
城市暴雨洪涝敏感性因素数据仓库构建与应用
2019-09-10 07:22江子皓王慧亮吴泽宁胡润停
人民黄河 2019年4期
江子皓 王慧亮 吴泽宁 胡润停






摘要:随着大数据技术的发展,基于大数据技术开展城市暴雨洪涝研究成为热点。根据城市防洪工作中对暴雨洪涝相关数据的业务需求,在对多源异构数据分析的基础上,设定洪水敏感性因素分析主题,构建相应的多维数据组织模式,建立城市暴雨洪涝数据仓库,有效地对城市暴雨洪涝多源异构数据进行储存、管理与组织。基于洪水敏感性因素分析主题数据仓库,利用关联规则分析进行数据挖掘,识别不同敏感性因素与洪水度量之间的关联规则,归纳出敏感性因素与洪水过程之间的关系,结果表明:将城市暴雨洪涝数据集成到数据仓库中并进行相关的数据挖掘操作,可以为防洪决策提供新的可行途径。
关键词:城市暴雨洪涝;数据仓库;关联规则;数据挖掘
中图分类号:TP392
文献标志码:A
doi:10. 3969/j .issn.1000- 1379.2019. 04.007
1 前言
随着水利信息化建设的不断完善,以及遥感、GIS、物联网等现代信息技术的发展和应用,城市防洪减灾相关数据快速增长[1],具有数据量大、数据结构复杂、数据来源多样、数据价值密度低等典型的大数据特征,如何构建针对城市洪涝的数据仓库并对数据加以有效利用,成为城市水文学研究的难点[2]。数据仓库可以有效集成多源异构数据,用于支持管理决策过程[3],同时用户可以在数据仓库基础上进行聚类、关联等决策分析,通过数据挖掘得到数据背后隐藏的信息。
目前国内外防洪领域数据仓库技术已有一些应用研究成果,H_ Mcgrath等[4]建立一个数据仓库来存储相关洪水预报数据,应对加拿大新不伦瑞克省城市洪水风险管理的需要,介绍了如何定位和搜集城市防洪数据仓库所需数据集,并提出了该数据仓库未来可以有哪些应用方向,包括利用聯机分析处理( OLAP)和数据挖掘工具进行防洪决策支持以及实现城市防洪数据在线可视化等:Z.Pan-Pan等[5]利用OWB工具建立防洪数据仓库与分布式数据源之间的数据语法系统,根据系统环境差异和数据复杂性等对原始数据进行筛选,最终实现了防洪信息的实时性;张蓉[6]利用数据仓库技术集成了大连市各水库防洪数据,保证了这些防洪数据能够实时共享,并利用联机分析处理( OLAP)从不同角度对防洪数据进行分析,达到了对数据充分利用的目的:丁斌等[7]利用数据仓库技术建立黄河防洪调度综合决策会商支持系统,采用科学的数据组织方法将不同数据源进行集成并直观地提供给防洪决策者,目前已广泛应用在防洪、防凌、调水调沙和水资源调度等工作中:梁国华等[8]进行了应用于洪涝灾害预防的数据仓库研究,认为目前数据仓库技术的研究与开发尚在起步阶段,难以满足决策支持系统或某些特殊领域要求。总体来说,目前国内外数据仓库技术在防洪领域中应用研究较少,且这些研究大多着重数据仓库结构体系及建模方法研究,很少进行相关实例应用研究。本文结合郑州市洪涝基础数据,尝试将城市暴雨洪涝数据仓库与数据挖掘技术相结合,挖掘分析不同敏感性因素与暴雨洪涝之间的内在联系,为防洪决策提供支持。
2 基于洪水敏感性分析主题的城市暴雨洪涝数据仓库构建
2.1数据仓库规划与需求分析
建立数据仓库一般以一个主题或若干个主题来完成[9].所包含的数据是根据不同的需求场景进行综合的,也就是不同的主题。主题是在较高层次上将信息系统中的数据进行综合、归类和分析利用的一个抽象概念,在逻辑上主题可以表达为某一宏观分析领域所涉及的分析对象[10]。由于城市暴雨洪涝涉及面过广,因此在建立数据仓库的时候应设定相应的主题来应对不同的城市防洪决策需求。本文设定的主题为洪水敏感性因素分析,结合水文、地质、气象、社会经济等数据资料,根据洪水灾害发生与否或灾害程度根据找出不同敏感性因素与洪水之间的联系。
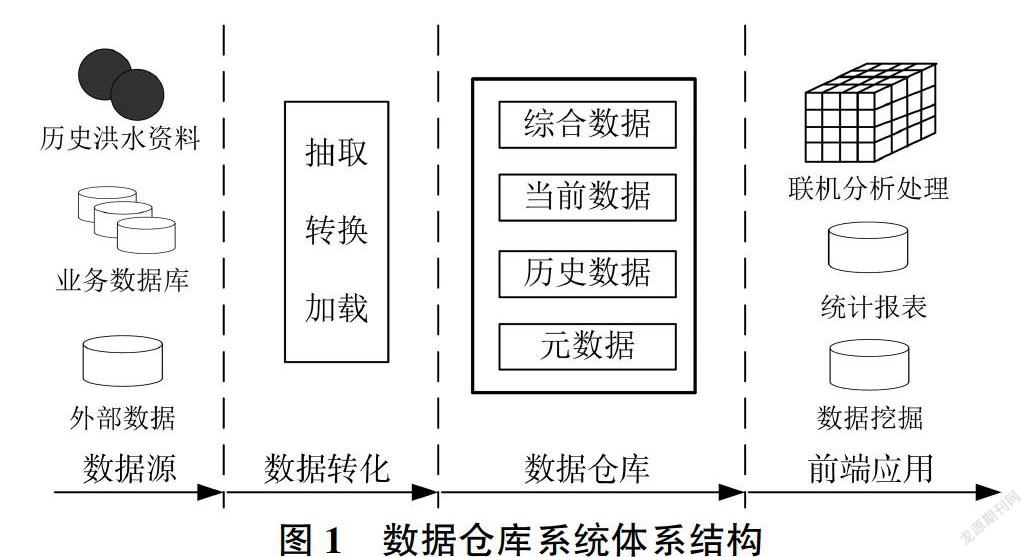
洪水敏感性因素分析数据仓库是在多个数据源基础上建立起来的信息集成平台[11],在对不同数据源进行分析之后,将多源异构数据通过ETL(抽取、转换、加载)工具转换成统一的格式,并输人数据仓库中,然后通过OLAP(联机分析处理)或数据挖掘技术对数据进行分析,找到开发者想要的数据之间的联系,即能够为防洪决策提供支持的知识。图1为洪水敏感性因素分析数据仓库系统体系结构。
(1)数据源:洪水敏感性因素分析数据仓库包括各个可能对城市洪水过程造成影响的数据,涵盖承灾体、致灾因子、孕灾环境和灾害本体,一般来自于多个数据源,包括已建成的暴雨洪涝数据库、地理信息数据库等业务数据库,统计的历史场次洪水降雨量、积水水位、流量等观测数据,还有各类防洪规划、行政区划、流域水系等外部数据。
(2)数据转化:在了解所需数据类型、范围、位置的基础上,通过ETL工具将不同数据源中分散或标准不统一的数据抽取出来,经过聚合、函数、组合等转换,最终加载到目标数据仓库中。
(3)数据仓库:数据仓库可以看作一个整合了不同业务数据的统一数据中心,除业务数据外,还有一类管理存储数据的元数据,主要指数据结构以及描述结构的信息,而且定义了数据之间的逻辑联系以及数据转换的操作规则,将数据仓库系统有机结合起来。
(4)前端应用:数据仓库的应用主要包括数据查询和报表、应用开发、联机分析处理( OLAP)、数据挖掘,在本研究中针对基于洪水敏感性因素分析主题数据仓库进行数据挖掘应用。
2.2 数据仓库建立
本研究选取郑州市区为研究区,并将其划分为3 324个子区域[12]。为了找出在降雨时有哪些属性对洪水过程有较大影响,搜集整理各子区域的面积、土地利用类型、地形条件、行政区划等数据,还有2011-2014年共12场历史洪水的降雨蒸发数据以及各子区域内的平均水深、最大水深、总径流量、高峰流量以及积水时长数据。
针对洪水敏感性因素分析主题所包含的数据类别进行分析,将城市暴雨洪涝数据立方体分为日期、水文气象、地形、行政区划、土地利用5个维度和平均深度、最大深度、总径流量、高峰流量、积水时长5个度量,具体维度所包含的属性见表1。
加上已确定的暴雨洪涝度量值,可以设计出城市暴雨洪涝洪水敏感性因素分析主题的数据仓库逻辑模型,见图2。
3 基于关联规则的城市暴雨洪涝敏感性因素分析
3.1 数据预处理
基于数据仓库开展城市暴雨洪涝敏感性因素分析,也就是数据挖掘技术,其数据直接来源于洪水敏感性因素分析主题数据仓库中的数据。为了分析子区域内不同属性与洪水之间的关联规则,本次数据挖掘选取面积、不透水率、坡度、各土地利用类型面积占比作为敏感性因素,平均水深、最大水深、总径流量、高峰流量以及积水时长作为洪水事实度量,挖掘不同敏感性因素与度量之间的关联规则,其中子区域的平均水深、最大水深、积水时长以积水点监测数据为准。将以上敏感性因素与度量分别按表2和表3所列分类标准离散化。分類标准由历史经验确定,虽然经过离散化的数据会丢失许多细节,但变得更有意义,由此才能产生出能被大众所接受的规则[13]。
3.2 关联规则分析及Apriori算法
关联规则分析是数据挖掘中一个重要的分支[14],本次应用是为了发现城市暴雨洪涝数据仓库中不同项(维度属性与事实度量)之间的联系,这些联系构成的规则可以帮助决策者进行防洪决策。关联规则表达的是项之间的关系,如规则X→Y表达了X决定Y,其中X看作规则的前件,Y看作规则的后件。在本次关联规则分析中,前件指需要进行分析的维度属性(洪水敏感性因素),后件指洪水事实度量,支持度(SLLpport)和置信度(confidence)用来描述规则的强度。
对于规则X→y.若支持度太小,表示X与Y在事务数据库很少同时出现,关注这条规则没有实际意义;若置信度太小,表示Y受X的影响程度很低,关注这条规则同样没有意义。因此,需要给定一个最小支持度阈值min_sup和最小置信度阈值min_conf,在城市暴雨洪涝系统中,只有规则X→Y的支持度≥min_sup且置信度≥min_conf时,才称规则X→Y,为强关联规则,也就是对防洪决策有用的规则。
其中强关联规则的挖掘重点在于如何找到频繁项集,对于全局项集I的非空子集I,若support(I1)≥min_sup,则称,,为频繁项集;若I1中包含有,的k个项,则称,I1为频繁k-项集。
传统的关联规则算法基本步骤为:找出所有支持度大于最小支持度阈值的项集,检验是否满足最小置信度阈值要求,生成强关联规则。传统方法采用的是穷举法的思路,在求频繁项集的过程中对每个非空集合都要遍历事务数据库,以求出它的支持度是否满足最小支持度阈值,显然这个方法是十分低效的。本研究选用Apriori算法进行数据挖掘,目的是改进求频繁项集的简单低效算法,采用逐层搜索策略产生所有的频繁项集[15].其基本原理是若项集A是一个频繁项集,则4的任意非空子集同样是频繁项集,方法具体描述如下:
设C为长度为k的候选集合,L为长度为k的频繁项集的集合,先找到所有的频繁1-项集的集合L1,由L2,生成候选集合C2,再由C2生成L2,即频繁2-项集的集合,然后由L2生成候选集合C3。依此类推,直到没有新的频繁k-项集被发现。这个方法只需在求每一个L时对事务数据库作一次完全扫描,效率得到显著提高。在本次关联规则挖掘应用中,选定最小支持度阈值为0.1,最小置信度阈值为0.5。
3.3 结果分析
应用上述数据挖掘算法与预处理的数据进行数据挖掘操作后,得到476条强关联规则,但其中存在许多没有意义的规则,比如属性与属性之间、度量与度量之间的关联规则。经过筛选和归纳整理之后,得出6条与洪水相关的强关联规则,这也是进行防洪决策所需要的规则,见图3。
对以上强关联规则进行分析,得到以下结论。
(1)从前两条规则看出,水域面积过小容易造成在降雨时发生较长时间的积水和较大的淹没深度,特别是建筑面积过大导致区域透水性降低,会使受灾程度加重。其原因是河湖水域可以对雨水进行储蓄、调节和传输,从而使得临近区域不容易发生积水,在以后的城市发展规划中可以增加水域面积以减轻城市暴雨洪涝灾害的影响。
(2)从第三、第四和第五条规则可以看出,在城市化过程中林草地面积降低,建筑和道路面积占比增大,进而导致城市不透水性增强,使得雨水汇流速度加快,而且城市管网规划建设不足,无法提供足够的排水管网,导致雨水无法顺利排走而发生大的洪水,在以后的城市发展规划过程中需要增加城市绿地面积占比以及修建足够的排水管道。
(3)从最后一条规则可以看出,面积较小和坡度分类为2的子区域可能在降雨发生时产生较大的洪水,原因是这些子区域汇流过程较为简单,雨水会迅速排到相应的积水点,造成积水过深的情况,在进行城市防洪决策时应重点防护这些汇水面积小且具有一定坡度的区域。
4 结语
本文针对洪水敏感性分析主题数据仓库进行构建,确定了数据仓库所需数据源、数据仓库体系结构和多维数据模型组织方式,并采用基于关联规则的Apriori算法对郑州市近年12场洪水资料进行数据挖掘应用,得到6条强关联规则,发现对城市暴雨洪涝影响最大的因素有区域透水性、坡度和排水管道密度等。在未来城市建设过程中,这些因素是需要重点关注的,即通过数据仓库的建立和数据挖掘应用能够对城市防洪决策工作提供支持。
目前数据仓库技术在防洪领域的应用还处于起步阶段,暴雨洪涝数据离散化还没有一个统一的分类标准,不同的分类标准可能会导致挖掘结果大不相同,如何建立准确的分类标准是基于大数据技术开展城市洪涝研究的重点和难点,还有待进一步研究。
参考文献:
[1]杨太萌,基于大数据的城市防汛决策支持系统研究[D].杭州:浙江大学,2016:1-5.
[2] 李恒义,孟琳琳,基于海绵城市的北京市巨灾洪水防御体系设计[J].人民黄河,2016,38(7):35-38.
[3] INMON W H.Building the Data Warehouse[M]. USA: JohnWiley&Sons,Inc. 2002:1-3.
[4]
MCCRATH H, STEFANAKIS E,NASTEV M.Developmentof a Data Warehouse for Riverine and Coastal Flood RiskManagement[J].ISPRS - International Archives of the Pho-togrammetry, Remote Sensing and Spatial Information Sci-ences,2014(2):41-48.
[5] ZHANC P P,SUN P J,CUO X J.Application of OWB onData Syntaxis of Flood - Control System[J].InformationTechnology, 2013, 37(3):139-142.
[6] 張蓉,大连市防洪减灾决策支持系统设计[D].大连:大连理工大学,2014:1-35.
[7] 丁斌,姚保顺,杜文,黄河防洪调度综合决策会商支持系统建设[J].水资源保护,2017,33(6):55-59.
[8] 梁国华,周惠成.防洪数据仓库的结构模型研究及应用[J].辽宁工程技术大学学报,2003,23(1):88-91.
[9]吴召俊,某银行的企业级数据仓库设计探究[J].电子技术与软件工程,2014(5):195.
[10] 朱传华,三峡库区地质灾害数据仓库与数据挖掘应用研究[D].武汉:中国地质大学,2010:11-29.
[11] 陈德清,王问宇,杨海坤,数据仓库技术在水文数据综合分析中的应用研究[J].水利信息化,2010(3):18-21.
[12] 王慧亮,吴泽宁,胡彩虹,基于CIS与SWMM耦合的城市暴雨洪水淹没分析[J].人民黄河,2017,39(8):31-35.
[13] 张骏,数据仓库和数据挖掘在马鞍山供水系统中的应用[D].哈尔滨:哈尔滨工业大学,2007:21-32.
[14] 李春葆,数据仓库与数据挖掘实践[M].北京:电子工业出版社,2014:85-86.
[15] ACRAWAL R,IMIELINSKIT,SWAMI A.Mining Associ-ation rules Between Sets of Items in Large Databases[ J].ACM, Acm Sigmod Record. 1993, 22(2): 207-216.
猜你喜欢
电子乐园·下旬刊(2021年3期)2021-02-08
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
国外科技新书评介(2016年8期)2016-11-16
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
哈尔滨理工大学学报(2016年2期)2016-09-12
卷宗(2014年12期)2014-04-02
档案管理(2009年3期)2009-05-22
计算机教育(2006年9期)2006-09-22
