
基于残差网络的食物图像识别研究
2019-09-17 08:27刘鹏臻
电子技术与软件工程 2019年16期
文/刘鹏臻
如今,在关注人们的健康和饮食状况方面,技术手段正扮演越来越重要的角色。因此诞生了许多应用可以让用户拍下的食物照片,识别食物并检测营养成分。怎么及时有效地从食物照片中提取出有用的信息是个挑战。在食物图像识别领域,现在也有一些食物图像识别的项目,这些项目主要基于手工设计特征提取的传统方法,然后使用机器学习的分类器进行食物分类。本文中,我们提出了一个ResNetcompress50网络模型,来实现食物识别。
1 相关介绍
图像识别属于人工智能的一个重要领域,国外很多高校和公司在图像识别方面投入了大量的资金和人力研究。2012年,深度学习技术在图像识别领域产生了巨大突破,Hinton教授的研究小组在ImageNet的大规模视觉挑战赛的图像分类比赛中赢得了第一名,准确率超过第二名10%之多,而其他小组均是使用的传统的图像识别方法。同年,谷歌受到深度学习的启发,发布了基于深度学习的图像搜索引擎,与之前图像搜索引擎对比,图像的准确率得到大幅提升。2015年的ImageNet图像识别比赛中,微软亚洲研究院的何凯明等人设计的残差网络更是达到了152层之深,并一举夺得冠军。2019年Hinton也因为深度学习获得图灵奖。

图1:图片增强结果示意图
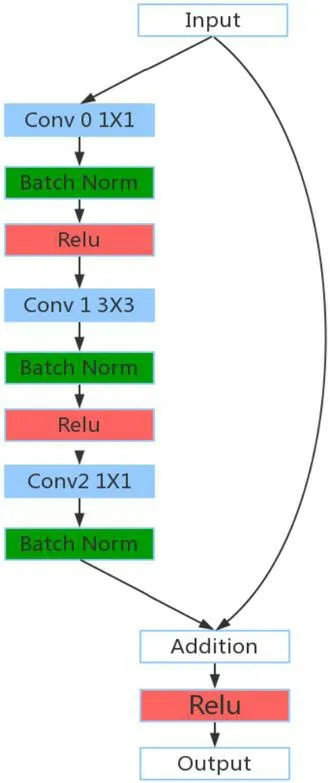
图2:瓶颈单元块结构示意图
2 数据集和模型实现
2.1 数据集
数据集的图像识别对象是新加坡的常见食物,我们使用爬虫从网上爬取新加坡食物的图片,进行数据清洗,给每个图片贴上准确的食物标签,进行监督学习。
训练集中每种食物只包含了400张图片,为了防止过拟合,这里我们参考使用ResNet论文中的方法进行图像增强。通过将原始图像统一调整到256×256像素,对图片进行截取和翻转将一张图片变成多张图片。截取是指分别在统一调整的图像左上角,右上角,左下角,右下角以及中间截取五处,截取大小为224×224像素。每张截取的图片都进行翻转,一张图片经过增强处理后,变成十张图片。如图1所示,这是一张辣椒螃蟹的图片进行图像增强后的结果。
2.2 模型实现
根据相关文献论文,使用CIFAR-10数据集,同样深度的深度残差网络和普通网络,深度残差网络在解决了深度退化问题,表现显然更好,所以我们选用深度残差网络。我们提出的ResNet-compress50模型是根据何凯明提出的深度残差网络50层模型结构改进的,减少了其中卷积层中的卷积核总数的1/4。根据实验结果显示,该方案确实大大减少了模型的训练时间和模型的大小,而准确率没有明显衰减。我们的网络单元块结构使用了何凯明提出的瓶颈结构,如图2所示。
我们使用三层网络来描述残差函数,三层的卷积核大小分别是1x1,3x3和1x1,其中1x1的卷积层主要是针对输入和输出维度不同是,使用1x1的卷积核可以做到先减少维度,后恢复维度,使得3x3的卷积层具有较小的输入输出尺寸。瓶颈结构相对于三层卷积层,三种卷积的时间复杂度很接近。这样设计卷积层的操作不会改变输入数据的维度,即输出的特征图和输入数据的维度不会改变,在于使用3*3的卷积核卷积层都会配一个大小为1的pad,同时步长被设置为1,同时每做一次池化操作输出的特征图的长宽都会缩小一倍。而1*1的卷积核的加入可以进一步增加模型的非线性,并且不会改变特征图的大小,这就大大增加了模型的表现能力。在输入方面,因为残差网络的输入设计一般都设置为256或者384等维度,模型不需要根据不同的输入维度设计不同的卷积结构,这就大大方便了模型的设计,直接加深网络结构使用同样的单元块就可以了。另外,我们在批量规范化层之后的激活函数都使用的是ReLU,ReLU能够使得函数收敛得更快,取得更高的准确率。在何凯明的另一篇论文中,提出了另一个瓶颈结构,把批量规范化放到相加层之后,如图3所示。
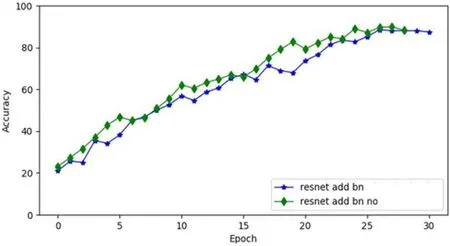
图5:相加层使用BN和没有使用BN对比图
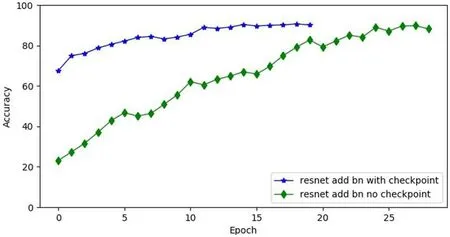
图6:使用checkpoint和不使用checkpoint训练对比图
组合瓶颈块结构,根据何凯明提出的残差网络结构,如图4所示。我们的实现的残差网络共50层,有4个stage,每个stage分别包含了3,4,6,3个单元块,为了减少模型的参数以及训练的时间,我们对模型结构进行了一些改进,减少了卷积层conv2到conv5卷积核的个数,卷积核的个数变为原来的3/4。在输出层,没有使用全连接层,这就大大减少了模型的参数,缩短了训练时间和验证用时。在输出之前,残差网络使用了全局平均池化层,全局平均池化将最后一层的特征图进行全局的均值池化,通过输入平铺层,形成一个个特征点,然后将这些特征点组成特征向量,通过softmax层进行归一化处理,计算分类概率。
3 实验与分析
3.1 模型实验
深度学习训练平台使用的是新加坡国立大学的深度学习框架SINGA,现在网络模型越来越深,数据集也越来越大,目前一般采用的算法时上述两种方法的折中,训练方法采用小批量梯度下降法,小批量梯度下降法把数据分为若干个批,按批来更新参数。
我们进行三个实验,选出最好的模型和超参数。第一个是对比不同层数的普通卷积神经网络和残差网络,以及我们提出的改进的方案性能,数据集采用的是ImageNet,我们初始化网络参数采用服从期望为0,标准差是0.01的高斯分布,网络的学习速率被初始化为0.01,每次遇到错误率平台区时学习率除以10,进行下一阶段的训练。为了提升模型的泛化能力,避免过拟合,我们在训练过程中还使用了权值衰减惩罚技术,其速率参数大小设为0.0001,冲量参数大小设为0.9,目标函数使用了L2范式的正则化处理。
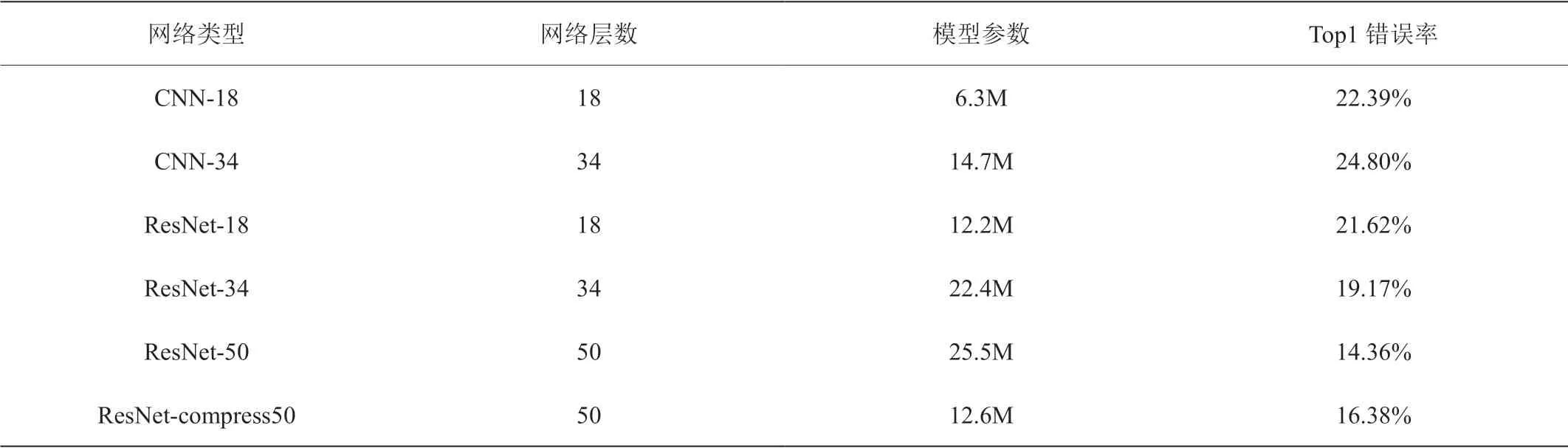
表1:不同网络模型性能对比
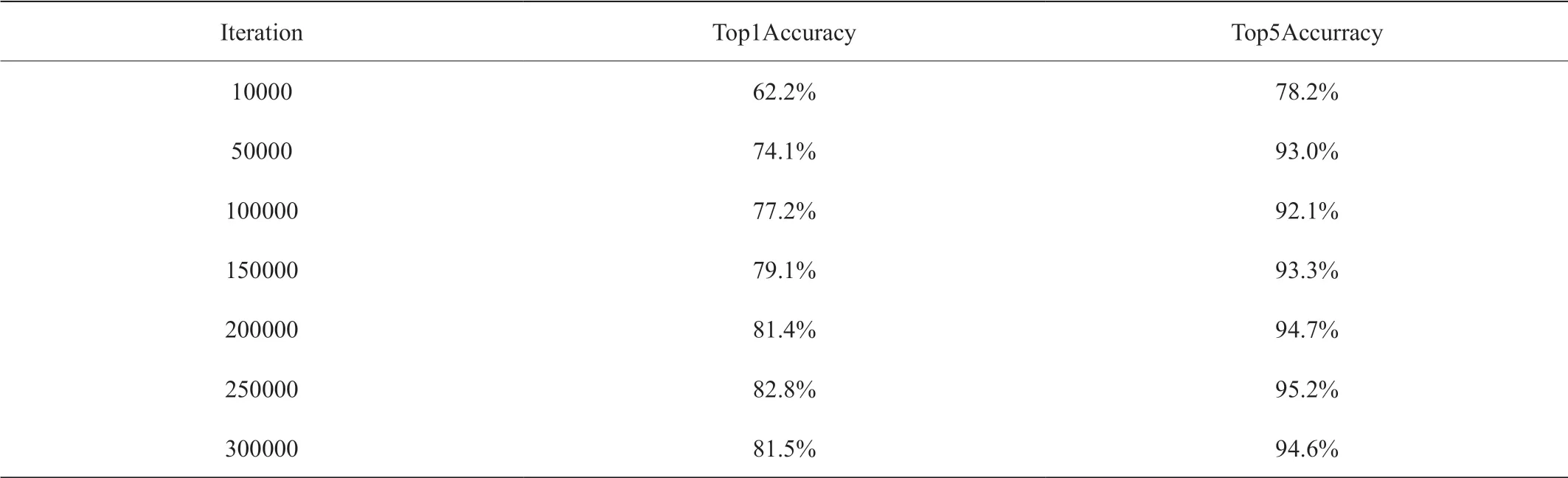
表2:不同Iteration的Accuracy

表3:Sgfood50数据集两种网络对比
第二个实验是在使用了另一种瓶颈结构与普通残差网络的瓶颈结构效果进行对比。参数相关设置同实验一。
第三个实验是采用了预训练的方式,在初始化参数时,我们首先使用ImageNet的数据集进行预先训练,得到的参数作为checkpoint,不再使用随机参数,而是采用checkpoint。其余设置同实验一。
3.2 实验结果分析
3.2.1 实验设置
使用的硬件设备是单节点机器,使用GPU进行训练,单节点包含了3个NVIDIA GeForce GT 970 GPU,每个GPU内存4G,操作系统是Ubuntu16.04。
数据集一共包含了50种新加坡常见食物,整个数据集共有二十万张图片,训练集和验证集的比例我们设置成9:1,即训练集有18万张图片,验证集有2万张图片。
3.2.2 实验结果分析
第一个实验对比卷积神经网络和残差网络。我们使用SINGA训练了五种不同的网络,普通卷积神经网络19层34层及深度残差网络的19层,34层和50层结构。如表1所示,普通神经网络参数大,错误率高。而使用ResNet则解决了梯度消失的问题,网络越深,识别率效果越好,模型相对普通卷积神经网络要小得多。
第二个实验我们在第一个实验基础上,选择ResNet-compress50进行继续训练,对50层模块进行改进,在一个瓶颈基础块中的相加层之后加上批量规范化层。在使用了不同的瓶颈单元块之后,50层的网络结果的变化,实验结果如图5所示,实验证明在相加层之后使用了模型规范化在本数据集中是较好的选择。
第三个实验是关于训练方式的优化,如图6所示,显然使用了checkpoint的参数进行训练的效果要好很多,通过优化,ResNetcompress50的网络的预测准确率可以达到82.3%,准确度甚至更优,训练收敛速度更快。
模型的训练时间。训练一个50层的模型需要大量的时间,使用残差网络向前传播大概一张图片需要3到4秒钟。在我们的实验中,训练的时间主要受几方面影响,一个是GPU的性能,如果使用CPU,训练时间可能达到一周甚至更久,输入图片的大小,以及我们的迭代次数和mini-batch的大小。根据粗略的估计,我们使用ImageNet进行预训练的时间大概需要10个小时,然后使用预训练的参数模型进行训练需要7个小时左右。
最终,我们在实现神经网络选用的是50层的残差网络,训练方法采用使用ImageNet数据集进行预训练得到的参数进行初始化模型,再使用基于mini-batch的随机梯度下降算法进行训练和权重更新。第一种食物准确率达到82.3%,前五种食物的识别准确率可达95.2%。
3.2.3 模型性能评估
最后,对我们的ResNet-compress50模型的评估,我们主要从三个方面进行评估。
第一个方面是ResNet-compress50模型的准确率Accuracy,系统的功能测试结果,我们得到第一名的预测结果准确率达到82.3%,前五位包含正确结果准确率达到95.2%。如表2所示。
第二个方面是,模型参数大小,训练总长,主要通过与原始ResNet50模型的对比。模型大小是92MB,训练时间需要7个小时左右,相对于原始的ResNet50网络,我们训练时间缩短了4个小时,模型大小也缩小了35MB,而模型识别的准确率几乎没有明显变化,训练时间的缩短对于日后使用用户数据集进行持续训练是大有好处的,对比结果如表3所示。
第三个方面是训练时间和预测时间,针对NVIDIA GeForce GT 970 GPU,加速库使用的是cuDNN5.1,每次迭代训练时间是测出一个minibatch一次迭代的时间,我们计算10次连续迭代过程间的平均时间差,我们设置每个minibatch大小是50,最后得到平均每秒可以执行1.2次迭代,而预测平均每秒可以执行6.7次迭代。
4 总结
我们提出了一个基于ResNet的网络模型ResNet-compress50来实现食物识别,这个50层的深层神经网络的表现很好,前五种结果识别准确率达95%,满足了一个关注健康和饮食应用所需要的图像准确识别的需求。
通过实验,本文选出最适合我们食物图像识别系统的模型,调优了模型的超参数以及最好的训练方法。因此,利用了深度学习的技术来满足食物图像识别的功能需求,这对于许多食物识别的的应用都是有参考意义的。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
医学食疗与健康(2021年27期)2021-05-13
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年16期)2019-09-27
自动化学报(2019年6期)2019-07-23
中国交通信息化(2019年4期)2019-07-13
电子制作(2018年19期)2018-11-14
中国交通信息化(2018年5期)2018-08-21
电子制作(2018年14期)2018-08-21
河南科技(2015年8期)2015-03-11
