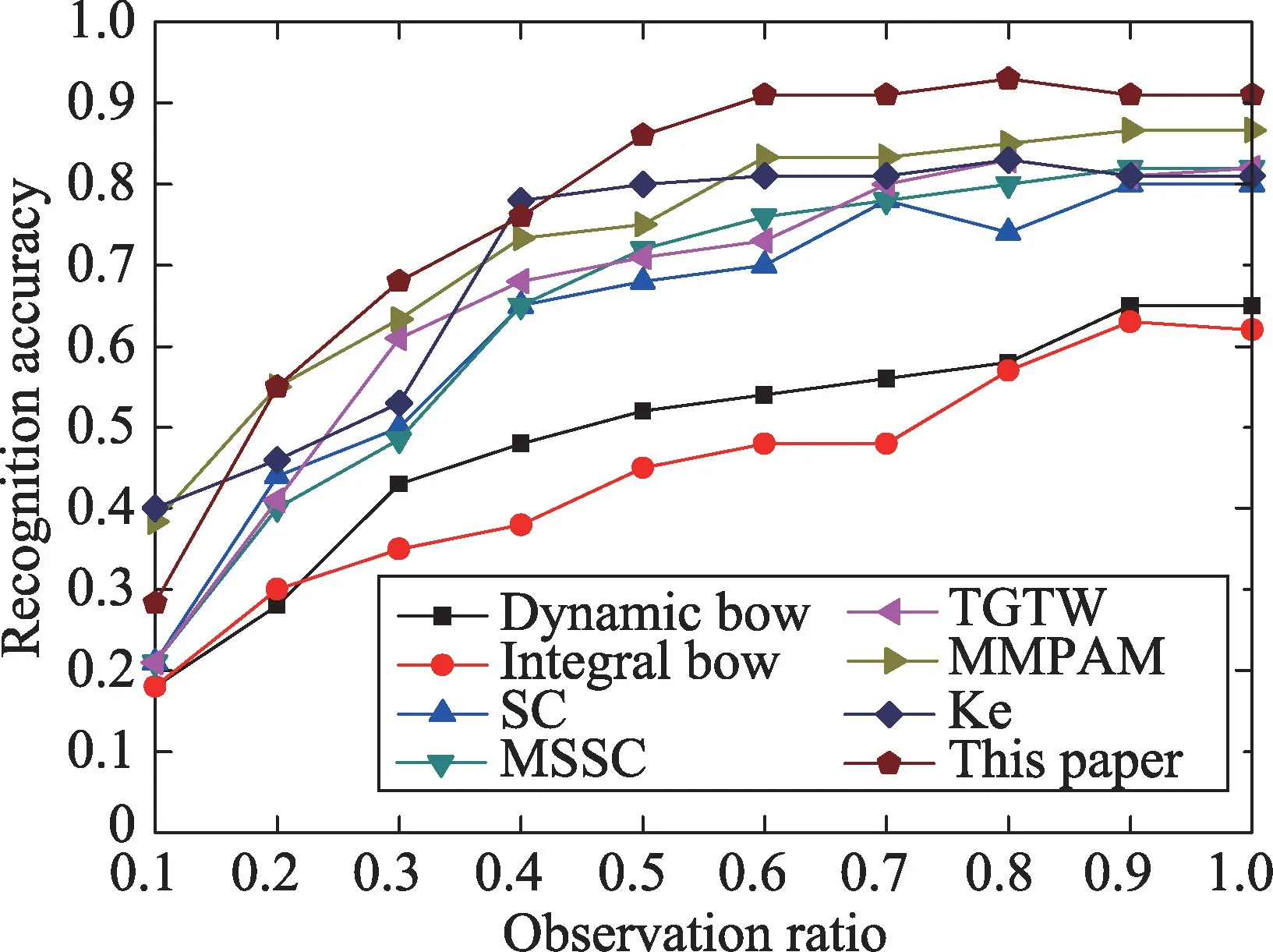
Fig.11 Experimental results of UT-Interaction set2图11 UT-Interaction set2实验结果
8 结束语

Fig.12 Confusion matrix of UT-Interaction set2 at observation of 0.5图12 观测率为0.5时UT-Interaction set2混淆矩阵
光流中的冗余信息对分析视频中人的动作有很大的影响。本文采取相应措施去除了光流中的冗余信息,针对去除冗余信息的光流图,本文提出的基于深度学习的动作预测框架具有参数量小,训练速度快,识别精度高的优点。实验结果表明了本文方法的有效性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
汽车工程师(2021年12期)2022-01-17 02:29:54
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
当代陕西(2020年14期)2021-01-08 09:30:42
电子制作(2019年11期)2019-07-04 00:34:38
电光与控制(2018年10期)2018-10-13 08:19:00
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
贵州师范学院学报(2016年4期)2016-12-01 03:54:07
中国铁道科学(2014年6期)2014-06-21 06:35:32
电视技术(2014年19期)2014-03-11 15:38:20
