
LQCD Dslash在神威·太湖之光上的研究分析与MPI实现*
2019-10-24 07:45:14陈建海何钦铭
计算机与生活 2019年10期
张 淼,周 宇,陈建海+,何钦铭,徐 顺,宫 明
1.浙江大学 计算机科学与技术学院,杭州310012
2.中国科学院 计算机网络信息中心,北京100190
3.中国科学院 高能物理研究所,北京100049
+通讯作者E-mail:chenjh919@zju.edu.cn
1 引言
格点量子色动力学(lattice quantum chromodynamics,LQCD)是粒子物理最前沿的研究课题之一。自然界存在四种基本相互作用——强相互作用、弱相互作用、电磁相互作用及引力相互作用。物理学家将强相互作用、弱相互作用及电磁相互作用统一起来称之为“标准模型”。量子色动力学(quantum chromodynamics,QCD)规范理论是标准模型中描述夸克、胶子组成的粒子强相互作用的基本理论,其重要特征是渐进自由,这使得高能强相互作用过程可利用微扰论进行处理,但此方法针对低能强相互作用过程就无能为力了。1974 年,Wilson 创建了格点规范理论[1],其将连续时空用离散晶格来替代,夸克放置于格点上,它们之间用规范场链建立联系。此理论不借助任何QCD以外的参数或假设从第一原理出发用非微扰方法来解决上述问题。
在用计算机对LQCD 理论进行数值模拟时需使用蒙特卡罗算法,而这一过程是高度计算密集型的,故现代LQCD 数值模拟过程均使用超级计算机来进行。目前,已经有很多工作在大规模超级计算机上实现了LQCD数值模拟。例如:2006年,Vranas等人[2]基于IBM 的BlueGene/L 超级计算机,在32 000 个CPU核心下,模拟QCD实现了12.2 TFLOPS的性能,并以此获得了2006年的戈登贝尔奖。2010年,Babich等人[3]在32 个由InfiniBand 互连的GPU 上,采用MPI(message passing interface)并行化QUDA 库,实现了4 TFLOPS的性能。2011年,Ammendola等人[4]用多核CPU(central process unit)、GPU(graphics process unit)及FPGA(field-programmable gate array)构建了一个由42U racks 组成的3D torus 网络原型系统——QUonG 用于LQCD 计算;同年,Babich 等人[5]通过使用多维度的并行化策略和域分解的预调节器将由post-Monte Carlo 算法实现的LQCD 扩展到256 个GPU上。2013年,Joó等人[6]将Dslash内核移植到Intel Xeon Phi 加速卡上,单节点取得了280 GFlops 的性能,整个求解器获得了大约215 GFlops 的性能,当将节点扩展到64 个Intel KNC 时,整个求解器获得了3.6 TFlops 的性能。2017 年,Bonati 等 人[7]使用OpenACC 实现了可移植的LQCD 蒙特卡罗算法代码。2018 年,Kanamori 等人[8]将Wilson 内核在Oakforest-PACS超级计算机上实现了并行化。
从“天河一号”初登TOP500榜首,到“天河二号”连续3 年登顶,世界首台10 亿亿次超级计算机“神威·太湖之光”连续4次夺冠,我国超算硬件架构已达世界先进水平,软件水平也有了一定的提升,如在神威平台上实现的千万核可扩展全球大气动力学全隐式模拟[9]和高可扩展非线性地震模拟[10]分获了2016年与2017 年的戈登贝尔奖,这是历史性的突破。但目前尚无工作针对LQCD 在这些国内超算平台上进行移植优化。2018年最新一期TOP500榜单,“神威”已被美国最新的“Summit”超级计算机超越。未来,我国不仅要重夺超算硬件架构水平的制高点,还需加快自身软件生态的建设。故为提升我国自主超算平台的软件水平,针对神威平台的特有架构,本文工作主要是将LQCD中的热点代码Dslash进行移植,通过代码向量化、循环展开、并行文件读写、主-从核DMA(direct memory access)通讯、主-主核MPI 通讯等优化手段,实现了Dslash代码在申威26010芯片上的异构众核并行,并实现了一定的优化效果,单核组从核阵列优化取得了165倍的加速比,使用MPI连并16 个核组优化取得了25 倍的加速比,同时发现使用MPI 引发了性能瓶颈,通过实验定位了瓶颈所在,为后续优化工作打下基础。
本文组织结构如下:第2章将介绍神威平台的系统架构与通信模式;第3章详细阐述了LQCD在神威平台上的优化过程;第4章对优化效果进行了数据测试并加以分析;第5章对全文内容进行了总结并对未来工作给予展望。
2 神威架构及其通信模式
2.1 系统架构
神威·太湖之光超级计算机采用的是基于申威26010 处理器的异构众核架构,其处理器架构如图1所示。每个处理器包含有4个核组(core group,CG),而每个核组又包括一个主核(management processing element,MPE)、64 个 从 核(computing processing element,CPE)组成的8×8计算处理元件阵列,以及一个协议处理单元(protocol processing unit,PPU)和一个DDR3 存储控制器(memory controller,MC)。4 个核组通过片上网络(network on chip,NOC)连接,且每个核组有自己的内存空间,主核和从核均通过存储控制器来访问。主核是具有256 位向量单元的全功能64 位精简指令集(reduced instruction set computing,RISC)核心,而从核是精简过的具有相同长度向量单元的64位RISC核心。每个从核都配置了一个64 KB大小的本地设备存储器(local device memory,LDM),其可以配置为用户可编程的高速缓冲区或用于数据自动缓存的软件模拟缓存。
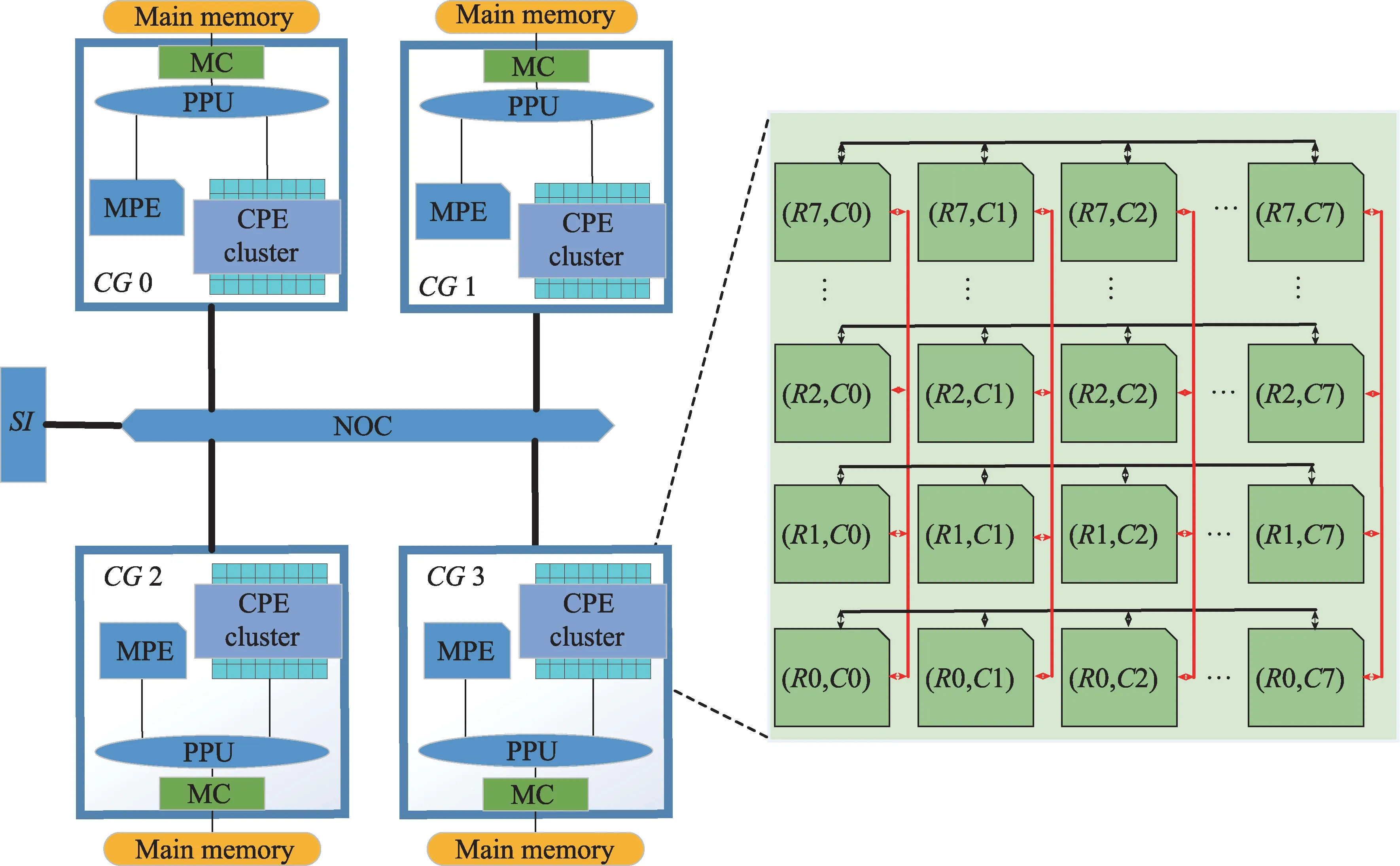
Fig.1 Architecture of SW26010图1 申威26010芯片架构
神威·太湖之光超级计算机总共有40 960 个处理器,它们之间通过中央交换机网络互连,且每256 个处理器组成一个完全连接的超节点。每个申威处理器具有260 个核心,其双精度峰值性能为3.06 TFlops,整机核心数目超过一千万个,总体性能达125 PFlops[11]。
2.2 通信模式
神威平台目前支持三种主要的编程模型,根据应用的特点,本文工作将研究重点放在了MPI+Athread混合编程模型上,其中Athread是由设备供应商提供的面向细粒度众核编程的轻量级线程库。利用Athread在从核阵列上进行众核高效率计算及从核间通讯,MPI用于不同核组的主核间数据传递。
基于此,本文工作所涉及的算法和优化策略将主要充分利用申威处理器的三种高级架构特性来获得高性能,即用户控制的LDM、直接存储器访问(DMA)和寄存器数据通信机制。每个从核上用户可控制的LDM 可视为私有的用户可编程存储空间。DMA 主要用于主存储器和LDM 之间的高效数据移动,以便用户可快速从LDM 中访问数据而不是从外面的主存储器中。低延迟的片上寄存器数据通信机制使得在同一核组中的从核之间可以进行快速有效的数据交换,而无需从核阵列和主存储器之间的额外数据移动。利用MPI的消息传递机制进行不同核组的边界数据的传输。
3 数学描述与优化方案设计及实现
3.1 数学描述
LQCD 描绘了一个四维(x,y,z,t)的格点阵列,并把每一维的首尾连接起来,如图2 所示,其为二维的示意图,类似一个“甜甜圈”。在每个格点上放置表示夸克的费米子场量,其是含有3个色分量和4个旋量分量的格拉斯曼数,这样每个格点就成为一个旋子,其在计算机中具体操作时以12 个复数构成的向量表示。在相邻旋子之间的连接上放置表示胶子的规范场量,其可以表示为色空间的3×3复数矩阵。由于是四维空间,且旋子间的连接又分为正、负两个方向,故每个格点上将会有8 个3×3 的复矩阵,以连接到8个邻居格点。

Fig.2 2-dimensional schematic diagram of LQCD图2 LQCD二维示意图
通过对每个格点附加费米子常量,每个连接附加规范场量来对格点的状态进行描述。不同的状态出现的实际概率不尽相同,此概率正比于e-βSg(U)+ψˉM(U)ψ,其中Sg(U)是全部规范场量Uμ(x)的一个泛函,M(U)是与规范场量相关的一个矩阵,其物理含义为全空间中任意两个局部夸克场之间的相互作用,这二者定义了LQCD在格点上的物理模型。
对四维空间中的所有状态进行积分,通过欧式空间的路径积分得到配分函数Z:
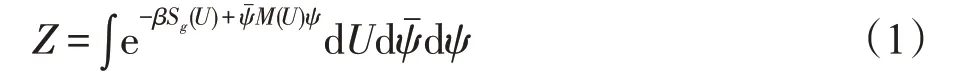
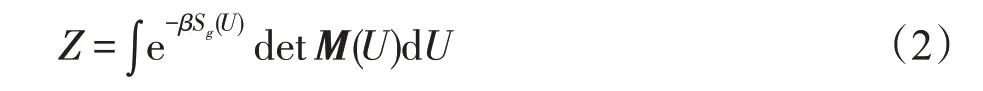
任意物理量O(U,Gq(U))的期望值可写为:
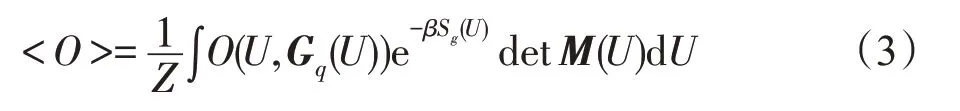
其中,Gq(U)=M-1(U)代表夸克传播子。
使用蒙特卡罗算法进行式(2)积分的计算仅需两个步骤:第一步,随机地生成规范场组态Uμ(x),并使其出现的概率为P(U)∝e-βSg(U)detM(U);第二步,计算可观测量值。其中,由于难以直接计算detM(U)与M-1(U),因此通过采用随机伪费米子场的方法来估算detM(U),从而将其转化为求解M-1(U),即稀疏矩阵的求逆操作。M-1(U)的物理含义是为了表示任意两个局部夸克场之间的传播振幅,对于求解M-1(U),每次只需计算它的若干列而非整个逆矩阵,问题便转化为求解线性方程组:

其中,b表示四维格点空间,通过x的求解,方便对M-1(U)的计算。
对于求解上述方程组,只需在{b,Mb,M2b,M3b,…}张开的Krylov子空间中迭代逼近即可达到满足要求的精度。在如共轭梯度法等Krylov 子空间算法中,关键的操作是矩阵乘以向量和向量内积的计算,其中矩阵向量乘是主要的计算热点,而向量内积涉及全局规约操作。
对于矩阵向量乘主要是计算以下的公式,即Wilson费米子矩阵:
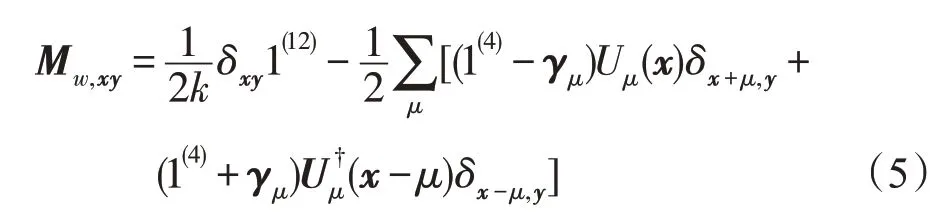
其中,μ表示4 个时空方向;x和y是两个4-矢量时空坐标;Uμ(x)表示从x点向μ方向的规范场连接,其为3×3的复矩阵,称为“组态”,U†是它的转置复共轭;γμ是4×4的稀疏复矩阵,形式为:
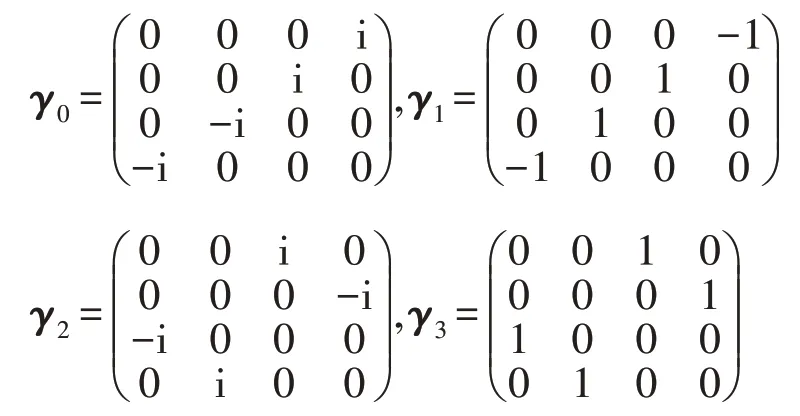
此费米子矩阵对角元部分的计算相对简单,非对角元上的计算才是关键部分,定义:
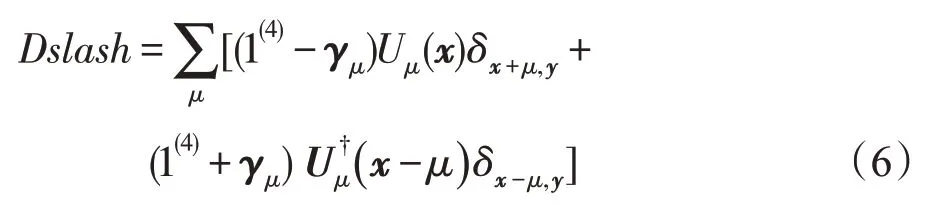
Wilson费米子矩阵每经过一次迭代计算,空间中的所有旋子就会更新自身的状态,上式定义的Dslash即为重点优化的热点部分。
3.2 代码结构
本文重点优化的包括Dslash 热点部分在内的Wilson费米子矩阵主要由3个函数所构成,它们的依赖关系如图3 所示(箭头指向的是被调用者)。这3个函数分 别 为mr_solver(…)、m_wilson(…)、dslash(…),它们的代码结构如下:

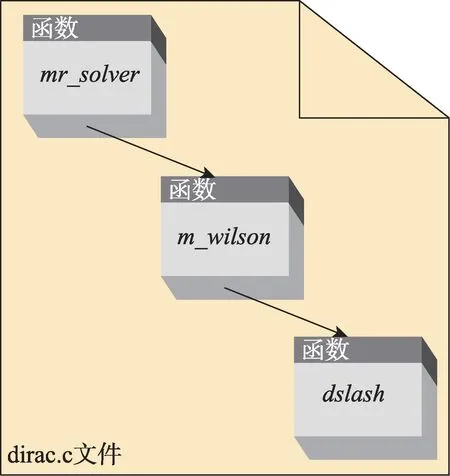
Fig.3 Dependences of 3 important functions图3 3个主要函数的依赖关系

LQCD的整个计算流程可简化为:在求解线性方程组的迭代条件下,将表示费米子场量和规范场量的复矩阵通过Wilson费米子矩阵调用Dslash运算以遍历更新所有格点的数据,然后进行规约运算,最后计算残差,输出结果解。如图4展示了上述基本流程。
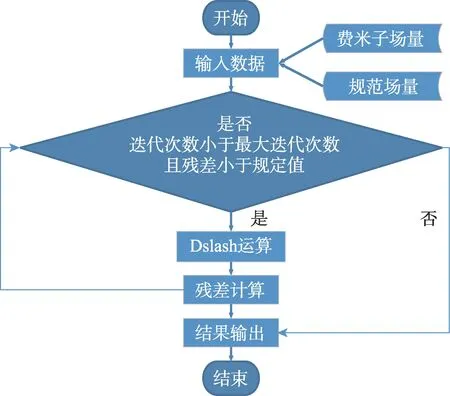
Fig.4 Flow of LQCD图4 LQCD计算流程
3.3 单核组优化方案
从式(6)可以看出,Dslash 运算可以归为一种四维的9-points stencil运算,如图5所示为二维示意,即每计算一个格点的数据均需要访问4个维度上相邻8个格点的数据及8个方向上的连接的数据。
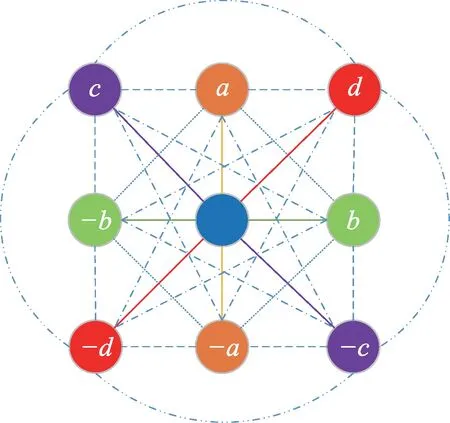
Fig.5 2-dimensional schematic diagram of 4-dimensional 9-points stencil图5 四维9-points stencil的二维示意图
关于stencil 计算,目前也已有很多的研究成果。如:Datta等人[12]针对stencil计算开发了一套行之有效的优化策略,并以此构建了一个自动调优的机制,其可通过搜索优化策略组及其参数来选出最优的策略,从而最大限度地减少运行时间,同时提高性能。此机制在Intel Clovertown、IBM QS22 PowerXCell 8等多核架构上进行了验证,并取得了很好的效果。Ho等人[13]通过利用本地存储器和异步软件预取技术来优化三维Lattice Boltzmann(LBM)stencil 模型,并在Kalray MPPA-256 多核处理器上获得了33%的性能提升。Bondhugula 等人[14]提出了一种全新的平铺技术——Diamod Tiling,其解决了现有自动平铺框架流水启动和负载不均衡的问题,使得可以并发启动且保证负载均衡,从而最大化stencil 计算的并行化。Ao 等人[15]在算法层面提出了一种计算-通信重叠技术,以减少进程间的通信开销;一种局部感知的阻塞方法,以增强数据局存性,从而充分利用片上并行性;以及一种针对不同线程中共享数据的联合访问模式。以此,他们将三维非静力大气模拟模型在神威·太湖之光上进行了实现,并获得了26 PFlops 的stencil计算性能。
根据Dslash运算的特点,目前实现的Dslash代码是根据从核LDM 的大小专门设计的,希望尽可能地把每个从核需要处理的数据存放在它上面的64 KB大小的LDM 上,从而最小化主存储DMA 开销。在此设计下,每个核组负责84大小的子格子空间,每个从核负责64 个格点,且这64 个点采用指定z和t的一个xy平面,如图6所示。
3.3.1 代码向量化及循环展开
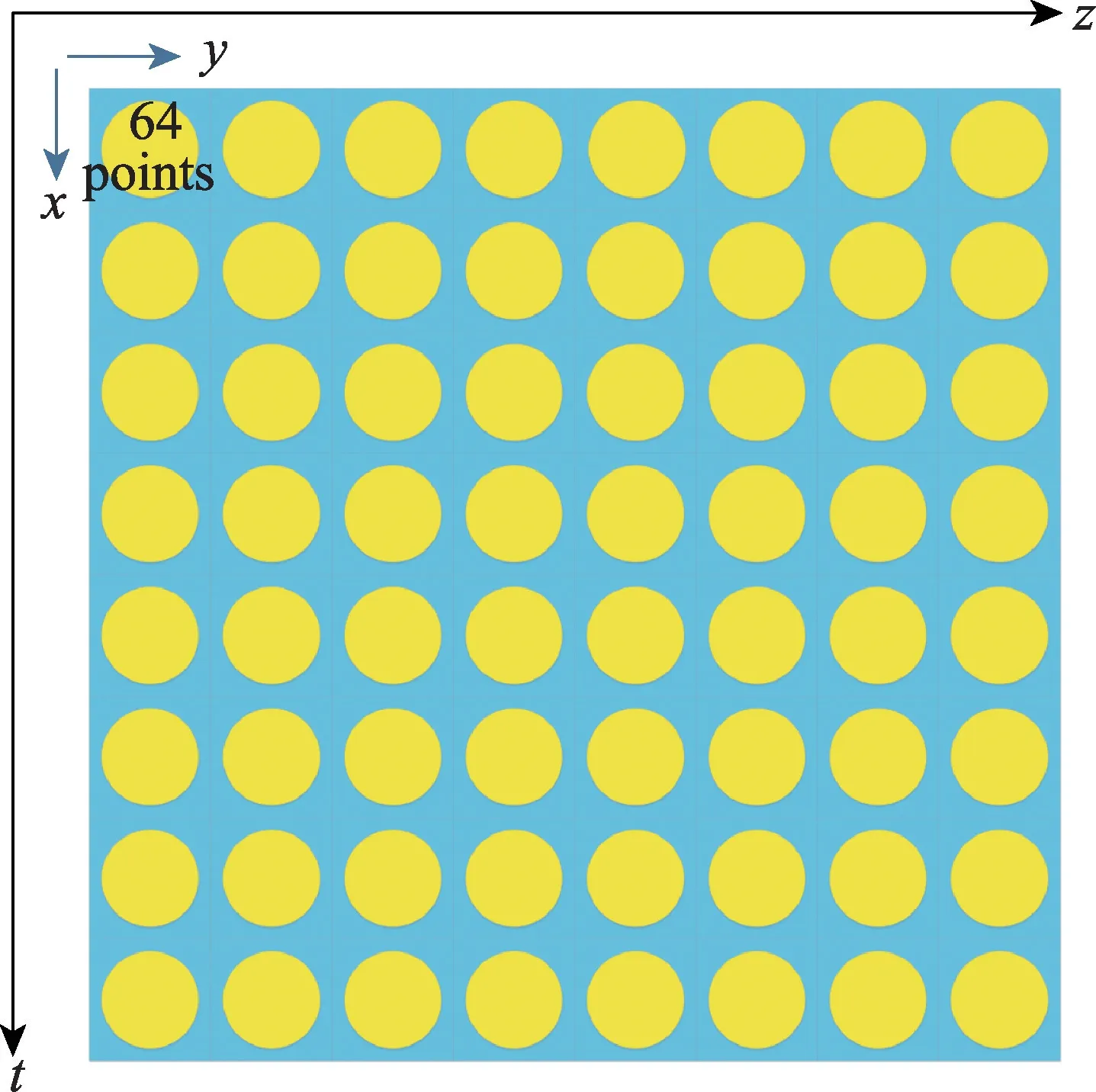
Fig.6 Schematic diagram of 4-demensional lattice data spreading on CPE cluster图6 四维格点数据在从核阵列上的分布示意图
在实际开发过程中,发现申威处理器针对简单循环以外的其他结构并没有提供自动向量化(如SLP(successive linear programming)算法)功能,因此在无法利用编译器进行向量化的情况下只能手动向量化代码。申威处理器每次能够处理4个浮点数值,且旋量的4个分量刚好可以一并处理,于是修改了数据的存储格式,将旋量指标放到最内层,这样矩阵元素在计算时被逐个处理,转置也不会带来额外的开销。Dslash中有8项不同的操作,不同的项需要考虑转置或不转置、1±γμ的符号等情况进行分别处理。另外,SU(3)矩阵有18个浮点数,而向量的存储是4个浮点数对齐的,这就意味着如果某个方向上的矩阵是对齐的,那么随后的一个就刚好不是对齐的,因此对齐与不对齐的情况也要分别处理。通过使用宏嵌套定义来分别对8个项生成对应的函数定义,从而对数据对齐或不对齐等各种不同的情况分别进行处理。
除了Dslash以外,其他涉及旋量场操作的函数也进行了向量化,主要是把循环内的操作改写成向量的形式。
指令流水线是否一直通畅并不断发射指令是影响从核计算效率的重要因素之一。循环是计算中最常见的结构,每次循环都需要进行分支判断,而条件判断会采用分支预测技术,但申威编译器的分支预测功能尚不健全,若直接采用其默认的分支预测功能就会造成流水线的不通畅,因此直接将Dslash中的64个时空点相关的循环全部展开。代码彻底展开后增加了代码的灵活性,其中有关和主存进行DMA传输的代码部分是异步的,这样就可以通过巧妙地安排代码次序来实现隐藏通讯时间。
3.3.2 从核寄存器通讯机制
从核寄存器通讯机制是申威处理器的一个非常特殊的机制。在实践过程中,感觉此机制使得从核上的程序并不像线程,而更接近于进程,这就直接改变了很多编程的基本思路。寄存器通讯只能发生在同行或同列的从核上,因此安排每个从核上的计算任务时,这种通讯关系必须满足。也就是说,对于任何一个时空点而言,相邻的8个时空点要么在同一个从核上,要么在同行或同列的其他从核上。若不满足这个条件,数据传输就需要中转,代码因此会变得很复杂,效率也会大大降低。如前所述,在目前的版本中,采用简单的分配方案,将从核的行和列映射到四维模型的z和t维度,然后给每个从核分配一个xy平面的8×8的薄片。此方案的好处是代码清晰直观,但效率不是最好的,一方面由于薄片的面积较大,另一方面是与主存通信的DMA 数量不平衡。在后续版本中,将采用参数化代码自动生成方案,为每个从核生成其特定的任务代码,使得从核间协调工作,并使用遗传算法、模拟退火算法等随机算法来优化从核的代码设计,使得从核上的任务操作顺序最优。基于薄片方案,在开发过程中了解到寄存器通信涉及到3 套队列,分别是“发送”“路上”“接收”,且它们有各自不同的大小和共用规则,非常复杂。如果接收从核的接收队列满了,路上队列也满了,那么有些数据就会停留在发送从核的发送队列中,在同步过后,不同从核的队列转移进路上队列的次序并不能保证是最初的发送次序,从而导致次序错乱。这个原理弄清楚后,让后一个发送从核与当前接收从核同步,保证发送的时候接收队列是空的,从而确保发送次序的稳定。
3.3.3 主-从核DMA异步通信
从核LDM与主存之间的数据传输采用的是异步DMA。神威架构定制的Athread 库包含了athread_get()等API(application programming interface)接口,这些接口一般都是一些宏,包装了编译器实现的“内置函数”,如dma()等。这些内置函数一般会被发射为若干行汇编代码,大致相当于嵌入汇编。这三层接口的效率由慢到快,在程序的不同部分会使用不同层级的接口,其中对计算要求较高的地方采用直接嵌入汇编代码或内置宏接口的方式调用所需功能。在DMA 操作方面,经测试Athread 的效率明显较低,因此直接采用dma_set_*()系列宏接口来实现DMA 传输。在主核和从核相互传输数据时,双方需要保证对“进度”的统一认知,这可以通过在主存上设置信号量来实现。具体编写代码时,无论是普通变量还是指针变量,都需要用volatile 关键字来修饰(其中对于指针变量的修饰,放置位置不同含义也不同),以保证缓存一致性。对于信号量的更新操作,申威处理器提供了3个指令,它们各自有相应的包装宏来调用,在实际使用时,重写了这些宏,以保证代码正确性。
3.4 基于状态机模型的多核组MPI通讯
在整个LQCD程序优化过程中,设计的整体思路是从核负责计算,主核负责通信。故在从核优化的基础上,使用MPI消息传递机制来进行核组间通信,以扩展并行规模。
核与核之间的通信主要出现在热点计算dslash函数中,每个核组负责存储84数量的格点,并负责本区域内格点的计算。边界从核在对四维空间边界上的格点进行计算时,需要从存储相邻格点的相邻核组中的从核中获取数据,同时也需要将自身的边界数据发送给对方。由于是四维空间,每个维度上都需要交换数据,且分前、后两个方向,那么就需要8次发送数据与8次接收数据,每次发送和接收的数据量为四维空间某个边界上的数据,即83数量的格点。整个计算需要多次执行dslash函数,因此相应的主核之间也需要进行多次MPI通信。
3.4.1 建立笛卡尔通信域
由于每个核组对应着四维空间的数据,那么核组之间就有了空间关系,为了更好地表示这种空间位置关系,建立了对应维度和维度长度的MPI 笛卡尔四维torus通信域,即此通信域的维度为4(x、y、z、t),且每个维度有其对应的进程数。这样在通信中就可以很方便地通过进程自身在笛卡尔通信域中的坐标(MPI_Cart_coords)找到其对应边界相邻进程的坐标(MPI_Cart_shift)。
3.4.2 非阻塞轮询监听及持久通信
在一次dslash 执行过程中,需要进行8 次数据发送和接收操作,如果使用阻塞函数(MPI_Send/MPI_Recv)来进行发送和接收,那么就需要很繁琐的设计来避免进程间的死锁。同时存放在从核阵列中的格点数据的状态在同一时刻不尽相同,因此主核并不能随时对边界数据进行发送,亦不能随时提供从核所需要的边界数据。基于此,对发送和接收采用非阻塞函数(MPI_Isend以及MPI_Irecv)[16],并考虑到需要多次进行dslash计算,对非阻塞发送和接收采用持久通信方式(MPI_Send_init 和MPI_Recv_init)以减小通信开销。但是采用非阻塞方式,就需要等待或者查看非阻塞函数是否完成,还涉及到主从核如何彼此相互通知数据已交予对方,因此采用模拟网络socket 通信中的I/O 复用机制select 方式来轮询监听发送和接收数据事件。算法如下:

将8 个方向的数据的发送和接收看成是16 个事件(8 个发送事件、8 个接收事件)并进行监听。主核层面设立8种状态来进行事件描述,分别为发送过程的4种状态NOT_READY(从核并没有准备好主核需要发送的数据)、NOT_SEND(从核数据已准备好,但主核尚未发送)、SENDING(数据发送中)、SEND_SUCCESS(数据发送成功)和接收过程的4 种状态NOT_RECV(还未接收数据)、RECVING(接收中)、RECV_READY(主核接收完成,等待从核接收)、RECV_SUCCESS(从核接收完成)。
每次轮询前对发送和接收事件的状态进行初始化。轮询时,对每个事件查看其状态,并执行相应的操作。若某个事件状态对应的动作未执行完,那么就立即查看下一个事件的状态;若某个事件的状态对应的函数或者变量发生变化,那么就改变此事件的状态并查看下一个事件的状态。发送和接收事件的状态都显示为成功时即标识着一次轮询的结束。
另外主从核之间需要特定标志来判断从核已准备好主核需要发送的数据,主核已接收到从核所需的数据。在设计方案中为这些事件各设立了一个变量,用以表示主核需发送的数据有多少从核已经放置到主核上,以及主核已经接收到数据并通知从核进行获取。
主核间除上述的通过MPI 通讯来传输格点数据,还需在求解残差过程中对每个核组中的残差数据进行全局规约。
3.5 并行文件读写
MPI-2 中提供了一套并行I/O 接口,实现了进程间并行读写文件的方法。LQCD 中每个进程对应的数据在数据文件中并不是连续存放的。进程数据分布方式为循环块分布,通过建立新的数据类型构造符(MPI_Type_create_darray)来定义分布式数组类型。打开文件之后(MPI_File_open),设置进程的文件视图(MPI_File_set_view),使得每个进程通过各自的文件视图访问数据时,文件中只包含视图对应的数据,且数据之间是没有空隙的。
4 性能测试与分析
为测试上述两部分的并行优化效果,现分别设置几组实验进行验证。首先,测试从核优化版本的效果;其次,测试MPI版本的扩展性效果。测试标准为热点计算部分(即涉及Dslash 运算的上述3 个函数)迭代150次的运行时间。
4.1 单主核版本与单核组从核优化版本
基于84 大小的格点数量,首先将程序在单个主核上编译成功并运行,这相当于纯CPU 版本;然后,将使用从核优化策略改进过的异构并行版本在单个核组,即64 个从核上运行。它们的运行时间如表1所示。
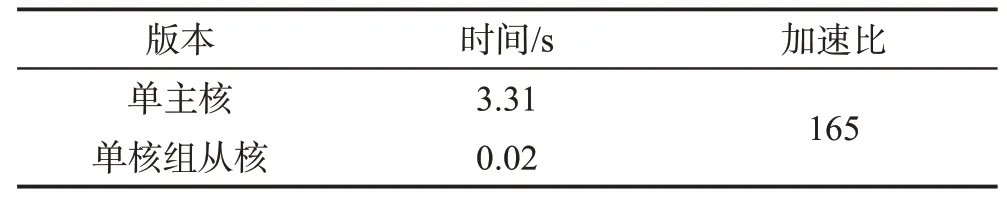
Table 1 Time comparison of single MPE version and single CG version表1 单主核版本与单核组从核版本运行时间对比
从以上实验数据可以看出,目前的从核优化策略取得了不错的效果,从核优化版本相较单主核版本的加速比达到了165倍。
4.2 单主核版本与从核优化MPE版本
在从核优化取得不错加速效果的基础上,为测试使用MPI 扩展核组规模的性能情况,将程序规模扩展到16 个核组上,每个核组负责的格点数据量仍为84,则总数据量为16×84。与之对应的单主核版本的数据量也扩大到16×84。它们的运行时间如表2所示。

Table 2 Time comparison of single MPE version and MPI version表2 单主核版本与MPI版本运行时间对比
从以上实验数据可以看出,MPI版本相较单主核版本依然有不错的运行速度提升,但相比上一节得出的加速比却有了较大的下降。由于单主核版本的数据量增大了16 倍,理论上运行时间也应增大16倍,实际的数据也符合这一情况(57.73/3.31=17.44,接近16)。但MPI版本相较单核组从核版本而言,整体数据量虽增大了16 倍,但每个核组负责的数据量没有变,且处理器的数量也相应扩大了16倍,那么理想情况下这两个版本的运行时间应相差不大,然而实际的数据却相差较大,MPI 版本慢了99.1%。这说明,MPI 版本在实际运行过程中出现了性能瓶颈,具体原因需要进一步探究。
进一步地,测试了随着核组规模的扩大,运行时间的变化趋势,如表3和图7所示。

Table 3 Running time of MPI version of different CG numbers表3 不同核组数MPI版本的运行时间
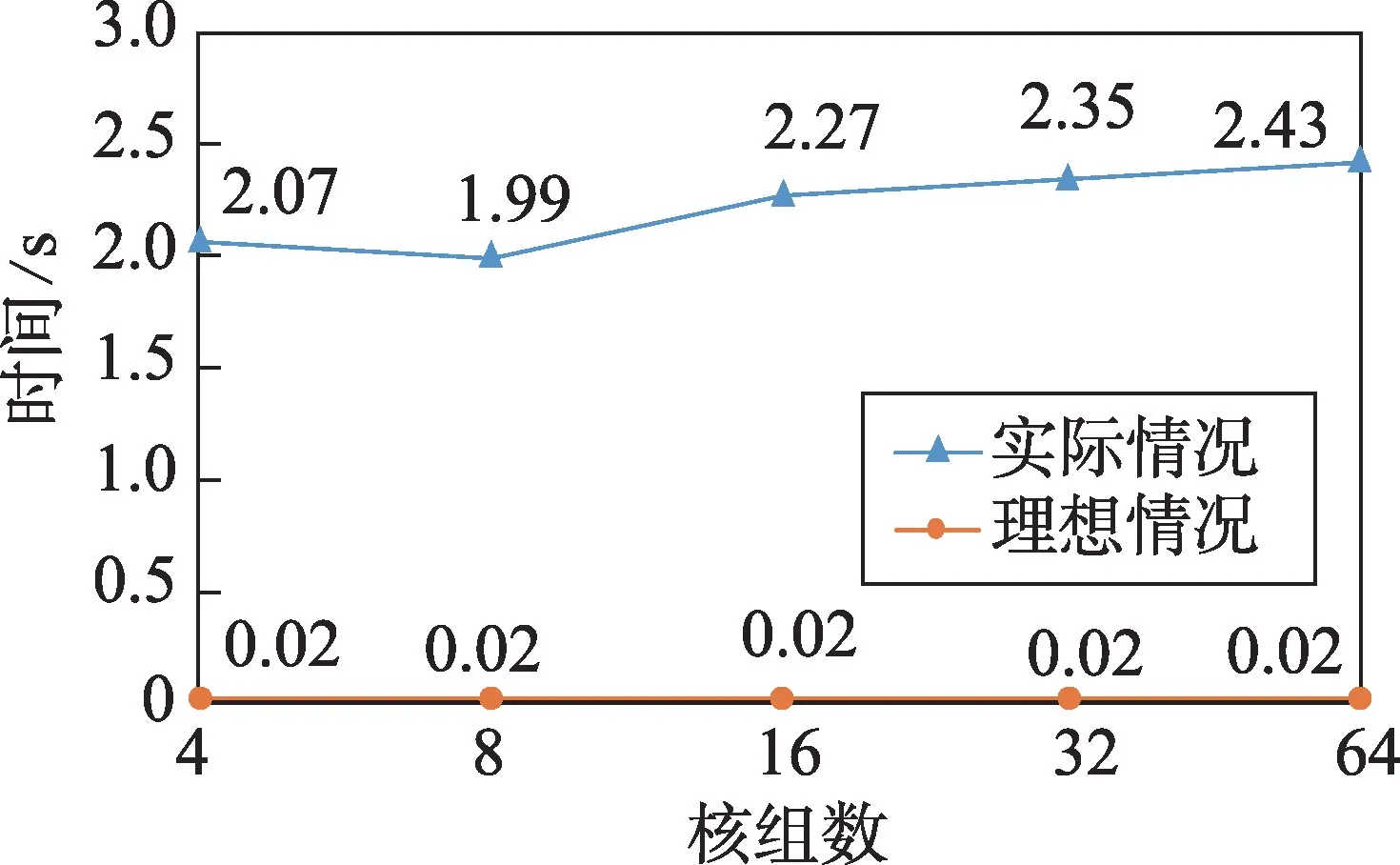
Fig.7 Trend of CGs scale and running time图7 核组规模与运行时间的变化趋势
从图7 可分析得出,使用MPI 扩展核组规模后,程序运行时间与单核组版本相比都有较大的差距,且随着核组规模的扩展,运行时间有增大的趋势。这进一步说明了使用MPI 诱发了性能瓶颈,且随着核组规模的扩大,程序的整体性能有下降的趋势。具体原因将在下一节中详细讨论。
4.3 从核代码拍数与MPI代码拍数对比
为了详细说明使用MPI 在主核间传输数据引发性能下降的原因,需要更准确地分析各部分程序运行的时间。使用神威平台提供的程序运行拍数计数接口rpcc进行测量,将拍数乘以处理器的主频即可准确得到该段程序运行的墙钟时间(wall clock time)。
利用神威平台提供的计数器接口,分别在从核关键代码和MPI代码中进行插桩,分别得到这些代码部分的拍数统计,测试数据如表4和表5所示。

Table 4 rpcc results of CPE codes表4 从核代码拍数测试结果
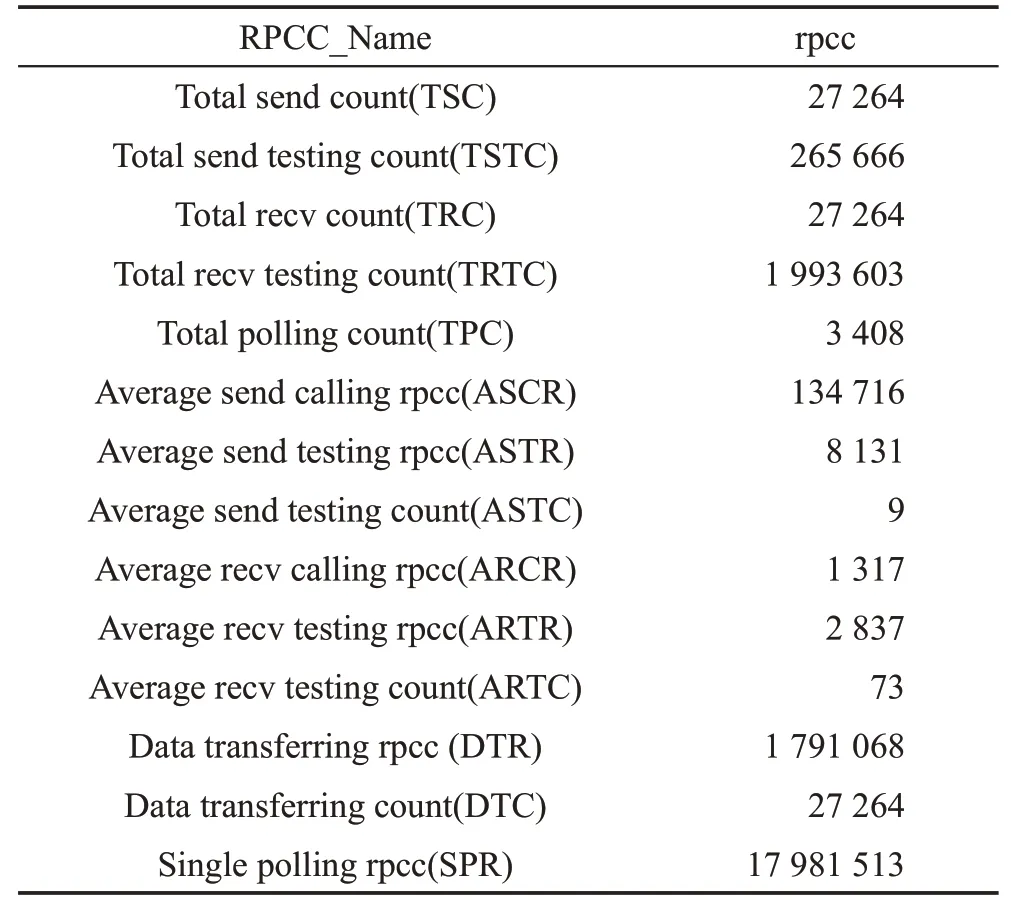
Table 5 rpcc results of MPI codes表5 MPI代码拍数测试结果
表4中,m_wilson_dslash 表示从核Dslash热点部分计算过程的拍数;slave_doit 表示整个从核代码运算过程的拍数。
表5中,在3 408次轮询下,共进行了27 264次的MPI 发送(send)和接收(recv)测试,它们之间的关系为TPC=TSC(orTRC)/8。在此基础上,测得单次轮询过程需17 981 513拍数,其中一次调用MPI发送指令需134 716 拍数,测试数据发送完成的过程需8 131拍数,且需大约9 次测试完成此过程;接收过程同理。从核发送到主核上的数据进行转化需1 791 068拍数。它们之间的关系为:
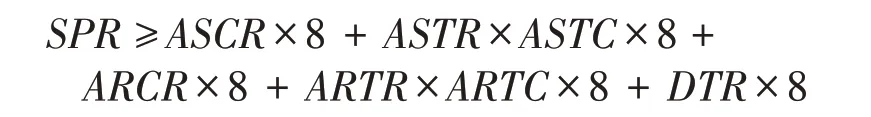
从以上两个表格数据中可以看出,MPI代码运行的平均拍数比从核代码运行的平均拍数大了3 个数量级,这就充分说明了MPI 代码占用了大量的运行时间,且从核代码的运算不能将其隐藏,这是目前LQCD 神威版本最大的性能瓶颈。再具体地分析,MPI 运行拍数中的Data transfering 部分又占据了大量的运行时间,其占比达到了895 534×16/17 981 513×100%=79.7%,这部分的功能主要是为了主核间传输数据,将从核上准备好的数据通过DMA传输给对应的主核,然后主核根据接收的次序对数据进行重排。
经过实验数据测试与分析,单核组从核优化取得了很好的效果,使用MPI 进行规模扩展后亦取得了一定的效果,但同时也造成了性能下降,通过利用拍数测量工具对代码的精确分析,将性能瓶颈定位到了主核对从核数据进行重排转化的过程,这促使下一步的工作需要改进这部分的算法设计。另一方面,减去这部分的性能障碍,MPI 传输过程的拍数也要比从核代码的拍数高出两个数量级,因此优化MPI传输也是下一步工作的重点。
5 总结与展望
LQCD 是当今高能物理领域最前沿的研究方向之一,在大规模超级计算机上实现其数值模拟,对于一个国家占领科技制高点具有重要意义。在本文中,总结了目前在神威·太湖之光超级计算机上对LQCD 中的Dslash 热点部分所做的移植和并行优化工作。主要贡献包含如下几点:通过分析LQCD的应用特点及数值特征,首次将其在神威平台上实现了成功移植及运行;通过使用向量化、指令流水线、寄存器通讯机制等手段在申威26010 处理器上实现了异构众核并行,并实现了不错的加速比;在实现从核阵列并行化的基础上,进一步使用MPI 实现了多核组连并运行,以此实现一定的并行规模,并着重分析了在目前版本中其成为性能瓶颈的原因。将LQCD在全自主国产超算平台上实现并行化进行了有力尝试。测试数据表明,神威平台对实现大规模的LQCD并行化具有巨大的潜力,对我国未来在高能物理强相互作用领域的数值模拟能力建设与提升具有重大意义。
接下来将会在以下几方面继续进行研究和开发:
(1)在神威平台上对LQCD 进行全面的众核优化。目前版本所使用的格点数量尚且较小,后面将优化所采用的stencil 模型,增大数据量,进一步发掘LDM 与寄存器通讯机制的功能,以更加充分地利用从核阵列的并行计算能力,提高运行效率。
(2)通过进一步的分析,极大地消除MPI 通讯瓶颈阻碍,或将使用MPI-2 等其他版本进行开发,以期进一步扩大并行规模,充分挖掘神威平台的整体计算能力。
(3)在并行规模和效率达到满意的程度后,将程序与Chroma框架进行整合,便于科研人员使用,为高能物理领域做出些许贡献。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:58:02
空间科学学报(2021年4期)2021-08-30 08:31:16
今日农业(2020年18期)2020-10-27 01:30:08
数学物理学报(2018年5期)2018-11-16 05:49:54
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
高中生·天天向上(2017年2期)2017-06-09 06:38:14
新高考·高二数学(2016年3期)2016-05-20 23:47:43
