
电网信息化业务运行监控存在的问题及对策
2019-09-17 08:28周英耀张华兵
电子技术与软件工程 2019年16期
文/周英耀 张华兵
近年来,电网企业在“集团化运作、一体化管理”战略要求下,不断深入和扩展信息化建设,系统及网络设备规模不断扩大,多种应用软件,如数据库、中间件等不断增加,业务系统的数量也越来越多。如今,全网统一的企业级系统全面投运,基本实现管理制度化、制度流程化、流程表单化、表单信息化以及各业务之间的横向协同、纵向贯通。
但是电网企业在信息系统应用性业务运行监控方面的技术手段相对薄弱,无法深入到业务应用内部,难以监控业务流程的每个步骤,从而阻碍了故障的快速定位、诊断和优化,IT运维人员不能精准到感知最终用户的体验,不能实时掌握业务运行状态。
为了使IT运维人员需要快速、准确定位系统性能瓶颈(硬件层面、软件层面),缩短故障恢复时间,确保业务不间断。同时对于应用开发人员也需要追溯业务功能及性能数据库,合理评估系统健康状态,量化IT运维部门工作,本文深入对业务运行监控进行分析和实践。
1 业务运行监控现在存在的问题
1.1 缺少对业务管理系统业务运行层面的监控分析手段及指标
目前的运维工具没有针对业务管理系统业务运行进行专业的监控和分析,业务运行情况的监控和分析处于空白状态。由于缺少全过程的业务运行监控,故障事后分析诊断条件不足,缺少故障现场溯源数据及相应技术规范及指标,大多情况下只能对设备日志、交易日志等进行分析,很难拿出有力的证据进行取证,另外即使有故障现场数据,问题分析人员面对海量的数据问题分析定位仍需要消耗较长的时间。
1.2 缺少对用户业务操作的真实体验的监控
对于用户业务操作的真实体验缺少系统的监控和数据支撑。公司现阶段的信息化建设,投入了很大精力在IT系统的建设和对IT基础架构的维护上,但即使部署了最先进的基础架构,并不间断地监控PC、网络、服务器、数据库等的性能,用户还是会抱怨系统运行缓慢,不能及时发现哪个业务操作响应慢,IT运维人员也很难向用户解析清楚问题原因在哪。
1.3 处于被动运维
公司应用系统结构复杂,各功能模块分布在相对独立的子系统,通过多个子系统再组合成多环节、长交易链条的完整的应用,很容易出现某个环节与其他环节的处理能力不匹配导致性能瓶颈,此类业务应用的性能问题经常发生且难于发现和定位。
因此,目前多数IT运维处于“被动式”管理,运维人员并非是应用系统的使用者,经常是接到投诉电话之后才知道系统出现了问题,再去寻找问题根源,管理十分被动。
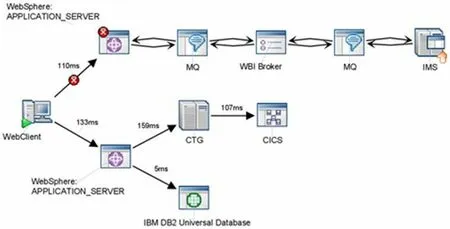
图1
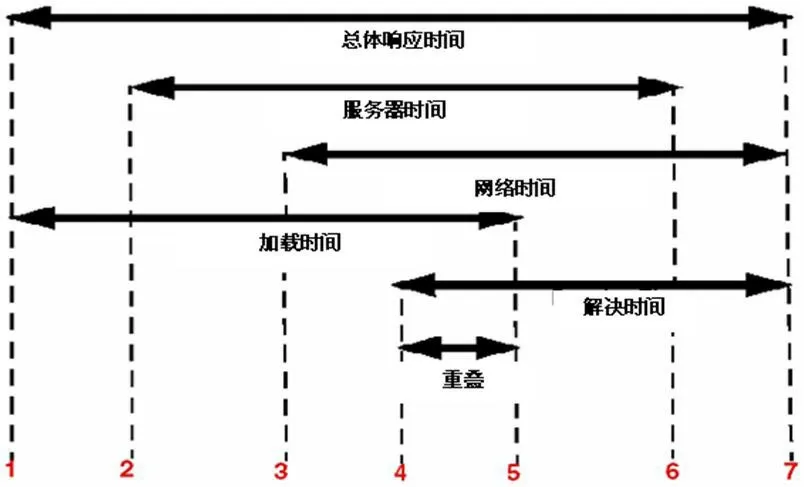
图2
1.4 IT环境复杂,定位问题困难
现阶段公司IT环境日趋复杂,每个企业级应用系统都部署在庞杂的基础架构上,并且与多个外部系统对接。当问题出现时,发现问题很困难,更谈不上快速定位、解决问题。
监控不全面,缺少故障现场溯源数据,事后分析诊断条件不足,难以做到全面诊断且效率低,网络尤其被动,常常面对指责难以举证。
2 业务运行监控解决方案
2.1 问题分析
当前的电网企业业务,从物理上,涵盖多个系统多台物理服务器的应用;逻辑上,包含多个应用逻辑部件的应用系统——不论从业务逻辑还是数据传输,应用都跨越多个资源环境,然后才组合成业务系统。
大多数复合应用为前端用户提供复杂的业务系统(B/S架构的Web应用),应用中的通用部件又可能被不同应用系统以各种形态相互互连或重用,单个用户请求可能贯穿甚至多次贯穿系统,业务请求对应的返回数据可能来源于多个子系统。
前端的应用界面隐蔽了应用后端的这种复杂构架,但是不论后端的子系统发生何种异常——不论来自业务请求的异常、系统资源的异常还是应用内部逻辑和代码的异常——用户都无法完整发出的交互请求。
正是由于复合应用系统的“复合”特性(业务逻辑和数据传输跨越多个资源环境),从优化其性能和可用性角度来看,它难以设计、难以构架、难以测试、难以管理;传统分立的块状系统管理工具和方法论也很难很好的对它进行管理和优化。
2.2 解决思路
为此我们提出如下的解决思路:
2.2.1 模拟用户交互监控
(1)完全站在用户的角度;
(2)监控交互的可用性, 交互的总体相应时间, 交互在各个资源上的相应时间;
(3)定时,定量监控IT系统对业务服务的支持水平与服务质量。
2.2.2 通过“解剖”交互,查找,定位故障根源,为资源级故障诊断指明方向
(1)对用户交互进行解剖,直到最基本的部件;
(2)对发生问题时记录的上下文信息从应用开发角度进行分析。
2.3 解决方案
基于这样的思路,电网企业提出包含以下3点的解决方案。
(1)采用对J2EE的应用程序进行实时监控和历史数据分析,发现并且报告J2EE应用的健康度。监控贯穿整个应用流程,如应用程序服务器、中间件适配器、传输协议、数据库、并且能够监控后台如CICS、IMS等主机系统。收集应用程序请求周期的数据,然后存储到监控数据库,数据包括请求开始,结束的时间,所用的中央处理器时间等等,并且能够通过一层层的递进跟踪找到每个类,每个方法的响应时间,中央处理器时间,从而定位发生交易失败、响应恶化的请求,并找到应用程序需要改进优化的地方。
(2)采用端到端的应用监控,跨节点,粗粒度监控响应时间,从而找到问题的根源。图1能很好的展示端到端的应用监控作用。
当一个应用跨越多个节点,出现不可用,或者响应缓慢的时候,第一步是需要知道慢在哪个节点上(哪台机器上),然后才能去诊断为什么那个节点会慢。以图1为例子,通过应用的拓扑图和每个节点上的响应时间,我们能很快的定位到“潜在出问题”的节点上。进而通过ITCAM for WR/DB/MSG来查看容器的性能指标找到问题根源。
(3)采用用户终端视角搜集响应时间。所监控的响应时间是指从客户端发起请求到服务端返回整个交易所消耗的时间:响应时间 = 客户端运行时间 + 网络时间 + 服务端运行时间。监控获取HTTP协议的响应点来实现对Web服务器的无侵入式监控,它不需要在Web服务器中安插任何代码,而是通过获取每个IP包的拷贝做协议栈分析来获得具体的响应时间,因此,理论上可以支持任何HTTP服务器。图2是所度量的响应时间。
其中图2编号分别代表:
(1)浏览器向Web服务器发出页面请求;
(2)服务器接收请求;
(3)服务器发出第一个包;
(4)浏览器请求第一个嵌入式对象;
(5)服务器发送页面HTML的最后一个包;
(6)服务器发送最后一个嵌入式对象的最后一个包;
(7)浏览器接收最后一个嵌入式对象的最后一个包。
3 总结
针对电网信息化业务运行监控,本文首先提出了业务运行监控现存的4个问题;并通过分析找出问题在技术上的根源:业务逻辑和数据传输跨越多个资源环境是业务运行监控难以管理的技术根源。
然后本文提出了模拟用户交互监控和通过“解剖”交互,查找,定位故障根源,为资源级故障诊断指明方向的解决思路。
最后本文提出了具体的解决方案,方案包括:
(1)采用对J2EE的应用程序进行实时监控和历史数据分析,发现并且报告J2EE应用的健康度;
(2)采用端到端的应用监控,跨节点,粗粒度监控响应时间,从而找到问题的根源;
(3)采用用户终端视角搜集响应时间。使得业务运行监控可以深入到业务应用内部,监控业务流程的每个步骤,从而使得故障得以快速定位、诊断和优化,IT运维人员精准到感知最终用户的体验,实时掌握业务运行状态。
猜你喜欢
疯狂英语·新读写(2021年10期)2021-12-07
铁道通信信号(2019年9期)2019-11-25
中国交通信息化(2019年5期)2019-08-30
新世纪智能(英语备考)(2019年4期)2019-06-26
铁道通信信号(2019年11期)2019-05-21
网络安全和信息化(2017年10期)2017-03-08
知识产权(2016年8期)2016-12-01
网络空间安全(2016年3期)2016-06-15
现代工业经济和信息化(2016年8期)2016-05-17
中国当代医药(2015年17期)2015-03-01
