
学习模型指导的编译器优化顺序选择方法
2019-09-16 02:32徐金龙赵荣彩姚金阳
计算机研究与发展 2019年9期
刘 慧 徐金龙 赵荣彩 姚金阳
1(河南师范大学计算机与信息工程学院 河南新乡 453007)2(数学工程与先进计算国家重点实验室(战略支援部队信息工程大学) 郑州 450002)3(河南省高校“计算智能与数据挖掘”工程技术研究中心(河南师范大学) 河南新乡 453007)
为应用程序选择最佳编译优化顺序是编译优化领域历久弥新的问题,而且是NP完全问题,编译器研究人员依靠他们对编译器后端的理解提出一些预定义的优化顺序.大型应用程序编译优化方案的提出需要研究人员花费很长的时间运行程序的不同优化版本,远不及体系结构和应用软件的更新速度.GCC(GNU compiler collection)编译器有超过200个的编译优化遍(pass),LLVM(low level virtual machine)编译器有超过100个的编译优化遍,并且这些优化在不同的应用层上工作,如分析遍、循环嵌套遍等.通常情况下,大多数编译优化是默认关闭的,编译器开发人员期望软件开发人员知道哪些优化对其代码是有益的,而软件开发人员可能并不熟悉编译优化相关知识.目前,大多商用编译器使用标准优化级别-O1,-O2,-O3等为应用程序执行固定顺序的优化,对于大多数应用程序可以带来“平均良好性能”.然而,由于应用程序具有不同程序特征,为产生最佳性能提升,必须采用更有程序针对性的编译优化顺序[1].特别是针对嵌入式系统的编译器更加依赖于代码优化,因为使用的体系结构更加受限于内存大小、处理器速度等.如何为目标程序实施更有针对性的优化顺序,最大化程序性能仍然是一个亟需解决的关键问题.
在高性能计算领域中,并行计算机系统日益复杂.为了降低系统功耗,开发人员应用了不同的硬件和软件技术.目前主流的P级高性能计算机系统大多使用了GPU[2]和MIC(many integrated core architecture)[3]等众核处理器作为加速器或协处理器.在2017年6月的TOP榜单中,排名前十的机器中有5台使用了GPU或者MIC处理器作为加速器和协处理器[4].计算密集型应用程序将大部分的执行时间花费在适合于高级编译优化的循环嵌套中,例如稠密线性代数代码等.近年来提出的多面体编译优化技术亦致力于将数学表示集中在多面体模型的循环嵌套中[5-6].因此,复杂体系结构下为应用程序特定循环结构选择更有针对应的优化顺序,对程序性能提升至关重要.目前,通常使用迭代编译方法和基于机器学习的方法解决编译器优化顺序的选择问题.
迭代编译(iterative compilation)是一种针对通用程序的优化方法,该方法可有效集成不同的优化技术,适用于不同的体系结构[7].Chen等人[8]提出基于数据中心的迭代编译方法,通过在主服务器上收集性能统计数据,选择最佳编译优化及进行收益分析.Purini等人[9]使用下采样技术减少优化搜索空间,为应用程序选择最佳编译器优化顺序.Nobre等人[10]提出将编译器优化遍之间的变换用图形进行表示,然后通过图形采样的方式确定目标程序的优化顺序,能够有效减小搜索空间和提升收敛速度.Martins等人[11]基于遗传算法,采用聚类技术实施应用程序特定的优化顺序选择.在面向FPGAs的硬件编译环境下,Huang等人[12]分析了2种基于顺序插入的迭代方法,用于可变序列长度的编译优化顺序选择.采用迭代编译获取的程序性能加速明显好于静态编译,但在程序的迭代编译过程中会产生庞大的编译优化空间.此外,迭代编译是一种“无记忆”的优化搜索方法,不能利用已经获取的编译优化经验.
因此,编译优化人员提出将机器学习技术加入传统迭代编译优化过程,逐步形成基于机器学习的迭代编译方法[13-15].优化预测模型的输入为程序特征,输出为特定性能目标,如程序运行时间、优化选择和优化顺序等.理想情况下,预测模型独立于应用程序,能对不同程序版本进行快速评估,显著减少迭代编译代价[16].Agakov等人[17]提出2种优化顺序预测模型:独立同分布模型和马尔可夫模型,以提升应用程序性能.预测模型在迭代编译过程中利用机器学习算法寻找更好的优化顺序,取得了一定的程序性能提升.但Agakov等人[17]提出的模型仅使用源代码程序特征,不能体现程序的当前版本优化状态,而程序的当前优化状态对接下来将使用的优化具有重要的影响.
Fursin等人[18]提出基于GCC编译器的Milepost GCC,将机器学习算法集成于GCC编译框架.Milepost GCC基于源代码及程序中间表示抽取程序特征,统计不同指令和函数控制流图信息,使用机器学习技术自动调整程序优化变换.但Milepost GCC主要解决的是优化选择问题,基于固定的优化顺序从中选择能最有效提升代码性能的优化,而且其使用的是固定长度的特征向量.Cavazos等人[19]提出一种基于机器学习的编译优化顺序预测方法,该方法使用性能计数器构建程序特征向量,并用于预测编译优化顺序.Dubach等人[20]提出使用机器学习在嵌入式程序和微体系结构之间进行可移植的编译器优化.Hoste等人[21]提出使用多目标进化算法为程序选择最佳编译优化.Kumar[22]提出通过在多核CPU上使用并行遗传算法选择最佳编译优化.Jantz等人[23]采用修剪设计空间搜索技术,在较小的非联合优化子集上进行多阶段的优化顺序搜索.Ashouri等人[24]提出优化顺序预测模型COBAYN,基于贝叶斯网络将程序特征表示与编译优化遍相关联,以最大化程序性能.Park等人[25]将基于多面体模型的迭代编译与机器学习相结合用以解决编译优化顺序问题,取得了较好的预测效果.现有基于机器学习的迭代编译方法大多数使用单独的静态程序特征或单独的动态程序特征进行优化预测模型的构建,如何采用更有效的程序特征表示方法需要进一步进行研究.此外,为了进一步降低编译器优化顺序选择过程中的迭代编译开销,如何构建更有效的优化预测模型,也亟需进行更深入的研究.
人工神经网络(artificial neural network, ANN)是一种模拟人脑功能对数据信息进行加工处理的系统化方法.本文提出基于机器学习的编译器优化顺序选择方法Features ANN,通过ANN基于监督学习模型进行编译器优化顺序选择.主要贡献有3个方面:
1) 使用动静结合的程序特征表示方法,通过主成分分析技术将高维程序特征降维为低维程序特征,在不降低程序表示性的基础上,为优化顺序预测模型选择最佳程序特征表示.
2) 优化顺序选择模型Features ANN的样本为由降维后的程序特征和当前最佳优化构成的二元组,利用人工神经网络建立统计模型并集成于编译器框架,为目标程序选择当前优化状态下的最佳优化及进行编译过程驱动.面对新的应用程序,Features ANN将新程序特征作为其输入,并预测最佳优化,从而生成新程序的最佳优化顺序.
3) 在2种平台上采用动静结合特征作为Features ANN预测模型输入时,相对于GCC 8.1.0编译器标准优化级别-O3分别获得1.49x和1.41x的程序执行时间加速.此外,与现有迭代编译方法和非迭代编译方法相比时,均获得了最佳的程序性能提升.
1 学习模型指导的优化顺序选择模型
1.1 优化顺序问题的形式化描述
为了对优化顺序选择问题有更直观的认识,我们首先对编译优化的选择空间进行形式化描述.定义布尔向量o,元素oi表示不同的编译优化,每个优化可以被启用(oi=1)或禁用(oi=0).编译优化的选择空间属于n维布尔空间,由向量空间oselection表示为
oselection=(0,1)n.
(1)
当对应用程序ai进行优化时,n表示编译优化总数,由一个指数空间作为其上限.例如,当n=10时,目标应用程序ai有1 024种可选择的优化方式.当应用程序有N个不同的优化版本A={a0,a1,…,an}时,将产生更大的优化空间.
当使用固定优化序列长度且不重复使用优化时,定义编译优化顺序为n维向量空间为ophase=n!,其中,n表示编译优化总数.当使用动态优化序列长度且可重复使用优化时,优化顺序空间扩展为
(2)
其中,m表示优化序列最大期望长度.假设n和m均为10,将产生高达110亿种不同的编译优化顺序.当优化序列最大期望长度m没有固定值时,编译优化顺序问题没有上界.
1.2 监督学习模型指导的优化顺序选择模型
监督学习模型指导的编译器优化顺序预测模型框架如图1所示,包括数据收集、模型训练和模型预测阶段.在数据采集阶段,首先根据程序特征表示方法,使用设计空间探索引擎(design space exploration, DSE)抽取程序特征{F1,F2,…,Fn},提取目标程序特征值{f1,f2,…,fn}.然后,使用DSE将优化集合{o1,o2,…,om}中的优化oi分别应用于目标程序.DSE通过启用和禁用优化实施不同的优化、优化顺序及测试应用程序运行时间.由于程序在每应用一次优化后,特征值将会发生相应的改变,需要根据更新后的特征值确定下一阶段应使用的优化.因此,我们设定DSE在每应用一次优化后重新提取特征值{f1,f2,…,fn},以表示程序的当前优化状态.并根据程序的当前优化状态再次选择优化集合{o1,o2,…,om}中的优化oi和测试运行时间.数据收集阶段收集的训练数据由{oi,f1,f2,…,fn,si}构成.其中,oi表示优化变换,{f1,f2,…,fn}表示程序特征值,si表示特征值为{f1,f2,…,fn}时程序实施优化oi可获得的加速比.当产生最大加速比smax时,对应的优化oi即为程序当前状态下可使用的最佳优化.
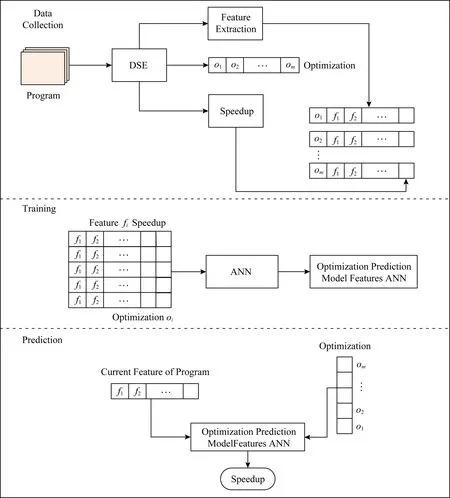
Fig. 1 Compile optimization sequence prediction model图1 编译优化顺序预测模型
在模型训练阶段,基于收集到的训练数据,采用ANN进行模型训练,构建程序优化及优化顺序预测模型Features ANN.在模型预测即使用阶段,基于程序在当前优化状态下的特征值,通过存储在预测模型中的知识为新程序预测当前状态下应用不同优化时的加速比,实现最大加速比对应的优化即为程序在当前状态下应使用的最佳优化,从而生成新程序的最佳优化顺序.优化终止条件为达到预先设定的最大优化序列长度,或连续为程序当前状态预测相同的优化.
2 程序特征表示
2.1 程序特征
现有程序特征表示方法包括:
1) 静态程序特征表示.静态特征通常在语法分析过程中、编译过程中提取.
2) 动态程序特征表示.动态特征在程序运行过程中提取,通常具有更好的程序表示性,但为获取动态特征往往需要反复执行程序的运行.
Features ANN优化顺序预测模型使用动静结合的特征表示方法(dynamic static features combination, DSFC),为预测模型提供更细粒度的输入.静态和动态特征列表如表1和表2所示[14].

Table 1 List of Static Features表1 静态特征列表

Table 2 List of Dynamic Features表2 动态特征列表
2.2 特征降维技术
程序特征的选择是构建优化顺序预测模型的关键,本文采用主成分分析法(principal component analysis, PCA)为目标程序选择最主要的静态特征和动态特征.当数据空间维度大于3维时,将无法在空间坐标系下用图形(如点、线、面)表示样本点.程序特征高维空间的多变量数据不能以图形化方式直观展示其空间特征分布规律,如样本相似度、样本中的异常点等信息.PCA的核心思想是通过正交变换,将一个变量维数较高而且变量之间存在相互关联的数据矩阵映射到一个较低维数的主成分空间.程序特征的PCA计算过程为:
Step1. 假定程序特征中有p个样本,每个样本共有n个变量,样本数据可构成一个p×n阶矩阵:

(3)
对样本矩阵进行标准化变换,得到标准化阵Z:
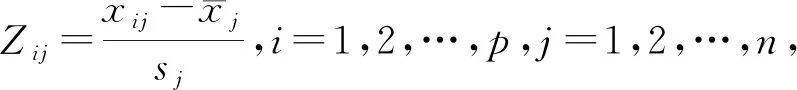
(4)
其中,
(5)
(6)
Step2. 对标准化阵Z求相关系数矩阵:
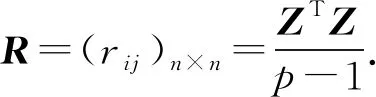
(7)
Step3. 解样本相关阵R的特征方程|λI-R|=0,求出n个特征根,按照特征值的大小倒序排列.对于每一个特征值λi求出其所对应的特征向量ei(i=1,2,…,n).
Step4. 主成分的选取规则:
(8)
(9)
其中,统计量Ii代表某一主成分λi的贡献率,统计量Si代表某一主成分λi的累积贡献率.k的选择原则是取累计贡献率90%,保证主成分变量包括原始数据的大多数信息,即求得Si≈0.9的所有λi所对应的主成分fi.
Step5. 载荷系数的计算.观测值xi(i=1,2,…,n)在主成分fi上的得分为
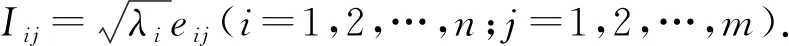
(10)
Step6. 根据程序特征,对程序特征主成分进行命名,对主成分及其荷载进行相关解释.
主成分提取原则一般选取主成分累计贡献率超过90%的前m个主成分,经过实验分析表明,由于程序特征值的冗余和协方差,程序特征可以降维至5维特征向量,此时仍能保持99%的数据差异性.
3 ANN构建
3.1 基于ANN的优化顺序预测
在编译器中确定合适的优化顺序是一个十分复杂的问题,我们可以将优化顺序问题定义为马尔可夫过程(Markov process, MP),即基于当前程序版本状态做出接下来应用何种优化的决定.本文以ANN为基础构造程序变换优化顺序预测模型Features ANN.Features ANN的基本思想是持续询问ANN预计使用何种优化可为当前状态下的程序产生最佳性能.ANN使用当前状态下的代码特征作为输入,利用网络层次表示特征之间复杂的非线性关系,并与优化过程中特定点的最佳优化相关联.Features ANN模型框架如图2所示:
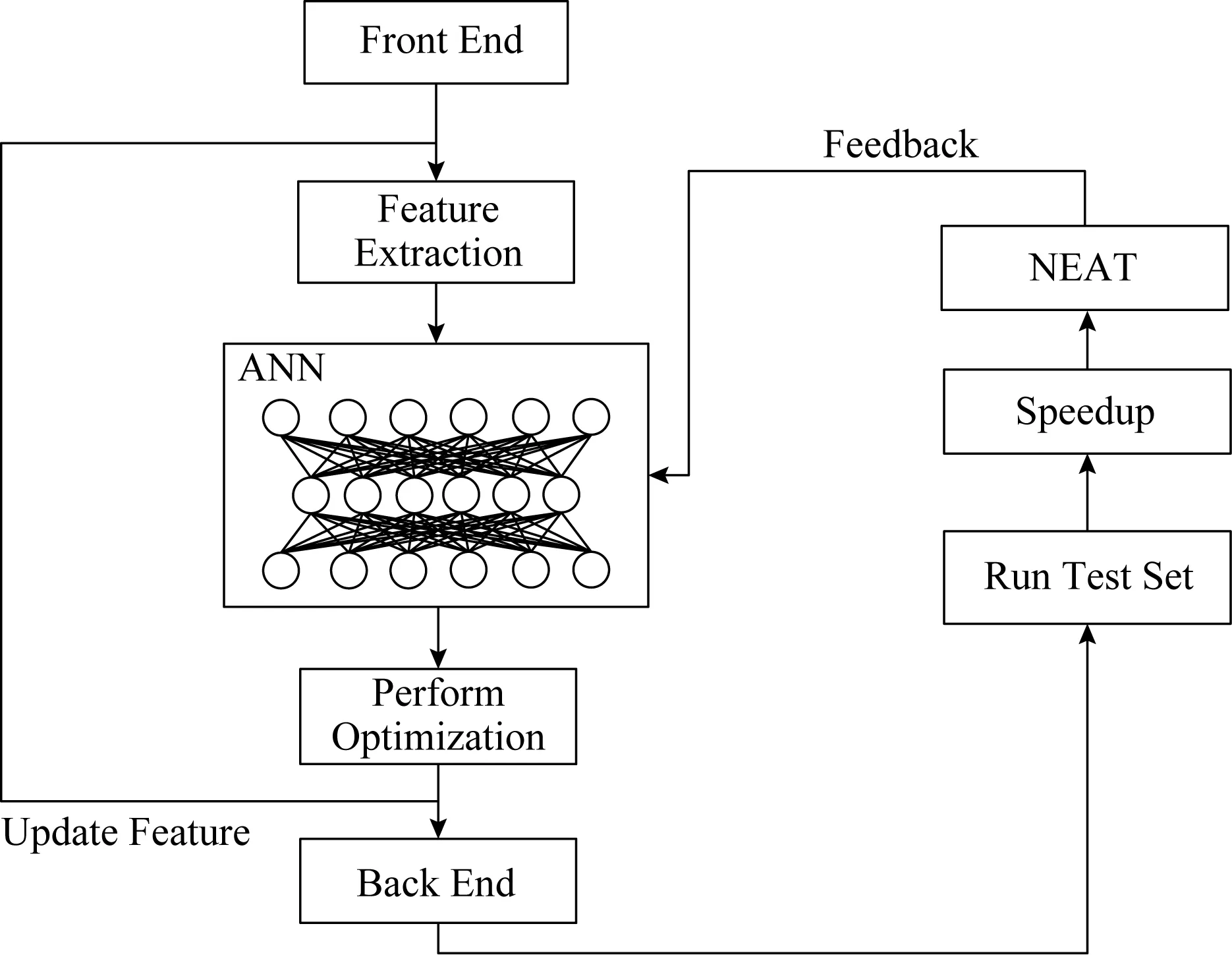
Fig. 2 Process of Features ANN compile optimization selection图2 Features ANN编译优化选择过程
在模型训练阶段,采用扩张拓扑的神经进化算法(neuro-evolution for augmenting topologies, NEAT)生成用来控制优化顺序的ANN,通过对每个函数应用不同的优化,并记录程序运行时间进行ANN评估.Features ANN迭代输出优化oi的过程如图3所示.ANN的输入为当前状态下的代码特征{f1,f2,…,fn},输出为应用不同优化oi后的收益概率P,选择最大概率P对应的优化obest作为当前状态下应使用的优化.应用优化obest后将形成一个新的程序版本,特征值发生改变,将更新后的特征值重新输入Features ANN,使其输出下一个要应用的优化oi+1.当ANN达到最大代数或连续若干代性能没有变化时,停止使用优化,生成目标程序优化顺序{o1,o2,…,om}.模型预测阶段将ANN集成于编译器,并作为新程序优化顺序的启发式规则进行使用.Features ANN优化顺序选择算法如算法1所示.
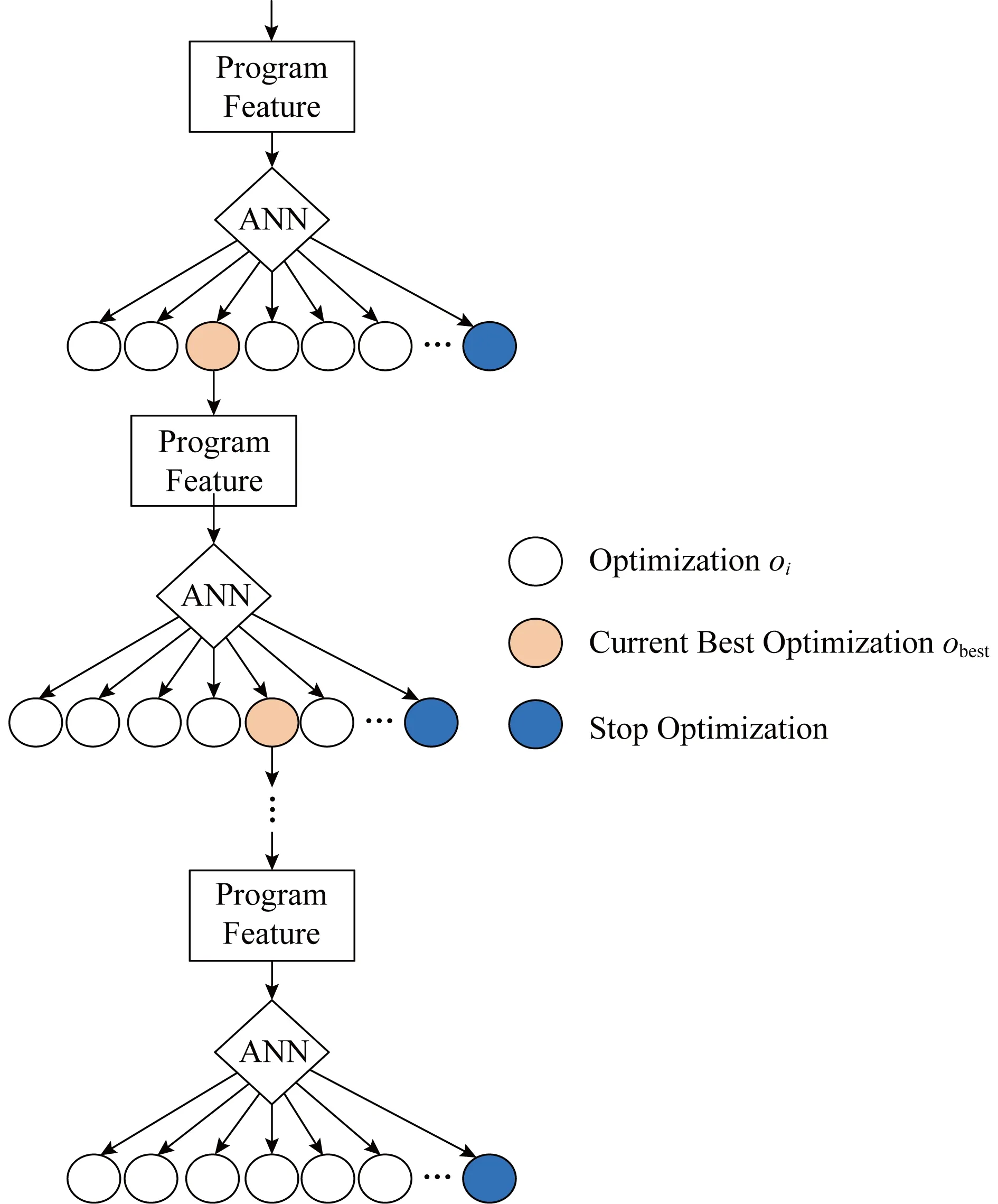
Fig. 3 Process of Features ANN output optimization oi iteratively图3 Features ANN迭代输出优化oi过程
算法1.基于ANN的优化顺序选择算法.
输入:程序特征值f1,f2,…,fn,优化{o1,o2,…,om};
输出:最佳优化序o*={o1,o2,…,om}及其对应的程序运行时间T*.
Step1. 初始化:设置每代神经网络个数N、网络代数M,并随机生成第1代网络.
Step2. 输入程序C当前状态特征值f1,f2,…,fn作为当前代网络输入层神经元的输入.
Step3. 计算每个网络的适应度Fitness(T),选择前10个具有最大适应度值的网络传播到下一代产生新的网络
Step4. 交叉和变异产生新一代网络.变异包括在网络隐藏层现有边上增加一个神经元(概率设置为0.1%)、增加一个新边(概率设置为0.5%)或删除一个现有边(概率设置为0.9%).
Step5. 当网络到达最大代数M或连续若干代性能没有变化,将具有最大适应度的优化作为当前程序版本状态下的最佳优化obest.
Step6. 算法终止条件:当达到最大优化个数或重复使用优化没有性能提升时,算法终止,转至Step7,否则更新函数特征,转至Step2.
Step7. 输出最佳优化序o*={o1,o2,…,om}及其对应的函数执行时间T*.
3.2 NEAT
由于优化顺序预测模型Features ANN处于动态编译环境中,因此ANN及特征抽取过程的开销要小,否则应用该网络进行优化顺序选择的代价会高于调整优化顺序带来的收益.本文采用NEAT算法[26]为程序变换优化顺序选择模型构建ANN.NEAT算法开始于若干没有隐结点的最小网络,在进化的实施过程中通过变异引入新结构,从而进行网络扩张.并通过适应度评估网络优劣,淘汰适应度较低的个体.由于种群从最小结构开始,优化搜索空间的维度也将是最小的.因此,NEAT算法总是搜索比其他进化神经网络算法更低的维度空间,网络构建开销小于其他同类算法.
NEAT进化神经网络的过程是从只有输入输出结点的简单网络开始逐步增加网络复杂程度,具有较大的结点连接自由度.如图4所示,NEAT采用结点基因编码进行网络结构和连接权值的描述.当创建新的结点和连接时,借助于所产生的历史标记,从而避免竞争约定问题.NEAT尝试将构成的网络尺寸最小化,在进化开始时让群体中每个神经网络都具有最小的拓扑结构,在进化过程中始终保持在网络中随机逐个添加神经元和连接.该过程和自然界生物体的生长过程一样,随着时间的推移,不断进化、不断增加复杂性,从而试图构建最小化的最优网络.

Fig. 4 NEAT gene mapping图4 NEAT基因映射
NEAT算法的适应度值为训练集中测试集性能的几何平均值:
(11)
其中,|S| 表示训练集个数,Speedup(s)表示程序运行时间加速比:
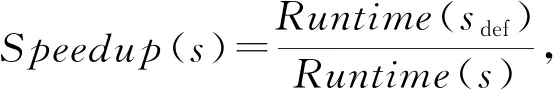
(12)
其中,Runtime(sdef)表示测试集s使用默认优化顺序时的运行时间,Runtime(s)表示使用预测模型预测的优化顺序时测试集s的运行时间.
4 实 验
我们在2种平台上进行Features ANN优化顺序预测模型的训练和评估,模型输入为程序热点函数特征,输出为相应的最佳优化顺序.
1) 平台1. 实验编译环境为Linux操作系统,版本为Readhat Enterprise AS 5.0,实验平台为国产处理器申威26 010,CPU主频为 2.5 GHz,L1数据cache为 32 KB,L2 cache为256 KB,向量寄存器宽度为256 b,可同时处理4个浮点型数据或8个整型数据.
2) 平台2.实验编译环境为Linux操作系统,版本为Readhat Enterprise AS 5.0,实验平台为Intel Xeon E5520处理器,CPU主频为2.26 GHz,L1数据cache 为32 KB,L2 cache为1 MB,二级Smart cache 8 MB.
实验中训练集测试用例为SPEC CPU2006测试集中的2 000个热点循环,测试集用例为NPB测试集和表3所示大型科学计算程序中的热点函数.实验将标准优化级别-O2及图5所示优化作为优化空间,将新的优化顺序与标准优化级别-O3的默认优化顺序进行性能对比,优化的启用禁用通过使用GCC8.1.0编译优化选项完成.对程序热点函数特征采用动静结合特征表示方法DSFC,将抽取的特征作为PCA过程的输入.我们分别比较了采用Features ANN和现有迭代编译方法、非迭代编译方法时测试集用例的程序性能.当现有方法使用的优化和测试集与本文不同时,我们采用本文的优化和测试集重新进行实验.对抽取的每个热点函数采用添加时间戳的方式进行运行时间计时,为减少噪声影响,每个样本运行10次,取执行时间平均值.

Table 3 Large Scientific Calculation Programs表3 大型科学计算程序
-fauto-inc-dec-falign-jumps-ftree-tail-merge-fstrict-overflow-fcombine-stack-adjustments-fcompare-elim-fcprop-registers-ftree-forwprop-ftree-pre-finline-functions-called-once-ftree-dce-fcaller-saves-fgcse-after-reload-ftree-vrp-fmove-loop-invariants-fipa-profile-fif-conversion-fssa-backprop-funswitch-loops-frerun-cse-after-loop-ftree-ccp-fif-conversion2-fstrict-aliasing-fpartial-inlining-fdce -fdefer-pop-fpeel-loops-fsplit-paths-fbranch-count-reg-fssa-phiopt-ftree-dominator-opts-fshrink-wrap-ftree-phiprop-ftree-partial-pre-finline-functions-fguess-branch-probability-ftree-sink-ftree-slsr-fipa-cp-clone-fschedule-insns2-ftree-loop-distribute-patterns-fthread-jumps-falign-functions-fipa-bit-cp-fsplit-wide-types-fisolate-erroneous-paths-dereference-falign-loops-falign-labels-findirect-inlining-ftree-coalesce-vars-foptimize-sibling-calls-fcrossjumping-ftree-vectorize-ftree-bit-ccp-foptimize-strlen-freorder-blocks-algorithm=stc-ftree-pta-fipa-pure-const-ftree-copy-prop-fschedule-insns-freorder-blocks-and-partition-ftree-ter-fdevirtualize-funit-at-a-time-fsched-interblock-fdelete-null-pointer-checks-ftree-sra-fipa-reference-fcse-follow-jumps-freorder-functions-fdevirtualize-speculatively-ftree-fre-freorder-blocks-fcse-skip-blocks-fhoist-adjacent-loads-fexpensive-optimizations-ftree-dse-fpeephole2-fipa-cp-alignment-fpredictive-commoning-ftree-loop-distribution-fgcse-flra-remat-fforward-propagate-fdelayed-branch -fdse-finline-small-functions-fgcse-lm-fsched-spec-fmerge-constants-ftree-switch-conversion-ftree-builtin-call-dce-fipa-cp-fipa-sra-fipa-icf-fcode-hoisting-ffast-math

Fig. 5 List of Optimization(GCC8.1.0)图5 优化列表(GCC8.1.0)
本文实验主要从4个方面进行:1)Features ANN采用不同特征时的性能比较.分别采用静态程序特征表示、动态程序特征表示和动静结合程序特征表示作为优化顺序预测模型Features ANN的输入,对比分析模型的预测性能.2)Features ANN与迭代编译方法的性能比较.比较测试集程序采用Features ANN与2种现有迭代编译方法时的程序性能.3)Features ANN与非迭代编译方法的性能比较.比较测试集程序采用Features ANN和3种现有非迭代编译方法时的程序性能.4)离线学习和在线预测时间开销比较.对比分析Features ANN和现有迭代编译、非迭代编译方法在训练数据收集、模型构建、特征抽取和模型预测上的时间开销.
5 实验结果分析
5.1 采用不同特征时的预测模型性能
基于现有程序特征表示技术,我们对比分析3类程序特征表示方法对优化顺序预测模型的影响:静态程序特征表示、动态程序特征表示和动静结合程序特征表示.其中,静态程序特征采用Milepost GCC静态程序,包括以固定长度特征向量表示的静态源代码及中间表示特征[18].动态程序特征采用基于性能计数器的动态特征表示(performance counter, PC),PC能实时采集、分析系统内的应用程序、服务等性能数据,以此来分析系统瓶颈、监视组件表现[19].动静结合特征表示我们的程序特征表示方法DSFC.
Features ANN分别采用不同特征表示方法,为NPB测试集和表3所示科学计算程序在平台1和平台2上预测优化顺序时,预测模型性能如图6和图7所示.其中,Milepost GCC表示静态程序特征,PC表示动态程序特征,DSFC表示本文提出的动静结合程序特征表示.Speedup表示相对于GCC 8.1.0标准优化级别-O3产生的性能加速比.
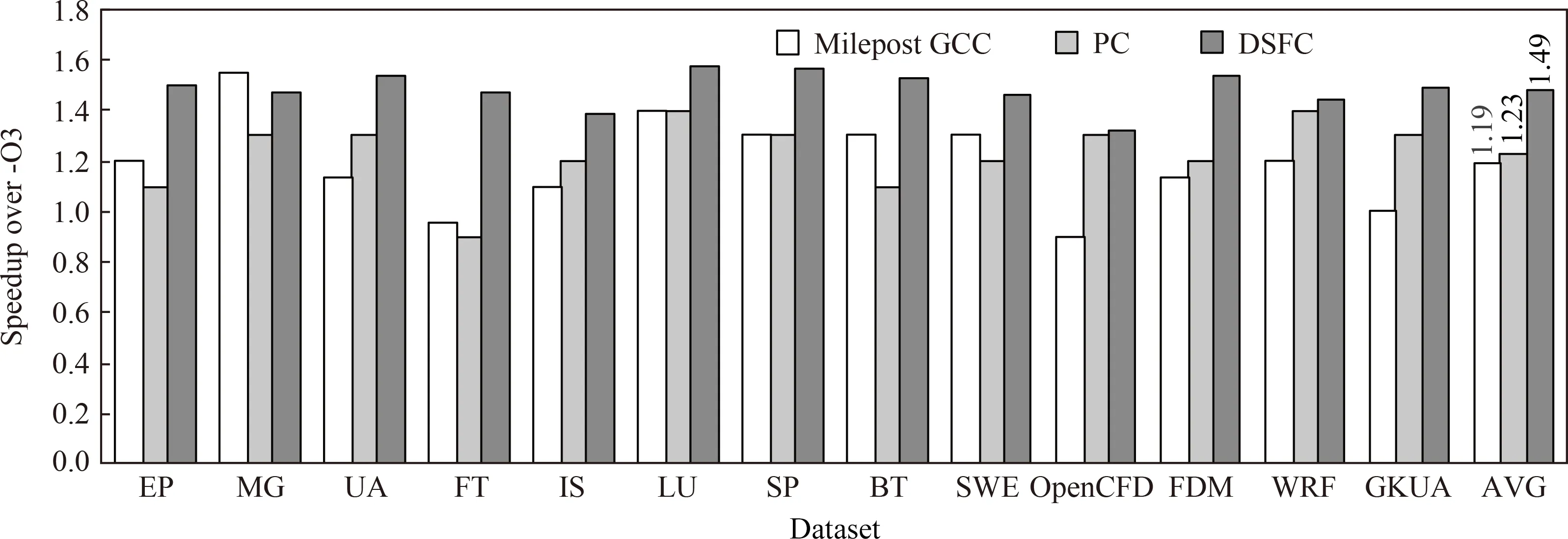
Fig. 6 Speedup on platform 1 when adapting different features图6 采用不同特征时平台1上测试程序加速比
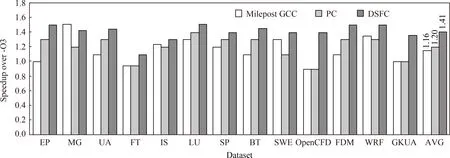
Fig. 7 Speedup on platform 2 when adapting different features图7 采用不同特征时平台2上测试程序加速比
实验结果表明,平台1上基于Milepost GCC静态程序特征、PC动态特征和DSFC动静结合特征为NPB测试集和大型科学计算程序预测优化顺序时,Features ANN相对于GCC标准优化级别-O3产生的平均加速比分别为1.19,1.23,1.49.平台2上产生的平均加速比分别为1.16,1.20,1.41.总体来说,对当前测试用例而言,采用DSFC动静结合特征可以产生最好的预测性能,PC动态特征次之,Milepost GCC静态特征具有相对较低的预测性能.
经程序分析可知,测试集LU的主要热点函数为rhs,占程序执行时间的24.98%.采用DSFC动静结合特征时,Features ANN为rhs预测的优化顺序为{-O2,-fpeel-loops,-funroll-loops,-fprefetch-loop-arrays,-fgcse-after-reload,-ffast-math}.采用Milepost GCC静态特征时,Features ANN为rhs预测的优化顺序为{-O2,-fpeel-loops,-funroll-loops,-fprefetch-loop-arrays,-fgcse-after-reload,-ftree-vectorize,-ffast-math}.采用PC动态特征时,Features ANN为rhs预测优化顺序为{-O2,-fpeel-loops,-fprefetch-loop-arrays,-funroll-loops,-ffast-math}.采用GCC-O3默认优化、DSFC动静结合特征、Milepost GCC静态程序特征和PC动态特征时对应的函数执行时间分别为:45.975 s,37.364 s,41.864 s,40.376 s.采用DSFC动静结合特征预测的优化顺序除使用标准优化级别-O2外,首先对该热点循环进行循环剥离,然后进行循环展开,循环展开可以将迭代次数少的循环进行展开以充分利用寄存器.循环中含有大量的3维数组和4维数组引用,使用-fprefetch-loop-arrays可以对数据预取,对含有大数组的程序可以产生较好的性能提升.此外,由于循环中含有大量的变量引用,在计算时会被重复使用,使用-fgcse-after-reload优化可以消除重复性的访存.采用Milepost GCC静态特征预测的优化顺序会对rhs 函数进行向量化处理,但该程序含有间接访存,且语句间含有阻止向量化的依赖环,内层循环迭代次数小,循环多为不完美循环嵌套,若对其进行向量化,将会引入一些数据整理指令,增大开销,性能反而会下降.采用PC动态特征预测的优化顺序在数据预取之后进行循环展开,会增加预取次数,且预测的优化中没有使用-fgcse-after-reload,获得的程序执行时间加速比小于采用DSFC动静结合特征产生的加速比.
DSFC动静结合特征表示优于Milepost GCC静态特征表示,原因在于Milepost GCC特征主要包括基本块和边的信息,这些信息是以整个程序为单位的固定长度的特征表示,而DSFC采用动静结合特征表示方法,而且程序特征是采用PCA方法选择的,不是固定不变的,更能表示出不同程序的主要信息.但是有一些程序如MG采用Milepost GCC特征时性能优于DSFC,原因是Milepost GCC有一些静态特征没有包括在在基于DSFC的特征中,这可能对特定程序有影响.DSFC动静结合特征表示也优于单独使用PC动态特征表示获得的性能.因此,在Features ANN预测模型中使用动静结合程序特征DSFC有利于进一步提升模型的优化顺序预测性能.
5.2 Features ANN与迭代编译方法的比较
为将Features ANN与现有迭代编译方法进行比较,我们选择与Nobre[10]和Martins[11]的研究进行对比分析.Nobre等人[10]提出一种基于迭代编译的优化顺序搜索方法,该方法首先将编译优化变换用图形方式进行表示,然后通过图形采样确定程序的优化顺序,能够有效减小优化搜索空间和提升收敛速度.Martins等人[11]基于聚类方法,采用遗传算法指导的设计空间探索技术选择应用特定的优化顺序,该方法是最近的基于迭代编译方法进行优化顺序搜索的典型代表.采用Features ANN和现有迭代编译方法为NPB测试集、大型科学计算程序在平台1和平台2上预测优化顺序时,预测模型性能如图8和图9所示.其中,GraphDSE表示Nobre等人[10]提出的基于图形的优化顺序预测模型,ClusterDSE表示Martins等人[11]提出的基于聚类的预测模型,Features ANN表示本文提出的预测模型.
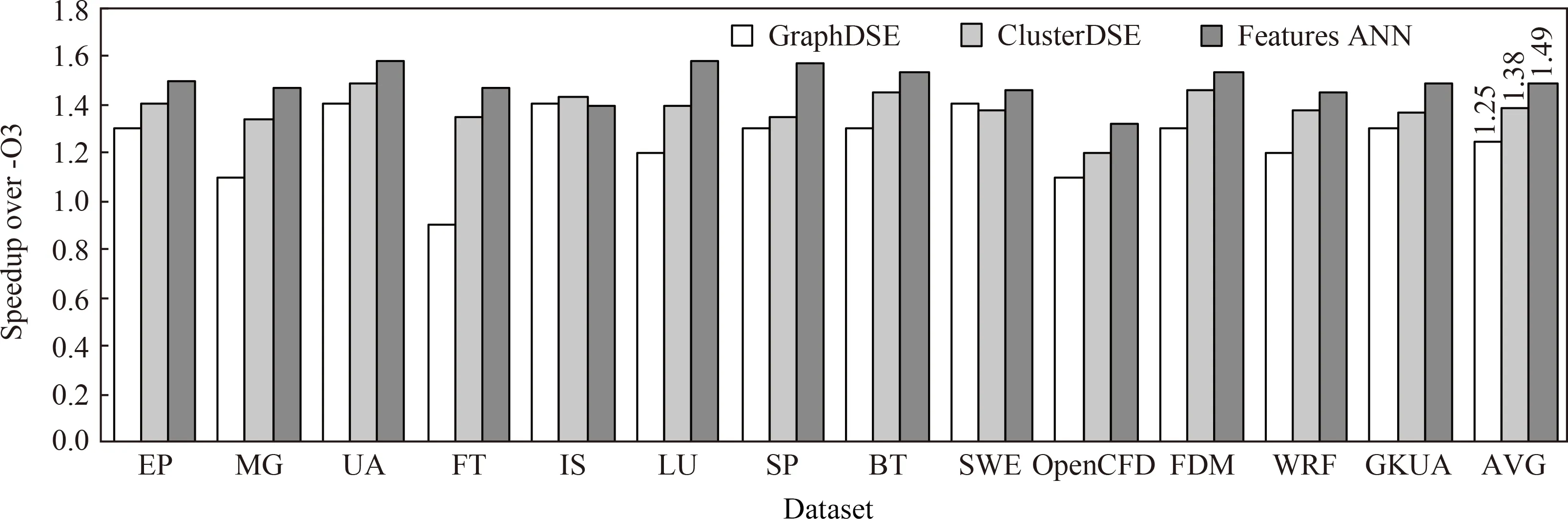
Fig. 8 Comparison with iterative compilation (platform 1)图8 Features ANN与迭代编译方法的性能比较(平台1)

Fig. 9 Comparison with iterative compilation (platform 2)图9 Features ANN与迭代编译方法的性能比较(平台2)
从图8可以看出,平台1上基于迭代编译方法为测试集预测优化顺序时,Features ANN,GraphDSE,ClusterDSE相对于GCC标准优化级别-O3的平均加速比分别为1.49,1.25,1.38.对当前测试用例而言,Features ANN具有最好的预测性能,ClusterDSE次之,GraphDSE具有相对较低的预测性能.经程序分析可知,测试集UA的主要热点函数为laplacian,占程序执行时间的40%.Features ANN为laplacian函数预测的优化顺序为{O2,-fpredictive-commoning,-funswitch-loops,-fpeel-loops,-ftree-loop-distribution,-ftree-vectorize,-ffast-math}.GraphDSE为laplacian预测的优化顺序为{-O2,-fpredictive-commoning,-funswitch-loops,-ftree-loop-distribution,-ftree-vectorize,-fpeel-loops}.ClusterDSE为laplacian预测的优化顺序为{-O2,-fpredictive-commoning,-funswitch-loops,-fpeel-loop,-ftree-loop-distribution,-ftree-vectorize}.采用GCC-O3默认优化、Features ANN、GraphDSE、ClusterDSE时对应的函数执行时间分别为43.87 s,38.57 s,43.19 s,42.50 s.由于函数laplacian中含有多个完美嵌套循环,且不含阻止向量化的依赖环,适合做向量化处理.Features ANN预测的优化顺序除使用标准优化级别-O2外,在为函数进行向量化处理前使用预测常见优化、分支外提,循环剥离与分布等优化.在进行向量化处理后调用快速数学库优化,打开-ffast-math,实验表明在精度要求不苛刻的情况下使用这种激进的优化方式可以获得较大的性能提升.而ClusterDSE预测的优化顺序没有使用-ffast-math,程序性能略差于Features ANN.GraphDSE预测的优化顺序在优化选择上与ClusterDSE相同,但优化顺序不同,即在向量化后进行循环剥离,从而导致一些可以使用循环剥离的循环体失去了向量化的机会.
从图9可以看出,平台2 Features ANN,GraphDSE,ClusterDSE相对于GCC标准优化级别-O3的平均加速比分别为1.41,1.16,1.22.Features ANN获得了最好的预测性能.因此,Features ANN优化顺序预测模型在2种平台上都获得了平均最佳的预测性能.Features ANN能够获得较好程序性能的原因在于模型基于机器学习算法构建,能在较短的时间内生成新程序的最佳优化顺序.而使用现有迭代编译方法为新程序搜索最佳优化顺序时,虽然现有方法在优化搜索性能和搜索时间上具有较大的改进,但仍需要进行多次迭代才能获得局部最佳程序性能.
5.3 Features ANN与非迭代编译方法的比较
非迭代编译方法的典型代表是基于机器学习的编译优化方法和基于多面体模型的编译优化方法,本文选择与Ashouri等人[24]和Park等人[25]的研究进行对比分析.Ashouri等人[24]提出COBAYN优化顺序预测模型,COBAYN是基于贝叶斯网络构建的优化顺序预测模型.Park等人[25]基于多面体编译框架,采用静态程序特征和几种不同的机器学习算法构建优化顺序预测模型.采用Features ANN和现有非迭代编译方法预测优化顺序时,预测模型性能如图10和图11所示.其中,COBAYN表示Ashouri等人[24]提出的优化顺序预测模型,LR和SVM表示Park等人[25]基于多面体框架通过逻辑回归和支持向量机构建的预测模型,Features ANN表示本文提出的优化顺序预测模型.
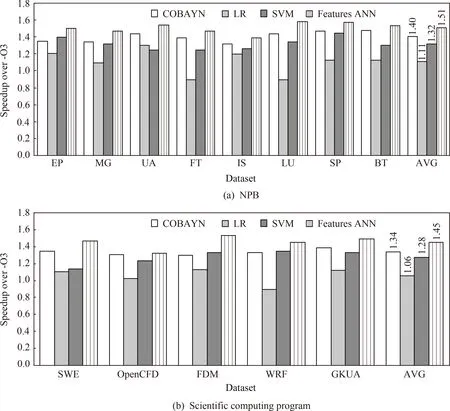
Fig. 10 Comparison with non-iterative compilation (platform 1)图10 Features ANN与非迭代编译方法的性能比较(平台1)

Fig.11 Comparison with non-iterative compilation (platform 2)图11 Features ANN与非迭代编译方法的性能比较(平台2)
从图10可以看出,平台1上基于非迭代编译方法为NPB测试集和大型科学计算程序预测优化顺序时,Features ANN相对于GCC标准优化级别-O3的平均加速比分别为1.51和1.45,COBAYN的平均加速比分别为1.40和1.34,LR的平均加速比分别为1.11和1.06,SVM的平均加速比分别为1.32和1.28.从图11可以看出,平台2上基于非迭代编译方法为NPB测试集和大型科学计算程序预测优化顺序时,Features ANN相对于GCC标准优化级别-O3的平均加速比分别为1.39和1.43,COBAYN的平均加速比分别为1.30和1.32,LR的平均加速比分别为1.03和1.05,SVM的平均加速比分别为1.24和1.23.对当前测试用例而言,Features ANN具有最好的预测性能,COBAYN次之,SVM的预测性能低于COBAYN,LR具有相对较低的预测性能.Features ANN能够获得较好预测性能的原因在于模型采用PCA特征降维技术,选择最主要的程序特征作为预测模型的输入.COBAYN采用探索性因子分析法选择程序特征,然而在实际应用中探索性因子分析必须和验证性因子分析结合使用,才能更好地进行因子分析.LR和SVM均采用固定的程序特征,缺乏程序特定性.此外,Features ANN基于ANN根据当前状态下的程序特征选择最佳优化,而现有方法对整个程序优化前的特征进行抽取和预测优化,Features ANN的预测精度更高.
5.4 离线学习和在线预测时间开销比较
使用Features ANN预测模型为新程序预测优化顺序时的细粒度时间,分为训练阶段(离线完成)和预测阶段(在线完成).训练阶段一次性完成,收集训练数据所需时间,取决于训练集中应用程序数量.表4和表5分别表示平台1和平台2上SPEC CPU作为训练集、WRF作为目标应用程序时不同预测模型每个特定阶段所需时间.采用本文提出的方法虽然需要若干天时间进行数据收集和模型训练,但对于新的目标程序需要很短的时间就可以完成较好的优化参数预测.
实验结果表明,Features ANN预测模型的离线学习时间略高于现有方法,但在线预测时间低于现有方法.而且从5.1节和5.3节的分析中可以看到,Features ANN在特征选择、预测性能等方面均优于现有方法.因此,Features ANN在特征选择、预测性能和在线预测时间开销等方面均取得了较好的效果.
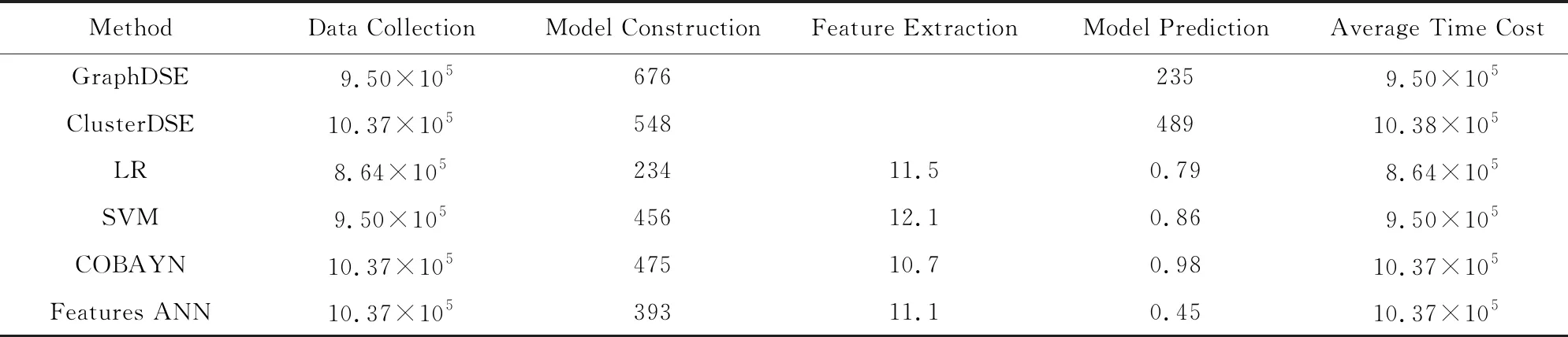
Table 4 Learning and Prediction Time of WRF (Platform 1)表4 WRF离线学习和在线预测时间(平台1) s

Table 5 Learning and Prediction Time of WRF (Platform 2) 表5 WRF离线学习和在线预测时间(平台2) s
6 结束语
本文提出一种选择编译器优化顺序的新方法:Features ANN,以最大化目标应用程序性能.该方法通过使用动静结合的特征表示方法进行程序表示,在最小均方误差意义下获取对原始特征数据的表示.基于程序特征和当前状态最佳优化构成优化顺序预测模型的样本数据,采用人工神经网络建立统计模型并集成于编译器框架,实施优化顺序选择及进行编译过程驱动.在2种平台上采用动静结合特征作为Features ANN预测模型输入时,相对于GCC 5.4编译器默认标准优化级别-O3分别获得1.49x和1.41x的程序执行时间加速.与现有迭代编译方法GraphDSE和ClusterDSE,及非迭代编译方法COBAYN,LR,SVM比较时,均获得了最佳的性能提升.
程序优化顺序选择是提升程序性能的关键技术,目前仍有一些后续工作值得研究,具体来说包括:1)我们将考虑增加更多的训练数据集、测试数据集和目标平台,以进一步提升预测准确率和通用性.2)由于不同的程序优化可能需要不同的目标代码特征,我们将研究更多优化变换的相关性特征,进一步提升程序性能.3)尝试人工添加噪声的方法增加预测方法的鲁棒性,研究在负载严重的多用户环境下提升预测性能.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
计算机研究与发展(2021年3期)2021-04-01
电脑爱好者(2020年6期)2020-05-26
计算机与网络(2019年9期)2019-10-21
人大建设(2019年12期)2019-05-21
瞭望东方周刊(2017年42期)2017-12-05
环球时报(2017-03-30)2017-03-30
