
基于时空域深度神经网络的野火视频烟雾检测
2019-09-13 03:38:32高联欣宋岩贝李佳欣
计算机应用与软件 2019年9期
张 斌 魏 维 高联欣 宋岩贝 李佳欣
(成都信息工程大学计算机学院 四川 成都 610225)
0 引 言
在现实生活中,火灾突发性难以控制,特别是野外森林火灾的发生不仅会使自然生态系统遭到严重破坏,而且还会对人类生命财产构成了严重威胁。由于烟雾的出现早于火焰之前,因此开发一种有效的早期森林火灾烟雾的检测方法具有重大的理论和现实意义。目前,研究者们在文献中提出的基于视频的火灾烟雾检测算法大多集中在颜色和形状等特征上,他们通常构建一个多维特征向量,然后作为SVM、神经网络、Adaboost等分类算法的输入。
文献[1]提出一种基于图像处理技术的特征提取算法和基于计算智能策略的分类器来检测烟雾的方法。该方法在检测过程着重于提取烟雾的颜色特征、边缘特征和运动区域检测等,然后使用两层前馈神经网络来判别不同帧中的烟雾的区域,但是该算法对于野外复杂场景下的烟雾检测适用范围有限。文献[2]提出了一种基于时空特征袋(BOF)模型的特征提取方法,他们从当前帧块中提取HOG作为空间特征,并且基于由热对流而使烟雾扩散方向向上的事实,提取HOOF作为时间特征。通过结合静态和动态特征,最后通过随机森林分类器进行分类,该方法检测效果良好。文献[3]通过连接局部二值模式(LBP)和基于局部二值模式方差(LBPV)金字塔的直方图序列提取了一个有效的特征向量,并采用BP神经网络进行烟雾检测识别,但是该算法对于稀薄烟雾的检测效果较差。文献[4]通过高斯混合模型(GMM)进行背景建模后提取疑似烟雾区域,并通过NR-LBP(非冗余局部二进制模式)特征描述烟雾纹理,然后通过支持向量机进行分类,但是在检测野外火灾烟雾下会出现误判。文献[5]首先使用背景差分法找出运动目标区域,然后设置一个采样缓冲区进行运动区域检测,接着利用自定义阈值函数进行烟雾的颜色、面积增长率和运动方向的分析,最后根据这些特征进行分类识别,但是该方法对于野外远距离烟雾检测效果较差。
传统的视频火灾烟雾检测方法通过依靠专业知识来手工设计的相关特征,然后创建基于规则的模型和判别特征。但这样的研究方法不能很好地适用于各种情况。近年来,基于深度学习的卷积神经网络(Convolutional neural network,CNN)模型在图像分类[6]和物体检测[7]等多个计算机视觉应用领域中,与传统机器学习方法相比具有更强大的特征学习和特征表达能力。Xu等[8]在视频图像序列上利用AlexNet网络结构检测人造的烟雾图像,准确率最高达到了94.7%。Frizzi等[9]构建了自己的CNN,类似于著名的LeNet-5网络结构,增加了卷积层中的特征图数量。作者在真实的烟雾场景进行测试,达到了97.9%的精确度,这比传统的机器学习方法的性能更高。陈俊周等[10]提出了一种级联的卷积神经网络烟雾识别框架,他们将CNN引入到烟雾的静态纹理和动态纹理中以进行特征提取,该方法有效降低了非烟雾区域的误检率。
CNN直接在原始RGB帧上运行,而不需要特征提取阶段。虽然目前很多文章中使用更深层次的CNN网络结构来提取特征,但它们并没有利用上时域中的特征。烟雾具有动态性,它会随着时间的变化而改变形状,循环神经网络(RNN)则可以累积一组连续帧之间的运动信息。因此,本文提出使用CNN和RNN的组合来进行视频烟雾的检测,详细的烟雾检测框架如图1所示。
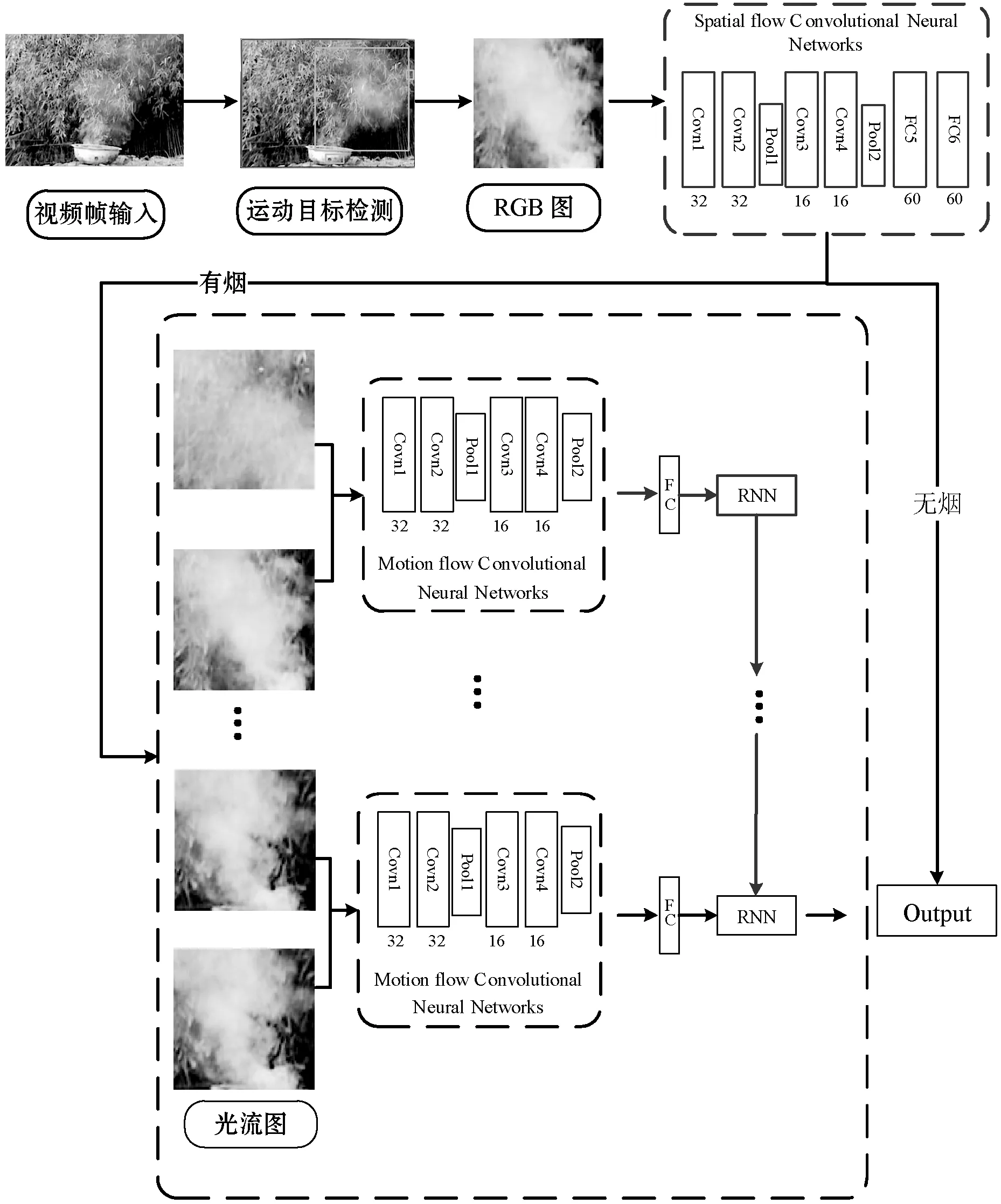
图1 基于时空域深度神经网络的野火视频烟雾检测框架
算法首先通过使用在文献[11]中提出的烟雾运动目标检测方法来检测出视频帧中的运动区域;然后,将这些候选运动区域作为空间流网络的输入以提取空域特征;为了充分利用视频中烟雾的运动信息,当候选运动区域被空间流网络CNN识别为有烟时,则取出该区域左右相邻两帧图像的相对应区域,并对连续两帧图像通过时间流网络进行处理,以获取相邻帧中对应区域之间的运动信息,最后输入给RNN进行时间上的运动特征累积,以进一步降低误检。现有的只利用空域特征的深层次CNN以及本文方法(去掉时间流网络和RNN部分)进行了对比实验,结果表明,本文所提出的网络模型实验结果表现出了较高的分类检测准确率,最后在多个真实视频场景中进行了测试,实验结果表明本文算法具有良好的准确性和实时性。
1 运动目标检测
常用的提取运动目标检测的方法有:光流法、帧间差法和背景减除法等。本文的视频烟雾检测过程由运动区域提取和对运动区域进行特征提取并分类识别这两大部分组成,具体的视频烟雾检测框架如图1所示。
在图像处理中,帧差法是一种通过对视频图像序列中相邻两帧作差分运算来获得运动目标轮廓的方法[12]。当监控场景中出现物体运动时,通过差分图像可以快速获得运动区域,但当移动目标快速运动时就会出现“重影”和“孔洞”现象,但对于运动较缓慢的烟雾,其检测效果不理想。因此,根据帧差法的原理,本文使用在文献[11]中提出的基于混合高斯模型和改进的四帧差法相结合的算法来检测运动目标。具体算法描述如下:
(1) 通过改进的四帧差法的算法和混合高斯模型分别对视频图像进行运动目标检测及背景建模以获取前景图像。
(2) 将它们得到的图像进行逻辑“或”运算并进行形态学处理,目的是为了去除图像中的噪声以及空洞现象等,最终提取出比较完整的运动目标区域。文献[11]运动目标区域检测的算法流程图如图2所示,算法最终对视频的检测结果如图3所示。

图2 运动目标区域检测流程图

图3 运动目标检测效果示例图
2 候选运动区域缩放
首先通过在文献[11]中提出的算法从视频帧中提取出疑似烟雾运动区域,再通过空间流网络来初步计算这些候选运动区域是否含有烟雾的特征。因为空间流网络结构对输入图片的大小是固定的,所以必须将这些疑似烟雾运动区域的图像数据转换到固定的大小。因此我们采用插值缩放[13]的方法(这种方法很简单,就是不管图片的长宽比例,不管它是否扭曲,全部缩放成CNN输入的大小),然后将这些缩放后的候选运动区域输入到CNN以提取用于初步确定该区域是烟雾域还是非烟雾域的特征。
3 基于时空域深度神经网络的烟雾识别模型设计
由于烟雾没有固定的轮廓和颜色,在传统的火灾烟雾图像识别研究中,研究者们需要根据一定的专业和先验知识来手工设计和处理特征。然而基于手工设计和处理特征的传统烟雾检测算法难以描述烟雾的本质属性,从而影响烟雾检测的准确性。但是卷积神经网络不需要将特征提取和分类训练两个过程分开,它在训练的时候就自动提取最有效的特征,具有强大的特征提取能力。同时CNN训练的模型对缩放、平移、旋转等畸变具有不变性,有着很强的泛化性。因此,我们将缩放后的这些候选运动区域作为空间网络的输入以提取空域特征,并在有烟的基础上进一步利用RNN进行时间上的运动特征累积,最后使用Softmax损失函数进行分类识别。
3.1 时间流网络结构
空间流CNN架构包括1个输入层、4个卷积层、2个子采样层、3个全连接层,我们利用Softmax回归模型对最后1个全连接层进行分类,以初步判断该候选区域是否含有烟雾。具体设计的网络结构如图4所示。

图4 空间流网络结构
空间流网络的输入大小为64×64的RGB彩色图像,然后依次经过两次卷积运算,取卷积核大小为5×5,步长为1,滤波数为32对输入图像进行卷积。第三层为池化层,作用是对激活函数的结果再进行池化操作,即降采样。我们使用最大池化方法,保留最显著的特征,并提升模型的畸变容忍能力。池化层使用池化的核大小为3×3,步长为2。第四和第五两个卷积层的卷积核大小为3×3,步长为1。最后两个全连接层每层有60个神经元,输出层有2个神经元,分别与最后的分类结果(有烟雾与无烟雾)相对应。为避免在全连接层上出现过拟合的现象,在全连接层中,网络采用Dropout[14]方法避免过拟合情况的发生。在每一个卷积层后用一个修正线性单元(Rectified Linear Unit,ReLU)激活函数,目的是将前面卷积核的滤波输出结果,进行非线性的激活函数处理。ReLU激活函数[15]的公式如下:
f(x)=max(0,x)
(1)
当输入特征值x<0时,输出为0,训练完成后为0的神经元越多,稀疏性越大,提取出来的特征就越具有代表性,泛化能力越强;当输入特征值x>0时,输出等于输入,无梯度耗散问题,收敛快。
3.2 运动流网络结构
在实际应用中, 雾气、云等都可能与火灾烟雾具有相似的特征,但火灾烟雾会随着时间的变化而改变它的形状。光流原理是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法[16]。因此,为进一步充分利用视频中烟雾的运动信息,当候选运动区域被空间流网络CNN识别为有烟后,提取该烟雾区域左右相邻两帧图像的相对应区域,并对连续两帧图像通过时间流网络进行处理,以获取相邻帧中对应区域之间的运动信息,最后输入给RNN进行时间上的运动特征累积,以进一步降低误检。
时间流网络包含了4个卷积层,在每个卷积层之后使用非线性函数Tanh函数。把该烟雾相对应区域左右相邻两帧图像的连续两帧作为输入,输入大小为64×64×4。每一层具体网络参数设置如表1所示,网络的最后一层是全连接层,输出向量为60维。

表1 时间流网络结构及参数设置

续表1
3.3 运动信息累积
在烟雾检测问题中,累积的运动信息非常有用,为了更好地提取视频序列中运动背景信息的运动特征,我们采用RNN网络,该网络可以处理任意长度的时间序列,从而可以通过该神经网络解决聚合运动上下文信息的问题。尤其是RNN网络具有前馈连接,其允许在一段时间内保存信息并基于当前帧和前一帧的信息产生输出。一个标准的RNN结构图如图5所示,对于给定的RNN网络,横向连接用作存储器单元,其允许在任何时间的信息流动。

图5 一个标准的RNN结构图
图5中,x、h和o分别表示输入层、隐藏层和输出层,L为损失函数,y为训练集的标签,t代表t时刻的状态,V、W、U是权值。则RNN在t时刻的输出以及最终模型的预测输出如下所示:
o(t)=Vh(t)+c
(2)
(3)
式中:σ为激活函数,一般使用Tanh函数。
4 实 验
本文使用Keras[17]和Tensorflow[18]来构建和训练所提出的CNN模型。为了便于比较,我们还使用Keras和Tensorflow实现了其他3个经典的卷积神经网络架构以及一个具有深层次的网络VGG-16。所有的实验都是在配备Intel(R) Core i3-6100 CPU @ 3.70 GHz和NVIDIA Tesla M40 GPU的PC上运行的Ubuntu 16.04操作系统中进行的。实验中还使用到OpenCV-3.1.0库和Python 3.5。
4.1 数据集
空间流网络的实验数据集图片来源于袁非牛教授实验室。数据集分为4组,分别命名为Set1、Set2、Set3和Set4。Set1有1 383张图像,Set2有1 505张图像,Set3有10 712张图像,Set4有10 617张图像。我们将Set3和Set4合并作为一个训练集,共计21 329张图像;将Set1和Set2合并作为一个测试集,共计2 888张图像。
如图6所示,烟雾和非烟雾的内部和外部类别差异非常大。图6展示了数据集中的一些示例图像,所有图像都来自生活中真实的场景。

(a) 烟雾图像 (b) 非烟雾图像图6 部分图像数据集示例
我们将来源于土耳其比尔肯大学信号处理小组、韩国启明大学计算机视觉和模式识别实验室、意大利萨莱诺大学机器智能实验室、内华达大学雷诺分校的计算机视觉实验室的野外火灾烟雾数据集,以及从YouTube、Youku等视频网站收集并截取出大量野外火灾烟雾的视频段,构建为一个新的共5 000个视频段的时间流网络数据集。其中有烟和无烟部分分别从有烟视频与无烟视频中截取,且均不与测试视频重复。实验中随机选择80%样本作为训练集,其余的作为测试集。

图7 部分视频集数据示例
4.2 网络模型训练
本文实验是基于Keras[17]平台实现的,且卷积网络模型的训练使用了GPU并行处理。CNN使用4.1节中的数据集进行训练。在训练过程中,我们选择了Adam optimizer[19]来优化网络损耗,Epoch设置为200,一次处理图片的最小输入的数量(BATCH_SIZE)为64,设置动量系数为0.9和权重衰减值为0.000 5,初始学习率为0.001,学习率在每10 epoch后缩小0.95倍。
4.3 评价指标
对于林火视频烟雾检测的性能测试,我们使用文献[20]提出的评估方法,公式如下:
(4)
(5)
(6)
式中:ACC表示准确率,N为样本总数;TPR表示被预测为烟雾的烟雾样本结果数,即检测率;TNR表示被预测为非烟雾的非烟雾样本结果数,即误检率;TP表示烟雾总数中正确检测到烟雾的数量;FN表示未被识别的实际烟雾区域的数;FP表示认定为烟雾的非烟雾数量;TN表示认定为非烟雾区域的非烟雾区域数量。
将本文方法与AlexNet[15]、Frizzi[9]、文献[21]中提出的算法以及和本文方法(去掉时间流网络)进行了对比,Frizzi[9]中使用的是一个具有8层结构的网络,而文献[21]中则采用的是较深层次的网络。我们基本上使用了4.2节中描述的与训练相关的超参数,并根据不同的网络架构调整了输入图像的大小。为了公平比较,所有比较的算法都使用同一个训练集,并且所有的网络模型都是从零开始训练。

表2 与不同的方法比较结果
从表2的数据结果可以分析出,与AlexNet、Frizzi和文献[21]中烟雾检测方法相比较,我们的方法在烟雾检测准确率和检测率都有更好的表现。尽管AlexNet、Frizzi中和文献[21]中的网络在烟雾检测方法检测准确率较高,但是这三种网络结构是无法累积一段视频的上下文的运动信息的。相比较而言,本文中的网络模型在去掉时间流网络和RNN单元之后,烟雾检测的准确率和检测率都下降了至少1%,由此说明时间流网络和RNN单元在本文的烟雾检测框架中起着重要的作用,意味着RNN单元累积了有效的上下文运动信息,这种上下文信息不仅能够很好地学习到图像的特征,还具有较高的检测正确率,有利于提高烟雾检测的准确率。
4.4 本文算法用于视频烟雾检测结果
本文算法在多个视频场景中进行测试,鉴于篇幅有限,图8仅列出9组视频的检测结果,其中视频1至视频5为含有烟雾的视频,视频6至视频9为与无烟雾的干扰视频,主要是自然景观中的云雾,视频图像大小为320×240像素。可以看出本文算法在多种场景下都具有良好的检测效果和一定的抗干扰能力。

图8 9组测试视频的检测结果图
实验测试结果如表3、表4所示。从表3中可以看出,在视频1中,文献[21]的算法比本文方法提早检测到烟雾,但本文算法在其他场景下的检测性能都不错。从表4中可以看出,在无烟雾的测试条件下,不同视频场景中出现了与烟雾颜色相近的白雾、移动的乌云以及摆动的树叶等干扰物,本文的算法在这些场景中都没有出现误检的情况,这说明本文算法具有较强的抗干扰能力,但是其他四种算法相对来说有一定的误检。总而言之,实验结果表明本文视频烟雾检测算法具有良好的准确性和实时性,并证明了时间流网络和RNN单元在本文的烟雾检测框架中起着重要的作用,在视频烟雾检测方面有更好的表现。

表3 有烟雾测试视频的检测结果

表4 无烟雾测试视频的检测结果
5 结 语
传统的烟雾检测方法是从输入图像中手动提取特征,然后使用分类器对烟雾进行分类和识别,这个过程通常比较复杂和繁琐。本文提出一种基于时空域深度神经网络特征提取与分类的林火视频烟雾检测算法。算法提取出候选运动区域的空域特征,当候选运动区域被空间流网络CNN识别为有烟时,进一步充分利用视频中相邻帧中对应区域之间的运动信息,最后输入给RNN进行时间上的运动特征累积,以进一步降低误检。与仅提取空域特征的烟雾检测方法进行了对比,实验结果表明,本文方法能够在多个视频场景下准确检测烟雾区域,检测性能得到改善,降低了检测失败率,并且具有一定的抗干扰能力。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小学阅读指南·低年级版(2021年3期)2021-03-19 06:12:40
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
华人时刊(2019年13期)2019-11-26 00:54:38
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
当代陕西(2017年12期)2018-01-19 01:42:05
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
科学启蒙(2014年12期)2014-12-09 05:47:06
