
基于LDA主题模型的短文体自媒体结构化分类方法研究
2019-09-10 07:22:44李贤阳邱桂华阳建中李长彬
荆楚理工学院学报 2019年6期
李贤阳 邱桂华 阳建中 李长彬




摘要:针对传统文本处理中非作用词的存在影响主题的可解释性,以及短文本篇幅短小、特征不明显等问题,提出了一种基于LDA模型的主题分类的改进算法。该算法通过信息的增益来过滤文本,同时与最优主题的选择方法相结合,利用算法建立起的分类规则对文本进行分类。实验结果表明,该方法通过改变作用词占比、特征词典的大小,可以有效的提升文本分类的准确性。
关键词:LDA模型;短文本分类;主题模型
中图分类号:TP391.1 文献标志码:A 文章编号:1008-4657(2019)06-0005-04
0 引言
随着移动互联网的飞速发展,人们的日常生活被QQ、微博、微信等网络信息所包围。这些信息都有同一个特点:他们都以短文本为信息表现形式,具有词汇少、特征维度高、稀疏等特点[1-2]。因此,对于信息快速分类的需求日益高涨,短文本分类技术在信息检索、搜索引擎、话题跟踪等领域越来越受到研究人员的关注[3]。
在主题挖掘的对象变为微博这样的短文本数据时,传统的主题模型就变得不那么合适了,其原因主要有以下两点:1、如果用针对长文本的分类方法计算短文本的词频-逆文本频率(TF-IDF),其上下文关联性强,易丢失短文本语义信息。2、短文本的特点是篇幅短而特征维度高,特征向量稀疏,使用传统的LDA模型可能无法取得良好的效果。针对以上短文本的分类研究目前还较为稀少,短文本的分类问题尚未得到解决。
1 潜在狄利克雷分布
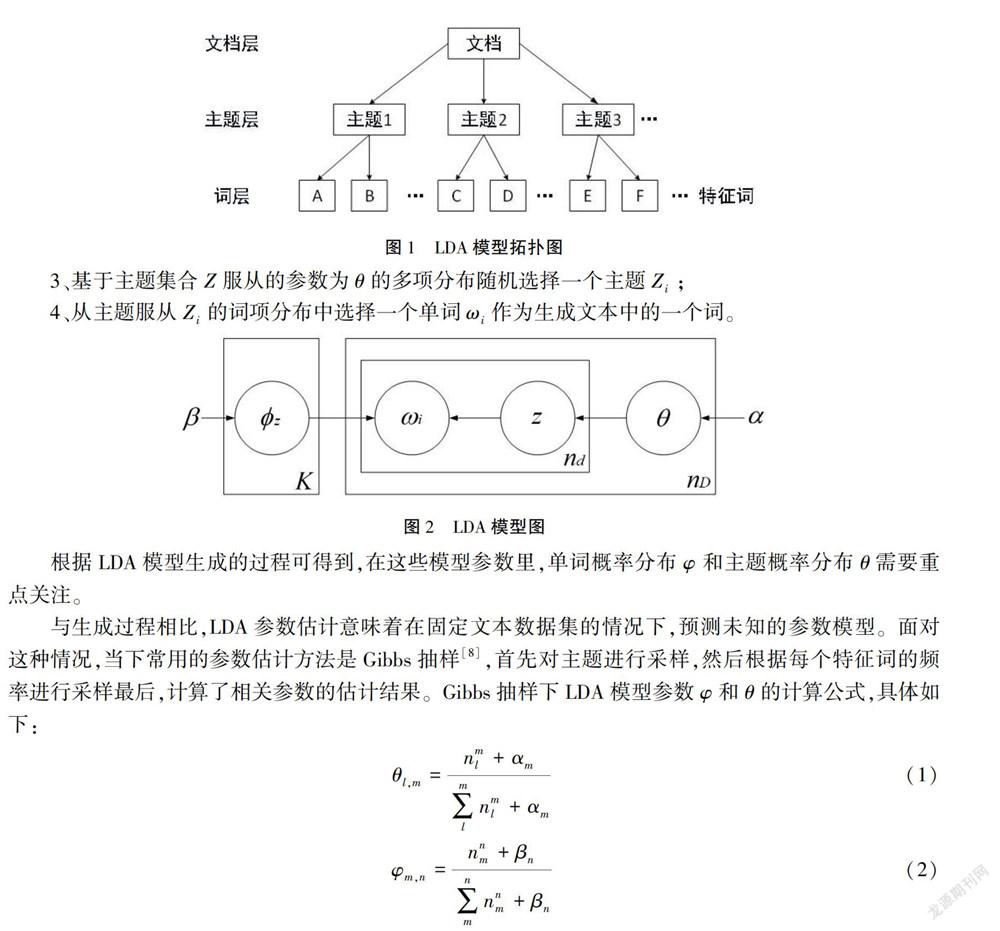
潜在狄利克雷分布模型通过引入文本主题分布思想,有效实现了对文本的降维表示,并在文本信息处理领域得到了广泛的应用[4-6]。LDA的结构,是由三层贝叶斯网络组成的,分别为词层、主题层、文档层。可以这样认为:许多个主题构成了一篇篇文章,而这些主题又是由许多个特征词汇组成的[7],其拓扑结构如图1所示。
根据LDA模型生成的过程可得到,在这些模型参数里,单词概率分布φ和主题概率分布θ需要重点关注。
与生成过程相比,LDA参数估计意味着在固定文本数据集的情况下,预测未知的参数模型。面对这种情况,当下常用的参数估计方法是Gibbs抽样[8],首先对主题进行采样,然后根据每个特征词的频率进行采样最后,计算了相关参数的估计结果。Gibbs抽样下LDA模型参数φ和θ的计算公式,具体如下:
其中,θl,m指在文档l中第m个主题的分布概率;φm,n指词项n在主题m中的分布概率;nml表示在文档l中出现主题m的频数;nnm表示在主题m下词项n出现的频数;αm对应于主题m下的狄利克雷先验;βn对应于词项n下的狄利克雷先验。
将LDA模型与参数估计思想相结合,使得LDA模型获得了在无监督条件下将文档中主题与特征词提取出来的能力。因此,当预测重大事件的趋势时,它可以替代專家知识,利用海量的新闻数据作为驱动力,来构建语义特征的指标。
2 基于LDA主题模型的改进算法
本节所讨论的内容针对微博微信中存在的短文本信息。综合词类特征和语义特征的短文本分类算法的处理流程如下:首先,采用信息增益滤波方法从短文本中选出最具代表性的词,称为特征词,使用LAD主题模型,可以根据这些众多的特征词构建对应的主题分布,选取其中一个最合适的文本主题,接下来把项目特征加入到特征字典中,得到一个新的短文本特征。在经过上述步骤之后,建立起新的分类规则对文本进行分类,算法框架如图3所示。
2.1 基于信息增益过滤的文本分类方法
利用LDA模型,来对文本进行建模,可以分析出文本的各个主题。例如通过搜索引擎进行建模,可以获取关键字“大数据”下的许多内容,有“模型、网络、算法、样本、一种、他们”等。可以十分显然的明白,“算法”这样的词汇比“一种”包含更多的信息量,而“他们”属于“非作用词”,对于分类毫无实际作用。
本文用信息增益来表示文本词汇有作用的程度,使用信息的增益来对文本信息进行过滤,能够有效提升文本分类的效率。利用信息的增益来衡量文本中的词汇对于文本的分类有无作用,并根据该作用的程度进行排序,保存那些对于分类作用大的词汇,过滤那些对分类无作用的词汇。由于主题是否对文本分类有作用是通过词汇来表现的,如果在对于分类有作用的主题中出现非作用词,将会降低文本分类的有效性和主题的可解释性;如果在对于分类无作用的主题中出现非作用词,就更加应该去除。综上所述,基于信息增益和LDA模型的短文本分类可以提高短文本分类的性能。
利用LDA模型对文本进行建模,可以得到文本在主题上的分布。设主题数为k,则:
2.2 最优主题的选择方法
在本文研究的文本分类方法当中,主题是否对文本分类有作用是通过词汇来表现的。然而,在许多短文本中,词汇内容多样而分散,对主题寻找形成了不小的挑战。对此,文章借助百度词库,以大量相似主题的长文本为参照,通过LDA模型进行训练,以期能够提升短文本在该算法中运用的分类性能。本节主要是对算法中如何选择最优主题进行了研究,最优的主题意味着该主题拥有最强的文本区分能力。因此,对主题进行加权,权重值的大小表示每个主题区分不同类别的能力。话题权重值越大,话题区分不同类别的能力越强。
具体算法步骤如下:
1、利用LDA主题模型对背景知识进行建模,获得其相应的隐含的主题分布d=t1,t2,…,tk;
2、设主题权重向量W=ωt1,ωt2,…,ωtk,初始化ωti=0;
3、对每一个长文本找出n个同类文本和n个不同类文本;
4、计算k个不同的主题分布权重值ωti;
5、选取权重值ωti最大的主题作为最优主题。
最后,基于信息增益的分类算法和最优主题算法,可以得到一个基于短文本的特征函数Fd=ωd,α·k,其中,α为文本中作用词占文本词汇的比例,ωd为特征词典的权重向量。
3 实验分析
为了充分验证本文所研究的基于LDA模型改进的文本分类方法,实验从百度词库中对数据进行爬虫获取,包含了政治、经济、社会、教育、体育、IT、医疗等七个大类。在七个大类中随机选取7 000个文本,在分类时平均分成7个组,进行交叉测试,设LDA主题数量为70,训练样本数与测试样本数按7∶3划分,训练迭代次数为2 000,测试迭代次数为4 000。
4 总结
鉴于传统文本处理中,非作用词的存在影响主题的可解释性,以及短文本篇幅短小、特征不明显等问题,提出了一种基于LDA主题模型的文本分类改进算法。首先采用信息增益过滤的文本分类方法,对非作用词进行有效过滤,同时与最优主题的选择方法相结合,建立起新的分类器对文本进行分类。通过实验改变作用词占比、特征词典的大小,可以有效的提升文本分类的准确性,验证了该种算法的有效性。
参考文献:
[1] 钱胜胜,张天柱,徐常胜.多媒体社会事件分析的研究与展望[J].南京信息工程大学学报(自然科学版),2017,9(6):599-612.
[2] 曾子明,杨倩雯.基于LDA和AdaBoost多特征组合的微博情感分析[J].数据分析与知识发现,2018,2(8):51-59.
[3] 张志飞,苗夺谦,高灿.基于LDA主题模型的短文本分类方法[J].计算机应用,2013,33(6):1 587-1 590.
[4] Zhou T,LYU R T,King I.Learning to Suggest Questions in Social Media[J].Knowledge & Information Systems,2015,43(2):389-416.
[5] Blei D,Ng A,Jordan M.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003(3):993-1 022.
[6] 邱先标,陈笑蓉.一种基于SA-LDA模型的文本相似度计算方法[J].计算机科学,2018,45(S1):106-109,139.
[7] 韩忠明,张梦玫,李梦琪,等.面向复杂主题建模的流式层次狄里克雷过程[J].计算机学报,2019,42(7):1 539-1 552.
[8] 張小平,周雪忠,黄厚宽,等.一种改进的LDA主题模型[J].北京交通大学学报,2010,34(2):111-114.
[责任编辑:许立群]
