
社交媒体内容可信性分析与评价
2019-09-16 02:50汤小虎曹玖新
计算机研究与发展 2019年9期
刘 波 李 洋 孟 青 汤小虎 曹玖新
1(东南大学计算机科学与工程学院 南京 211189)2(东南大学网络空间安全学院 南京 211189)3(计算机网络与信息集成教育部重点实验室(东南大学) 南京 211189)
随着移动互联网以及智能移动终端的普及,新浪微博(1)http://weibo.com、Facebook(2)http://www.facebook.com、Instagram(3)http://www.instagram.com等社交媒体平台将人们的生活和互联网越来越紧密地联系在一起.由全球领先的社交媒体数字营销机构DataReportal发表的2019全球数字报告显示,全球77亿人口中活跃的社交媒体用户已经达到45%,Facebook的月活跃用户达到了22.71亿,中国的新浪微博月活跃用户也已经达到了4.46亿[1].此外,Kantar Media CIC在2017年中国社会化媒体格局概览中指出中国的社会网络如新浪微博等社交媒体平台,已经覆盖了人们生活的方方面面[2].这是因为社交媒体具有快捷、方便、双向、开放等特点,给人们消费信息带来了巨大的便利.然而,社交媒体的这些特点也使它成为了孕育不可信信息的温床.一方面由于在社交媒体中内容的发布几乎是零门槛,用户自身认识局限性导致的错误观点或者是用户出于某种目的而设计的片面新闻、虚假新闻都能轻易地发布在社交媒体平台上.另外一方面,由于社交媒体中信息的交换十分频繁,不可信的内容能够很快传播开来,覆盖大量的用户,给社会和个人带来严重的负面影响.
传统的内容可信性判断是通过人工来实现的,对于社交媒体中海量的内容,这种方法已经不可行.如今随着数据挖掘、机器学习等技术的发展,采用计算机评估内容可信性成为了主流.该方法的最大优势在于能够从全局角度去评价内容可信性,避免了人工评判中信息不对称的问题.现在大部分社交媒体平台都有自动化的信息过滤机制,如点评类网站Yelp(4)http://www.yelp.com对垃圾评论进行过滤,问答互动型网站Quora(5)http://www.quora.com会隐藏劣质答案而向用户推送最佳答案.本文将从社交媒体中用户的特点出发,考虑用户的主题因素和从众因素,提出一种基于概率图模型的方法来对社交媒体中的内容可信性进行判断.
1 相关研究综述
从20世纪90年代中期开始,互联网内容的可信性研究就成为了一个重要的研究领域[3].随着社交媒体的兴起,研究社交媒体中内容的可信性变得尤为重要.对于计算机领域中的可信性,Fogg等人[4]给出了被大部分研究者所认同的解释.他们认为可信性包含2个基本维度:可信赖度(trust worthiness)和专业度(expertise).可信赖度包含无恶意(well-intentioned)、真实(truthful)、公正(unbiased)3个方面,侧重于描述信息本身;专业度包含经验丰富(experienced)、知识渊博(know-ledgeable)、能力突出(competent)3个方面,侧重于描述信息源.
根据上述2个维度,可以将社交媒体中内容的可信性研究分为面向信息源的可信性研究和面向信息的可信性研究.考虑到传统网络媒体中内容可信性的研究方法也适用于社交媒体,本研究把传统网络媒体当作特殊的社交媒体也纳入到社交媒体内容可信性研究的讨论中,那么信息源就体现为传统网络媒体中的网站和社交媒体中的用户.信息则是网站或者用户发布于传统网络媒体或社交媒体上的多媒体内容.
面向信息源的可信性研究可以分为2类:基于网络拓扑结构的信息源可信性研究和基于信息源特征的信息源可信性研究.基于网络拓扑结构的研究以信息源为节点、信息源之间的关系为边构造网络模型,根据信息源在网络中所处的位置,对信息源的可信性进行计算.PageRank[5]算法是其中最为经典的算法,之后出现了许多基于PageRank的改进算法,比如Appleseed[6],TrustRank[7],CredibleRank[8],VoteTrust[9]等算法.基于信息源特征的研究是寻找影响信息源可信性的因素,比如信息源的活跃度、权威度、与其他信息源的关系、历史行为和信息源发布内容语义信息、传播范围、时效性等,研究这些因素如何影响信息源的可信性,采用合适的模型对这些因素进行组合,从而得到信息源的可信性[10-11].虽然在信息源的可信性计算中加入了很多因素,但这些研究大部分都忽略了信息源的主题因素,默认信息源在所有主题下是一样的,不符合常理,比如说人们更倾向于相信一个医生发布的关于药品的内容,而不相信他发布的关于天文的内容.
面向信息的可信性研究方面通常考虑多种因素,采用迭代模型、优化模型和概率图模型3种模型来进行研究.使用迭代模型度量信息可信性的研究利用影响信息可信性的因素和信息可信性之间的相互影响关系,通过影响信息可信性因素计算信息的可信性,然后通过信息可信性量化影响信息可信性的因素,不断重复这个过程直至收敛.采用迭代模型的最简单情形是利用信息源可信性和信息可信性之间的相互影响来计算信息的可信性[12-14].也有一些迭代模型考虑多种因素,如信息源之间的关系、信息的语义等[15-16].采用优化模型的信息可信性计算方法主要目的是寻找一个映射把影响信息可信性因素和信息的可信性联系起来,有2种实现方式:一种是回归[17-20],另一种是分类[21-22],区别在于前者得到的是连续值,后者得到的是离散值.采用回归方法时通常会使用逻辑回归、最大似然估计等算法,或者是根据具体应用场景设计相应的回归算法;分类方法中会采用支持向量机、决策树等算法.基于概率图模型的信息可信性研究认为:信息源做出的判断、信息源的特征、信息本身的特征等可观测变量的分布依赖于信息的可信性、信息源的可信性等随机变量,通过建立随机变量和可观测变量之间的关系得到概率图模型.大部分研究采用了贝叶斯网络[23-25],也有研究使用的是条件随机场模型[26].
随着社交媒体的普及,近几年研究重心逐渐从传统网络转移到Twitter(6)http://twitter.com、新浪微博等社交媒体平台.目前国外研究涉及到的媒体平台主要包括Twitter[14,21]、新浪微博[20,26]以及Yelp[27],研究对象可划分为事件层面的信息可信性研究[14,20]以及推文层面的可信性研究[21,26-27].文献[14]通过构建推文与信息源、信息源之间的关系图,将推文的可信性作为隐含变量通过最大期望(expectation maxi-mum, EM)算法进行求解,进而通过投票思想获得事件的可信性.文献[20]通过构建推文间的关系图来将事件的可信性计算转化为图优化问题.社交媒体中往往存在很多噪音数据,比如大量的从众转发等现象,对推文可信性判断带来干扰进而使事件的可信性判断出现不可忽视的偏差.由此可见,从大量噪音数据中筛选出真正有用的推文数据就显得十分重要.推文层面的研究大多依赖于数据集的标注标签以使用传统机器学习方法,考虑到训练集规模较大、人工标注耗费成本较高,我们更倾向于使用无需人工标注的方法,如使用带标签数据集或无监督学习方法.Fontanarava等人[27]使用Yelp带标签数据集采用了集成学习的方法,混合了多个模型对Yelp上特定领域的评论可信性进行了研究.他们从评论的语言学特征入手,采用判别模型支持向量机和生成模型循环神经网络对评论内容的可信性进行分析,另一方面采用随机森林,根据用户和评论元数据的特征,对评论的可信性进行了分类.最后将3个模型得到的结果采用线性内插法结合到一起,得到最终的结果.Yelp等评价类网站与新浪微博等内容导向的社交平台的元数据特征存在明显差别,如评价类平台特有的星级等,所以针对内容导向的社交平台仍需挖掘有用特征.
目前国内对社交媒体信息可信性评价的相关工作较少.谢柏林等人[28]在2016年的研究中,侧重于及早发现微博中的虚假信息,将转发以及评论内容的观点倾向,结合用户对信息的识别度作为观测值,使用状态持续时间概率为Gamma分布的隐半马尔可夫模型计算原创微博的可信性.除此以外,任亚峰等人[29]在2015年针对虚假评论检测进行了研究,该研究考虑到人工标注数据集后采用监督学习的不合理性,基于少量已知正例样本采用PU(positive and unlabeled)学习算法标注未知标签数据,最后在标注数据集中构建多核分类器来检测虚假评论.虽然这些研究开始重视社交网络信息的可信性,但近几年国内在该方面的研究还很少见.
面向信息的可信性研究中大多忽略了主题因素,然而用户在不同主题下具有不同的可信性[30].默认信息源在所有主题下具有相同可信性,一方面削弱了信息源在其擅长主题下的可信性,另一方面也增强了信息源在其不擅长主题下的可信性,从而影响最终可信性计算结果的准确性.文献[21]在研究Twitter平台中的信息可信性时考虑了用户主题对信息可信性的影响,认为用户的主题与其参与的推文的主题偏差越大,推文和用户的可信性就越低.该研究针对Twitter平台的10个话题爬取了2 000条相关推文,采用人工进行标注分析,一方面模型对标注信息依赖性较高,另一方面数据规模较小,无法充分挖掘潜在特征.
在解决冲突数据相关问题中,需要保证数据源之间的独立性.数据源之间的依赖关系如频繁的拷贝行为,会对最终数据准确性的分析产生影响[31].Dong等人[13]在该问题的研究中,通过贝叶斯建模数据源之间的依赖关系,并据此调整数据源可信性在数据准确性分析中的权重.社交媒体内容可信性分析也应当考虑同样的问题.此外,频繁拷贝信息的信息源不仅经常出现在不可信信息的发布者中,也经常出现在可信的发布者中,并不能从他们发布信息的行为中得到所发布信息可信性的倾向.
综上所述,本文将同时考虑用户的主题因素和拷贝因素对社交媒体中内容的可信性进行进一步研究.由于社交媒体中缺乏内容和用户可信性的标记,人工标记难度很大,成本很高,比较适合采用无监督的方法进行研究,而概率图模型比较适合无监督的学习[32],同时具有直观易于理解的特点,所以本文在考虑用户主题和拷贝因素的基础上,使用了贝叶斯网络对社交媒体中内容的可信性进行分析和评价.本文的主要贡献在于同时考虑了用户的主题特性和从众行为特性,一方面将可信性评价与用户的擅长领域联系起来,另一方面也降低了社交平台中拷贝内容等噪音数据给可信性评价带来的干扰,最终在新浪微博真实数据集的实验结果表明本文提出的社交媒体内容可信性评价模型相比其他模型更具有适用性.
2 内容可信性评价模型
为评价社交媒体信息的可信性,本文提出社交媒体内容可信性评价模型LCEM(latent credibility evaluation model).首先描述模型背后的思想,简要介绍用户的主题因素、从众因素以及各因素与内容可信性之间的关系,然后给出模型的构建过程.
2.1 模型思想
在社交媒体中,用户发表或者转发一条内容的行为可以看作是一次投票行为.对于转发微博,其投票对象是转发微博对应的原始微博.对于原创微博,其投票对象是发表微博所承载的内容信息,可以认为原创微博是一种特殊的转发微博,是将抽象内容转发为具体文本,而不是文本对文本的转发.为了将原创微博与转发微博统一起来,近似认为原创微博的投票对象也是原始微博.如果一个用户发表了原创内容或者单纯转发了他人发表的内容,可以看作是该用户对其发表或者转发的内容投了一次赞成票,表示其认为原始内容是可信的.如果在转发的同时加上了自己对内容的观点,当观点的情感极性是正向的,那么可以当作用户相信原始内容,投出了赞成票;反之,如果评论的情感极性是负向的,那么可以当作用户不认可原始内容,投出了反对票.很显然,不同用户投票对于人们判断内容可信性的参考价值是不一样的.
首先,如果一个投票是在用户从众的情况下产生的,那么意味着这个投票的产生未经过用户的判断,投票中没有赞成和反对的倾向,其产生独立于内容的可信性,所以不具备参考价值.如果用户在非从众的情况下做出了一次投票,表明用户是通过自己的思考,利用相关的知识经验进行了判断.由于知识经验和内容是相关的,所以投票也就与内容的可信性联系在一起,具有参考价值.CNNIC2016年中国互联网新闻市场研究报告[33]中显示,超过60%的用户在转发新闻内容的时候并未对内容的可信性进行判断,这些大量的从众投票会严重干扰人们对内容可信性进行判断,所以依据用户的从众行为过滤没有价值的投票显得十分必要.
此外,用户在非从众情况下投票的参考价值也有着很大的差异.如果一个用户在一个主题下比较活跃,那么用户对该主题相关的知识掌握的也就相对较多,也就越容易做出正确的判断,用户在该主题下的投票参考价值也就越大;相反,在用户不熟悉的主题下,用户缺乏判断该主题下内容可信性的知识,不容易做出准确判断,所以这时候用户做出投票的参考价值很小.总的来说,用户非从众情况下投票的参考价值很大程度上取决于用户在投票对象主题下的专业程度.本文将用户的活跃程度视为用户的专业程度.
综合考虑用户的从众行为和主题分布可以很大程度上过滤掉没有价值的投票,提升具有参考价值投票的作用,从而提高对内容可信性判断的准确度.下面从这2方面出发,以新浪微博平台为例,从用户视角阐述新浪微博中投票的产生.首先用户打开其微博主页会看到最新发表或转发的微博,如果用户倾向于从众的话,他很有可能直接转发看到的热门微博.如果该用户独立思考能力比较强,那么他会选择自己感兴趣的微博进行转发,并且会考虑微博的可信性,以一定的概率转发微博,做出投票.这个过程中涉及到2种投票的概率:一种是用户从众情况下的概率;另一种是非从众情况下的概率.对于前者,用户呈现出的态度可能是支持也可能是反对.可以认为用户是从已有的转发微博中随机挑选了一条进行转发,所以他的态度取决于他转发微博的态度.那么从众用户投出赞成票的概率就是用户所处环境下赞成票数占所有票数的比例,即表示支持的转发数占总转发数的比例,投出反对票的概率则是反对票数占总票数的比例.对于后者,用户也会投出赞成票或者反对票,这取决于用户自身的属性.用户在非从众情况下可能赞成了可信的内容(真阳性),也有可能支持了不可信的内容(假阳性),同样也会出现反对可信内容(假阴性)和反对不可信内容(真阴性)的情况.所以用户投赞成票和反对票的概率就是它们在内容可信性下的边缘概率,也就是在内容可信与否2种情况下的投票概率之和,其中边缘概率的计算公式为
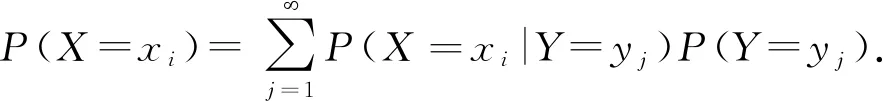
(1)
2.2 模型建立
考虑到缺乏带标记的社交媒体内容可信性数据,本文基于生成模型的思想,采用贝叶斯网络建立了社交媒体内容可信性评价图模型LCEM,利用盘式记法简化表示为图1,模型中的各个符号含义如表1所示.

Fig. 1 Latent credibility evaluation model图1 社交媒体内容可信性评价模型

Table 1 The Description of Symbols表1 模型符号说明

Continued(Table 1)
下面详细描述模型的建立过程,从变量之间的关系建模到整个贝叶斯网络的构建.

ρdu~Bino(1,πu).
(2)
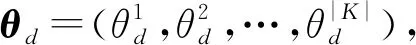
zdu~Muti(1,θd).
(3)
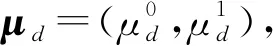
λdu~Bino(1,μd).
(4)
4)vdu表示用户u对内容d的投票,投票分为赞成票和反对票,分别用1和0表示.其服从的分布分为2种情况:一种是用户u在从众情况下产生;另一种是用户u在非从众情况下产生.

vdu=Bino(1,φukc).
(5)
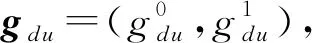
vdu~Bino(1,gdu),
(6)
上下文环境变量gdu的建模方法为
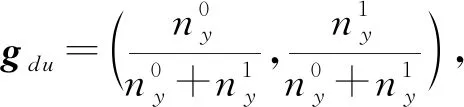
(7)
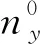
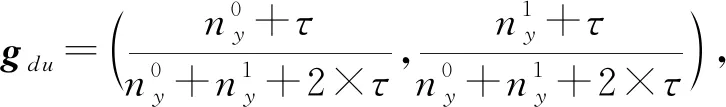
(8)
其中,参数τ是新引入的一个超参数,用于平衡用户投赞成票和反对票的概率.
上述1)~4)所有变量中,如图1,用户从众行为ρdu、内容主题zdu和内容可信性λdu将作为模型的隐含变量;投票结果vdu、用户u以及上下文环境gdu则作为可观测变量;剩下的用户从众概率分布参数πu、内容主题分布参数θd、内容可信性分布参数μd以及用户投票行为分布参数φukc是待估计参数,也就是需要求解的变量.
为了提高模型的灵活性和进行平滑处理,为每个待估计参数引入相应的先验分布,先验分布的参数就是超参数.首先用户u在内容d的从众行为ρdu服从单次二项分布,那么用户的所有投票的从众行为ρu=(ρd1u,ρd2u.…)服从二项分布,那么有:
ρu~Bino(nu,πu),
(9)
其中,nu表示用户u的投票次数.为便于计算,πu的分布满足二项分布的共轭先验贝塔分布,也就是:
πu~Beta(η),
(10)
其中,超参数η=(η0,η1),每个分量表示0和1的个数.同理有:
θd~Dir(γ),
(11)
其中,超参数γ=(γ0,γ1,…,γ|K|),
μd~Beta(α),
(12)
其中,超参数α=(α0,α1),
φukc~Beta(β),
(13)
其中,超参数β=(β0,β1).
模型中,{u,vdu,gdu}是可观测变量,{μd,φukc,πu,θd}是待估计参数,{ρdu,zdu,λdu}是隐含变量.模型的输入是所有投票记录对应的可观测变量和超参数的值,输出是所有隐含变量以及待估计参数的值.
图1中各变量的联合概率分布的抽象表达为
P(W,λ,z,ρ,μ,θ,φ,π;α,γ,β,η).
(14)
根据上面提出的社交媒体内容可信性评价模型,投票产生的具体过程为
1) 对于每一个用户u、每一个内容主题k和每一种内容可信性c,从贝塔分布Beta(φukc|β)中取样生成非从众情况下用户u在内容主题为k和可信性为c情况下投票行为的分布参数φukc;
2) 对于每个用户u,从贝塔分布Beta(πu|η)中取样生成用户u的从众行为分布参数πu;
3) 对于每条内容d:
3.1) 从狄利克雷分布Dir(θd|γ)取样生成内容d的主题分布θd;
3.2) 从贝塔分布Beta(μd|α)中取样生成内容的可信性分布μd;
3.3) 对于每个投票给内容d的用户u:
3.3.1) 从二项分布ρdu~Bino(1,πu)中取样生成用户u的从众行为ρdu;
3.3.2) 从二项分布λdu~Bino(1,μd)中取样生成内容的可信性标签λdu;
3.3.3) 从多项分布zdu~Multi(1,θd)中取样生成内容的一个主题zdu;
3.3.4) 若ρdu=0,则从二项分布vdu~Bino(1,φukc)中取样生成投票vdu,其中k表示zdu的取值结果,c表示λdu的取值结果;若ρdu=1,则从二项分布vdu~Bino(1,gdu)中取样生成投票vdu.
3 模型求解
在完成概率图模型建立后,需要针对其中的待估计参数进行求解.本文在参数估计的过程中采用了吉布斯采样算法.吉布斯采样作为马尔可夫蒙特卡洛方法的一种特殊情况,适用于高维数据的采样,普遍应用于概率图模型中.采用吉布斯采样求解模型,最主要的工作是推导隐含变量的采样规则.根据采样结果可以很容易地计算待估计参数.
3.1 隐含变量联合概率推导
首先给出隐含变量在已知数据,即数据集和超参下的联合概率分布形式,表示为
P(λ,z,ρ|W;α,γ,β,η).
(15)
引入隐含变量分布参数,即待估计参数后,式(15)可表示为

(16)
那么要计算隐含变量的联合概率分布,需要先计算P(λ,z,ρ,μ,θ,φ,π|W;α,γ,β,η),即隐含变量和待估计参数在已知信息下的联合概率分布.根据贝叶斯公式以及D-分离规则有:
P(λ,z,ρ,μ,θ,φ,π|W;α,γ,β,η)∝P(W,λ,z,ρ|μ,φ,π)P(θ|γ)P(μ|α)×P(φ|β)P(π|η).
(17)
根据概率图模型中各条生成路线,式(17)可以整理得到:
P(λ,z,ρ,μ,θ,φ,π|W;α,γ,β,η)∝
(18)
表达式(18-1)对应图1中η→πu→ρdu生成路线,表示用户从众行为的先验分布中采样生成用户从众行为的分布,然后从该分布中采样出用户是否从众.同理表达式(18-2)对应路线β→φukc→vdu;表达式(18-3)对应路线γ→θd→zdu;表达式(18-4)对应路线α→μd→λdu;表达式(18-5)对应路线gdu→vdu.对于投票结果vw,其生成路径分别对应表达式(18-2)和表达式(18-5)这2种不同的情况,由公式的指数上标也就是投票记录对应的用户从众行为ρw决定.当该投票是在用户非从众(ρw=0)情况下产生时,其生成路径对应表达式(18-2),当该投票在用户从众(ρw=1)情况下产生时,其生成路径对应表达式(18-5).
将式(18)带入式(16)计算隐含变量的概率分布,并且将多重积分根据积分变量进行转化来简化计算复杂度,整理为
P(λ,z,ρ|W;α,γ,β,η)∝
(19)
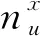

(20)



(21)
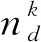
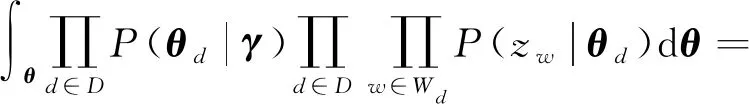
(22)

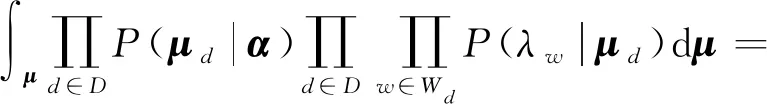
(23)
并且表达式(19-5)可以转化为
(24)
至此,结合式(20)~(24),可以得到隐含变量的联合概率分布:
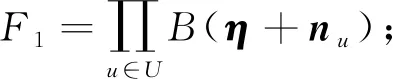

(25)
3.2 采样算法
在3.1节隐含变量的联合概率分布的推导基础上,继续阐述隐含变量的状态转移分布推导过程,并给出LCEM的吉布斯采样算法.
根据吉布斯采样算法,LCEM的转移概率为
P(λo,zo,ρo|λ,z,ρ,W;α,γ,β,η)∝
(26)
其中(λo,zo,ρo)表示与一个投票vo对应的隐含变量,{λ,z,ρ}表示剔除该投票vo对应的隐含变量后剩余投票对应的隐含变量.可以看出需要采样的隐含变量的转移概率同所有隐含变量的联合概率与剔除该组变量的隐含变量的联合概率比值成正比.并且可以使用式(15)的形式来表示联合概率,整个转移概率公式推导可拆分成对每一部分的推导.下面具体推导式(26)中F1和F的关系,其中Γ(·)表示伽玛函数:
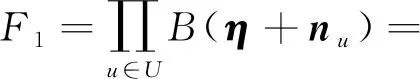
(27)
同式(27)推导过程,式(26)中F2和F的关系为
(28)
式(26)中F3和F的关系为
(29)
式(26)中F4和F的关系为
(30)
式(26)中F5和F的关系为
F5=(gvo)ρoF.
(31)
综合式(27)~(31),一组隐含变量转移概率的具体表达形式为
P(λo,zo,ρo|λ,z,ρ,W;α,γ,β,η)∝
(32)
其中ρo∈{0,1},若当前隐含变量对应的投票记录在从众情况下产生,即ρo=0,最终的概率与上下文gvo无关,同理ρo=1,最终概率与第2项无关.
对其中某个隐含变量进行采样时,另外2个变量作为隐含变量的固定值.所以该隐含变量的采样概率只和式(32)中的相关项有关,其他项在当前采样过程中作为常量.所以各隐含变量的采样规则为
P(λo|λ,z,ρ,W;α,γ,β,η)∝
(33)
P(zo|λ,z,ρ,W;α,γ,β,η)∝
(34)
P(ρo|λ,z,ρ,W;α,γ,β,η)∝
(35)
根据隐含变量的采样公式对隐含变量进行采样,将采样得到的结果作为后验知识,结合事先设定的先验知识,利用先验分布和后验分布的共轭关系,可以得到各个待估计参数的计算规则:

(36)

(37)

(38)
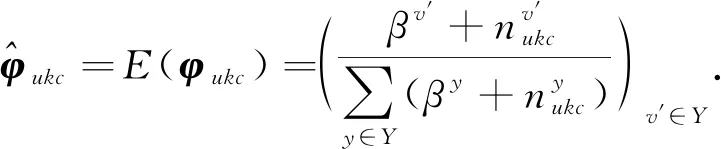
(39)
根据这些规则就可以得到本文提出的可信性评价模型LCEM的吉布斯采样算法.算法输入是所有内容对应的投票记录集合W、内容所有主题类别K、内容可信性先验分布参数α、内容主题先验分布参数γ、用户从众行为先验分布参数η、用户在不同主题和可信性下投票行为的先验分布参数β、上下文环境变量平衡参数τ,以及采样迭代次数I.算法输出包括内容可信性分布μ、内容主题分布θ、用户从众行为分布π、用户在不同主题和内容可信性下投票行为分布φ,以及所有隐含变量{λ,z,ρ}.详细过程如算法1所示.
算法1.LCEM吉布斯采样算法.
输入:{W,K,α,β,γ,η,τ,I};
输出:{μ,θ,π,φ,λ,z,ρ}.
② for alld∈Ddo
③ for allw∈Wddo
④
⑤λw~U(0,1);
⑥zw~U(1,|K|);
⑦ρw~U(0,1);
⑧ end for
⑨ end for



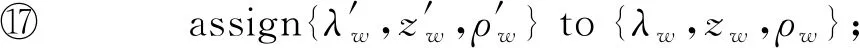
4 模型评价
本节采用真实社交媒体平台的数据来验证本文提出的模型.采用的数据来自于文献[34]的新浪微博公开数据集,数据中有3万条原创微博、3 700万条转发微博、140万个用户.从数据中可以提取出可观测变量的值,从而得到模型的输入.
4.1 参数设定
需要设定的参数包括迭代次数I、微博主题类别K,以及各先验分布的超参.
首先对迭代次数I的设定.由于吉布斯采样是一个随机化求解方法,无法保证迭代确定次数后收敛.本文将迭代次数设定为一个较大值1 000,通过观察困惑度(perplexity)来判断是否收敛.困惑度是一个用于衡量概率模型拟合程度的量,值越小表示拟合效果越好.随着采样进行,困惑度会不断减少,当困惑度变化范围小于一定阈值,则认为其收敛,实验设定阈值为0.001.困惑度计算方法为
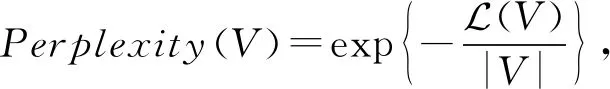
(40)
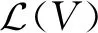
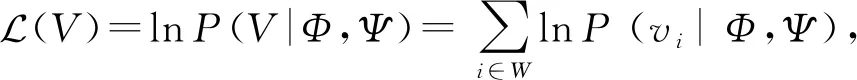
(41)
其中Φ表示待估计参数集合,Ψ是超参数集合.
本文中模型的似然函数可以表示为
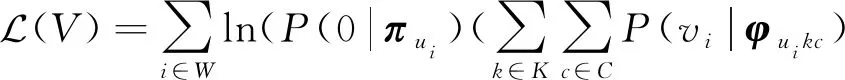
(42)
对于主题类别K的设定,也就是主题类别个数的设定,本文采用HDP(hierarchical Dirichlet processes)模型[35].HDP模型可以看做是LDA(latent Dirichlet allocation)模型[36]的扩展,是非参数化的LDA模型,可以自动调整主题个数,达到不用人工确定主题个数的目的.本文将微博文本输入HDP模型,经过5天32 182次迭代,得到如图2所示的主题与困惑度关系:
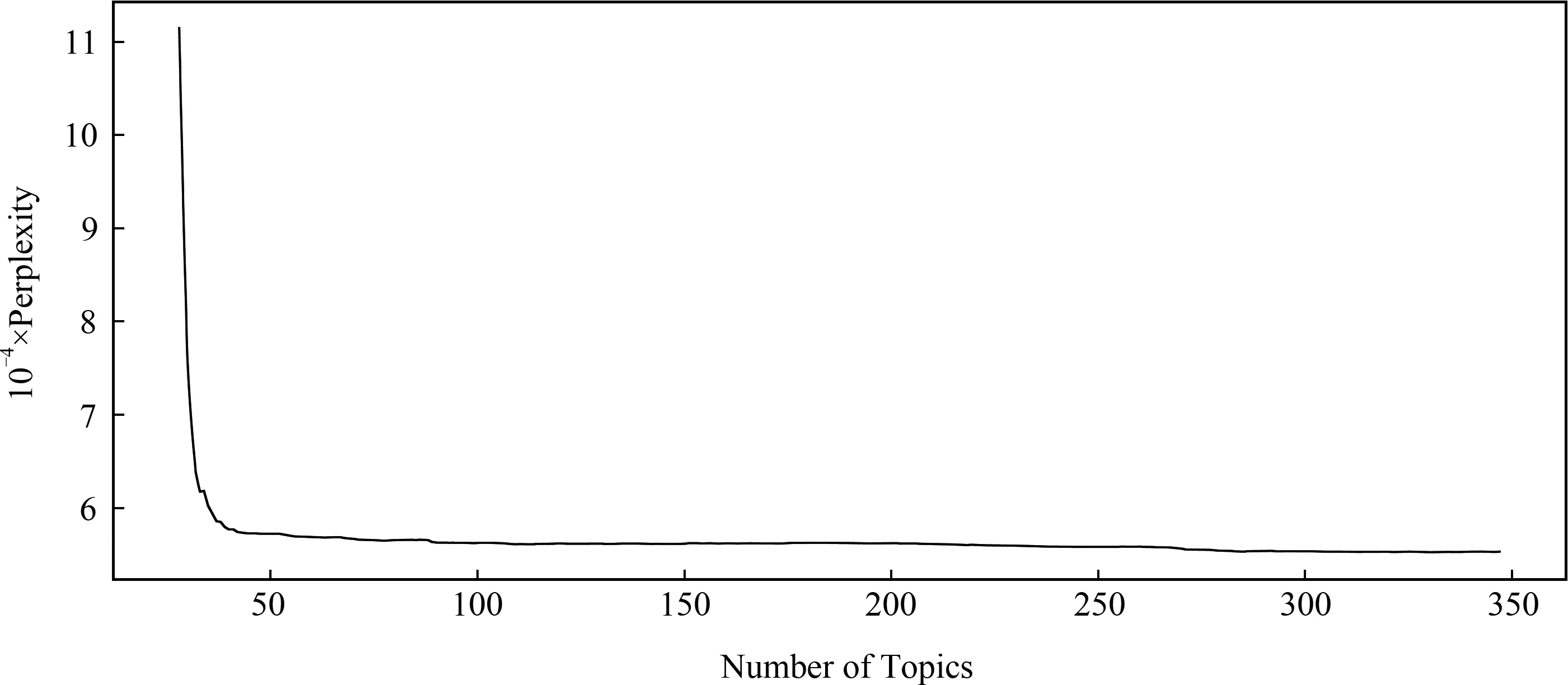
Fig. 2 The relation between number of topics and perplexity图2 主题数和困惑度的关系
从图2中可以发现主题数100之后,困惑度趋于平稳,所以本文将主题数确定为100.
对于{α,γ,η,β} 这些先验分布的超参数,假设它们的各个分量都相等,即α=α′×(1,1),γ=γ′×(1,1,…,1),η=η′×(1,1),β=β′×(1,1)那么对向量的设定就可以转化为对标量的设定,即对系数{α′,γ′,η′,β′} 的设定.设定{α′,γ′,η′,β′,τ}这些参数时,本文利用了贝叶斯优化工具(7)https://github.com/fmfn/BayesianOptimization搜寻合适的参数,设定的搜索区间为α′∈[0.01,2],γ′∈[0.01,2],η′∈[0.01,2],β′∈[0.01,2],τ∈[0.01,100],搜寻结果为α′=0.01,γ′=0.01,η′=0.01,β′=0.01,τ=94.47.
4.2 实验结果
为了验证LCEM模型的有效性,本文选取了6个模型进行对比.
3) TruthFinder[37].该方法是一种迭代模型,通过信息源(source)建立事实(fact)之间的联系,采用类似于PageRank的方法计算fact的可信性.
4) LTM[24].该模型也是概率图模型,其思想是各个fact中每个source做出的声明(claim)受到fact可信与否的影响,利用这个影响关系来判断fact的可信性.
5) KDEm[17].该模型是一种回归模型,采用了核密度估计的思想,将同一fact的所有claim映射到函数空间,将用户的可信性作为权重,对fact的可信性进行拟合.
6) CATD[38].该模型也是回归模型,通过fact可信性与source之间的关联,建立优化目标,在计算source权重时考虑了source发表的claim数服从幂律分布,每个source权重的置信度会有很大差别,根据置信度来修正权重.
其中TruthFinder,KDEm,CATD有公开源码(8)https://github.com/MengtingWan/KDEm,由文献[17]提供.这6个模型中的source,claim,fact分别对应着本文研究场景中的用户、投票、微博.
由于本文采用的公开数据集中并不携带内容可信或者不可信的标签,常规的F1值评价方法并不适用.本文将采用的评价方法为:取实验结果中可信性最高的100条微博和可信性最低的100条微博,采用人工的方式判断前100条中可信微博的数量和后100条微博中不可信微博的数量,将前100条中可信微博的比例和后100条中不可信微博的比例作为评价指标.
对各个模型中输出的内容可信性评分排序,提取出可信性最高的100条微博和可信性最低的100条微博,得到的对比结果如图3所示.本文提出模型的准确程度都要高于其他模型,即使除去用户主题因素的考虑,相比其他模型也具有一定的优势.不考虑从众因素的情况下,效果也和其他模型中最好的相差无几.其中的原因是对比模型是建立在用户行为差异比较大的基础上,即所有用户投出的赞成票数和反对票数差别较小.但是在社交媒体中反对票数本来就远小于赞成票数,加上从众用户的存在,它们悬殊更加巨大.在本文使用的数据集中,根据情感分析得到的赞成票数和反对票数的比值达到了900.而本文从用户的从众因素和主题因素2个角度弱化了这种负面影响,得到了相对于其他模型较好的结果.虽然TruthFinder也考虑到用户之间存在着拷贝,但是只是单纯地为所有内容的可信性加上了一个相同衰减系数,并不影响最终可信性的排名.图3也体现了用户从众因素对内容可信性评价的影响大于用户的主题因素,原因在于用户参与其不熟悉的主题往往反映了一定的从众倾向,即从众因素中包含了部分主题因素.

Fig. 3 The precision of credibility top100 and bottom100 microblogs图3 可信性Top100以及Bottom100微博的精确率
同时,从图3中可以明显看到,在Top100中可信微博的比例都比较高,而在Bottom100中不可信微博的比例都很低.究其原因,一方面数据集中可信内容数要远大于不可信内容数;另一方面,用户在参与负面新闻时往往持批判的态度,即根据情感极性分析得到的是反对票,但实际上是赞成票.这样就导致了在Bottom100中负面新闻占据了很大一部分,使得真正不可信的内容减少.
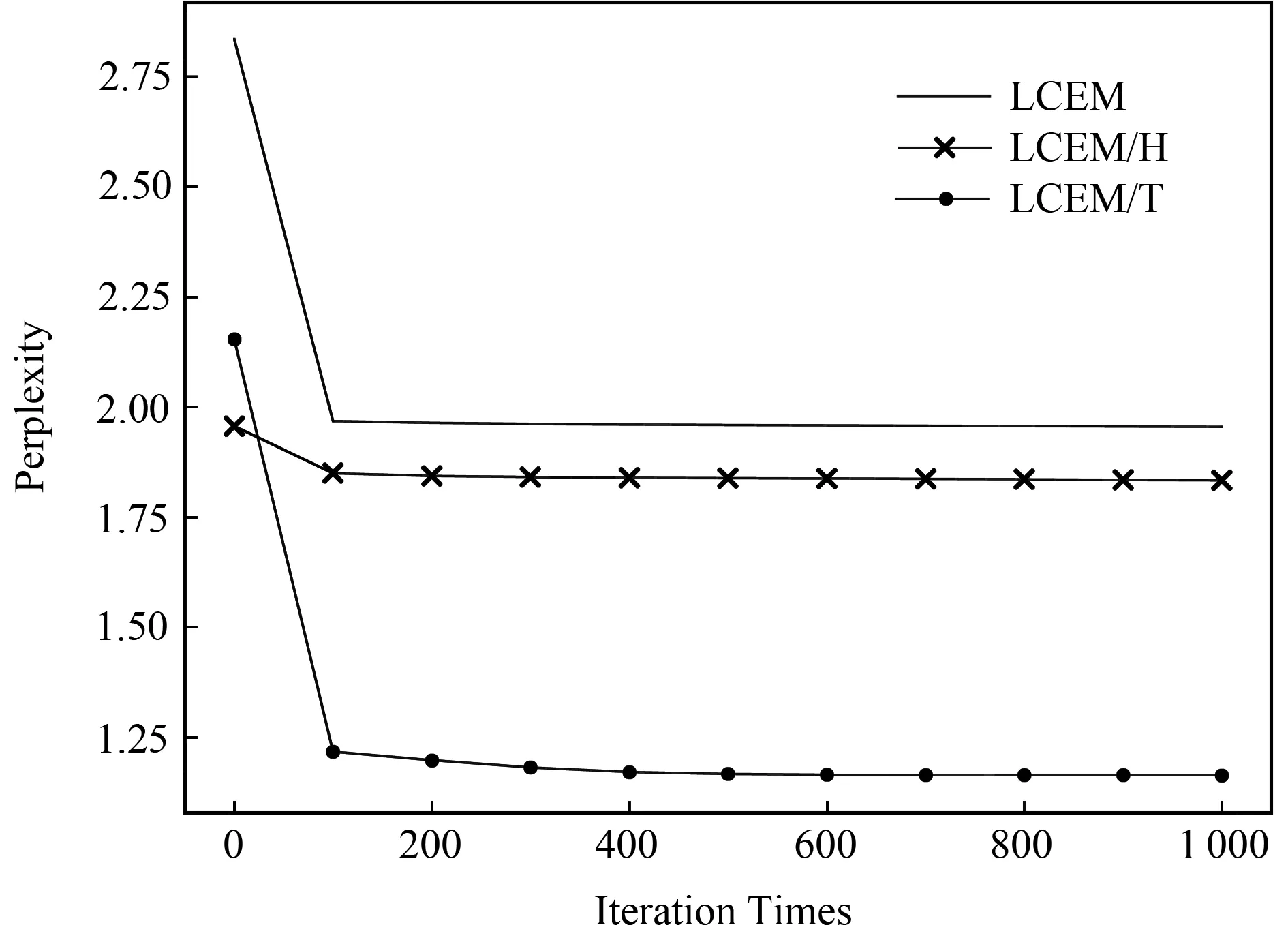
Fig. 4 The perplexity of LCEM, LCEMH and LCEMT图4 模型LCEM,LCEMH,LCEMT的困惑度
5 总结与展望
本文致力于解决的问题是社交媒体中内容可信性判断的问题.针对该问题,考虑到在社交媒体中用户在消费信息时有跟风的倾向和选择自己感兴趣信息的倾向,本文从用户的从众因素和主题因素以及内容的可信性因素出发,对用户发表或传播内容时持有的支持或反对态度进行分析建模,从而实现对内容可信性的评价.实验结果表明,本文提出的模型更加适合社交媒体中内容可行性的评价.
虽然相比现有的内容可信性评价模型,本文提出的模型具有较好的效果,但是本文模型在以下方面仍有改进的空间:提高评论支持或反对的计算准确程度;更加准确地衡量用户转发内容时的上下文环境;除了考虑用户的从众行为,加入用户对特定用户的依赖能够提高可信性判断的准确程度.
猜你喜欢
思维与智慧·下半月(2021年11期)2021-11-23
小学生学习指导(高年级)(2021年4期)2021-04-29
疯狂英语·新读写(2018年3期)2018-09-07
财讯(2018年28期)2018-05-14
中国注册会计师(2018年2期)2018-03-12
艺术研究(2017年2期)2017-07-26
课程教育研究·学法教法研究(2016年1期)2016-03-17
科技与创新(2014年17期)2014-10-22
新高考·高二数学(2014年7期)2014-09-18
图书与情报(2014年3期)2014-02-27
