
电商语言文本数据处理方法研究
2019-10-11 04:02张丽周东
科技视界 2019年22期
张丽 周东

【摘 要】近年来,随着我国电子商务领域的高速发展,有关商品描述、商品评价等电商语言文本信息也随之大量产生。如何对海量的电商语言文本数据进行高效地处理成为行业一个亟待解决的问题。针对这一问题,本文利用机器学习和统计学的相关原理,将Redis缓存处理方法与数据库处理方法相结合,提出一种针对电商语言文本数据的机器学习分页数据处理方法,以提高对电商海量语言文本数据的处理效率。
【关键词】电子商务;语言文本;数据处理
中图分类号: TP391.1;F724.6 文献标识码: A 文章编号: 2095-2457(2019)22-0074-002
DOI:10.19694/j.cnki.issn2095-2457.2019.22.032
0 引言
2018年5月28日,习近平主席在中国科学院第十九次院士大会、中国工程院第十四次院士大会上指出“进入21世纪以来,全球科技创新进入空前密集活跃的时期,新一轮科技革命和产业变革正在重构全球创新版图、重塑全球经济结构”。随着我国社会科技的进步,创新型经济越来成为未来社会的大趋势。近十年来,以互联网为媒介的电子商务作为一种创新型的商业运营模式得到了飞速的发展,出现了淘宝、京东、拼多多、苏宁易购、美团等巨头电商企业。网上购物、网上贸易等商业活动日渐成为人们生活中不可分割的一部分,随之而来是海量的商品信息从线下转移到线上,有关商品描述、商品评价等电商语言文本信息也随之大量产生,如何对海量电商语言文本数据进行高效处理成为行业所面临的一个较大的挑战。近年来,相关的论文(如赵春雷等 2012;曾超宇等 2013;程学旗等 2014;徐国虎等2013;张素智等 2015)、书籍(如付磊等 2017;于君泽等 2018)、专利(如廖耀华等 2018)等成果为大数据处理、缓存处理以及电商数据处理等提供了有价值的参考。
1 电商语言文本的处理
一般情况下,电商网站需要将每一件商品包括商品的标题、编号、价格、颜色、版本、功能、所属类目以及用户对该商品的评价等语言文本信息展示给消费者查看,而这些商品信息则以数据的形式存储在网站的后台系统。在电商文本信息展示的过程中,因为量大,给高性能分页展示带来较大挑战,所以要对这些数据进行处理。譬如,电商网站中的某个类目有20000个商品需要在网站的前台进行展示,一页展示20条商品信息,那么20000条信息需要分1000页展示,当用户点击某一页时,后台将对应的该页数据返回到前台并展示,这一过程行业通常定义为数据同步,用于对语言文本这种数据进行处理。现有的数据同步主要有以下三种方法:
a)数据库直接同步法
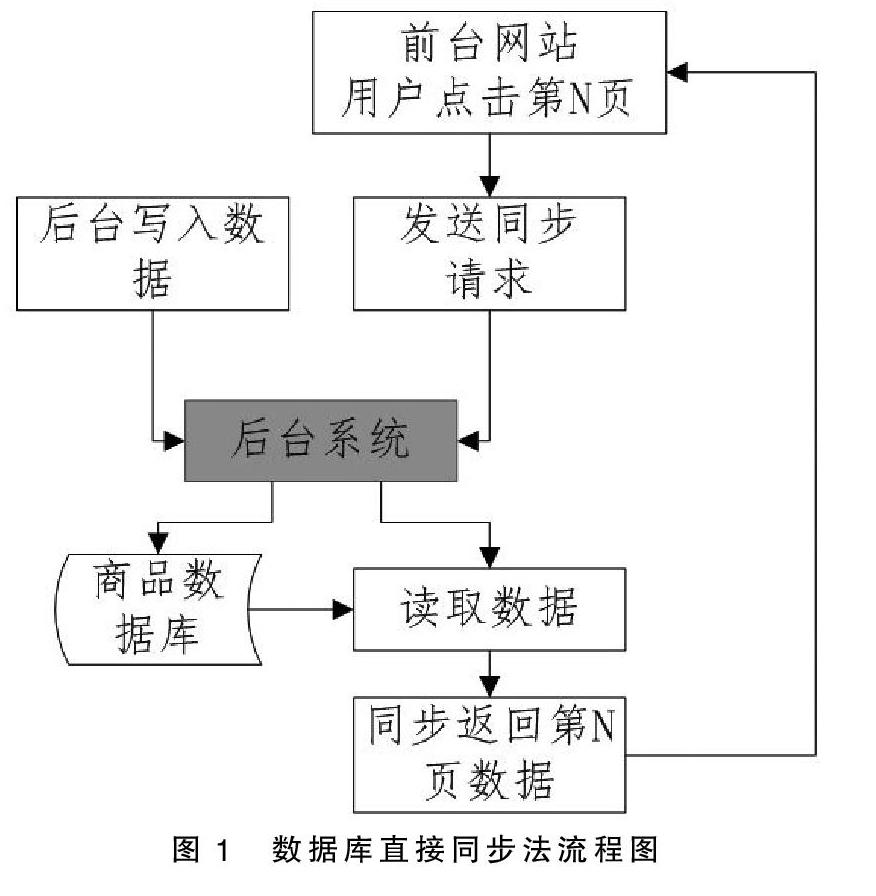
用户在点击某一页数据的时候,发送请求后台,后台根据页号和每页展示的数量等参数直接从数据库里面把商品数据提取传到前台并展示。后台运营人员新增的数据也会直接同步到数据库。该方法的具体运作流程如图1所示。
但是因为网站前台用户在分页访问请求时,直接访问数据库,没有缓存的参与,所以该方法存在以下缺陷:
第一,性能较差。每次分页都要查询一次数据库才能拿到数据,相比读取缓存方式,其速度慢且效率低,如果并发访问量大,数据库则难以支撑。
第二,安全性较差。请求返回的数据从数据库直接获取,如果有恶意用户发恶意请求进行攻击,则会导致数据库瘫痪。
b)缓存直接同步法
该方法主要是以memcache或者redis为载体的缓存同步法。其主要运作流程如图2所示。
缓存直接同步法将数据库数据全部同步到缓存,用户在发送分页请求的时候,全部从缓存里面提取数据,不和数据库有任何交互,相比第一种方法,其速度较快,性能较好,并且因为前端数据分页请求不和数据库交互,安全性也得到了提升,但是该方法对缓存容量要求较高。如果需要分页的数据量很大,同时一条数据包含的字段信息较多,就对缓存容量有很高的要求。如果使用大容量缓存,在成本上是较为昂贵的。
c)緩存与数据库结合同步法
该方法主要将缓存方式与数据库方式结合起来进行同步。当有用户访问某个分页的时候,如果缓存里面不存在该分页的内容,就将该页面的数据从数据库同步到缓存,并同时同步到前台,如果存在就不访问数据库,直接从缓存里面取。该方法的运作流程如图3所示。
该方法是基于单纯数据库同步与单纯缓存同步的基础之上的一种同步方法,相比第一种方法,因为引入了缓存机制,性能和安全都有所提升。相比第二种方法,该方法一定程度上节省了缓存的容量。在数据量很大、分页数非常多时,对于没有点击到的分页,无需载入缓存。但是某些仅仅被用户点击几次的中间页面也要在第一次分页请求后加入缓存,而对于之后其他请求量更大的分页,缓存容量不足以支持时,就只能从数据库中直接同步。这样一来就会导致访问量很小的分页页面数据占用缓存空间,造成了缓存资源的浪费,而访问量大的则无法利用缓存,使得数据同步性能下降,缓存与数据库利用不平衡。
2 基于机器学习的分页数据Redis同步法
在综合分析了现有数据同步三种方法的优点和缺点基础上,我们利用机器学习和统计学的相关原理,将Redis缓存处理方法与数据库处理方法相结合,提出一种针对电商语言文本数据的机器学习分页数据处理方法,目的是提高语言文本数据的处理效率。该方法,一方面是基于数据库与缓存同步相结合方法之上,该方式确保了数据同步的性能、安全性及容量利用率的提升;另一方面,引入了根据用户的行为统计数据的机器学习方法,解决了原缓存同步与数据库同步相结合方法在海量数据处理时缓存容量不足、缓存资源浪费以及缓存与数据库利用不平衡从而导致同步性能下降的缺陷。
在用户发生页面分页请求的时候,引入一个页面统计计数器,数据同步行为会依赖这个记数器,该记数器周期固定地记录每个页面所有用户的请求累加次数n,并设定一个记数的阈值常量THRESHOLD,这个n >=THRESHOLD时就触发数据库中该页对应的数据同步到Redis,用户再次请求该页数据的时候就从Redis获取。当在固定周期时间内统计该页请求阈值n< THRESHOLD时,则将该页的缓存数据删除并释放空间,数据请求同步再次改为从数据库中获取,避免了在该页访问用户量很少的情况下还要将该页数据从数据库中同步到Redis,这样不仅减少了数据量过大时Redis空间的压力,同时,节省昂贵的Redis资源,并将数据库与Redis的使用进行了合理均衡的分配,进一步提高了同步的性能。详细方案步骤如下:
猜你喜欢
心理学报(2022年4期)2022-04-12
今日农业(2021年21期)2022-01-12
水泵技术(2021年3期)2021-08-14
知识经济·中国直销(2018年10期)2018-11-06
池州学院学报(2017年5期)2018-01-23
公民与法治(2016年12期)2016-05-17
当代化工研究(2016年9期)2016-03-20
中国科技信息(2015年17期)2015-11-02
西华师范大学学报(自然科学版)(2015年3期)2015-02-27
中国期刊年鉴(2015年0期)2015-01-19
