
基于元算法Django架构下社团推荐系统的设计
2019-10-21 09:21赵琳徐明昊
微型电脑应用 2019年6期
关键词:聚类
赵琳 徐明昊


摘 要: 高校社团管理系统所采用的B/S方式鲜有智能推荐功能,推广效率低,资源浪费明显,依赖熟人系统。为了克服这些问题,应用聚类和KNN算法集成为元算法,并设计和实现了基于Django框架的智能社团推荐系统。
关键词: Django; 聚类; KNN算法; 社团推荐
中图分类号: TP277
文献标志码: A
文章编号:1007-757X(2019)06-0122-04
Abstract: There are few intelligent recommendation functions in the B/S mode used in college community management systems. The way isolated introduced by the president campus publicity results in inefficiency and obvious waste of resources. For this reason, this paper chooses clustering KNN algorithm, and designs and implements an intelligent community recommendation system based on Django framework.
Key words: Django; Python language; Clustering; KNN algorithm; Community recommendation
0 引言
社团在大学生第二课堂成长中起着重要作用。目前,高校社团系统管理模式多采用B/S方式。王翠香、邵星等人[1]设计了一种基于Android 手机OS平台的社团管理系统.钮永莉、戴子东等人[2]使用JSP技术设计了一种MVC框架的社团管理系统。张明东、戴丹丹等人[3]提出了一种基于Java EE的社团管理方案。王金龙、孙月兴等人[4]实现了一种基于Python的社团管理系统。这些系统通过主流技术满足了社团管理增、删、改、查等基本要求,对于大学生个性化智能推荐的需求没有涉及。
李嘉琪、李俊、李婷、付麟惠等人[5]通过为每个社团添加类型标签匹配学生用户爱好的方法实现社团推荐。该方法策略单一不能满足多需求精准推荐。石铠、任泺锟、彭一鸣、李慧嘉等人[6]通过图理论构建最优的重叠社团结构的方法聚类领袖社团实现推荐,但计算复杂度受限于特定带宽,影响了应用范围。王玙、刘东苏等人[7]提出了联合聚类协同过滤算法,通过提取相似用户偏好的方法建立属性相似性与打分相似性相结合的推荐算法,此方法用户与社团属性的耦合还不高,依赖于熟人环境,对于新生群体的陌生群体应用效果有限。
综上所述,本文针对现有社团管理系统智能推荐功能薄弱,着眼强化用户与社团属性耦合,提出了一种将聚类、kNN算法集成为元算法的Django架构下的智能社团推荐系统,针对大学生群体,提高推荐效率。
1 相关技术
1.1 系统架构
Django是Python web中最流行和应用最多的轻量级开发框架之一[9]。他是一种基于MTV模式的架构,核心包括:数据模型(ORM)映射器,请求路由(url分发器),视图(请求响应处理模块)和前端模板(用户交互)。预设的用户系统、账号管理、安全防范等系统功能为web开发带来很大方便,大量减少了代码编写量,提高了各类应用系统的开发效率,其架构如图1所示。
1.2 其他技术
Bootstrap是一款基于HTML、CSS、JavaScript的前端開发框架,拥有大量完备的Web组件。Jquery封装了JavaScript常用的功能代码。SQLite是一款轻量级嵌入型关系数据库。Redis数据库是一款高性能键-值数据库。
2 需求设计[8]
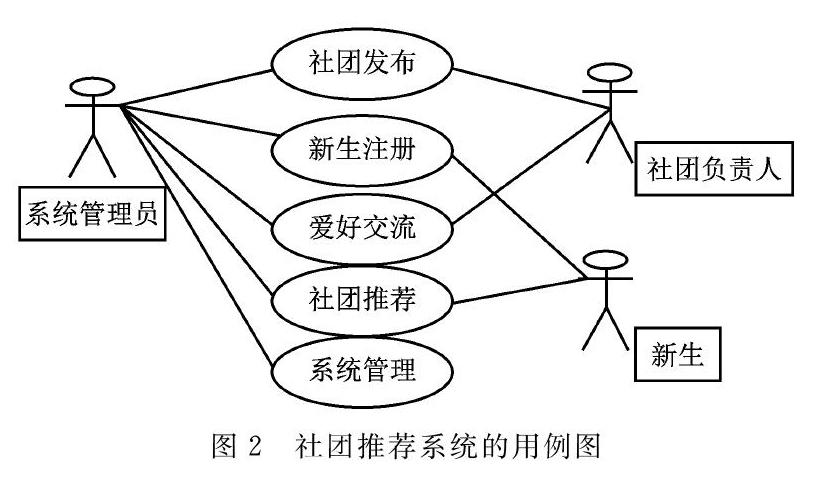
从本应用的具体需求看,智能社团推荐系统需要社团发布、新生注册、爱好交流、匹配社团推荐、系统管理等5个功能需求。核心功能为根据新生的信息进行个性社团推荐。如图2所示。
3 元算法
3.1 算法思想
聚类算法是一种无监督的学习,适合在未知分类的情况下进行全自动分类。该算法试图将相似对象归入同一簇。
本文采用k-均值聚类算法。其具体思想是:随机确定未知样本集合中k个初始点作为质心。为每个点找距离其最近的质心,并将每个点分配至所对应的簇中。然后更新该簇所有点的平均值。
K邻近算法是指存在一个样本数据集合,且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般只选择样本数据集中前k个最相似的数据。出现次数最多的分类,作为新数据的分类。其缺点在于计算未知分类样本时要和已知集合中每个样本进行距离计算,对于大样本空间时间复杂度高。
本文将以上两种算法集成为元算法,首先在大学新生数据集上应用k-均值聚类算法进行预分类。再在每个子类中的新生与社团样本集中与该类新生类别相似的社团上应用KNN算法,降低KNN算法应用时的样本数量,达到提高算法效率,在不依赖熟人的情况下进行有效推荐。
3.2 关键问题
(1) 新生数据抽象。新生关键属性由用户ID,兴趣爱好,投入时间组成。数据模型伪代码如下:
模型中User对象为Django内置对象。
(2) 社团数据抽象,社团属性主要由以下字段组成如表1所示。
(3) K-均值聚类算法[10]
本应用中,每个类的聚类中心取该类样本的平均值。用欧式距离式如式(1)进行聚类中心与样本相似性计算,以各聚类平方和最小为聚类目标,如式(2)。
S1:随机选取k个新生样本作为聚类中心
S2:按照公式(1)计算所有新生样本的欧式距离
S3:将每个新生分配至与其距离最近的聚类中
S4:用聚类中所有新生样本的均值更新聚类中心,按照公式(2)计算目标函数值;
S5:根据目标函数值判断结束事件触发。
(4) 距离计算
分別从新生数据模型中和社团数据模型中建立新生三元组和社团三元组按照公式(1),进行距离D=新生(Hobby, Inputtime, Clusterlabel)-社团(Hobby, Inputtime, Class)计算。
(5) 聚类中k值确定
由于预先不知新生数据可分为几类,因此,本文根据肘部法则对聚类数量进行估计。随机选取不同专业新生数据中的10人进行评估,分别对这10个同学进行k值为1-9的分类,以平均半径做为簇指标,不同k值与其平均半径的关系如图3所示。
随着k值的增大,平均半径的畸变程度会减小;每个类中的学生数伴随减少,相反,随着k值继续增大,平均半径畸变程度的改善效果会不断减低。畸变程度下降幅度最大的位置即为肘部。从图3中可估计得k为4。
3.3 算法分析
聚类算法中k值即为预分类的聚类个数,本文取4,KNN算法中k值是指被测分类样本最近的前k个样本的个数,本文为了提供更多选择k取12。由于通过聚类操作进行了预分类,因此在进行新生社团推荐时,不需要将所有新生与社团进行距离计算,只在每个新生子类并与该类标签相似的社团上进行距离计算,从而降低了KNN算法的时间复杂度。
3.4 算法流程图
如图4所示。
4 系统设计
社团推荐系统框图如图5所示。
5 系统开发
5.1 开发环境:
(1) 操作系统及主语言:Windows 7 64位,python 3.7.2。
(2) 系统框架及第三方库:Django 2.1.5,numpy 1.16.1,matplotlib 3.0.2。
(3) 前端技术:JavaScript,bootstrap-3.3.7-dist,jquery-1.11.1。
(4) 后端数据库:SQLite3,Redis-x64-3.2.100。
5.2 开发过程
(1) 建立工程:创建名为mysite的工程项目并进行项目manage.py,settings.py,
urls.py等文件配置;
(2) 创建应用:本项目共创建两个应用,即Freshmen应用和Association应用;
(3) 设计Modle:本项目分别在Freshmen和Association应用中设计新生数据模型和社团数据模型;
(4) 创建数据库:设置settings数据库属性,SQLite3数据库为主主数据库用于两个应用的数据存储,Redis数据库用于社团浏览次数的键值对数据存储;
(5) 设计前端模板:在Freshmen应用和Association应用中分别设计用户管理、社团管理、社团浏览、社团介绍、社团推荐等前端页面。通过bootstrap技术和query技术用于前端页面布局、样式设计以及数据提交等功能实现;
(6) 视图处理:分别在两个应用的Views.py文件中编写视图处理函数,响应request请求,并进行处理;
(7) url路由:本别在项目url、Freshmen应用url和Association应用url中分配前端页面请求和处理代码之间的映射。
6 系统测试
本文以某学院80名新生为例进行测试,对这80名新生进行统一注册,首先应用k均值聚类算法进行预分类(k取4),聚类结果如图6所示。分类后每个新生记录会产生一个类别标签,用于和社团集合中的向量进行距离计算。
本系统通过该学院的50个社团进行测试供新生选择。经对新生进行聚类预分类后,将每个类别的新生与社团集合
中相应类别的向量应用KNN算法,将推荐的社团数量降低,结果如表2所示。
本系统新生社团推荐结果页面如图7所示。
7 总结
本文针对现有B/S社团管理系统中智能推荐功能不足的缺点,通过python web技术设计了一款基于Django框架的社团推荐系统。并以降低欧式距离为基础的KNN算法计算样本量为目的,将k均值聚类算法与kNN算法集成为元算法,同时弥补了传统社团推荐依赖于熟人系统的不足,扩大了社团推荐在新生群体的应用范围。经测试,算法有效降低了计算样本量,社团推荐系统功能有效。
参考文献
[1] 王翠香,邵星. 面向Android应用的大学生社团系统设计与实现[J]. 国际IT传媒品牌,2015(36):52-55.
[2] 钮永莉,戴子东. 基于MVC框架的高校社团管理系统研究与实现[J].西安文理学院学报(自然科学版),2018(7):84-87.
[3] 张明东,戴丹丹. Java EE下学生信息管理系统的设计与实现[J]. 才智,2018(3):164.
[4] 王金龙,孙月兴. 基于Python的高等学校社团信息管理系统[J]. 数字技术与应用,2017(8):105-107.
[5] 李嘉琪,李俊,李婷,等. 基于大数据的社团个性化推荐系统[J]. 电脑知识与技术,2017(13):60-71.
[6] 石铠,任泺锟,彭一鸣,等. 基于多节点社团意识系统的属性图聚类算法[J]. 计算机科学,2017(6):433-437.
[7] 王玙,刘东苏. 基于联合聚类与用户特征提取的协同过滤推荐算法[J]. 情报学报,2017(8):853-858.
[8] 雷晓薇. 基于Django框架的教学管理系统的研究与实现[J]. 电子设计工程,2018(18): 39-43.
[9] 杨志庆. 基于的系统的开发与实现[J]. 机电一体化,2013(9):70-72.
[10] Peter Harrington,《机器学习实战》[M]. 北京:人民邮电出版社,2017:187-188.
[11] 张俊晖. Django框架在web开发中的应用[J]. 农业网络信息,2015(2):51-52.
(收稿日期: 2018.11.23)
猜你喜欢
计算机与网络(2021年20期)2021-12-18
科学与生活(2021年19期)2021-10-30
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电机与控制学报(2019年5期)2019-10-21
软件导刊(2018年9期)2018-12-10
软件(2017年6期)2017-09-23
计算机应用(2016年10期)2017-05-12
电子技术与软件工程(2016年23期)2017-03-06
商情(2016年50期)2017-02-28
电子技术与软件工程(2014年18期)2014-11-05
