
医院网站日志挖掘数据预处理的研究
2019-09-19 07:41:28李立峰翟玉兰
重庆理工大学学报(自然科学) 2019年8期
蒙 华,苏 静,李立峰,翟玉兰
( 广西医科大学 a.第一附属医院 计算机管理中心;b.信息与管理学院 教研科, 南宁 530021)
医院网站日志挖掘研究即利用数据挖掘技术分析用户访问模式等信息,从网站日志中发现并抽取有效信息,挖掘访客感兴趣的潜在有用信息。医院网站的用户访问模式较为复杂,具有时间分布的随机性、不均匀性,用户浏览器及其版本的不确定性以及使用网络代理多样性等特点[3-4]。数据挖掘对象范围是数据库中的结构化数据,针对医院网站访问用户无结构或者半结构化的行为数据进行挖掘分析的难度较大,分析效果不理想,无法有效接近用户行为。针对以上存在的问题,需对Web日志数据进行预处理,将原始Web日志数据中错误、缺漏、干扰的信息转换成相对完整和准确的用户访问事务数据库,以适应新挖掘应用需求[5-7]。数据预处理操作主要是通过清洗原始数据和用户识别、进行会话处理、标准化页面和建立用户相似度矩阵等操作,获取反映用户浏览行为的有效数据并转换成后续挖掘算法可识别的格式,以此提高挖掘质量[8-10]。
本文对用户访问广西某大型综合性医院官网的日志数据进行预处理,旨在从繁杂数据源中抽象出适合数据挖掘算法所需模式,提高预处理结果矩阵的有效信息含量。
1 数据预处理流程
Web日志记录数据挖掘模型的算法流程如图1所示,分成2个步骤:① 日志记录数据的预处理操作,包括过滤日志数据、识别用户、识别会话数据及路径补充,确保日志数据应用于数据挖掘模型的有效性。② 页面聚类处理得到日志数据。
1.1 日志数据预处理
Web日志数据预处理包括清洗、过滤日志数据,识别用户,识别会话,数据标准化。其中数据预处理是基础,决定后期数据挖掘的质量。数据挖掘流程见图1。

图1 数据挖掘流程
1) 清洗数据及过滤
清洗数据是在数据的多种属性中抽取对挖掘目标影响较大的属性,从而降低数据维数,提高日志数据中信息有效率。日志源数据表共有14项属性,根据挖掘需求,清洗相关系数较小的属性,保留用户访问时间、方式、IP地址、请求页面、浏览器类型及用户计算机操作系统共6个属性。
过滤日志数据访问页面痕迹中包含的图片、图像、视频、音频以及服务器对用户请求响应失败的信息等,这些数据对后续分析无影响[5]。
[10]Selected Works of Jawaharlal Nehru, Second Series, Vol.11, New Delhi: Oxford University Press, 1991, p.372.
2) 用户识别原则
对日志中访问的用户,根据用户IP、浏览器及其版本、操作系统等对用户进行划分。当 IP地址一致时,若客户机操作系统或使用浏览器类型、版本不同,则视为不同用户[3,11-12]。
3) 会话识别
识别用户的访问行为,并划分每个访问用户浏览的页面序列到相应的会话事务,即进行事务识别。根据文献[6,13],25.5 min为最佳用户会话中止的界定时间,此即为时间戳[14]。
4)会话补充
① 客户端浏览器Cache存储近期浏览的文件,包括某些点击率很高的网页点击信息。本文根据Web日志和Web站点结构中链接信息填补会话空缺。
② 若在浏览站点设置中,当前浏览网页与用户前一次请求的网页之间无链接路径,则用户可能使用浏览器返回键,调取客户机的缓存页面,获得一个完整的用户访问路径。但实际情况中该方法很难获取客户机的缓存信息进行会话补充[8-9]。
5) 结构化、标准化
网站日志经过清洗等处理操作后,需转换为符合数据挖掘算法的输入格式,并保存到关系型数据库表或数据仓库中,即将数据标准化或结构化。本文选择页面序列作为指标进行聚类。
1.2 页面聚类
后期聚类分析结果准确程度受Web页面相似度分析的影响,相似度分析也是归类不同页面群体的重要依据。选取页面序列作为相似性度量指标[6],从预处理结果数据中统计用户对各页面的访问次数。
根据式(1)计算页面Pi和用户clientj之间的关联度矩阵L。
(1)

根据页面和用户的关联度矩阵计算出页面之间的相似度矩阵R,如式(2)所示[14],R即为日志数据标准化后的结果。
(2)
计算后得到Web日志数据标准化后的结果矩阵R(详见实验结果)。R凝聚了用户和访问页面之间联系的信息量,运用聚类分析、神经网络等算法对R聚类,得出页面聚类模式等以利于对医院网站结构的分析优化。
2 医院日志挖掘预处理实验
2.1 实验数据
本文数据来源于广西某大型综合性三级甲等医院网站2011年10月31日日志.txt文件,总大小为31.2 M。日志文件是非结构化的文本文件,记载用户访问该医院网站的记录总计152 500多条,见图2。

图2 医院网站日志片段
2.2 实验结果分析
利用SQL2000数据库技术删除音频等数据,得到32 500多条医院网站访问记录,清除率为80%。网页唯一性编码共计1 850多个,即为经过数据过滤后该日用户浏览的所有界面集合。对这些记录进行会话识别和补充,得到2 800多个不同会话,见表1。其中:time表示当日时间;no表示该用户访问医院网页对应的编码;ping表示融合IP地址、浏览器和操作系统等内容的字段;work表示区分会话字段。若ping相同,用户会话会分割记录点,两者time字段相差≥25.5 min,即分为两个会话记录。
表1 网站日志文件会话集片段
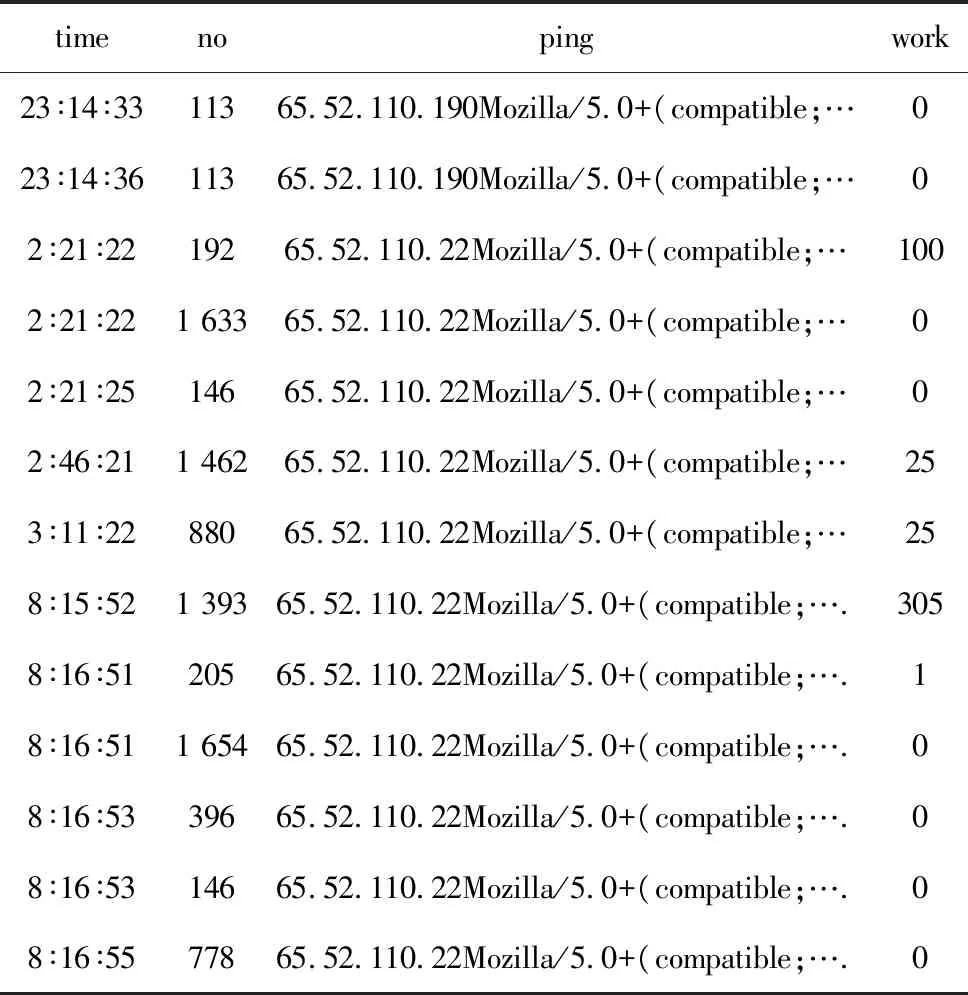
timenopingwork23∶14∶3311365.52.110.190Mozilla/5.0+(compatible;…023∶14∶3611365.52.110.190Mozilla/5.0+(compatible;…02∶21∶2219265.52.110.22Mozilla/5.0+(compatible;…1002∶21∶221 63365.52.110.22Mozilla/5.0+(compatible;…02∶21∶2514665.52.110.22Mozilla/5.0+(compatible;…02∶46∶211 46265.52.110.22Mozilla/5.0+(compatible;…253∶11∶2288065.52.110.22Mozilla/5.0+(compatible;…258∶15∶521 39365.52.110.22Mozilla/5.0+(compatible;….3058∶16∶5120565.52.110.22Mozilla/5.0+(compatible;….18∶16∶511 65465.52.110.22Mozilla/5.0+(compatible;….08∶16∶5339665.52.110.22Mozilla/5.0+(compatible;….08∶16∶5314665.52.110.22Mozilla/5.0+(compatible;….08∶16∶5577865.52.110.22Mozilla/5.0+(compatible;….0
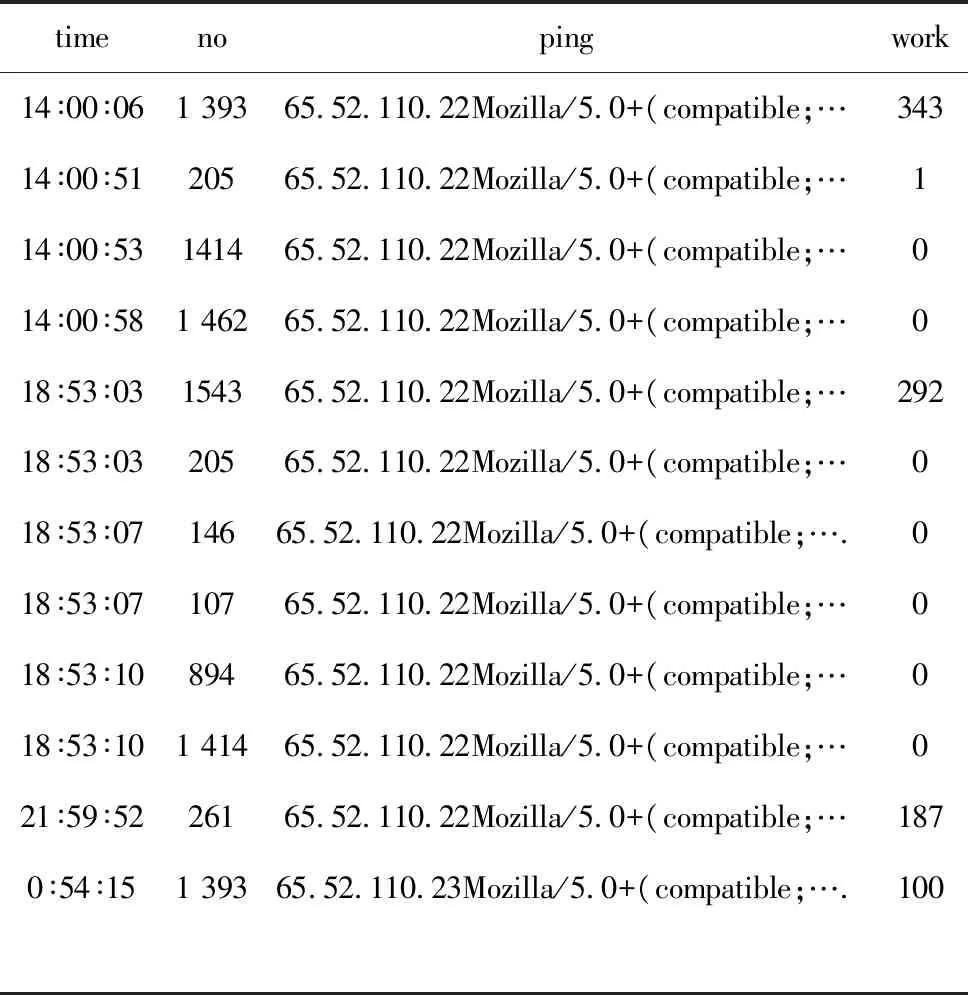
timenopingwork14∶00∶061 39365.52.110.22Mozilla/5.0+(compatible;…34314∶00∶5120565.52.110.22Mozilla/5.0+(compatible;…114∶00∶53141465.52.110.22Mozilla/5.0+(compatible;…014∶00∶581 46265.52.110.22Mozilla/5.0+(compatible;…018∶53∶03154365.52.110.22Mozilla/5.0+(compatible;…29218∶53∶0320565.52.110.22Mozilla/5.0+(compatible;…018∶53∶0714665.52.110.22Mozilla/5.0+(compatible;….018∶53∶0710765.52.110.22Mozilla/5.0+(compatible;…018∶53∶1089465.52.110.22Mozilla/5.0+(compatible;…018∶53∶101 41465.52.110.22Mozilla/5.0+(compatible;…021∶59∶5226165.52.110.22Mozilla/5.0+(compatible;…1870∶54∶151 39365.52.110.23Mozilla/5.0+(compatible;….100
最后,经过页面聚类分析,得出页面聚类矩阵R,即信息含量较大、较可靠的相似度矩阵。矩阵R大小为2 363×2 363,反映了页面和用户的关联程度。图3所示为R矩阵的片段A,大小为11×11。
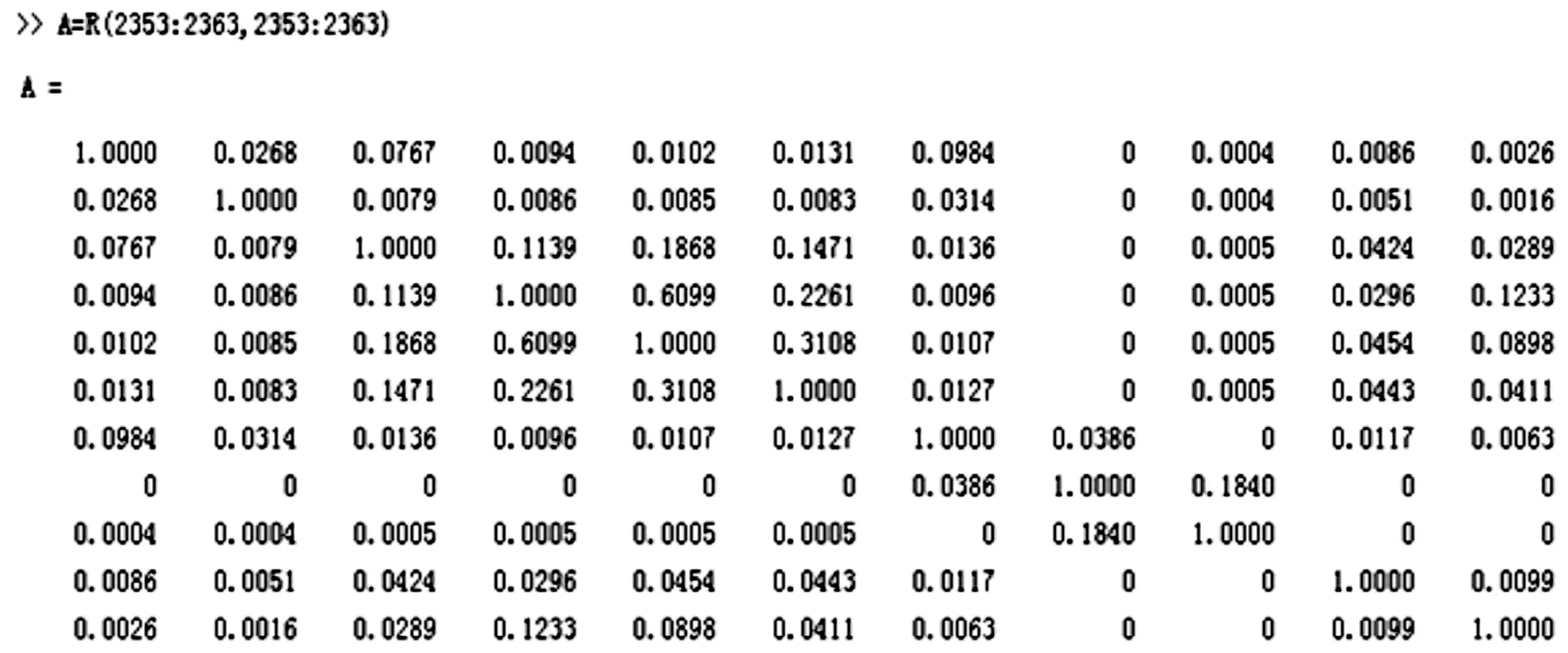
图3 页面聚类输出矩阵片段
实验基于预处理原理及流程,采用win7操作系统、SQL2000、Matlab7.1实现网站日预处理过程。将存在缺失、错误、噪音的原始数据转化为信息含量较大,较可靠、完整的相似度矩阵R,直接用于网站日志挖掘分析。
收集医院官网一段时间内的网站日志数据,通过预处理,提取主要特征量,降低聚类分析数据维度和复杂性,组成更庞大的相识度矩阵R群。R群可作为进一步深入聚类分析的径向基神经网络(radial basis function,RBF)输入向量群。RBF网络一般由输入层、隐层和输出层组成,其非线性映射能力和逼近性能较强[15]。隐层一般采用高斯型函数,第i个隐层节点输出为
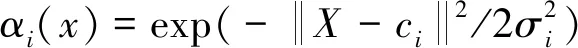
i=1,2,…,m
(3)
式(3)中:m为隐层神经元个数;X为多维输入向量即相似度R矩阵集;ci第i个隐层节点高斯核函数中心;σi第i个隐层节点基宽度。结合遗传算法优化RBF神经网络的权值ci、阈值σi及隐层神经元i,降低RBF聚类算法对初始数据中心的依赖,可使聚类结果更准确[16-17]。通过遗传算法优化RBF神经网络的聚类算法,分析网站访问用户的浏览行为、频繁度、主题、归类兴趣、目标相同的用户行为及相似用户组频繁访问的页面组,能持续优化网站目录结构、推荐特色、针对性的网站[18-22],进而提高医疗结构的服务满意度。
3 结束语
数据挖掘是近年来研究的热点,但针对医院日志挖掘分析较少。日志文件的预处理工作着重考虑在提高信息含量时适合挖掘算法输入的模式。但在完善用户浏览路径和会话识别对常态时间域的依赖上仍有不足,无法有效地将日志和站点拓扑结构结合起来,这也是今后的研究工作。进一步需要深入分析空间数据挖掘聚类算法在医院网站日志中的应用以及网站日志大数据在监测异常行为预警中的应用。
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
华人时刊(2021年13期)2021-11-27 09:19:02
大众投资指南(2021年35期)2021-02-16 01:06:26
心声歌刊(2020年4期)2020-09-07 06:37:14
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
电子设计工程(2014年19期)2014-02-27 12:00:42
电子设计工程(2014年18期)2014-02-27 12:00:13
电脑爱好者(2011年11期)2011-06-22 08:20:18
