
区域医疗健康平台中检验检查指标的标准化算法
2019-09-16 02:32张佳影张知行张欢欢
计算机研究与发展 2019年9期
张佳影 王 祺 张知行 阮 彤 张欢欢 何 萍
1(华东理工大学信息科学与工程学院 上海 200237)2(上海申康医院发展中心 上海 200041)
随着医疗信息化的不断深入,国内外在现有医疗体系之上相继建立起了区域医疗健康平台.以上海市为例,随着上海市医联工程项目在2008年3月正式投入使用,上海市建成了包括市内38家三级医院的临床诊疗信息共享平台,实现了对患者的基本信息、基本病历资料、住院病案资料、医嘱资料、医疗费用资料、实验室检验检查报告、医学影像检查报告的交换共享,并通过网站等其他辅助系统加强各医院间的协同诊疗.然而,由于历史原因,各家医院关于同一检验检查指标的称谓不尽相同.仅以“血清钠”为例,便有“钠离子浓度”、“NA+”、“动脉血钠”、“血钠(Na)”等10多种不同说法.由于目前并没有完整可用的指标同义词库以进行指标映射,这一问题已严重影响到了区域间医疗信息的互联共享.由此,对区域医疗健康平台中检验检查指标做标准化处理,将各家医院的同一指标的不同称谓映射成统一的标准名称,便至关重要.然而,由于检验检查指标涉及到大量的医学知识,加之各家医院的指标体系纷繁庞杂,由医学专业人员对其进行人工标准化,需要耗费大量的时间与精力.因此,如何设计一个检验检查指标的标准化算法,便成了关键所在.
检验检查指标的标准化问题,可以看作是一个实体对齐问题,即将医疗健康平台中的候选指标映射到标准指标上.关于实体对齐,目前主要有2类任务,分别是不同知识库中实体间的实例匹配[1-2],以及文本中实体和知识库实体之间的实体链接[3-4].前者常利用知识库中实体的属性信息进行实例匹配,后者常利用文本中实体的上下文信息与知识库中实体的属性信息进行实体链接.然而,本文的任务与以上2种任务都不同:检验检查指标存在于电子病历之中,只有相应的取值及取值范围,而不存在属性信息;同时,它也不似文本中实体那般拥有上下文信息;更重要的是,本文任务中并不存在一个标准知识库来提供所有指标的标准名称.也就是说,目前的方法都难以直接适用于本任务.
有鉴于此,针对区域医疗健康平台中的检验检查指标标准化问题,本文提出了一种指标标准化算法框架.首先对指标数据进行预处理;接着通过基于密度的聚类算法,将不同的指标聚为多个簇,以缩小指标的对齐范围;然后,迭代地利用二分类算法查找簇内筛选出的标准名称的同义指标;最后,对指标对齐结果进行映射与修正.实验结果表明,在上海市8家三级医院的实验数据集上,最终的二分类映射算法F1-score可以达到85.27%.
1 相关工作
目前的实体对齐任务基本可以分为实例匹配和实体链接2类.
许多研究聚焦于知识库实体间的实例匹配,这些研究利用知识库中实体的属性信息进行匹配,它们基本可以分为2类,分别是成对实体匹配方法和集体实体匹配方法.成对实体匹配方法主要有基于传统概率模型的方法、有监督学习的方法、聚类方法和主动学习方法.传统概率模型方法根据属性相似性进行成对实体比较[5-7],有监督学习方法常使用决策树[1,8]、支持向量机[9-10]、集成学习[11-12]等方法进行二分类,聚类方法利用属性相似性进行实体聚类[13-15],主动学习方法通过人机交互不断迭代来训练分类模型[16-18].集体实体匹配方法则将实体的关联实体也纳入考虑,常见的方法有LDA方法[19-20]、CRF模型[21-22]、Markov逻辑网[23-24]等.
就文本中实体与知识库实体间的实体链接而言,主要有基于概率生成模型的方法[3,25]、基于主题模型的方法[4,26]、基于图的方法[27- 30]和基于深度神经网络的方法[31- 34].
2 指标标准化算法
指标标准化算法的整体流程如图1所示.首先,对指标数据进行预处理,实现大小写统一、单位统一和指标参考值提取.接着,利用指标的字面特征,通过基于密度的聚类算法,将不同的指标聚为一个个指标簇,以缩小指标的对齐范围.然后,为每一个簇确定一个标准名称,并利用二分类算法找出簇内标准名称的同义指标进行指标映射.对于剩下非同义指标,从中筛选出一个新的标准名称,继续利用二分类算法进行同义指标的查找(1)实际操作中选填项一般无数据填入.如“LOINC编码”字段是帮助识别是否是同一个指标的重要特征,然而由于是选填项,实际上没有任何数据填入.,如此迭代进行,直到所有簇内均为同义指标或簇内只剩1个指标为止.最后,再由医学专业人员对指标对齐结果进行修正处理.
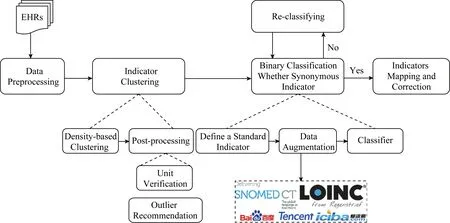
Fig. 1 Overall process of indicator standardization algorithm图1 指标标准化算法整体流程
2.1 数据预处理
病历中的指标数据,排除选填项(2)当然也可以对所有的非同义指标重新进行聚类,如此迭代进行.只是在实际应用时考虑到38家医院的不同指标太多,聚类的时间成本很高,本文作为区域医疗健康平台中检验检查指标的标准化算法的初步尝试,暂且迭代使用二分类算法进行标准化.,必填项中主要包括指标名称、缩写、参考值、单位、所属检查项、检查指标结果、异常指标提示等字段.其中,所属检查项因各家医院标准不一、检查指标结果因其取值因病人而异、异常指标提示因不具有指标区分度而失去作为指标标准化特征的意义.因此,可用的字段基本仅限于指标名称、缩写、参考值和单位这4项.对指标进行数据预处理,主要是统一指标大小写、统一指标单位,以及提取指标参考值.
2.2 指标聚类
为缩小指标的对齐范围,本文使用基于密度的聚类算法,将不同的指标聚到一个个指标簇中.基于密度的聚类算法依据样本分布的紧密程度来划分簇,它主要考察样本的可连接性,并在可连接样本的基础上通过不断扩展聚类簇来获得最终结果.
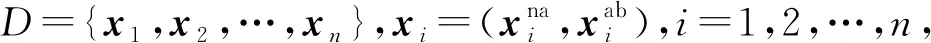
定义1.ε-邻域.对于xi∈D,它的ε-邻域为数据集D中与xi的距离不大于ε的所有样本,即Nε(xi)={xi∈D|dist(xi,xj)≤ε}.
定义2.核心对象.如果xi的ε-邻域内至少包含minPts个样本,即|Nε(xi)|≥minPts,那么xi是一个核心对象.
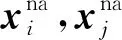
(1)
(2)
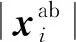

(3)
聚类算法从核心对象出发,不断向外扩展,进而生成聚类簇,其伪代码如算法1所示.
算法 1.基于密度的聚类算法.
输入: 指标集合D={x1,x2,…,xn}、领域参数ε,minPts;
输出:簇划分C={C1,C2,…,Cm}.
① https://baike.baidu.com/② http://fanyi.baidu.com/
③ http://fanyi.qq.com/ ④ http://www.iciba.com/
① 初始化核心对象集合T=∅;
② forxi∈Ddo
③ 确定指标xi的ε-邻域Nε(xi);
④ if |Nε(xi)|≥minPtsthen
⑤ 将指标xi加入核心对象集合T=T∪{xi};
⑥ end if
⑦ end for
⑧ 初始化聚类簇数k=0,簇集合C=∅,未访问的指标集合P=D;
⑨ whileT≠∅ do
⑩ 记录当前未访问指标集合P′=P;
需要注意的是,由于聚类是一个无监督的学习过程,它可能存在2个问题:
1) 聚为一簇的指标实际上医学含义不同,却因为名称相近或缩写相似而被归为一簇;
2) 有些离群值既不是核心对象,又不能通过核心对象访问,因而没有被聚类.因此,需要对聚类结果进行后处理.
① 单位验证.假设同义指标的单位是相同的,那么可以对每一簇指标进行单位验证,将不同单位的指标分离为不同的簇.
② 离群值推荐.对于未被聚类的离群值,有2种处理方案,第1种是按距离远近,将离群值分到单位相符且距离最近的那一簇中;第2种是考虑到离群值与其他簇都距离较远,很可能它本身就是一个全新的指标.本文采用第2种处理方案.
2.3 簇内二分类
即使经过后处理,无监督聚类算法也无法保证簇内的指标皆为同义指标.因此,本文为每一个簇确定一个标准名称,并利用二分类算法将簇内指标划分为标准名称的同义指标和非同义指标2类.特别地,为方便医学专业人员对指标对齐结果进行后处理修正,考虑到标准指标应为最常用的指标,本文以簇内出现频次最多的指标为标准指标.
2.3.1 数据增强
由于医学专业人员很难凭空枚举出所有的同义指标,加上有些指标可能会有与名称毫无联系的同义词(如“B型钠尿肽”和“脑钠素”),因此在数据集生成方面,除由医学专业人员手动标注部分同义指标用于分类器训练之外,本文还利用SNOMED CT知识库[36]、LOINC知识库[37]、百度百科①等途径来抽取标准指标的同义词用于训练.其中,SNOMED CT知识库为全英文库,目前并无中文版本,因此需要借助百度翻译②、腾讯翻译③、爱词霸翻译④等翻译工具将英文指标翻译为中文指标.需要注意的是,即使对同一个指标,翻译工具也有可能会得到不同的翻译结果,因此翻译本身也是获取同义词的途径之一.表1给出了“B型钠尿肽”经数据增强后的同义指标示例.

Table 1 An Example of the Synonymous Indicators表1 同义指标示例
2.3.2 特征抽取
本文设计了2类特征用于指标的二分类,分别是相似度特征和分块打分特征.
1) 相似度特征
这类特征主要考虑了簇中每一个候选指标与标准指标及其所有同义词的名称相似度和缩写相似度.
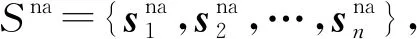
① 最长公共子序列相似度
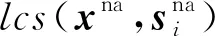
② Jaccard相似度
这个相似度可以判定名称顺序不同的指标,比如“B型利钠肽”和“利钠肽B型”的Jaccard相似度为1.
③ 余弦相似度

④ 编辑相似度

2) 基于一对多字段的分块打分特征
分块打分特征主要是针对指标参考值这种一对多的字段而言.对于指标参考值来说,由于不同医院对同一个指标,在参考值的上下界设置上有时会略有不同,因此实践中存在着一个指标名称对应多个参考值的现象.为应对这一问题,本文参考文献[38]中的知识库实体对齐分块算法,提出基于参考值的指标分块打分算法.指标分块打分算法基于2个假设:①相同的指标拥有相似的参考值;②拥有相似参考值的可能就是同一个指标.因此,本文的分块打分算法由2部分组成:首先,为标准指标的每一种参考值寻找一个与之最相似的候选指标参考值;然后,从这些最相似的参考值出发,构建候选指标与标准指标之间的匹配分块.需要注意的是,由于同一个指标可能有多种参考值,算法允许同一个指标出现在不同的块中.本文根据不同块的权重求出候选指标的加权平均得分,以此作为分类特征.
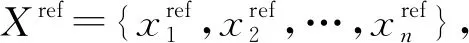
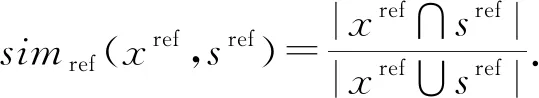

Fig. 2 A schematic diagram about how to calculate similarity of reference value pairs图2 参考值对相似度计算示意图


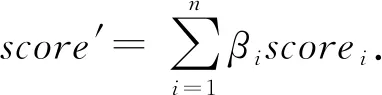
综上,我们得到了每个指标基于参考值的分块打分特征.
2.4 重定义簇
簇内二分类将簇内指标划分为标准指标的同义指标与非同义指标.针对非同义指标,本文将其单独取出作为一个新的簇,并从中筛选出一个新的标准名称,继续利用二分类算法进行同义指标的查找,如此迭代进行,直到所有簇内均为同义指标或簇内只剩1个指标为止.
2.5 指标映射与修正
到此阶段,指标标准化算法已进入尾声,只需把簇内的同义指标统一映射为对应的标准指标,并交由医学专业人员对指标的对齐结果进行核验与修正.特别地,聚类过程中可能会把同义的指标分到不同的簇中,二分类过程把簇中非同义指标剔除出来后,人工核验时还需对同义的簇进行合并.
3 实验结果与分析
3.1 数据集
本文从上海临床诊疗信息共享平台中抽取指标数据集进行实验.在指标数据的抽取过程中,本文考虑了2个因素:1)指标的种类要丰富,否则无法模拟实际应用场景;2)同义指标的名称要多样化,否则指标的标准化没有意义.因此,本文以医院为单位,抽取其中所有的指标,保证了丰富性;同时选取了不同指标名称最多的前8家医院,以满足多样性.这8家医院的不同指标名称数量分别为:1 404,1 243,1 098,1 010,992,958,921,849,合并去重后共有5 211个不同指标名称.在扩充了这些指标名称的缩写字段之后,不同的记录数为7 542条;在扩充了这些指标名称的缩写和参考值字段之后,不同的记录数达到了12 750条.在聚类实验部分,本文选择了236条数据进行评测.在二分类实验部分,本文以正负例1∶1的比例进行采样,并将采样结果按7∶3的比例划分为训练集和测试集,最终得到947条训练样本和406条测试样本.本文另外选取了100个正例和100负例作为验证集.
3.2 实验设置
本文通过在验证集上网格搜索,采用参数minPts=3,ε=0.35,阈值θ=0.7,α=0.6进行实验,选取梯度上升决策树(gradient boosting decision tree, GBDT)作为最终的二分类模型,并使用Precision,Recall,F1-score来评价聚类和二分类的效果.
3.3 实验结果
3.3.1 聚类算法对比实验
为了考察本文所使用的基于密度的聚类算法DBSCAN的有效性,本文选取了4种常见的聚类算法进行对比,它们分别是k均值聚类(k-means clustering,k-means)、均值漂移聚类(mean shift clustering, Meanshift)、高斯混合模型(Gaussian mixture model, GMM)与凝聚层次聚类(agglo-merative hierarchical clustering, AHC).需要注意的是,由于这4种基准算法除高斯混合模型外都需要事先定义簇数(而本文算法不需要),在实验时本文将它们的聚类数目设为真实的簇数.实验结果如表2所示:
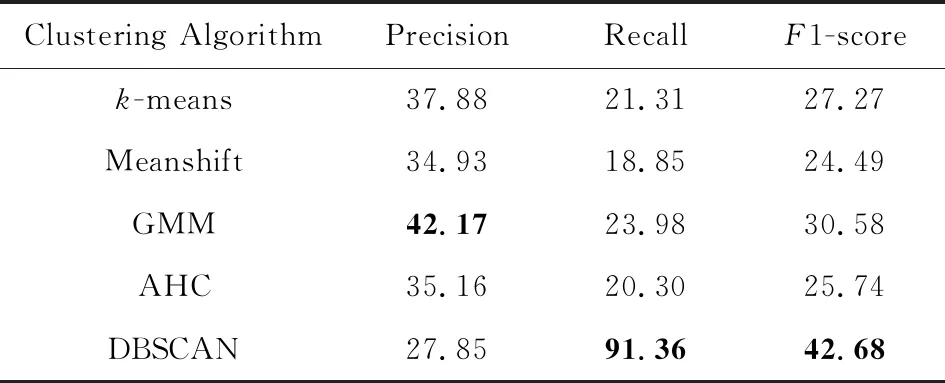
Table 2 Comparisons of Our Method and Common Clustering Methods表2 不同聚类算法的性能对比 %
Note: The best results are in bold.
从表2可以看出,本文基于密度的聚类算法的F1-score明显高于其他4种聚类算法,其提高幅度均在10%以上.然而,虽然本文方法的Recall能达到91.36%,但Precision仍然不是很高,这也显示了本文在聚类后进一步进行二分类映射的必要性.
3.3.2 二分类算法对比实验
1) 不同分类特征和不同分类器的对比
为了考察不同分类特征和不同分类器对分类性能的影响,本文选择不同的特征组合,将它们在逻辑回归(logistic regression, LR)、朴素贝叶斯(naive Bayes,NB)、k近邻(k-nearest neighbor, kNN)、支持向量机(support vector machine, SVM)、随机森林(random forest, RF)、梯度上升决策树(GBDT)等不同分类器下的F1-score进行对比.实验结果如表3所示,其中特征字段的名称(name)、缩写(abbreviation, Abbr.)和参考值(reference value, Ref.)分别表示名称相似度特征、缩写相似度特征和参考值分块打分特征.
从表3可以看出,当使用名称相似度特征、缩写相似度特征和参考值分块打分特征,辅以GBDT分类器时,分类效果最好,其F1值可达85.27%.从表3中横向来看,无论使用哪种特征,大部分情况下都是GBDT分类效果最好,而NB分类效果最差.这是因为GBDT使用Boosting方法进行集成学习,能够有效提高泛化性能,而NB分类器的条件独立假设在本文中很难成立.从表3中纵向来看,无论哪种分类器,基本都是随着特征数目的增多,分类效果越来越好,当使用全部3类分类特征时,分类效果达到最好.
Table 3 Comparisons of Different Classification Features and Different Classifiers表3 不同分类算法的性能对比 %
Note: The best result is in bold.
2) 与现有方法的对比
本文从最近3年来发表的实体对齐方法中选择了3种state-of-the-art方法,与本文所使用的全部3类特征辅以GBDT分类器的二分类方法进行对比,这3种基准方法分别是:
① 知识图谱融合方法(KG fusion).Wang等人[39]设计不同类型的属性相似度,使用机器学习方法进行多源知识图谱的融合.
② 诊断对齐方法(Diag. alignment).Ning等人[40]利用诊断的上下位信息和属性相似度将中文诊断映射为ICD编码.
③ 知识库对齐方法(KB alignment).王雪鹏等人[41]利用网络语义标签进行多元知识库的实体对齐.
需要注意的是,由于本文任务中既没有属性信息,又没有上下文信息,所以在实际实验中3种基准方法的部分特征没法使用,而主要使用了其中的实体名称和缩写的相似度计算方法.
与现有方法的对比实验结果如表4所示:
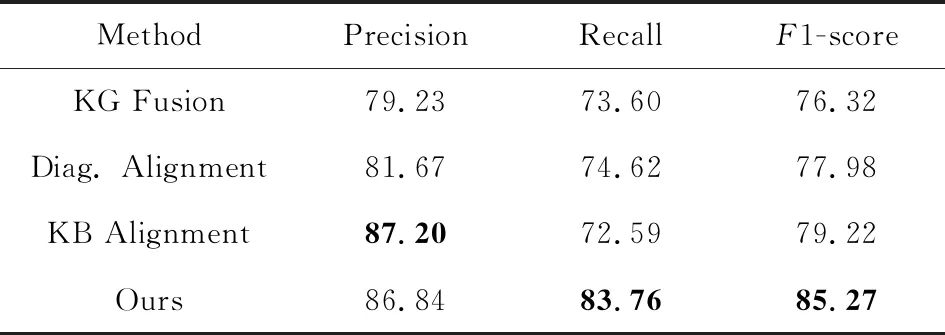
Table 4 Performance Comparison of Entity Alignment表4 与现有方法的对比 %
Note: The best results are in bold.
从表4可以看出,本文方法在所有方法中取得了最好的分类结果,其Precision,Recall,F1-score分别为86.84%,83.76%,85.27%.值得注意的是,对比表3最后1列,当使用GBDT分类器时,本文方法的任意2类特征组合的F1-score都比现有方法来得好.这是因为本文的算法专门针对检验检测指标进行设计,因而能取得更好的效果.
4 结 论
本文针对区域医疗健康平台中的检验检查指标标准化,先根据指标的字面特征进行聚类,再使用相似度特征和分块打分特征迭代地进行二分类映射.实验表明,最终的二分类映射,其F1-score可以达到85.27%,优于现有方法.在未来,可以将指标的同义词信息及参考值信息应用到聚类算法之中,并尝试使用更多的相似性度量特征,以获得更好的结果.
致谢感谢上海中医药大学的张海涛同学和上海信医科技有限公司的王俊同学在数据集标注上提供的帮助!
猜你喜欢
医学美学美容(2021年21期)2021-11-20
考试与评价·七年级版(2021年2期)2021-08-14
初中生学习指导·中考版(2020年7期)2020-09-10
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
医学新知(2019年4期)2020-01-02
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年13期)2016-10-17
股市动态分析(2016年11期)2016-10-11
股市动态分析(2016年10期)2016-09-30
恋爱婚姻家庭·养生版(2013年2期)2013-05-14
