
基于膨胀卷积神经网络模型的中文分词方法
2019-10-21 02:01王星,李超,陈吉
中文信息学报 2019年9期
王 星, 李 超, 陈 吉
(辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105)
0 引言
不同于英语中每个单词之间有分隔符,汉语中词语没有明确的分隔符。因此中文分词(Chinese word segmentation, CWS)是中文处理的基础任务,分词的好坏直接影响后面的自然语言处理任务[1]。自从Xue等[2]用最大熵模型四词位标注集进行中文分词之后,许多方法将中文分词作为序列标注问题进行处理,这样可以使用监督学习[3-4]或半监督学习[5-6]的方法处理,然而这些方法受到特征选择和特征提取的限制[7]。
近年来深度神经网络模型已经成功用于多项自然语言处理任务中。Collobert等[8]提出一种神经网络模型来完成序列标注任务。此后,许多方法将神经网络模型应用到中文分词任务中。Zheng等[9]首先将带窗口的前馈神经网络模型应用到中文分词任务中。Pei等[10]在Zheng等[9]的基础上提出最大张量边界模型MMTNN,利用张量和标签间的关系表示标签与上下文之间的关系。Chen等[11]提出了一种带有重置门和更新门结构的递归神经网络模型(GRNN)来保留上下文信息,并且提出了分层训练防止梯度扩散现象。Chen等[12]提出用单向的LSTM神经网络来获取前文信息的方法。Yao等[13]舍弃了窗口的方法,针对单向LSTM的不足进行了改进,提出了基于双向的LSTM网络的中文分词方法,有效提高了模型的效果。Xu等[14]同样在GRNN模型上提出了一种改进方案,利用LSTM和递归神经网络更好地结合局部信息。Cai等[15]提出一种新颖的神经网络模型,并不是采用上下文的窗口,而是构建句子完整的切分历史,直接在结果上进行建模,但存在训练和测试速度慢的问题。Cai等[16]在这基础上做了一定的改进,将模型里的Beam Search算法改进为贪婪算法,大幅减少了模型训练和测试的时间。Zhang等[17]提出了基于词的转移模型,对句子从左往右进行增量解码,能有效利用字和词的融合特征来进行分词。
以上分词模型取得了不错的效果,但还存在以下不足:(1)输入以汉字为主,没有使用汉字的字根特征、五笔特征等更深层的信息;(2)模型以循环神经网络为主。采用循环神经网络特征提取时,根据输入序列长度进行顺序计算,计算效率受到限制。针对第一个不足,本文在输入特征时加入字根特征,字根特征能够有效提高分词效果[18],使用卷积神经网络对字根进行特征提取,并将字根特征与字符特征融合作为整体输入特征,能够更好地理解汉字语义信息。针对第二个不足,本文模型采用卷积神经网络,卷积神经网络能够有效提高分词效果[19],卷积神经网络能够独立于序列长度运算,减少训练和评估模型所花费的时间。在整个序列中,卷积神经网络不是递增表示每个字符,而是将卷积核作用于整个序列,其计算成本随着卷积层数的增加而增加,而不再是由输入序列的长度所决定。为了减少卷积神经网络的层数,提高计算效率,本文采用膨胀卷积作为主要模型。与典型的卷积神经网络层一样,膨胀卷积也是使用滑动窗口作用于文本序列上,不同的是膨胀卷积窗口可以跳过宽度为δ的输入,通过控制膨胀卷积窗口跳过的字符长度,能够使用更少的卷积层来提取整个序列的特征。此外,本文在卷积层中加入残差结构来解决神经网络因层数增加而出现的退化问题。实验表明,字根特征的引入,并结合加入残差结构的膨胀卷积神经网络,有效改善了中文分词效果,并提高了中文分词的速度。
1 膨胀卷积神经网络模型
中文分词任务通常被认为是序列标注问题,通过所属标注来判断每个字符在词语中的位置,常用的标注集是{B, M, E, S},利用这四种标注获取词语的边界信息,其中B、M、E表示词语的开头、中间、结尾,S表示单个字。
基于神经网络的序列标注任务通常由三部分组成: (1)浅层特征层,即向量化表示;(2)神经网络层;(3)标签推理层。
1.1 浅层特征层
在双向长短时记忆网络中文分词模型中,浅层特征层使用汉字的嵌入式表示,通常用查找表来找到字符的向量表示。而本文加入字根特征,如图1所示。字根特征用卷积神经网络进行特征提出,并与字符特征融合作为模型的输入特征。用c表示字符,r表示字根,则字符c的字根列表xr=[r1,r2,…,rn],输入特征如式(1)所示。

图1 字符—字根融合特征
1.2 神经网络层
1.2.1 膨胀卷积
卷积操作是卷积神经网络的重要特征,卷积层以特征映射为组织方式,其中的每个单位与前一层的局部感受野相连接,利用共享的卷积核与局部感受野做卷积运算,再经过激活函数做非线性运算来得到特征值。通常神经网络中卷积运算以二维形式出现,但由于自然语言处理任务的特殊性,卷积在自然语言处理任务中以一维卷积的形式出现。对于字符序列x,使用一维卷积核W卷积,结果c可由式(2)得出。
膨胀卷积核与一般卷积具有相同的操作,不同的是可以一次跳过δ个输入宽度,在更长的有效输入上定义卷积操作。具体定义如式(3)所示,其中δ是膨胀宽度。当δ=1时,膨胀卷积就成为一般卷积操作,当δ>1时,膨胀卷积能够扩展字符上下文宽度。


图2 堆叠膨胀卷积
随着卷积神经网络层数的加深,会出现过拟合现象。在膨胀卷积神经网络中使用批量归一化方法并加入残差结构,使用模块化方法来训练,这种模块化方法将前一层输出特征作为下一层的输入特征,同时能够共享网络参数,能够有效缓解过拟合情况。
1.2.2 膨胀卷积神经网络


图3 残差结构


最后使用线性变换得到每个字符xt属于每个类别的得分,如式(9)所示。
1.3 标签推理

本文使用两种方法处理输出标签的预测。首先使用式(11)。这种方法将每个字符的标签认为是条件独立的,使用贪婪算法得到输出标签序列。
然而输出标签彼此都要相互影响,因此考虑到线性条件随机场模型作为预测模型,如式(12)所示。
其中,Ψ(y|x)是特征函数。如果具体只考虑连续的两个标签,如式(13)、式(14)所示。
其中,s(x,y)是每个标签的评分函数,具体如式(15)所示。
线性条件随机场明确表明了相邻标签间的相互作用,虽然需要在输出空间中全局搜索,但能够满足某些输出约束,具有更好的特征复杂性,对于标签之间的相互关系提供了更多的先验信息。
2 训练
将膨胀卷积神经网络作为一种编码器,由式(9)来得到每个字符的概率。如果将标签看作是相互独立的,可以直接用最大似然方法训练解码。如果将标签看作相互作用的,用条件随机场方法训练解码。

在每个模块之后,通过增强正确的预测值来学习模型,后面的模块则不断优化初始预测。这种处理损失的方法能够缓解深层结构的梯度消失问题,广泛用于计算机视觉领域[21]。
本文在浅层特征层x和每个模块的输出mt之后使用了dropout方法来帮助缓解过拟合现象,在膨胀卷积网络中使用批量归一化(bath normalization,BN)方法并加入残差结构,有效规避复杂参数对网络训练产生的影响,加速训练收敛的同时提高了网络的泛化能力。
3 实验设计与分析
3.1 实验环境、数据集和评测标准
本文实验配置为: Inter(R)Core i7-6800K@3.40GHZ处理器,操作系统Ubuntu16.04 LTS(64bit),运行内存16GB(RAM),显卡: GIGABYTE GeForce GTX1080Ti,使用TensorFlow 1.12构建神经网络模型进行训练和测试。
本文实验数据采用由Bakeoff2005提供的PKU,MSR,CITYU,AS四种数据集,四种数据集的分词标准各有不同。PKU是由北京大学计算语言学研究所提供的语料库,其分词特点是姓名中姓和名要分开,组织机构等在语法词典中的直接标记,大多数短语性的词语先切分再组合。MSR是微软亚洲研究院所提供的语料库,其分词特点是由大量的命名实体构成的长单词。AS是由台湾中央研究院提供的语料库,分词规范与北大制定的分词规范类似,同时也与台湾地区的语言使用习惯相关。CITYU是由香港城市大学提供的语料库,分词规范受香港地区的使用习惯影响。数据集规模如表1所示。其中随机选取训练数据的90%作为训练集,10%作为开发集。所有的数据在输入前需要经过预处理,将英文字母替换成X,数字替换成0。

表1 Bakeoff2005数据集
所有实验均采用标准Bakeoff评分程序计算常用的评测指标:P(准确率),R(召回率),F1(召回率和准确率的调和平均值),以F1值为主要评测指标。计算公式如式(17)~式(19)所示。
3.2 实验设计
本文与中文分词中常用的双向长短时记忆网络模型做对比,解码器分别使用贪婪算法(BiLSTM)和条件随机场(BiLSTM+CRF)。对于膨胀卷积神经网络做了多种对比实验: (1)使用基本的膨胀卷积神经网络模型(DCNN)进行训练;(2)膨胀卷积神经网络模型使用条件随机场解码(DCNN+CRF);(3)膨胀卷积神经网络模型加入残差结构(DCNN+Res);(4)膨胀卷积神经网络模型加入残差结构并使用条件随机场解码(DCNN+Res+CRF)。以上BiLSTM模型和DCNN模型都使用字符和字根的融合特征作为浅层特征层的输入特征。实验结果如表2所示。

表2 分词模型评价指标对比

续表
本文比较了各个模型的处理速度。在每个数据集中,以其中速度最慢的为1.0,其他模型的速度是与速度最慢的比值。实验结果如表3所示。

表3 分词模型在Bakeoff2005数据上处理速度
本文将DCNN模型与近年来中文分词神经网络模型做对比。实验结果如表4所示。
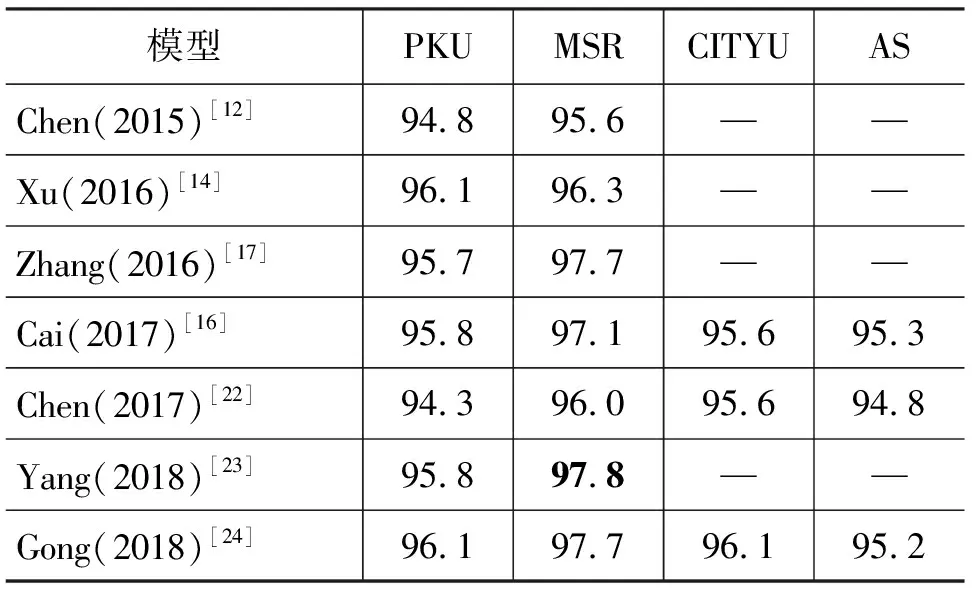
表4 与其他模型对比

续表
主要参数设置如表5所示。字根向量和字符向量采用随机初始化的方式,向量维度都设置为100。对于浅层特征输入和神经网络中每个模块输出都使用dropout,且设为0.15。优化算法使用Adam对模型进行优化,初始学习率设为0.001,并以1.0的速度进行衰减。卷积层数为4。梯度裁剪参数为5。设置每个batch为128,迭代100轮次。

表5 参数设置
3.3 实验分析
3.3.1F1值结果分析
为了验证条件随机场(CRF)的影响,本文在每个模型解码的时候都分别使用了贪婪算法和条件随机场两种解码方式。以表2中PKU数据集的实验结果为例,BiLSTM+CRF比BiLSTM提高了0.89%,DCNN+CRF比DCNN提高了0.10%,DCNN+Res+CRF比DCNN+Res提高了0.08%。通过对比可以发现,条件随机场解码确实能够提高模型分词结果,而且对于BiLSTM模型的影响较大,对于DCNN模型提高的较少。MSR、CITYU、AS三个数据集也出现同样的现象。表明条件随机场考虑到前后字符之间的相互关系进行全局搜索时,与BiLSTM这种与时间序列模型相关性更大。
为了验证DCNN模型的效果。将DCNN模型与BiLSTM模型的实验结果做对比。以表2中PKU数据集的实验结果为例,DCNN模型比 BiLSTM 模型提高了1.26%,DCNN+CRF模型比BiLSTM+CRF模型提高了0.47%,DCNN模型比BiLSTM+CRF提高了0.37%。在MSR、CITYU、AS三个数据集中,DCNN(+CRF)模型的F1值也要高于BiLSTM(+CRF)模型。而且DCNN模型在不使用CRF情况下,其F1值已经能够达到与BiLSTM+CRF模型相同的效果,甚至要更好些。说明DCNN模型在处理中文分词中有很好的优势。
为了验证残差结构的效果。将DCNN+Res模型与BiLSTM模型和DCNN模型的实验结果做对比。以表2中PKU数据集的实验结果为例,DCNN+Res模型比BiLSTM模型提高了1.36%,DCNN+Res+CRF模型比BiLSTM+CRF模型提高了0.47%。DCNN+Res模型比DCNN模型提高了0.05%,DCNN+Res+CRF模型比DCNN+CRF模型提高了0.04%。加入残差结构后DCNN模型的实验结果有一定的提高。
3.3.2 模型速度分析
以表3中PKU数据集的实验速度为例,DCNN模型的速度约是BiLSTM模型的2.5倍,DCNN+CRF模型的速度是BiLSTM+CRF模型的两倍,DCNN+Res(+CRF)和DCNN(+CRF)速度相差不大。DCNN模型整体要比BiLSTM模型速度要快。每个模型在使用CRF解码时,速度变慢许多。在MSR、CITYU、AS三个数据集中,实验速度的结果分析和PKU数据集中的实验结果相同。说明DCNN在处理速度上具有很大优势。
综合表2和表3分析。DCNN模型F1值比BiLSTM模型好,处理速度更快。DCNN模型不使用CRF情况下与BiLSTM+CRF模型的F1值相差不大,处理速度却约是BiLSTM+CRF模型的3倍。而加入残差结构后,DCNN+Res模型的F1值和速度都要比BiLSTM+CRF模型好。通过分析比较,DCNN模型在F1值和速度上都取得更好的效果。
3.3.3 与其他模型对比分析
表4列出与其他模型的对比。比较对象为Chen扩展的LSTM模型,Xu的GRNN改进模型,Zhang的基于词的转移模型模型,Chen的对抗神经网络模型,Cai的句子切分模型,Yang的Lattice LSTM模型,Gong的LSTM转换模型,Zhang的LSTM联合学习模型。
由表4可知,DCNN模型与近年来深度学习中文分词模型相比中取得不错的结果。PKU数据集和CITYU数据集略好与其他模型结果,比Gong提高了0.1%。MSR数据集上结果略差些。AS数据集的实验结果得到了很好的提高,比Gong提高了2.1%。
4 结论
本文工作主要有以下几点: (1)针对自然语言处理中的中文分词任务,使用膨胀卷积神经网络结构进行分词;(2)使用字根特征来丰富输入特征,能够更好地理解文本语义信息;(3)将残差结构加入神经网络中,有效缓解了神经网络中梯度消失的问题;(4)在训练时使用模块化方法,并优化模块中平均损失。实验结果表明本文使用的DCNN神经网络的方法相比于传统的BiLSTM模型能够提高分词的结果,并且能够大幅度提高分词的速度。
本文使用的膨胀卷积神经网络虽然能够对中文分词结果进行有效的改善,但还有进一步改进的空间。在实验中发现,CRF解码方式严重影响中文分词的速度,后续工作将寻找更高效的解码方式来优化。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
