
一种基于多核CPU加速DLIS测井数据解码方法
2019-10-21 12:00:10钟华明曾少军梁玉楠
测井技术 2019年3期
钟华明,曾少军,梁玉楠
(中海石油(中国)有限公司湛江分公司,广东湛江524057)
0 引 言
DLIS(Digital Log Interchange Standard)[1]格式是Schlumberger公司从1991年开始采用的一种全新的测井数据记录标准,该标准得到了API(美国石油学会)的批准和推荐使用。该数据格式具有与机器无关、自描述、语义可扩展性以及面向对象的数据结构等特点,便于高效处理大量的测井信息以及相关信息。但是DLIS测井数据格式使用统一的语言描述以及面向对象的数据记录方法,使其与las、wis等数据格式具有很大的区别,不能够直接获得文件数据。同时DLIS的设计格式使其与每一个字节都有具体含义的CLS和XTF格式有很大的区别。在做数据解码的时采用DLIS解码流程解码,该方法采用串行解码方式,解码效率往往不高,当文件达到百兆字节以上时,其数据量达到上千万条,文件解码时间超过了测井解释人员可容忍的等待时间[1]。
通过对RP66(Recommended practice 66)文档进行仔细阅读和推理,理清DLIS的特点以及内部结构,根据DLIS内部结构的特点分析可并行的结构,并利用目前普遍使用的多核处理器设计了合适的并行解码算法。
1 DLIS的特点
面向对象的数据结构是DLIS的一大特色[2-4],DLIS采用对象数据结构记录测井信息,包含30多种明确的数据对象,例如数据道对象(Channel Object),帧对象(Frame Object),参数对象(Parameter Object),文件头对象(File-Header Object),数据源对象(Origin Object)等,这些对象均为字典约束定义对象,具有固定的模板结构属性。这种面向对象记录机制,使信息记录变得更加紧凑,一致性和关联性更好。
多帧类型是DLIS最显著的特征。以往的测井数据格式,无论是LIS还是BIT一个文件都只能记录一种采样间隔的数据,而DLIS可以将不同仪器所测得的不同采样间隔的数据通过帧作为索引记录到同一个文件中。
DLIS使用27种数据代码来定义和说明每一种数值,每种数据代码都有明确的码值、字节名称、字节长度以及详细的定义描述标准。因而可以直接使用数值代码转换程序来解码数据,克服了应用平台的限制。
2 DLIS的结构
DLIS采用逻辑格式和物理格式2层格式对数据存储的方式进行说明[1]。逻辑格式是对测井相关信息以及曲线数据逻辑划分进行说明,物理格式说明测井数据存储在物理文件中的比特流。
2.1 逻辑格式
逻辑格式可以细分为4部分:逻辑文件、逻辑记录、逻辑记录段以及可视记录。可视记录是逻辑格式与物理格式之间的接口,每个可视记录在物理媒介中映射到相应的BIT流中,在逻辑格式中映射到所包含的逻辑记录段,它可以包含1个或者多个逻辑记录段。每个逻辑记录段只包含在1个可视记录中,它包含了逻辑记录在物理存储介质中描述和实现所需的结构,用来在可视记录中分离不同的逻辑记录,同时逻辑记录段是最小的加密逻辑结构体。逻辑记录将连续的、相关联的信息包组织在一起,从语义上看,它有2种逻辑组织方式:EFLR(Explicitly-formatted Logical Record)和IFLR(Indirectly-formatted Logical Record)。EFLR是一种自我描述的逻辑记录,逻辑记录体的信息格式可以从记录本身得到。IFLR这种逻辑格式一般记录的是测井曲线数据,记录体的数据格式不能直接从记录本身解码得到,它必须关联到相应的EFLR,并利用相应的数值转换程序才能够解码所记录内容,两者的关系见图1。每个逻辑记录可以包含1个或者多个逻辑记录段,由逻辑记录段的Predecessor属性来判断逻辑记录的开始,由Successor属性字段来判断逻辑记录的结束。每个DLIS中包含1个或者多个逻辑文件,每个逻辑文件包含了1个或者多个逻辑记录,由逻辑记录FILEHEADER对象标识每个逻辑文件的开始位置。

图1 逻辑记录格式关系
2.2 物理格式
物理格式是数据在物理媒介中存放和组织的方式,物理格式可以分为3个互不相关的部分:逻辑格式、不可见信封以及可见信封(见图2)。
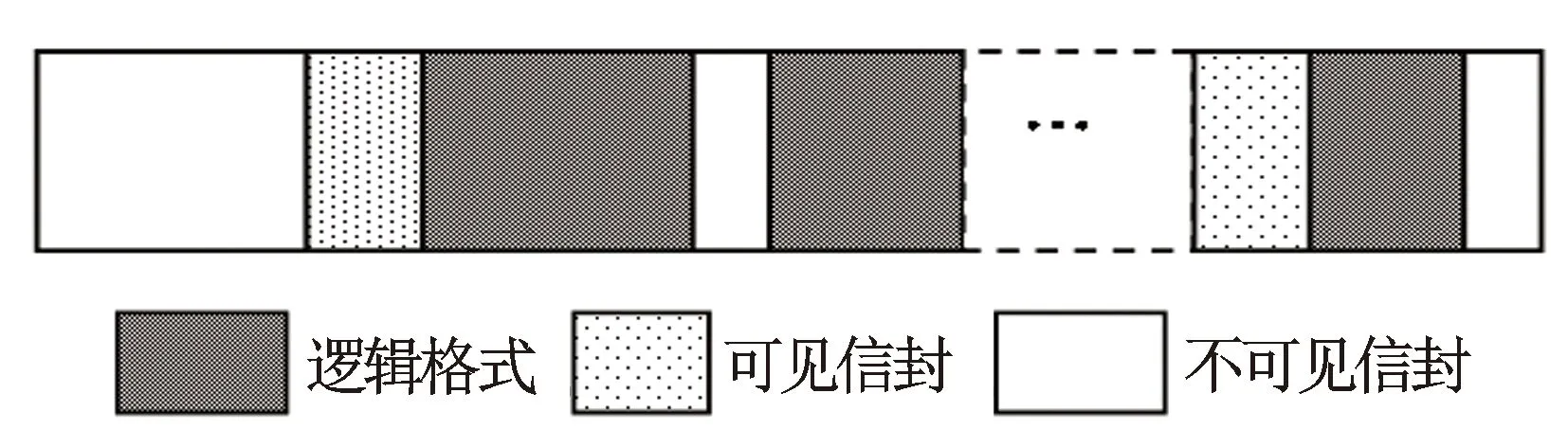
图2 物理记录格式
逻辑格式记录的是可以应用的数据;不可见信封记录是受到存储机制控制的,它不能按常规的数据读写,它是存储机制和应用程序之间的控制接口,通过特殊的查询程序进行访问。可见信封记录的是数据传递的信息以及物理格式的定义,但是其记录的数据不是逻辑记录的一部分。存储单元标识SUL(Storage Unit Label)是由ASCII码字符串组成的可见信封,它是DLIS数据文件的入口,定义了DLIS数据格式的版本号、存储单元序列号等相关信息,用来标识一个逻辑文件是否跨越多个存储单元。
3 并行算法设计
3.1 多核CPU并行计算
随着计算机硬件的快速发展,多核处理器在PC机上的普及,多核和多线程已经成为应对处理器性能提升中遇到的瓶颈问题的一种可行的方法,多处理器和多核技术已经得到了广泛应用[5-9]。但是多线程并发编程无论在性能分析还是调度优化一直都存在很高的难度,使多核技术没有得到更好的应用。针对这个问题,微软公司的Visual Studio从2010版开始加大了对并行编程的支持,同时引入了Concurrency Visualizer分析工具,在一定的程度上降低了并行性能的分析难度,帮助开发者分析可并行执行的代码,能够较好地满足多核并行计算编程的要求。
3.2 DLIS并行设计
每个DLIS包含大量独立存储的EFLR和IFLR记录。EFLR和IFLR都是以对象独立分离存储,因此,在设计算法的时候,可以对每个EFLR和IFLR进行并行计算;但实验发现加速比并不明显。这是因为不同的EFLR或者IFLR其内部的数据所对应的数据格式不同,在数据解编前,需要映射到相应的数据表示码,增加了并行通讯的任务量,使解编效率无法提升;同时DLIS的数据体主要使用IFLR来存储,IFLR含有大量的数据,而且数据的表示码不同,IFLR的解码速度直接制约了DLIS解编效率。
IFLR逻辑记录中保存EFLR记录FRAME对象中所包含的曲线列表在某一个采样点的数据记录;每条曲线在同一采样点有一维或者多维采样记录,即包含一个或者多个采样数据。同一条曲线所有采样数据的数据表示码是相同的,其表示码和维数可以从EFLR记录CHANNEL对象中获取。为了减少程序间的调用及通讯,加快并行解编速度,对IFLR记录按照曲线拆分,对拆分的曲线并行解码;结果表明,这种方式实现的并行解码能够获得较好的加速比。
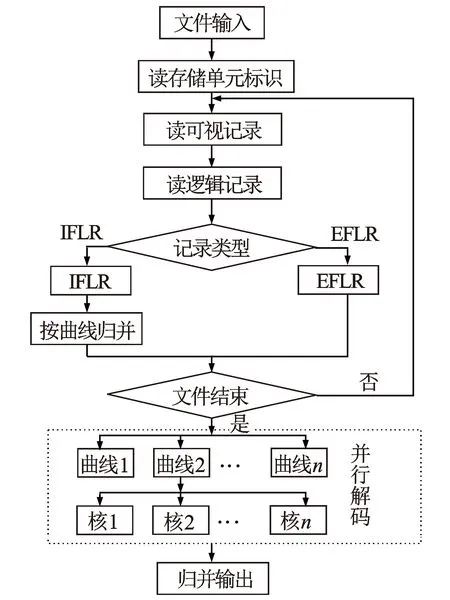
图3 算法流程图
图3为DLIS并行解码流程图,根据EFLR和IFLR这2类逻辑记录中,分离出曲线数据体,对曲线数据体进行划分并映射到CPU的运算核中,实现并行解码。
4 DLIS解码算法实现
在解编之前,首先根据FRAME对象曲线列表等相关信息对每条曲线数据进行分离,然后根据CHANNEL对象对每条曲线数据进行归并后并行解码。DLIS并行解码采用Visual Studio并行模式库(PPL)中的parallel_for_each方法实现。算法实现描述见图4。

图4 DLIS解编算法描述
5 结果分析
实验环境为Intel core(TM)i7-4710MQ 2.56 GHz CPU,选择9个不同大小的DLIS文件来测试所设计的并行算法,文件大小从几兆到200多兆之间,并将该算法运行结果与易朝建、黄政在磁带数据格式解编方法中提出的DLIS串行解编方法运行结果进行对比。
其加速比计算采用式(1)进行计算,结果见表1。
(1)
式中,sp为加速比;Δtp为本程序运行时间;Δty为易朝建所建立的算法程序所运行时间。
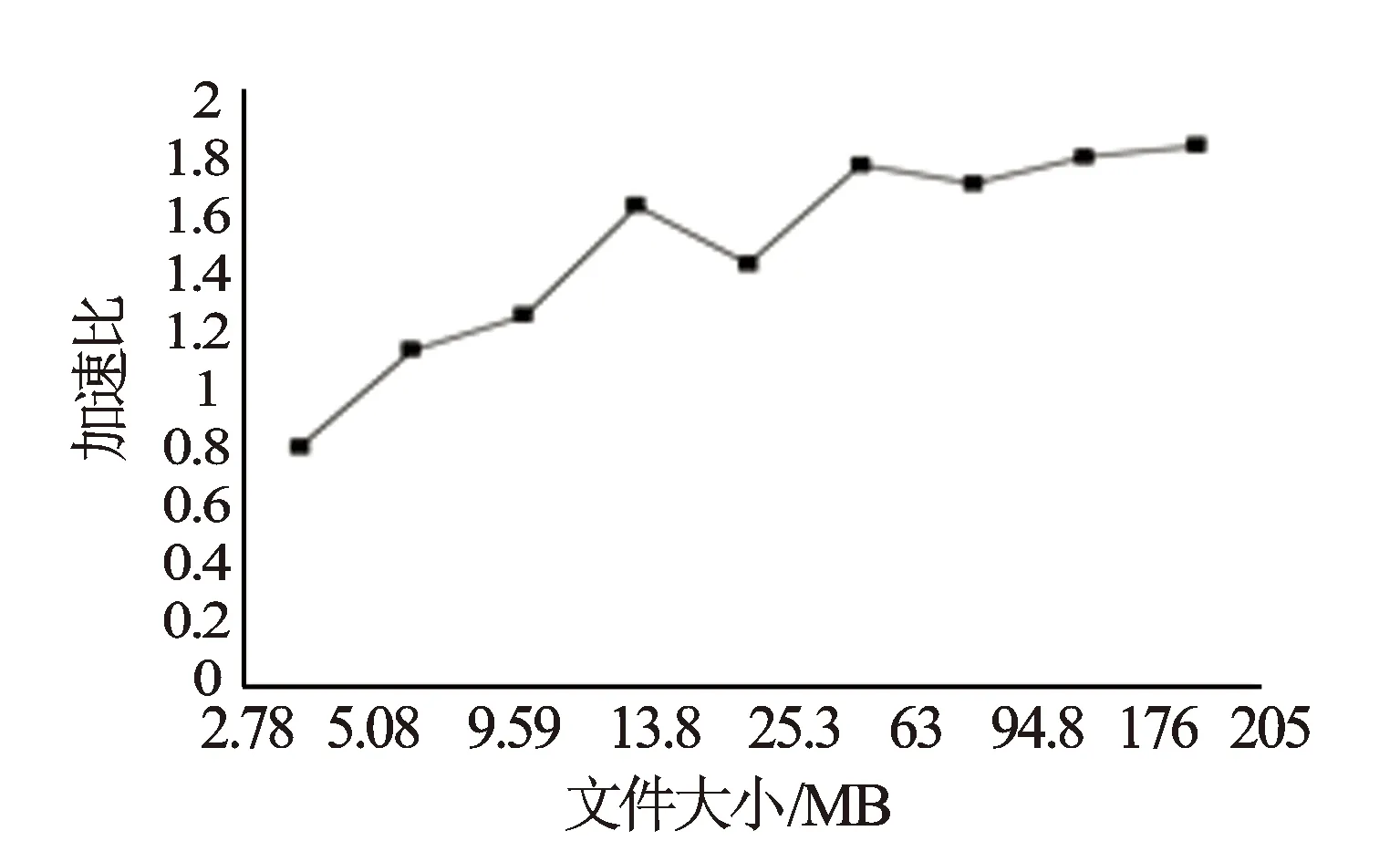
图5 加速比随着文件大小变化
从图5中可见,当文件小于5 MB时,多核CPU并行解编速度并不优于串行解编速度,这是由于在并行解码的过程中,需要消耗过多的通讯时间,抵消了并行运算带来的优势,降低了解码效率。当文件大于5 MB后,其解编的加速比随着文件的大小不断加大,当文件大小趋200 MB时,加速比趋近2。
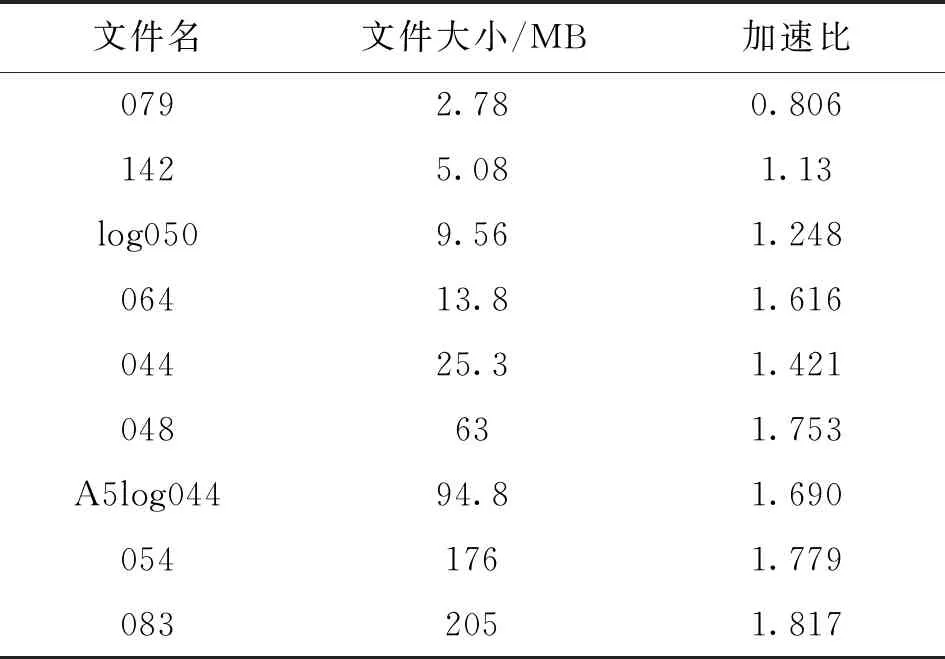
表1 算法运行加速比
因此,当文件很大的时候,并行解编速度比串行解编快近一倍,减少用户等待时间。
6 结 论
基于多核CPU加速DLIS并行解码方法在生产中的应用结果表明,当DLIS文件小于5 MB,采用串行解码方式能够获得更快的解码速度,优于并行解码;当DLIS文件大小大于5 MB,多核CPU并行解码方法远优于串行解码方法,并随着DLIS文件大小增加,加速比快速增大,并趋于2。因此,当DLIS文件较大时,采用基于多核CPU加速DLIS并行解码方法能够获得较好的效果,在一定程度满足用户对解码响应的需求。
猜你喜欢
测井技术(2022年3期)2022-11-25 21:41:51
中国石油石化(2022年12期)2022-07-16 08:28:28
中国煤层气(2021年5期)2021-03-02 05:53:12
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
电子测试(2018年1期)2018-04-18 11:52:49
中国煤层气(2015年4期)2015-08-22 03:28:01
淮南师范学院学报(2015年3期)2015-03-22 01:16:16
中国质量与标准导报(2015年2期)2015-02-28 22:27:15
