
基于生成式对抗网络的结构化数据表生成模型
2019-09-16 02:32宋珂慧张江伟袁晓洁
计算机研究与发展 2019年9期
宋珂慧 张 莹 张江伟 袁晓洁
1(南开大学计算机学院 天津 300350)2(新加坡国立大学计算机学院 新加坡 117417)
近年来,在机器学习和数据库等领域,高质量数据集的合成问题一直以来是一个非常重要且充满挑战性的问题[1-2].合成的高质量数据集可用于很多场景,例如数据库性能基准测试(performance bench-marking)、降低数据挖掘成本以及改进模型训练过程等.其中,合成的高质量数据集可用来提升模型,尤其是深度学习模型的训练过程.
在训练某个机器学习模型的过程中,当训练样本数量不足时,很容易出现过拟合[3]现象.过拟合现象往往由训练样本数量不足引起,导致模型中的复杂参数只能捕捉训练样本中十分具体的随机特征,导致一些细微的误差都会对其产生巨大影响,因此在训练的过程中会出现模型在验证集上表现变差的现象.图1展示了分类器多层感知机(multi-layer perception, MLP)在数据集“Poker Hand”上的预测准确率曲线,从图1两条曲线的走向可以看出,在迭代6次之后,在训练集上的准确率尽管稳步上升,但在验证集上的准确率已经开始下降,也就是出现了过拟合现象,2条曲线之间的区域大小反映了过拟合现象的严重程度.

Fig. 1 An example of model performance图1 模型训练过程中的预测准确率
为了防止过拟合现象发生,需要将原有的训练集扩大.其中一种方法是领域专家手动标注更多的数据样本,但这既浪费人力又容易出错;另一种自动合成更多数据样本的方法更为可行.如图2所示,原始训练样本首先作为生成器(generator)的输入,生成器输出的合成训练样本和原始训练样本一起组成扩大后的训练集,最终将这个扩大后的训练集用于分类模型的训练.由于合成数据集质量较高且保留了原始数据样本中的重要特征,用扩大后的样本对分类模型进行训练的过程将更加稳定,并能够解决因训练样本不足引起的过拟合问题,提升了分类模型在验证集上的准确率.因此,设计一个性能良好的生成器是图2所示整个工作流程的重要环节.
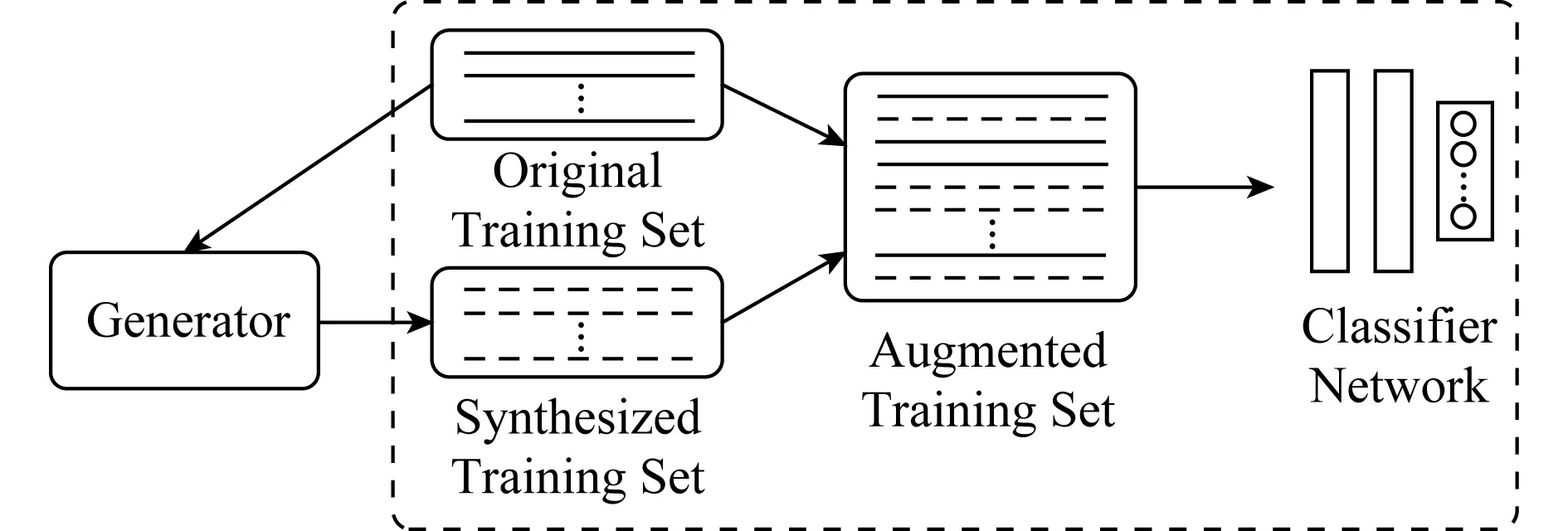
Fig. 2 The workflow of training classifiers using synthesized datasets图2 使用合成数据集训练分类模型的流程图
近年来,有不少与生成模型相关的研究[4-7],其中备受瞩目的是生成式对抗网络(generative adversarial network, GAN)[8].生成式对抗网络是Goodfellow等人[8]在2014年提出的一种生成模型,并被广泛应用于对原始样本分布特征的无监督式学习.目前为止,有不少针对GAN的相关研究,并衍生出若干GAN模型的变种,如C-GAN[9]和AC-GAN[10]等,都能够生成高质量的图片数据.
关系数据库中不具有主外键约束的单表被称为结构化数据表.结构化数据表包含若干属性,每个属性有自己特有的分布,属性间也有或强或弱的相关性,例如身高和体重正相关,身高越高的个体,体重就越大.属性的取值具有无序性(与结构化数据表中每条记录所处的位置无关)、取值离散等特点,与图片数据不尽相同.因此,GAN及其若干变体都无法直接用于结构化数据表的生成.为了解决这个问题,本文主要提出了一个基于生成式对抗网络的结构化数据表生成模型,称为TableGAN.
该模型为传统生成式对抗网络模型GAN的一种变体,由一个生成器(generator)模型G和一个判别器(discriminator)模型D组成.生成器G的目的是尽量学习原始数据的真实分布,生成让判别器甄别不出真伪的合成数据,而判别器D的目的是尽量提升自己甄别原始数据与合成数据的判别能力.2个模型在相互对抗优化的过程中,不断提升各自的生成能力与判别能力.最终,生成器能够生成符合原始数据分布特征的合成数据,和原始数据一起用于分类模型的训练,从而解决由于训练样本不足导致的过拟合问题.和其他传统生成式对抗网络不同的是,TableGAN修改了优化函数,保证了模型有一个稳定的训练过程,并且为了防止噪声对模型稳定性的影响,在生成器模型和判别器模型中都添加了L2正则化项,还增大了输入噪声的多样性,在一定程度上避免了模式崩溃(mode collapse)情况的发生.据我们所知,TableGAN模型是生成式对抗网络在结构化数据表生成领域的首次应用.
为了证明TabelGAN的有效性,本文提供了在2个数据集上,针对3种分类器网络的一系列实验结果和相关分析.充分的实验表明TableGAN能够生成有助于提升分类器网络训练的数据样本.为了更好地展示TableGAN生成数据的效果,我们选择了一个在数据挖掘比赛网站Kaggle(1)https://www.kaggle.com/c/sf-crime/discussion/15836上排名最靠前的分类模型,实验证明使用合成的数据集训练后,分类模型的准确率仍可以进一步提升.
1 相关工作
数据合成在机器学习和数据库等领域有着十分重要的应用[11-13].其中一个在机器学习领域的应用就是利用合成的数据来解决过拟合问题.过拟合问题在机器学习领域存在已久,是一个亟待解决的问题.近年来,有不少学者提出对这个问题的解决方案,包括合成更多的训练样本[14]、交叉验证(cross-validation)[15]、正则化(regularization)[16]和提前停止(early stopping)[17]等方法.其中,合成更多的训练样本是最常使用的方法之一.
在计算机视觉领域,合成更多训练样本这一技术通常被称为数据增强(data augmentation).为了得到更多的训练样本,需要对原始训练图像进行简单的几何和外观方面的转换,包括对图片进行旋转、扭曲等,但是这些转换都基于一个很强的假设,即这些细微的物理转换都不会改变图片的类别标签.由于此假设没有相关的理论证明,这种通过物理转换来扩大训练集的方法具有一定的局限性.
生成模型是近年来机器学习领域最有前景的方法之一,它通过学习并遵从给定数据集的概率分布来生成新的样本数据.其中变分自动编码器(variational auto-encoders, VAE)[6]和生成式对抗网络(GAN)[8]是生成模型中众所周知的代表.
VAE是一个概率图模型,由一个编码器(encoder)和一个解码器(decoder)构成,编码器将数据分布的高级特征映射到数据的低级表征(latent vector),解码器接受数据的低级表征,然后输出同样数据的高级表征.VAE的训练过程完全依赖于一个假设损失函数及KL散度,使得生成的数据尽可能去接近真实数据的分布.
然而,GAN为我们提供了一个对目标函数更为灵活的定义,其中包括Jensen-Shannon[8]、所有的f-divergences[18]以及一些其他距离度量的组合[19].GAN由一个生成器G和一个判别器D组成,它们均由深度学习网络实现.生成器和判别器相互对抗进行训练,生成器尽可能生成与原始数据分布相近的数据集,使判别器无法将其与原始数据区分,而判别器则尽可能提升自己区分原始数据与合成数据的能力.经过一段时间的对抗训练后,生成器能够生成接近原始数据分布的样本,用于解决由于训练样本不足导致的过拟合问题.GAN被证明训练难度大且十分不稳定[20],因此不少学者提出了GAN的若干变体,用于改进生成数据的质量.例如,C-GAN[9]将条件信息,即类标签,添加到生成器模型输入中,用于改进原始GAN模型.AC-GAN[10]中的判别器不仅要判别输入数据来自原始数据还是合成数据,还要判别输入数据的类别标签.本文提出了GAN模型的另一个变体TableGAN,用于生成高质量的结构化数据表,并将其用来训练分类模型以改善模型的训练过程.
2 算法实现
本节主要介绍文中所提出算法的模型推导和理论分析,首先对模型训练过程发生的过拟合现象进行形式化定义和描述,然后回顾生成式对抗网络的基本原理,最后给出基于GAN的结构化数据表生成模型TableGAN中算法的相关理论分析,包括模型推导、算法伪代码等.
2.1 问题定义
给定一个带标签的训练集Y={yn}N,其中yn=(xn,cn),cn∈{1,2,…,M}是第n行数据的标签,xn是除了标签之外的其他属性.训练一个神经网络的基本目标是,用给定训练集去估计模型中的所有参数:
(1)
结合贝叶斯公式:
p(θ|y)=p(θ|x,c)∝p(θ)p(x|θ)p(c|x,θ).
(2)
假设所有的训练样本均为条件独立,可以得到:
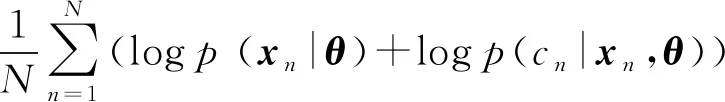
,
(3)
其中,p(θ)为模型所有参数的先验概率,p(xn|θ)是对样本xn的似然估计,p(cn|xn,θ)是对标签cn在给定xn和θ条件下的似然估计.
在训练神经网络时,模型中所有参数通过梯度下降的方式找到最优解.然而,当训练样本Y数量不足时,往往会出现过拟合现象.也就是说,尽管模型在训练集上效果很好,但在验证集上效果却很差.因此,我们需要合成更多高质量的训练样本,这些新合成的样本需要保留原始训练样本的重要特征,使扩大后的样本能够更好地训练模型中的参数.本文提出了一个基于生成式对抗网络的结构化数据表生成模型——TableGAN,用来扩大原有的训练样本并保留原始样本中的重要特征,为后续神经网络的稳定训练提供良好保障.
2.2 生成式对抗网络GAN
生成式对抗网络GAN是Goodfellow等人[8]在2014年提出的一种生成模型,目前已经成为人工智能学界一个热门的研究方向.GAN的基本思想源于博弈论中的二人零和博弈,即二人的利益之和为零,一方所得正好为另一方所失.因此,GAN由2个相互博弈的神经网络模型组成,一个叫生成器G,另一个叫判别器D.生成器G的目的是尽量学习原始数据的真实分布,生成让判别器甄别不出真伪的合成数据;而判别器D的目的是尽量提升自己甄别原始数据与合成数据的判别能力.2个模型在相互对抗优化的过程中,不断提升各自的生成能力与判别能力,这个学习优化过程就是寻找二者之间的一个纳什均衡.在训练优化一段时间之后,生成式对抗网络的生成器能够捕捉原始数据的真实分布,并生成一系列符合同一分布的合成数据样本.
生成器为了捕捉原始数据x的真实分布pg,使用一个映射函数(一般由深度神经网络实现),将一个已知的分布p(z),例如高斯分布,映射到另一个数据空间G(z,θg),其中z称之为噪声(noise),θg表示生成器模型中的所有参数.生成器的目标是尽量缩小G(z,θg)与真实数据分布pdata(x)之间的差异.对于判别器模型来说,通过输出0或1来表示判别器对输入数据真假的判别情况.当输入数据采样于原始数据pdata(x)时,判别器输出为1;而当输入数据采样于合成数据集G(z),也就是从生成器中输出的数据时,判别器输出为0.
在GAN的训练过程中,生成器模型和判别器模型进行相互对抗来进行优化,因此对G和D进行交替式训练.对于G而言,需要最小化log(1-D(G(z))),也就是尽可能让G合成的数据集G(z)能够欺骗D,使得判别器D的输出D(G(z))接近1.然而对判别器D而言,需要增强自己判别真假数据的能力,即最大化logD(x)与log(1-D(G(z))),也就是当输入数据为真实数据x时,判别器的输出D(x)尽可能接近1,而当输入数据为合成数据G(z)时,判别器的输出D(G(z))尽可能接近0.因此,GAN的优化问题是一个极小-极大化问题,GAN的目标函数可以描述为
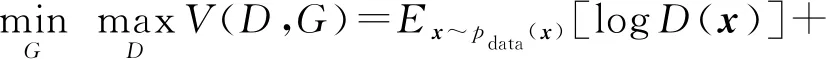
.
(4)
2.3 结构化数据表生成模型TableGAN
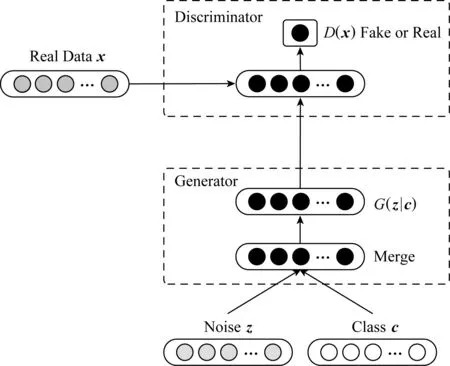
Fig. 3 The structure of our TableGAN图3 TableGAN模型示意图
本节主要介绍基于GAN的结构化数据表生成模型TableGAN.图3给出了模型TableGAN的示意图,TableGAN由一个生成器G和一个判别器D组成,符合某种分布的噪声z与类标签c一起作为生成器G的输入,经过G的变换后生成合成数据样本G(z|c),随后与真实数据样本x一起作为判别器D的输入,判别器的最终输出又会进一步指导生成器网络的训练过程.
生成器网络与判别器网络均由深度神经网络实现,生成器网络和判别器网络中的所有参数分别由θ与γ表示.2个网络相互对抗进行训练,目标函数为
(5)
式(5)与传统GAN模型的目标函数对比而言,增加了类别标签c作为生成器的输入,即给生成器额外的信息指导其更好地生成数据.然而在训练的过程中,使用式(5)作为目标函数易出现生成器梯度消失现象,从而导致模型极难训练,文献[21]中有相关理论证明.因此,TableGAN模型使用Earth-Mover(EM)距离来衡量原始样本与合成样本之间的距离,即使2个分布没有重叠或重叠的部分非常少,依然能够反映2个分布的远近,EM距离定义为
(6)
其中Π(P1,P2)为P1和P2所有可能的联合分布,计算在此联合分布下样本对距离的期望,此期望的下界就是EM距离.因此,使用EM距离后的目标函数为

(7)
传统GAN模型在训练过程中往往会发生模式崩溃(mode collapse)的现象,这指的是模型只能捕捉并保留原始数据中很少的一部分特征,以致生成的数据样本十分单一.我们的TableGAN则针对这个问题,使用3个技巧来缓解模式崩溃的现象:1)增加生成器输入噪声z的多样性.对图片数据集来说,传统GAN模型生成器的输入噪声服从单峰的正态分布,而对于本文需要生成的结构化数据表来说,输入多峰分布的噪声能够增加合成数据的多样性;2)我们放弃基于动量的优化方法,例如Adam,而使用RMSProp[22-23];3)在神经网络模型上增加L2正则化项,保证TableGAN训练过程中的稳定.
TableGAN的训练过程如算法1所示,针对参数θ与γ,使用式(7)给出的目标函数来分别交替训练生成器网络与判别器网络,训练过程收敛后会得到:
(8)
此时,判别器Dγ*已经收敛,θ*也已收敛于V(D,G)的最小值,模型已经训练至稳定状态.之后,我们使用模型中已训练好的生成器,生成更多的训练样本,用于分类模型的训练过程.
算法1.TableGAN训练算法.
输入:学习率(learning rate)η、剪切参数(clipping parameter)d、批大小(batch size)m、生成器每迭代1次时判别器迭代的次数nd;
输出:收敛后生成器网络和判别器网络的参数θ与γ.
① WHILE 不收敛 DO
② FORt=0,1,2,…,nd



⑥γ←γ-η×RMSProp(γ,gγ);
⑦γ←clip(γ,-d,d) ;
⑧ END FOR
在2.3单因素试验结果上,对四氢呋喃用量(X1)、KOH 甲醇溶液质量浓度(X2)、提取温度(X3)3 个因素进行响应曲面试验设计。设响应曲面因素与水平及编码值见表2,响应曲面法优化稻谷中叶黄素提取方法见表3。
3 实验与分析
本节主要介绍相关实验设置,包括实验所使用的数据集、分类模型以及用于比较的基准算法,之后给出实验结果并对其进行分析与讨论.实验代码已更新至GitHub(2)https://www.kaggle.com/c/sf-crime/data
针对每个数据集,我们采取3个实验步骤:
1) 使用原始训练样本对分类模型进行训练,在测试集上得到分类模型预测准确率;
2) 使用原始训练样本,对数据库领域结构化数据表扩展方法Dscaler、数据匿名化方法k-anonymity与t-closeness、生成式对抗网络C-GAN和我们的模型TableGAN进行训练,随后使用训练好的模型生成合成的数据集,与原始训练样本一起组成了扩大后的数据集;
3) 使用步骤2中扩大后的数据集进行训练,在测试集上得到分类模型的预测准确率,和步骤1中得到的准确率进行比较.
3.1 数据集
本文使用2个公开的数据集用于实验.一个是数据挖掘比赛网站Kaggle上公开的数据集(3)http://archive.ics.uci.edu/ml/datasets/Poker+Hand,另一个是机器学习仓库UCI(4)https://www.kaggle.com/c/sf-crime/discussion/15836上公开的数据集,表1提供了2个数据集的统计信息.

Table 1 Summaries of the 2 Datasets表1 实验数据集统计信息
1) SF Crime.本数据集收集了旧金山市近12年来的犯罪记录,共有9个不同的属性,其中属性“Category”为标签,共有39种不同的取值.分类模型需要根据犯罪事件发生的时间与地点来预测犯罪的种类.表2提供了此数据集的详细信息.
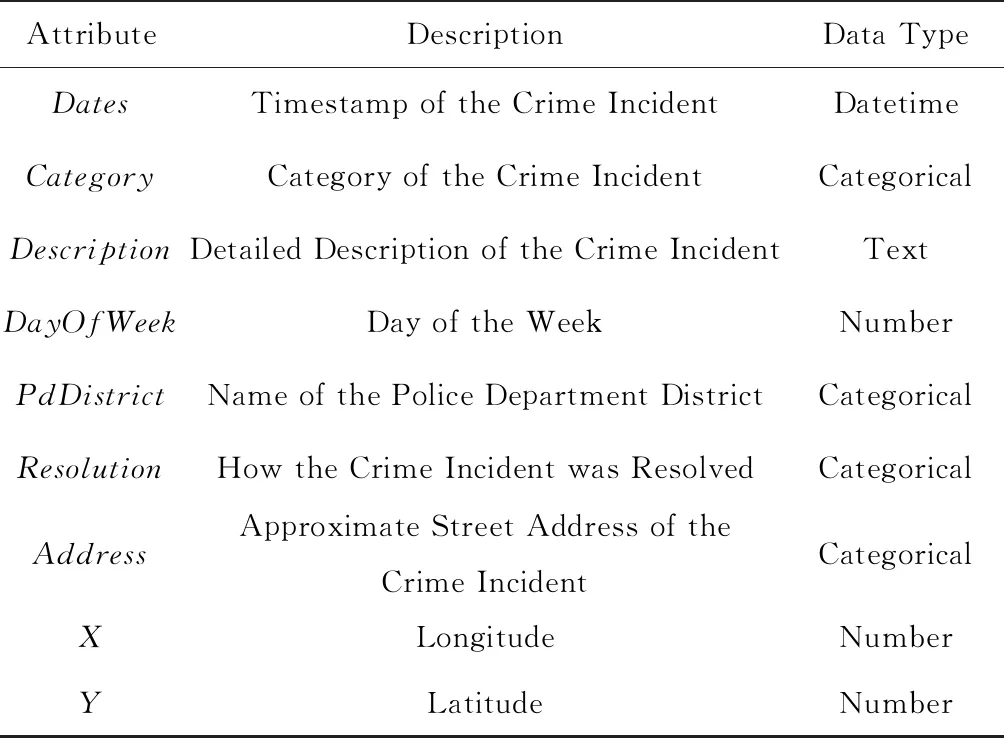
Table 2 Summaries of the SF Crime Dataset表2 关于SF Crime数据集的描述
2) Poker Hand.本数据集记录了从52张扑克牌中抽出5张扑克牌的大小与花色,共有11个不同的属性,其中属性“Class”为标签,共有10种不同的取值,包括“同花顺”、“同花”、“顺子”等.分类模型需要根据5张扑克牌的大小与花色来预测牌型.表3提供了此数据集的详细信息.
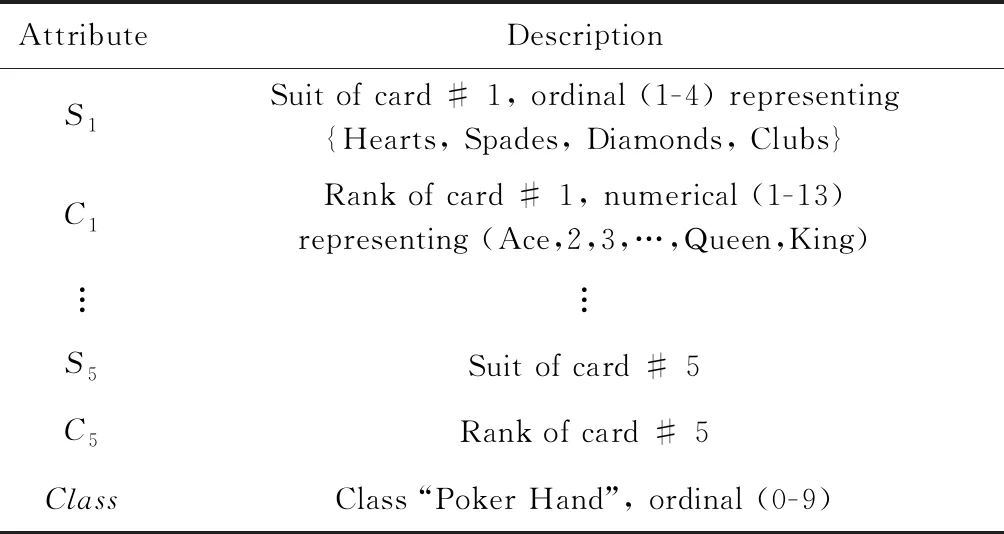
Table 3 Summaries of the Poker Hand Dataset表3 关于Poker Hand数据集的描述
3.2 分类模型
1) MLP.这是引言提到的在数据挖掘比赛网站Kaggle③上排名最靠前的分类模型,它是一个3层神经元感知器,在SF Crime数据集下,这个分类模型的性能在所有的公开算法中排名前1%.
2) RF.随机森林是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(ensemble learning)方法,其输出的类别由个别树输出的类别的众数而定.也就是说,对于一个输入样本,N棵树会有N个分类结果,而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出.
3) DT.决策树是一种基本的分类方法.决策树模型呈树形结构,表示基于特征对实例进行分类的过程.它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布,具有可读性、效率高等优点.
本文模型TableGAN由高层神经网络API——Keras来实现,基于TensorFlow后端.针对每个数据集,TableGAN根据Epochs和D_iters这2个参数的不同取值,生成17份不同的合成数据样本.其中,Epochs反映了模型的学习程度,如果训练时的Epochs过小,由于特征学习不够充分,生成的合成数据集不足以大幅提高分类模型的预测准确率,反之,如果Epochs过大,模型会学习数据中过于具体的特征,依旧会影响分类模型的预测准确率,本实验Epochs的取值在20~90之间.D_iters反映了模型中判别器相对于生成器的迭代次数,即每当生成器迭代1次时判别器迭代的次数.例如D_iters=5表明每当模型生成器训练1次时判别器训练5次.此参数表明维持生成器和判别器这2个模型训练程度的动态平衡具有十分重要的意义.
3.3 基准算法
本文采用10折交叉验证的方式对提出的TableGAN算法和4个方法在2个数据集上进行了实验,并将结果进行了比较和分析.
1) Without scaling up. 未采用任何生成模型,使用原始训练样本对分类模型进行训练.
2) Dscaler[24]. 数据库领域较新的结构化数据扩展方法Dscaler,一般针对多张具有主外键关系的结构化数据表,旨在保留主外键间参照关系.而单个结构化数据表的扩展方法,只是简单在数据表中进行采样,以此合成新的数据集.
3) Anonymization. 采用数据匿名化方法k-anonymity与t-closeness结合.参数k∈{2,10,100},t∈{0.001,0.1,0.5},表4的实验结果取这些参数下最高的准确率值.
4) C-GAN[9]. C-GAN是传统生成式对抗网络的一种变体,通过增加额外信息来提升合成数据的质量.其在图片数据集MNIST上表现良好,能够根据标签生成高质量的图片.
5) TableGAN为本文提出的算法.
3.4 实验结果分析
本节通过比较使用扩大后的训练集与原始训练集对分类模型的训练情况来证明TableGAN的有效性.我们使用训练后的分类模型在验证集上的预测准确率来量化TableGAN合成数据的质量.表4呈现了在2个数据集上的所有实验结果.可以看出,TableGAN在大部分情况下都可以改进分类模型的训练情况,并且比Dscaler,Anonymization,C-GAN这3个模型表现要好.3.4.1和3.4.2节有对实验结果详细的对比分析,并根据Epochs和D_iters这2个参数的变化情况绘制了分类模型对应的预测结果图.
Continued (Table 4)
Notes:“” means the corresponding classifiers using the augmented training data produced by data anonymization algorithms (k-anonymity+t-closeness); “” means the classification results of data produced by Dscaler; “*” means the classification results of data produced by C-GAN;“” means the classification results of data produced by our TableGAN. The best results have been highlighted in bold.

Fig. 5 Performance comparison using Random Forest classifier on SF Crime dataset图5 使用随机森林在数据集SF Crime上的性能对比
3.4.1 SF Crime数据集上效果对比
图4展示了在SF Crime数据集上应用分类模型MLP的实验结果.其中,TableGAN的性能一直优于C-GAN的性能,即使这个分类模型已经是在此数据集下性能排名前1%的分类器,TableGAN依旧可以通过扩大训练样本的方式,进一步提升分类模型的预测准确率.而数据隐私算法扩大后的数据集,由于隐藏数据中部分重要特征,训练分类模型的准确率还不如原始训练样本对分类模型进行训练的准确率.
图5和图6分别展示了在分类模型随机森林和决策树下的实验结果.尽管这2个传统分类模型的学习能力不如MLP强,也就是过拟合现象不够显著,但TableGAN依旧能够提升分类模型的准确率,TableGAN的表现也优于C-GAN模型的表现.
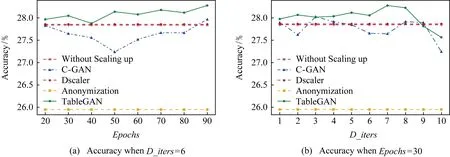
Fig. 4 Performance comparison using MLP classifier on SF Crime dataset图4 使用MLP在数据集SF Crime上的性能对比
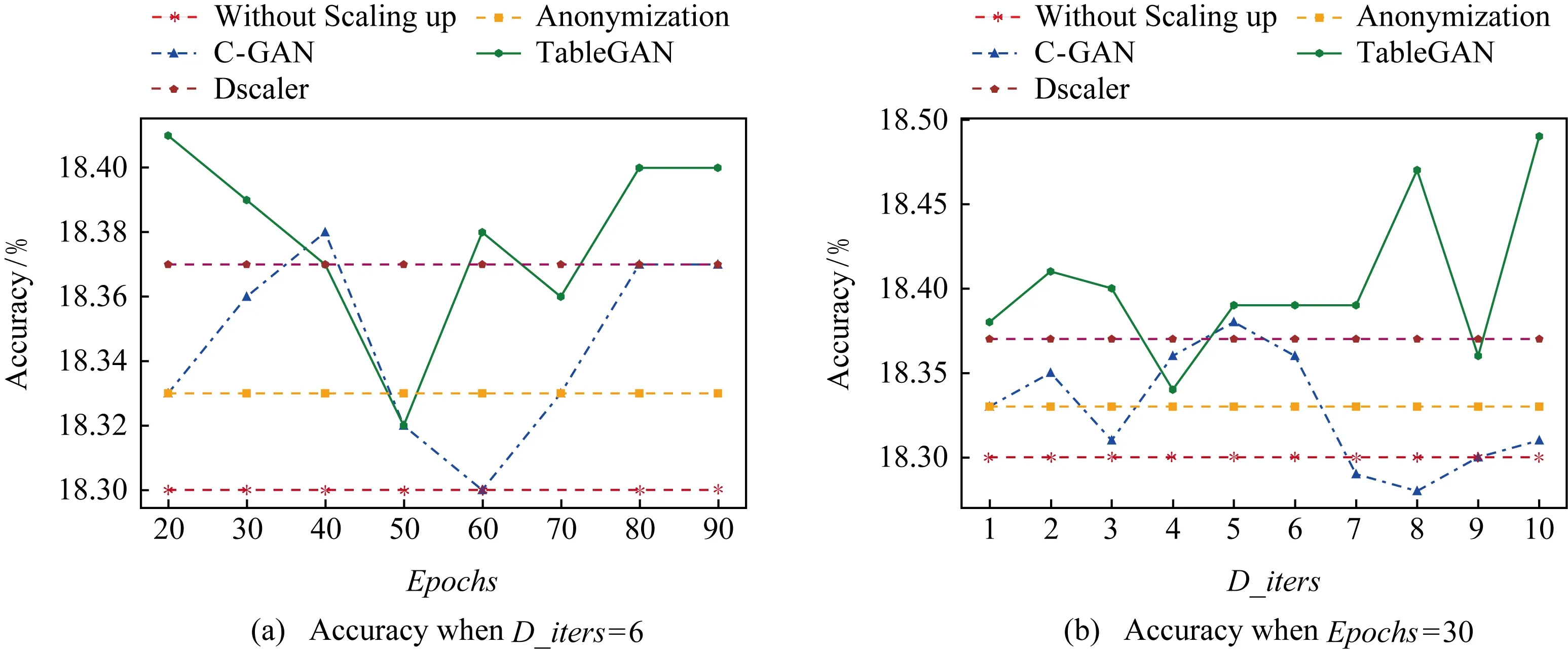
Fig. 6 Performance comparison using Decision Tree classifier on SF Crime dataset图6 使用决策树在数据集SF Crime上的性能对比
为更好地证明本文方法TableGAN在数据集SF Crime上的优越性,使用配对样本t检验.显著性检验表明,TableGAN在置信区间为0.95的情况下,性能优于其他所有算法.

Fig. 7 Performance comparison using MLP classifier on Poker Hand dataset图7 使用MLP在数据集Poker Hand上的性能对比
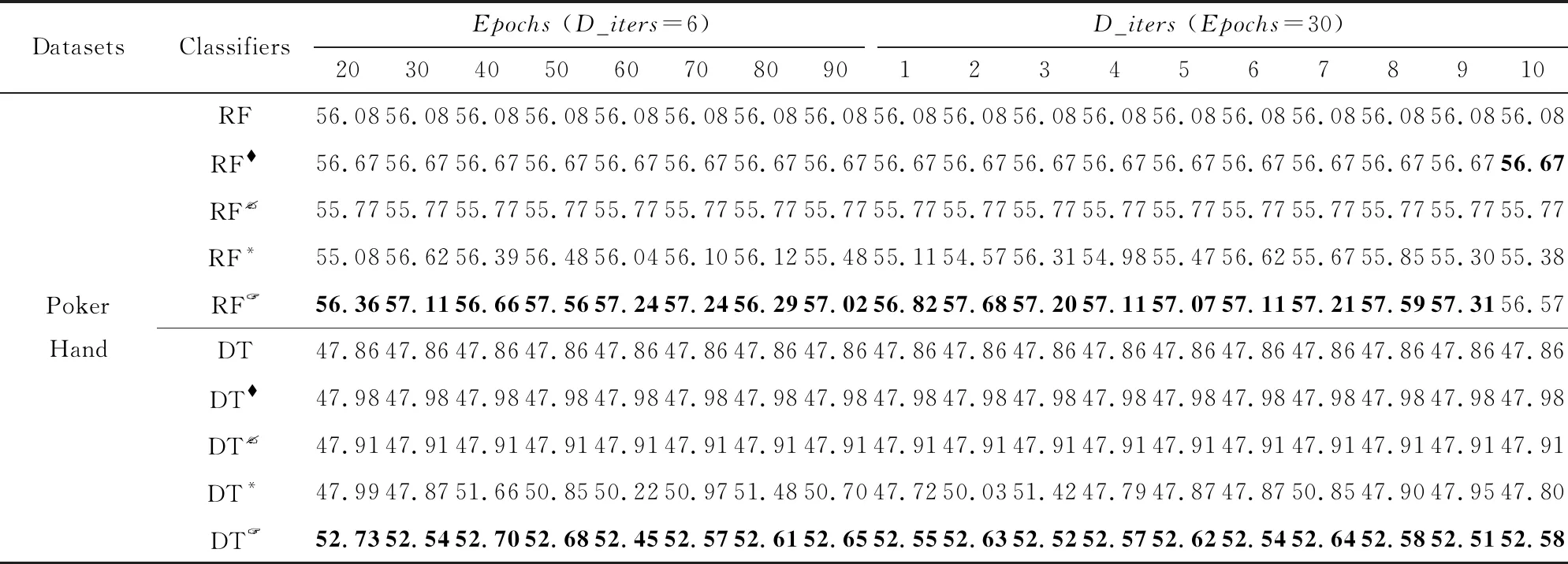
3.4.2 Poker Hand数据集上效果对比
图7展示了在Poker Hand数据集上应用分类模型MLP的实验结果.可以看出使用TableGAN扩大原始训练样本之后能够大幅提升分类模型的准确率,并且TableGAN比C-GAN有着更好的性能.当TableGAN训练30轮,且每当生成器训练一次后判别器被训练6次时,TableGAN提升分类模型的性能最显著,准确率由原来的54.71%提升至60.16%.通过观察分类模型训练过程中的loss曲线,使用TableGAN扩大训练样本在很大程度上缓解了过拟合的问题.
图8和图9分别展示了在分类模型随机森林和决策树下的实验结果.使用TableGAN扩大训练样本后,能将分类模型随机森林的准确率由原来的56.08%提升至57.68%,并能将分类模型决策树的准确率由原来的47.86%提升至52.73%.从图8和图9可以看出TableGAN很大程度上提升了分类模型的预测准确率,并总比使用C-GAN的性能好.从图9可以看出,随着参数Epochs和D_iters的变化,分类模型的预测准确率变化不大(最上方的曲线较为平缓),也就是说,我们的模型TabelGAN即使没有谨慎选择参数,仍然可以生成高质量的合成数据集来改善分类模型的训练过程,反观C-GAN,参数的细微变化很大程度上影响了分类模型的准确率.
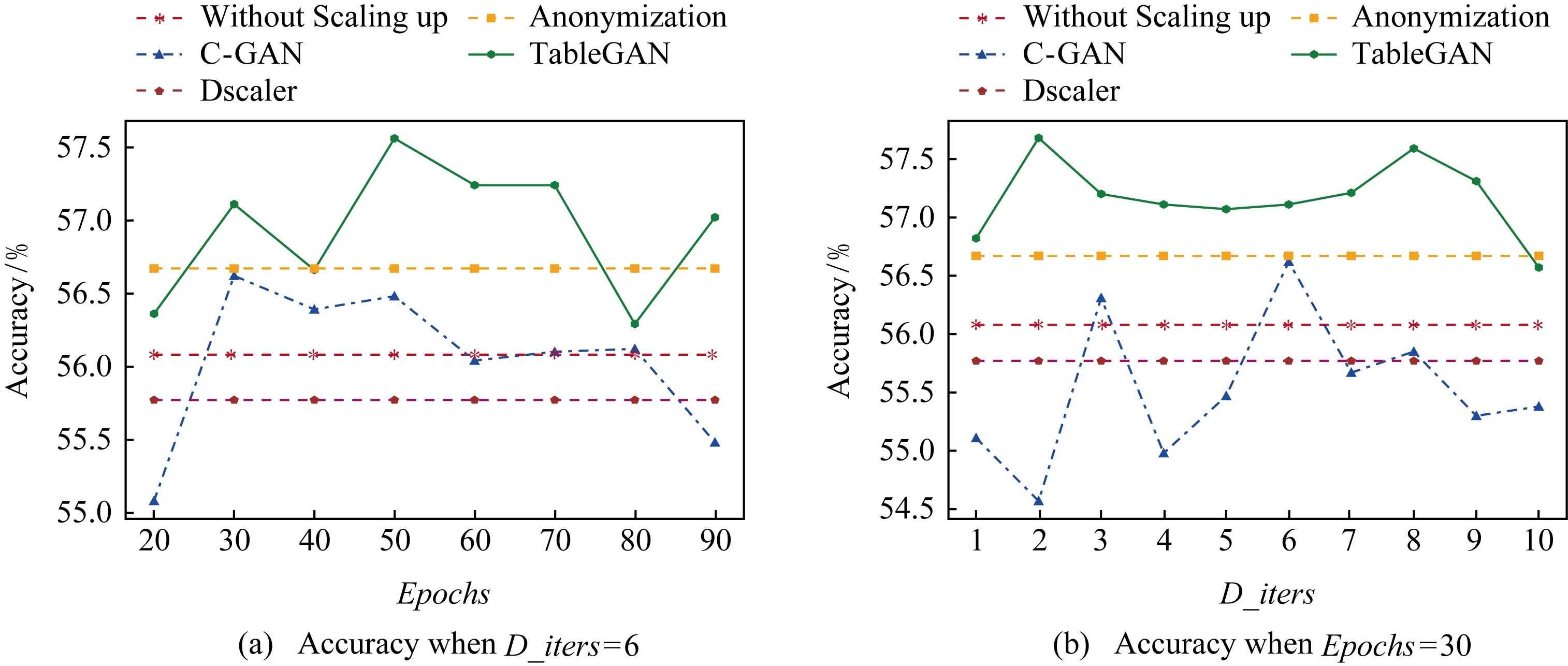
Fig. 8 Performance comparison using Random Forest classifier on Poker Hand dataset图8 使用随机森林在数据集Poker Hand上的性能对比

Fig. 9 Performance comparison using Decision Tree classifier on Poker Hand dataset图9 使用决策树在数据集Poker Hand上的性能对比
为更好地证明本文模型TableGAN在数据集Poker Hand上的优越性,使用配对样本t检验.显著性检验表明,TableGAN在置信区间为0.95的情况下,性能优于其他所有算法.
总之,通过实验可以看出我们的模型TableGAN在2个数据集上都能够生成高质量的合成数据,用于改善分类模型的训练过程,从而提升分类模型的预测准确率.
4 总结与工作展望
本文研究了结构化数据表的生成问题,提出一个基于生成式对抗网络的生成模型,生成符合原始数据样本分布的合成样本,以扩大训练样本的方式解决由于训练样本不足导致的分类模型过拟合问题.实验证明,本文提出的方法能够生成高质量的结构化数据表,进一步提高分类模型的准确率.
猜你喜欢
芜湖职业技术学院学报(2022年2期)2022-11-24
物联网技术(2020年12期)2021-01-27
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
科技创新与应用(2020年6期)2020-02-29
汽车零部件(2017年4期)2017-07-12
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
教学月刊·中学版(教学参考)(2016年5期)2016-06-14
