
基于R语言爬虫技术的网页信息抓取方法研究
2019-10-21 10:12庄旭东王志坚
科技风 2019年6期
庄旭东 王志坚
摘 要:随着互联网的快速发展,大数据时代的来临,网络上的数据和信息呈爆炸性增长,网络爬虫技术越来越受欢迎。本文通过以抓取二手房出售数据为例,探索R语言爬虫技术的网页信息抓取方法,发现基于R语言的rvest函数包与SelectorGadget工具实现的网页信息爬取方法比传统方法更加简单快捷。
关键词:R语言;网络爬虫;网页信息抓取;二手房
传统的网络搜索引擎在网络信息资源的搜索中起着非常重要的作用,但它们仍然有很多限制。现如今,在网页信息抓取上R语言有其独特的优势,用它所编写的爬虫语法相对直观简洁,规则更加灵活简单,对操作者要求也相对较低,不必深入研究某一软件或编程语法,也不必具备很多网页方面的相关知识,非专业的人甚至是初学者,也可轻松掌握其方法,快捷方便获得所需的网页信息。除此之外,R软件可以非常自如的处理百万数量级以下的数据,而且其本身就是一个用于统计计算和统计制图的功能强大的工具,运用R软件进行操作,所实现的爬虫技术的网页信息抓取撷获得到的数据,可以直接进行统计分析和数据挖掘,省去了数据的再导入或整合的步骤,更加直接方便。
1 研究方法概述
本文运用R软件中的rvest函数包,来实现抓取网页信息数据。运用该包中read_html()、html_nodes()和html_text()三个函数与SelectorGadget工具(以下简写为工具)相配合。使用read_html()函数抓取整个网页的原始HTML程式码,再使用html_nodes()函数从整个网页的元素中选出由工具获取的路径的信息,最后使用html_text()函数将HTML程式码中的文字资料提取出来得到我们所需要的数据。并且根据网页的规则,利用for()这一循环函数实现多网页的信息抓取工作。接着与不同的抓取网页信息的方法进行比较得出R语言做爬虫的优势,并对R语言爬虫技术的网页信息抓取方法进行比较展望,也对大数据时代的数据获取方式与技巧作进一步探索。
2 网络爬虫的相关概念与步骤
2.1 网络爬虫概念
网络爬虫,是一个用于自动提取网页信息的程序,可以自动从万维网上下载网页,并将收集到的信息存储到本地数据库中。根据网络爬虫系统的结构和实现技术,大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。这些爬虫技术的出现是为了提高爬行的效率,我们需要在更短的时间内尽可能多地获取有用的页面信息。
2.2 网络爬虫步骤
实现网络爬虫的基本步骤有:①首先选取一部分精心挑选的种子URL;②将这些种子放入待抓取URL队列;③从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中,此外,将这些URL放进已抓取URL队列;④分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
3 基于R语言rvest包实现网页信息抓取
本文使用SelectorGadget路径选择工具,直接定位我们所需要的数据,再结合R语言rvest包,以2018年4月链家网广州二手房出售数据为例,将我们需要的数据从网页中抓取出来。
3.1 网页信息抓取准备
3.1.1 SelectorGadget工具
信息的抓取需先定位数据,选取网页节点,然后获取的二手房相关信息的网页路径信息,具体的步骤如下:
①准备好SelectorGadget工具:打开广州链家网页面,并打开该工具列,其开启之后,会显示在页面的右下角。
②产生CSS选择器并显示该选择器所能撷取的HTML元素:使用鼠标在网页上点选要获取的资料,被点选的HTML元素就会以绿色标示,而这时该工具会尝试侦测使用者想要抓取的资料的规则,进而产生一组CSS选择器,并显示在该工具列上,同时页面上所有符合这组CSS选择器的HTML元素都会用黄色标注出来,即目前这组CSS选择器将会撷取所有绿色与黄色的HTML元素。
③去除不需要的HTML元素:该工具所侦测的CSS选择器一般会包含一些所不需要的资料,这时可以将那些被标示但要排除在外的HTML元素点除,点除的元素会标示成红色。
④获取精准的CSS选择器:在选择与排除HTML元素后,所有想要撷取的元素已经全部精准标示出来,可以生成一组精确的CSS选择器,显示在该工具列上,可以利用其在R软件中进行处理。
3.1.2 R軟件相关函数包与使用
实现网页信息的爬取,R语言的编写需要引用到xml2、rvest、dplyr、stringr等的函数包里的函数,故而下载这几个函数包,并且加载所需的包。具体做法的是使用install.packages()与library()函数进行实现,也可以将这些包下载到本地安装。
3.2 网页信息抓取实现
下面以链家网广州二手房出售为例,根据前面的步骤,首先使用read_html()函数抓取整个链家网页的原始HTML程式码,再使用html_nodes()函数从整个链家网页的元素中选出由SelectorGadget工具获取的路径的信息,最后使用html_text()函数将HTML程式码中的文字资料提取出来得到我们所需要的链家网数据。
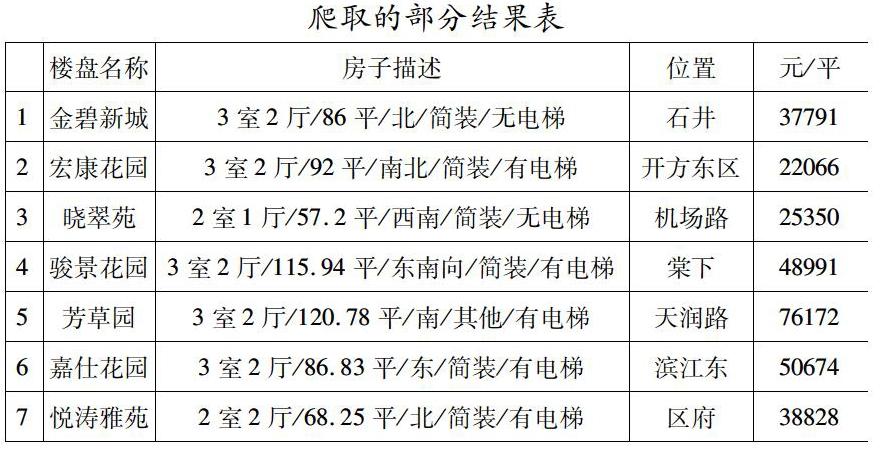
rvest包的几个函数针对了某个网页进行数据的爬取,但可以发现,广州链家网的二手房数据有很多页,并且有用的信息包括房名、描述、位置、房价等,因此,选用循环函数for(),编写出如下的函数,将链家网上所有有分析价值的信息都爬取出来,并写成csv格式的文件,便于进一步分析,由于篇幅有限,在此就列出部分结果,如下表所示。
上表给出了广州部分二手房的基本信息。
可见,运用rvest包结合CSS选择器能够快速实现R语言下的网络数据抓取,并适当结合stringr包中的字符串处理函数对网页数据进行清洗和整理,能十分方便有效地获得网页数据并且可以直接进行数据处理和分析。通过直接利用所爬取的数据,对房价是否符合正态分布进行简单地分析,展示R语言实现网页数据爬取之后对获得的数据进行分析的便利性和优越性。
4 rvest包与其他网页信息抓取方法比较分析
R语言实现网络爬虫有两种方法,一种是利用本文所提到的rvest包,另外一种是利用RCurl包和XML包。
由rvest函数包配合SelectorGadget工具实现R语言在网页信息爬取上的应用这个方法,与采用XML包和RCurl包进行爬取相比,更加简单,代码更加简洁直观。R中的rvest包将原本复杂的网页爬虫工作压缩到读取网页,检索网页和提取文本,使其变得非常简单,而且根据网页的规律,运用for()循环函数进行实现多张网页的信息爬取。而使用XML包和RCurl包进行实现,则需要一些关于网页的基础知识,模拟浏览器行为伪装报头,接着访问页面解析网页,然后定位节点获取信息,最后再将信息整合起来。该方法更为困难繁琐,在访问网页时有时并不能顺利读取解析,并且在选取节点的时候需要HTML的基础知识,在网页源代码中找寻,有些网页的源代码相当复杂,并不易于定位节点。
两种实现的方法所能达到的效果基本大同小异,而且利用for()循环函数可以实现多网页数据的爬取,从上手角度上讲,rvest包显示是更胜一筹,是XML包和RCurl包的进化,更加简洁方便。
而除此之外,用Python實现网络爬虫也是很受欢迎。Python的pandas模块工具借鉴了R的dataframes,而R中的rvest包则参考了Python的BeautifulSoup,两种语言在一定程度上存在互补性。Python在实现网络爬虫上更有优势,但就网页数据爬取方面而言,基于R语言工具进行实现,更加简洁方便,而且R在统计分析上是一种更高效的独立数据分析工具,运用R语言获取的数据避免了平台环境转换的繁琐,从数据获取、数据清洗到数据分析,代码环境、平台保持了一致性。
参考文献:
[1]吴睿,张俊丽.基于R语言的网络爬虫技术研究[J].科技资讯,2016,14(34):35-36.
[2]西蒙·蒙策尔特.基于R语言的自动数据收集:网络抓取和文本挖掘实用指南[M].机械工业出版社,2016.
[3]刘金红,陆余良.主题网络爬虫研究综述[J].计算机应用研究,2007,24(10):26-29.
猜你喜欢
三联生活周刊(2017年30期)2017-07-27
中国新通信(2016年21期)2017-01-06
中国新通信(2016年21期)2017-01-06
科学与财富(2016年29期)2016-12-27
投资北京(2016年10期)2016-11-23
电脑知识与技术(2016年20期)2016-08-19
财经(2016年19期)2016-08-11
电脑知识与技术(2016年17期)2016-07-23
商(2016年24期)2016-07-20
中国市场(2016年23期)2016-07-05
