
基于LSTM的地铁站流量预测模型
2019-10-14 03:46
福建质量管理 2019年18期
(沈阳理工大学 辽宁 沈阳 110000)
地铁在城市的交通系统中具有相当重要的地位。若能够准确预测地铁站的流量,可以作为地铁的安保决策的依据,确保社会的和谐稳定,能够为我国的地铁流量预测提供参考。
一、基于LSTM的模型设计
(一)问题分析
地铁是人们日常的重要交通方式,其出入流量受到人们日常出行习惯的影响,具有规律性,适合使用LSTM来根据前几天的流量情况来预测当天的人流量。考虑到人们每个时间段的出行习惯不同,每个地铁站的地理位置不同,应当针对不同地铁站、不同时间段训练模型、预测流量。
LSTM(Long Short-Term Memory),为传统RNN的变形,是一种时间循环神经网络,适合预测具有教程时间序列的事件。
(二)模型结构
模型(模型图如图1所示)的输入为长度为20的数组(即之前20天的流量数据),模型的顶层为节点数为6的LSTM层,第二层为节点数为12的LSTM层。使用多层LSTM,将LSTM层进行累加,是为了能够得到更高更抽象的特征,并能够一定程度上增加模型训练的准确率并减少训练时间。模型的第三层为全连接层,节点数为1,它作为网络的输出,输出的是一个浮点数,是预测当天的流量的归一化后的结果。
其中第一层的节点数目使用了常用经验公式[1]:
(1)
式中:l表示LSTM的节点数,n表示输入数据的长度,m表示输出层的节点数(输出数据的长度)。
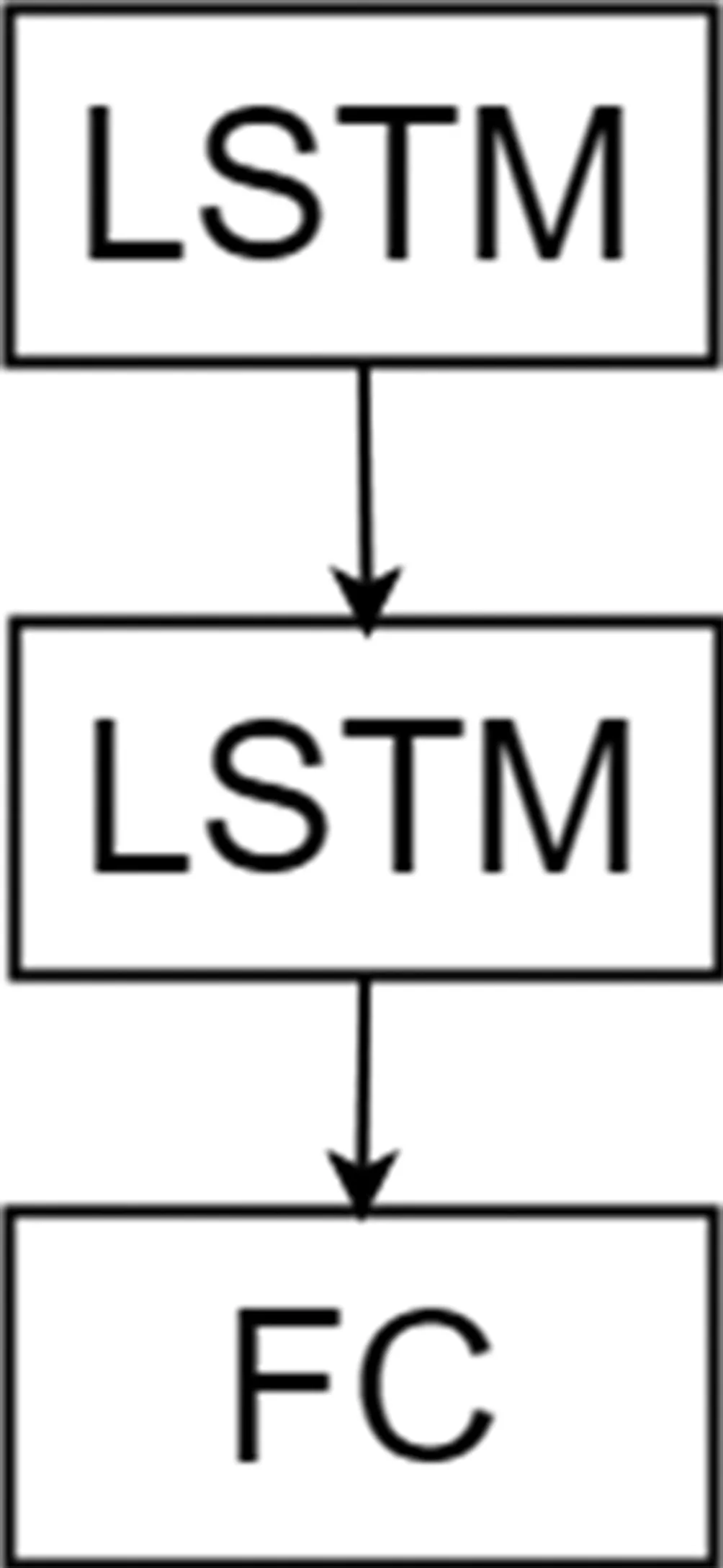
图1模型结构
当训练该模型时,使用了均方误差损失函数(mean squared error),其公式为:
(2)
二、实验数据及结果
(一)实验平台
使用Python语言利用Keras深度学习框架实现了本实验,并使用了因特尔i7-7700处理器、NVIDIA GTX 1050显卡,于Windows10操作系统上进行训练、并验证模型。
(二)实验数据及数据预处理
实验数据来源于纽约市从2017-04 至2018-01 近九个月的地铁旋转门数据,数据中包含了时间、监控器编号、车站名称、出入站人流量等信息。本实验为预测某个地铁站某个时间段的流量,因此需要从源数据中提取流量信息。考虑到数据量较大,数据的字段较复杂并需要数据之间的合并计算,需要使用能够完成复杂操作大数据量的工具完成这行工作。
Spark是基于分布式的计算框架,适合处理大数据量的作业,本实验使用了Spark SQL对原数据处理,提取出了每个地铁站每个时间段的流量信息,并将其保存至文件供模型训练和测试。
在模型的输入和输出中,为了加快梯度下降的速度、提高精读以及网络中最后一层也只能输入0-1的小数,需要对所输入的数据进行归一化,以及对预测出的数据进行反归一化以加以利用。本实验使用了线性归一化(也称最大最小归一化),公式如下:
(3)
(三)评价指标
为了分析预测的效果,设定了MAE(绝对平均误差)作为评价指标[2],用以评价模型的优劣。其中N为预测天数。
(4)
(四)实验结果及结论
如图2所示,为训练模型中某一地点11点至15点的预测值、实际值对比图(红色线条的高度为预测值,黑色线条的高度为实际值,纵轴为流量值,横轴为测试的样本批次)。从对比图中可以明显看出,预测值大体符合流量变化趋势,能够相对有效地预测出人流量趋势,能够达到流量预警,是一种有效的人流量预测模型。
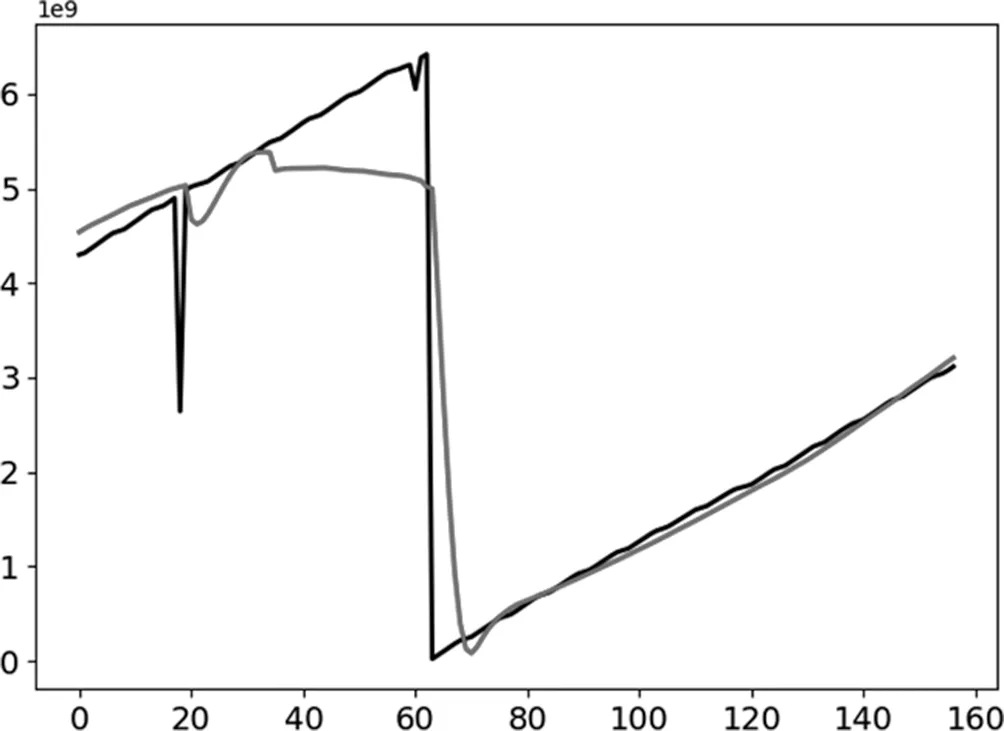
图2 预测值与实际值对比
(五)不足之处
本模型存在当人流量骤变时所预测的趋势有滞后性以及无法预测出一些极端流量情况等问题,本模型仍有继续改进的空间。另外,本模型是针对某一地铁站、某一个时间段的人流量进行预测,当有众多地点以及时间段较多时,需要相当多的模型进行预测,虽然模型的结构没有变化,但是训练的计算量较大,需要使用较长的训练时间。
猜你喜欢
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
今日农业(2020年13期)2020-08-24
科学与信息化(2020年18期)2020-08-03
文理导航(2018年9期)2018-08-16
现代经济信息(2016年34期)2017-08-12
意林(2017年8期)2017-05-02
医学研究杂志(2015年5期)2015-06-10
中国药业(2014年21期)2014-05-26
