
面向OAI-PMH协议的西太平洋地区医学索引数据服务设计与实践*
2019-10-17 01:10:00范云满
医学信息学杂志 2019年8期
范云满 方 安 王 蕾
(中国医学科学院医学信息研究所 北京 100020)
1 引言
数字资源的不断增加,数字信息的极大丰富,导致对不同资源与组织形式的元数据统一加工、保存、跨库检索存在困难。在这种背景下,产生了基于开放文献预研(Open Archives Initiative,OAI)的元数据互操作协议(Protocol for Metadata Harvesting)(OAI-PMH协议),这是一种独立于应用、能够提高Web上资源共享范围和能力的互操作协议标准,主要通过指定的命令集合,利用Internet和元数据技术,提供数字资源的元数据信息的互操作。随着加入开放获取(Open Access,OA)的机构不断增多,已经在OAI官方机构登记注册数据提供者从2005年139家[1]发展到2018年12月超过3 680家[2]。
西太平洋地区医学索引(Western Pacific Region Index Medicus,WPRIM)面向西太平洋地区的医学期刊用户,提供收录、索引服务,依托于WHO西太平洋区域办事处与其成员国若干机构合作的项目。同时WPRIM收录索引期刊文献后,需要向全球卫生图书馆(Global Health Library,GHL)提供收录文献的元数据。WPRIM已经为GHL提供两种数据提交的方式,定期按照指定格式批量生成文献XML,通过FTP的方式上传到GHL。WPRIM以应用程序接口(Application Interface,API)的方式提供两个函数,根据期刊名称等信息获取文献ID列表,根据文献ID获取相应的元数据。虽然能根据检索条件为有检索需求的用户提供文献服务,但存在元数据信息不能自解释的问题;同时由于该API服务是一个WPRIM系统定制的服务,不是一个通用的协议标准,存在元数据的语义不能自我表达,导致与其他仓储系统的互操作性不够完全兼容。
本文主要介绍WPRIM系统实现OAI协议的过程中解决自我制定元数据标准、制定数据分组策略、Resumptiontoken的实现机制3个问题,通过OAI协议数据提供者验证注册工具实现WPRIM服务的注册,验证WPRIM系统OAI数据服务工作的完成。
2 背景技术
2.1 OAI协议
OAI协议包含两种角色的参与者,数据提供者(Data Provider)和服务提供者(Service Provider)。数据提供者以OAI-PMH方式发布元数据,服务提供者(用户)以OAI-PMH为基础获取元数据来建立增值服务。本文工作目前实现了前者,即数据提供者的角色。
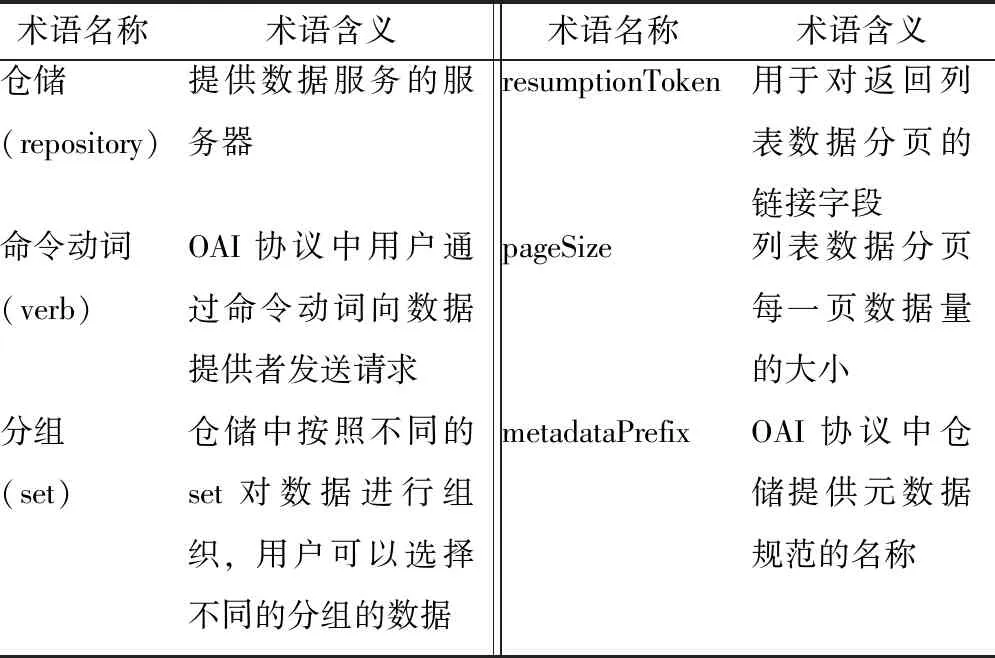
表1 文中用到的OAI协议术语
仓储依靠6个命令动词(verb)对外提供数据服务,见表2。需要特别说明的是ListMetadataFormats列出仓储提供的元数据规范, ListRecords和LisIdentifier都是列出仓储中的数据列表,但是前者列出数据的详细信息(按照某一种元数据规范),后者则只是列出数据的标识。
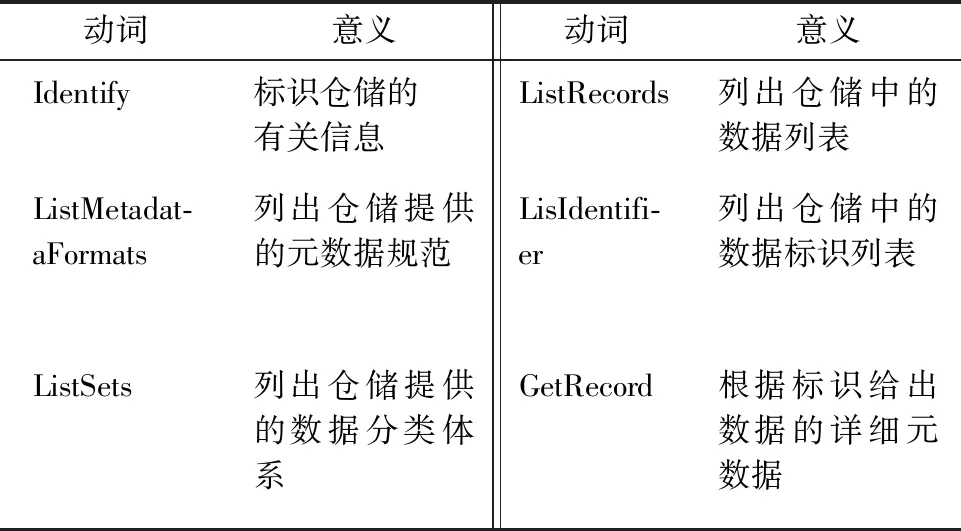
表2 数据服务者提供的6个动词
由于OAI-PMH是一个互操作协议标准,不是可以直接利用的工具,具体应用可以根据协议内容各自实现,例如开放文献预研社区的成员提供了很多的版本。WPRIM系统在实现OAI协议的数据服务时,主要解决自定义元数据规范并且按照自定义的元数据规范列出数据信息,以及实现分页列出数据,其中最为关键的是resumptionToken的实现策略。
2.2 自定义元数据规范
OAI协议中返回一个条目的数据xml,其中第2部分元数据为返回的主体部分,通常仓储选择DC(Dublin Core)的元数据规范描述该主体,但是也可以按照仓储自定义的并且已经发布的元数据规范予以描述。DC元数据规范以15个元素为核心,包括7个资源内容描述类元数据项、4个知识产权描述类元数据项和4个外部属性描述类元数据项。DCMI成立了多个工作组,针对不同领域的需求进行扩展,国内的很多机构也以DC为基础,制定了各自的元数据方案。但是DC元数据仍然存在元数据项受限、已有元数据项缺少能够表达复杂关联关系的能力,另外各个机构制定的元数据方案之间并不能互相通用,缺少互操作机制。
2.3 数据分组策略制定
仓储需要通过分组对内部数据组织才能更好为用户提供服务,因此需要根据WPRIM的数据特点设置分组。
2.4 resumptionToken实现
2.4.1 resumptionToken 如前所述OAI协议通过6个命令动词,由数据提供者向服务提供者提供数据,其中ListIdentifier和ListRecords都有一个独特的参数resumptionToken,用来处理不完整列表。数据提供者由于受到网络带宽、硬件资源等的限制,在提供批量元数据时每次提供的数据列表为固定大小,如100。当服务提供者向数据提供者查询到的列表数量大于100时,数据提供者每次只提供100条数据,该服务提供者继续申请获取后面的数据时,数据提供者再提供后面的100条。由于数据服务者和服务提供者之间没有采取握手机制,即数据服务者并不能记住每次请求是由哪一个服务提供者发出的,更不知道该服务提供者上次提出请求时的查询条件是什么,因此需要在两者之间有一个联系的标识,称为resumptionToken。该标识由数据提供者发出,随数据列表一起发给服务提供者,服务提供者收到该标志的时候,将该标志保存,当需要获取下一批次的数据时,将该标志发给数据提供者。如果服务提供者没有收到该标志,说明收到的数据是查询到的全部数据。
2.4.2 DSpace Hewlett Packard和麻省理工学院于2002年开展的联合开发的一个开源的数字资源管理软件平台,使机构能够捕获和描述数据内容[2]。它可以在各种硬件平台上运行,支持OAI-PMH2.0版。由于DSpace作为世界上很多机构知识库建设的中间件,很多机构知识库也利用其中实现的OAI-PMH功能。DSpace中的resumptionToken的生成机制主要有两个关键点:一是需要每次仓储中的所有数据条目加载到服务器中,二是采用Base64算法对每一次的查询条件及返回的数据加密生成resumptionToken,但是前者在中大型规模的仓储中容易产生内存溢出的问题。
2.4.3 开放源码软件ARC Old Dominion University数字图书馆小组开发的基于OAI的搜索引擎,提供了OAI协议中服务提供者完整的实现,是一个通用的服务提供者平台[3]。ARC的resumptionToken的生成机制相比DSpace有改进,采用URLencoder生成resumptionToken。可取得根据查询条件得到的所有数据。这样可在很大程度上缓解内存溢出的问题,但是当查询条件是查询所有数据时仍然容易导致内存溢出。
2.4.4 Archimede 拉瓦尔大学图书馆开发的一个用于机构知识库的开源软件,具有全文搜索、Web用户界面等功能,完全支持OAI-PMH协议2.0版[4]。Archimede的resumptionToken生成机制进一步优化:根据查询条件查询(0-pagesize+1),pageSize为每次分页数据量的大小。同样,Archimede采用URLencoder生成resumptionToken,利用urldecoder对resumptionToken解密。利用该方法已经解决了内存溢出的问题,但是pageSize的选择需要根据经验加以设定,不能依据数据提供者、数据收割者两者之间互通的带宽动态设定。
3 WPRIM系统OAI协议实现
3.1 WPRIM元数据规范
为了能够满足WPRIM系统完整描述自身的元数据,让数据服务提供者理解WPRIM的元数据项,WPRIM系统借鉴了DC元数据[5]、PUBMED[6]、Web of Science的元数据方案[7],发布了自身的元数据方案,命名空间是http://wprim.whocc.org.cn/WPRIM_2,所有的元数据项(Term)在该空间下定义。图1是WPRIM制定元数据规范的主要片段,略去了Title,Abstact等简单的元数据项。本元数据规范包含的Journal、AuthorList、KeywordList和Meshlist都是组合元数据,是DC元数据规范无法表达的。

图1 WPRIM元数据规范主要片段
3.2 WPRIM分组策略
WPRIM系统中收录的论文都是期刊论文,其元数据都是期刊论文元数据,同时WPRIM需要定期按月向GHL提供元数据。基于以上考虑采用两种分组策略:第1种按照期刊名称、ISSN分组,用户可以按照期刊名称、ISSN获得对应的论文;第2种按照更新时间分组,将数据的更新时间划分到每个月,用户可以按照每个月取得该月的更新数据(包含新收录的数据)。随着下一步的工作继续开展,考虑加入更多的分组类别。
3.3 WPRIM系统resumptionToken的生成算法
WPRIM以DSpace中的OAI协议模块为基础实现数据提供者的功能,其生成逻辑如下所述:第1次根据请求条件查询(0-pageSize+1)条数据,判断得到的数据集大小是否大于pageSize,如果大于pageSize返回值中包含resumptionToken,否则不包含。同时利用算法侦测数据收割者的网络带宽动态决定pageSize的大小,具体的生成机制,见图2。本生成机制基于一个假设,数据收割者访问WPRIM的OAI仓储时,第1次先发出Identify请求,而ListRecords请求因为需要指定数据分组、metadataPrefix等条件,因此不会在第1次请求时就发出。探测网络带宽的算法如下:记录下用户Identify请求时的来源IP。在向该用户返回结果XML数据时,记录下该响应所需要的时间。用户的网络带宽反比于响应时间,时间越长,则带宽越小,反之越大。通过大量的实验制定网络带宽基数,以及对应响应时间的网络带宽阶梯差值。当接收到该用户的ListRecords请求时,通过用户的IP和网络带宽的关联关系查到对应的带宽,进而决定pageSize的大小,从而实现用户的带宽不同,其批量返回数据集大小的不同。
3.4 WPRIM系统OAI协议的验证
OAI官方组织提供了一个能够提供数据服务的仓储注册的功能,目前已经登记注册3860个。注册时需要经过两个步骤的验证,第1步为验证Identify响应,检验其是否满足OAI-PMH2.0版本的协议要求。第2步的验证包括6个动词请求分别验证、错误请求的处理、OAI 2.0特有异常的处理、POST请求的处理以及resumptionToken能够正常使用的验证。验证成功后的WPRIM系统的数据服务者链接已经出现在官方列表中[4]。
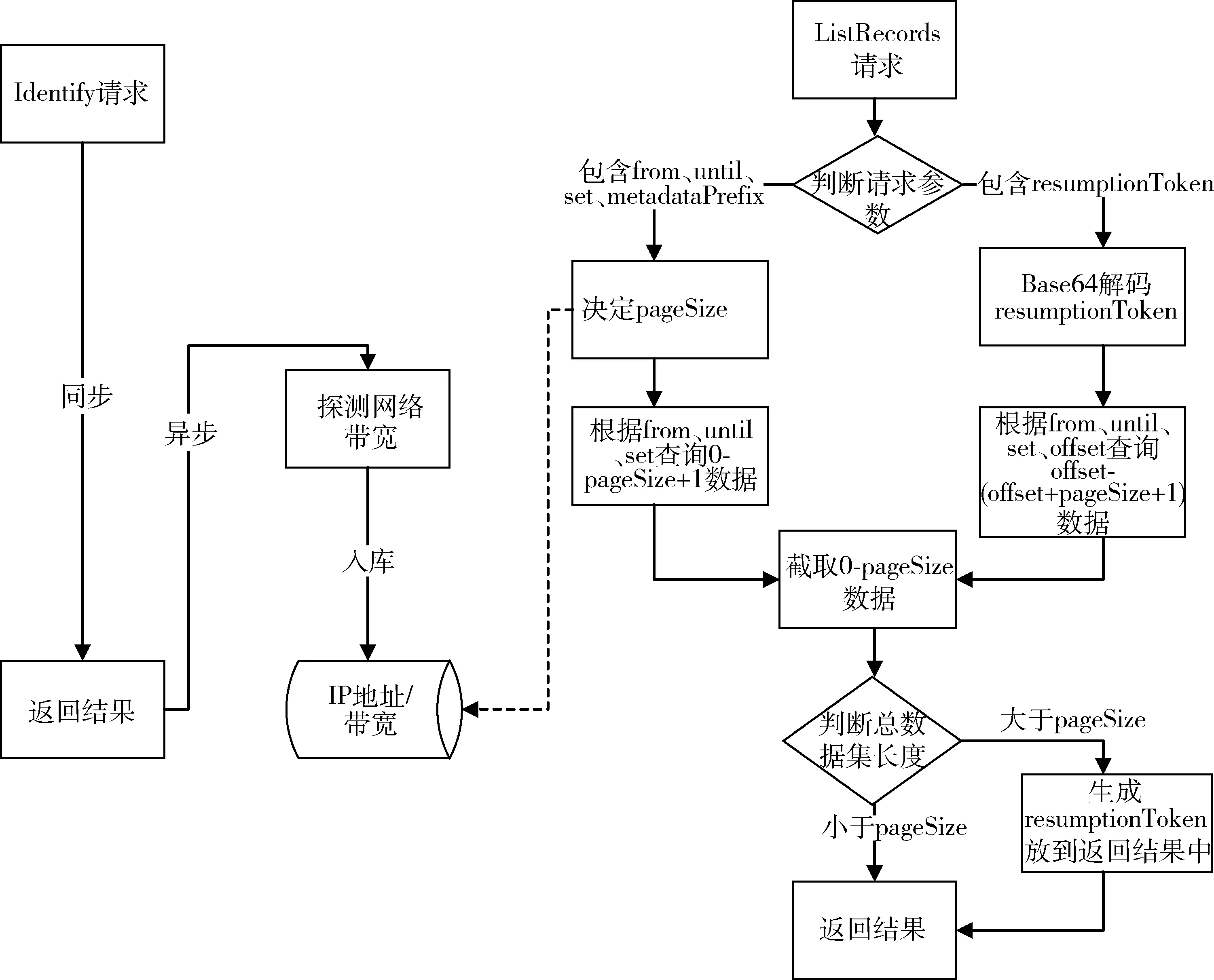
图2 WPRIM系统resumptionToken生成机制
4 结语
WPRIM收录、索引西太平洋地区的医学期刊,对用户提供检索服务,同时为了提高WPRIM与其他的期刊仓储的互操作性,除了在原有已经具有的API接口的基础上,需要加入对OAI-PMH协议的支持。本文介绍WPRIM在实现OAI-PMH协议时面临的3个问题提供的解决策略:(1)制定WRIM元数据规范。利用该元数据规范实现WPRIM的元数据能够被其他的数据仓储理解、支持。(2)制定WPIRM数据的分组策略。根据WPRIM的数据特点以及WPIRM需要向GHL定期提交数据的要求,采用期刊名称、ISSN和数据更新年月作为分组的策略,实现了对数据的有效组织,同时能够实现数据对GHL数据定期同步更新。(3)resumptionToken生成策略的制定。WPRIM在分析其他知名系统实现策略的基础上,提出了一种基于网络带宽自适应的高效生成策略。通过解决上述问题,WPRIM系统实现了对收录数据的索引并提供数据服务,也已通过OAI组织网站上的验证注册服务,证明本文的实现策略是可行的。下一步的工作拟在通过为其他的仓储提供数据服务的基础上,优化WPRIM的OAI-PMH协议的服务。
