
一种基于随机游走的歌曲推荐算法
2019-10-18 09:18:44吴雪君米红娟
网络安全与数据管理 2019年10期
吴雪君,米红娟,李 欣
(兰州财经大学 信息工程学院,甘肃 兰州 730020)
0 引言
互联网的快速发展使得用户在面对呈指数级增长的信息量时很难挖掘出有用的资源。推荐算法的出现在一定程度上为用户缓解了这个难题。推荐算法主要通过历史数据中用户对项目的行为操作,利用相应算法计算相似度,为用户推荐他可能感兴趣的项目。现在已经有许多实际的应用,如Netflix的电影推荐,亚马逊网站的图书、CD推荐等。
常见的主流音乐推荐算法可以分为三种:基于内容的推荐算法、协同过滤推荐算法、混合推荐算法。基于内容的推荐算法[1]易于实现,它只需要用户个人的历史数据,分析用户曾经喜欢过的歌曲的属性信息,计算所用歌曲间的相似度,为用户推荐相似的未收听过的歌曲。但是推荐结果缺乏多样性,且特征提取的方法受到技术的限制。协同过滤推荐算法[2-3]是根据历史数据中用户对歌曲的评分(评分数据可以是用户对项目的各种操作),计算相似度,发现偏好相同的用户,根据相似用户的偏好预测目标用户对其他歌曲的喜好程度,不足之处是存在冷启动问题和数据稀疏性问题。混合推荐算法将上述两种算法互补组合进行推荐,比如Stanford大学推出的Fab系统,将两种算法结合为用户提供个性化推荐[4]。
有学者也提出了新的推荐算法,例如基于图结构进行推荐。传统的随机游走(Random Walk,RW)[5]是一种理想的数学模型,它从所处的节点出发,以相同的几率游走到其某一个邻居节点,可以将它假设成马尔科夫链。随着研究的发展,随机游走模型也被应用在推荐系统中,实现对用户的个性化推荐。YILDIRIM H等人[6]提出了一种基于随机游走模型的面向项目的协同过滤推荐算法,使用项目间的余弦相似度和修正的余弦相似度来初始化状态转移概率,该模型能在稀疏数据下增强相似性矩阵。ZHANG L等人[7]提出了一种基于分类随机游走的推荐算法,引入了分类等级分数,针对用户对不同类别的偏好进行推荐。对于冷启动问题,SHANG S等人[8]利用社交信息来解决缺少用户评分信息时的冷启动问题,通过构建用户-项目有向图,结合项目内容和社交信息为用户进行推荐。
近年来,场论在其他学科中的应用越来越广泛,已有学者提出经济场、物流场等概念与理论。费孝通[9]提出“场”是一个研究多学科的综合平台,可以给其他学科的研究提供新的理论依据与研究视角。汤银英[10]在物流场的基础上,建立了物流场理论体系,研究了物流场的各种特性,构造了发展动力场模型,为物流企业的发展提供策略。
本文提出一种基于随机游走的音乐推荐算法,首先根据歌曲的基本信息和用户的收听数据,计算歌曲间的综合相似度,降低评分矩阵的稀疏性,构建歌曲相关图,再结合物理场论中的场力公式,将歌曲看作相互作用的节点,结合音乐的重要度,确定随机游走模型中的转移概率矩阵,降低随机游走的时间复杂度,提高歌曲推荐的准确性。
1 推荐算法相关理论
1.1 随机游走模型
随机游走由一系列随机的轨迹组成,在推荐系统中,对于m个用户和n个项目,模型中用户游走到当前节点的概率由前一步P(Xu,d+1=j|Xu,d=i)决定,Xu,d=i表示用户u随机游走d步后在项目i处的随机变量[6]。
Pij=P(Xu,d+1=j|Xu,d=i)
(1)
其中,Pij∈P,P为m×n的转移概率矩阵。


(2)
定义用户u在节点j的总概率如式(3)所示。
(3)
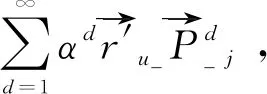
1.2 场论模型
场是物质存在的基本形式,相互作用存在于场之间,如温度场、电场、磁场等。在场中,某物质对其他物质产生的影响可以用作用力表示。在万有引力场中,任意两质点间的引力由式(4)计算。

(4)
场力的统一公式如式(5)所示。
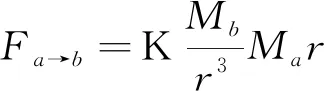
(5)
其中,K是常数,M表示物质的特性(包括式(4)中的M1与M2,式(5)中的Ma与Mb),比如质量、重要性等,r是两种物质之间的“距离”。
2 基于随机游走的歌曲推荐算法
2.1 构造歌曲相关图
2.1.1 歌曲评分相似度
设用户集U={u1,u2,...,ua,...,um},歌曲集I={i1,i2,...,ij,...,in},根据数据集中用户的行为操作,构造二部图G=
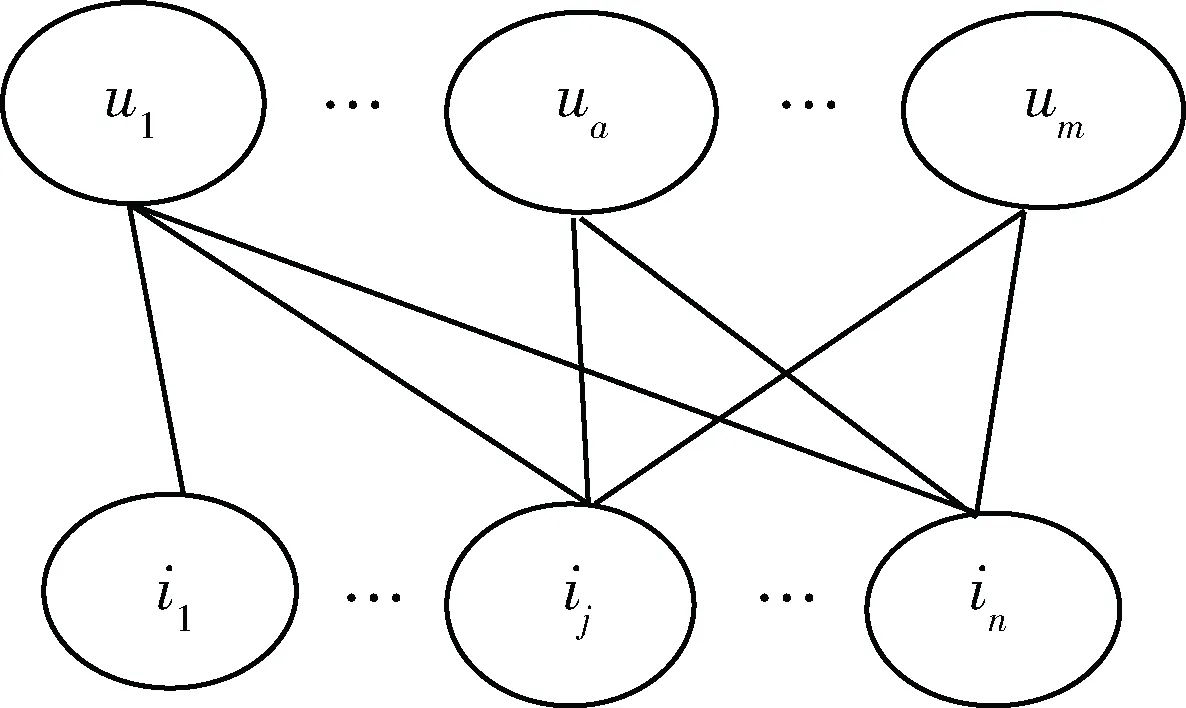
图1 二部图示例
基于协同过滤的歌曲推荐算法通过分析历史数据集中用户对歌曲的评分来获得项目或用户间的关系。对于m个用户和n个项目,用户对项目进行自己的操作,比如购买、分享、删除等,这些行为操作表示了用户对项目一定的喜恶程度,是一种隐式评分。在如式(6)所示的用户-项目评分矩阵R中,raj表示第a个用户对第j个项目的评分值。传统的协同过滤推荐算法通过评分矩阵计算相似度,得到具有相似偏好的用户或项目进行推荐。本文使用的数据集中用户的历史操作是以收听歌曲的次数计数,所以以用户收听某首歌曲的次数来作为用户对项目的评分。

(6)
歌曲ix和歌曲iy的评分相似度计算的基本思想是,找出既收听过歌曲ix,也收听过歌曲iy的所有用户Uix,iy,然后计算相似度Simix,iy。计算歌曲相似度的方法有很多,如皮尔逊相关系数、余弦相似度、修正的余弦相似度[11]等。
经过对现有语料的分析,用户收听某首歌曲的次数变化范围在1~7 939之间,用户一般不会再次收听不喜欢的歌曲,但是会不断循环收听喜欢的歌曲。根据数据集中用户收听歌曲的历史行为,生成User-Item矩阵。为消除用户收听歌曲存在的次数差异,通过式(7)对数据做最大值最小值归一化。
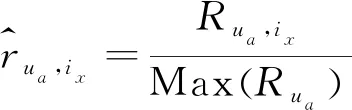
(7)
其中,Max(Rua)表示第a行元素中的最大值,即用户ua收听单首歌曲的最大次数,Rua,ix表示用户Ua收听歌曲ix的次数。
本文选取改进的余弦相似度方法计算歌曲评分相似度,如式(8)所示。
Sim1(ix,iy)=
(8)

2.1.2 歌曲基本信息相似度
根据数据集中音乐的固有信息,例如曲风、演唱者、发行年份等,计算歌曲基本信息相似度。
①曲风属性可以作为标签属性,其取值为摇滚、金属、说唱等,属性间的相似度用式(9)计算。
(9)
其中,S1(ix,iy)表示歌曲ix与iy之间的曲风相似度,K表示两首歌曲共有的标签数,N表示该属性所有的标签数。
②发行年份属性,对年份进行分段处理,比如10年作一次划分,年份从1922年~2011年,则1922年记为1,1931年记为2,2011年记为10,划分后用式(10)计算两首歌曲之间的发行年份相似度。
S2(ix,iy)=e-|Tix-Tiy|
(10)
其中,S2(ix,iy)表示歌曲ix与iy的发行年份相似度,Tix、Tiy分别表示歌曲ix和iy的发行年份所处的分段值。
③演唱者属性,将演唱者属性看作二元属性,即两首歌曲的演唱者相同记为1,不同记为0,用Sim3(ix,iy)表示歌曲ix和iy的演唱者相似度。
歌曲ix和iy的基本信息相似度通过Sg(ix,iy)(g=1,2,3)的加权求和得到,如式(11)所示。
(11)
其中,w1表示曲风属性占的权重,w2表示发行年份属性占的权重,w3表示演唱者属性占的权重。
2.1.3 歌曲相关图
由歌曲评分相似度Sim1(ix,iy)和歌曲基本信息相似度Sim2(ix,iy)加权求和计算歌曲综合相似度Sim(ix,iy),如式(12)所示。
Sim(ix,iy)=αSim1(ix,iy)+βSim2(ix,iy)
(12)
其中,参数α、β分别表示歌曲评分相似度和歌曲基本信息相似度所占的权重。
2.2 改进的随机游走推荐模型
传统的随机游走算法在时间复杂度上有明显的缺点,因为在为每个用户进行推荐时,都需要在整个用户-项目二部图上进行迭代,直到每个项目被选择的概率值收敛,这一过程的时间复杂度非常高。改进后的随机游走算法通过构建转移概率矩阵,大大降低了算法的时间复杂度。
由歌曲综合相似度,得出对应的相似度矩阵M1。运用式(5),计算作用力矩阵Mforce。其中距离r用歌曲节点间的综合相似度Sim(ix,iy)来计算,如式(13)所示。两首歌曲越相似,Sim(ix,iy)越大,r就越小,表示歌曲间的“距离”越近。
(13)
式(5)中的物质特性M采用歌曲的重要性,即歌曲的度来衡量,歌曲的度为用户-歌曲二部图中歌曲顶点连接的路径数,也就是收听过这首歌曲的用户数,根据用户-歌曲二部图得到每首歌曲的度outix。由于每一项都有常系数K,通常K取1,得到歌曲间的场力如式(14)所示。
(14)
综上,得到作用力矩阵Mforce,其中Mforce(ix,iy)=Fix→iy,Mforce(ix,ix)=0。
对Mforce进行归一化计算,得到转移概率矩阵Mtran,其中Mtran(ix,iy)如式(15)所示。
(15)
通过Mtran计算出各节点对应歌曲的最终推荐值N,如式(16)所示,将推荐值N按从小到大排序,得到推荐结果。
由N=(1-λ)N0+λNMtran得[12]:
N=(1-λ)(1-λMtran)-1N0
(16)
其中,N是所有节点的推荐值向量;N0是一个n×1的列向量,表示目标用户的收听记录,N0(ix)=1,表示该歌曲被目标用户收听过;N0(ix)=0,表示该歌曲未被目标用户收听过,参数λ表示权重。
3 推荐算法实验及结果分析
3.1 数据集
公开数据集Million Song Dataset(MSD)包含了一百万首歌曲的特征分析和元数据。其他几个互联网音乐社区贡献了相关互补数据集,例如The musiXmatch Dataset提供了歌曲的歌词数据。The Last.fm Dataset提供了歌曲信息、艺术家信息等。Kaggle曾经举办过The Million Song Dataset Challenge,利用了一百万用户的播放记录数据。
本文使用到的数据是MSD的子集The Echo Nest提供的可以与MSD关联的user-song-play count数据集。数据集有元数据和评分数据,其中元数据包括歌曲的曲风、演唱者、发行年份,评分数据是用户收听歌曲的次数。
3.2 实验与结果分析
实验中训练集为100万用户的收听歌曲的记录,Kaggle比赛提供了额外的11万用户对38万多首歌曲的收听记录,验证集为其中1万用户的收听记录,测试集为剩余10万用户的收听记录,测试集中一半的收听数据可见。
根据歌曲元数据计算歌曲基本信息相似度时,对于歌曲的基本信息,曲风、年代、演唱者三者之间存在一定的联系,例如某一演唱者属于某一年代,他的歌曲一般在这一年代较流行,也具有该年代的主流曲风。本文实验中曲风、年代、演唱者所占自的权重均为1/3。
经过实验证明,计算歌曲综合相似度时,歌曲评分相似度Sim1(ix,iy)和歌曲基本信息相似度Sim2(ix,iy)的权重为α=0.4,β=0.6时实验效果最佳。计算歌曲最终的推荐值N时,参数λ取经验值0.85。
本文采用Kaggle比赛中使用的平均精度均值(Mean Average Precision,MAP)作为评价指标,评价歌曲推荐方法的准确性,其公式如下:

(17)
其中:MAP@500表示给第a个用户推荐Top500的音乐的平均准确率,U表示所有的用户数量。
Kaggle比赛第一名Aiolli使用基于内存的协同过滤进行推荐,以该实验的结果作为参照进行对比,结果如表1所示。

表1 算法运行时间比较
从表1可见,改进的随机游走歌曲推荐算法提高了推荐的准确性,利用歌曲综合相似度建立歌曲相似度矩阵,降低了相似度矩阵的稀疏度,再由歌曲的重要性结合场力公式,构造转移概率矩阵,基于随机游走进行推荐,相比于协同过滤算法,该算法具有更好的推荐准确性。
4 结论
本文提出了一种基于随机游走的歌曲推荐算法,引入物理学中的场论理论,解决了随机游走算法同等对待节点的不足,通过计算歌曲综合相似度,降低了相似度矩阵的稀疏度,将歌曲的重要性和场力公式结合,构造转移概率矩阵,进行基于随机游走的推荐。实验证明,该方法比一些传统的协同过滤方法具有更好的推荐准确性。但本文仅利用了歌曲的基本信息和评分数据,没有充分利用歌曲的其他重要特征,后期将继续研究如何融合歌曲的更多特征,比如音频特征、歌词特征等,以提高算法的推荐准确性。
猜你喜欢
艺术家(2022年7期)2022-11-22 09:48:39
考试与评价·八年级版(2020年5期)2020-10-29 05:42:35
青年歌声(2019年7期)2019-07-26 08:35:12
西部论丛(2019年9期)2019-03-20 05:18:04
青年歌声(2018年4期)2018-10-20 07:59:24
西藏文学(2018年1期)2018-03-26 07:16:24
黄河之声(2018年15期)2018-01-27 14:02:32
黄河黄土黄种人(2017年12期)2017-12-23 13:30:03
大众文艺(2017年13期)2017-03-11 11:36:52
民族音乐(2016年3期)2016-06-05 11:33:45
