
基于双层上下文语义分类网的遥感郊外建筑物检测研究
2019-09-10 07:22:44张旭侯金元葛娴君
河南科技 2019年8期
关键词:遥感
张旭 侯金元 葛娴君
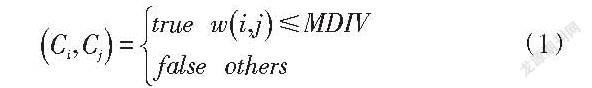



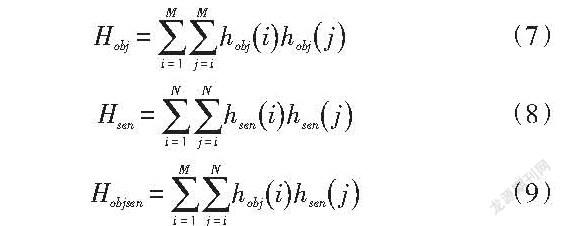
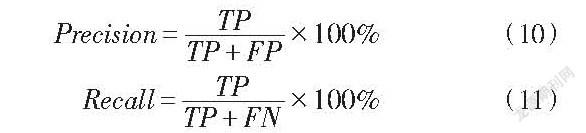
摘 要:本文提出了一种基于双层上下文语义网的遥感郊外建筑物检测方法。该方法主要包括以下两个阶段。第一阶段:郊外大视场遥感图像疑似区快速提取;第二阶段:通过构建双层上下文语义分类网对建筑物疑似区精准鉴别。实验表明,本算法具备检测精度高、虚警率低以及运算效率高等优点。
关键词:遥感;建筑物检测;上下文;双层语义网
Abstract: This paper proposed a remote sensing suburban building detection method based on double-layer context semantic network. This method mainly includes the following two stages. The first stage is the rapid extraction of suspected areas from remote sensing images with large field of view in suburbs; the second stage is the accurate identification of suspected areas of buildings by constructing a two-tier context semantic classification network. Experiments show that the algorithm has the advantages of high detection accuracy, low false alarm rate and high operational efficiency.
Keywords: remote sensing;building detection;context;bilevel semantic network
1 基于图割理论的郊外大视场建筑物疑似区快速提取
1.1 基于图论最优二叉树的郊外大视场粗分割
接着,判断集合之间的相似关系,利用集合间相似度和集合内部相似度进行判断,具体为:若两个图像区域相似度较高,则任一集合内部的相似度小于集合之间的相似度,进行合并;否则,进行分离,具体标准为:
为区域像素个数总和的反比例关系式,表示区域的边缘长度与区域面积的比值。
1.2 基于建筑物几何特征的疑似区虚警初步筛除
由于大视场的复杂性,初步分割得到的建筑疑似区中,存在大量的虚警,可利用建筑物几何特征初步筛除疑似区虚警。本文采用建筑物疑似区长宽比和矩形度的形状特征进行虚警剔除。
基于图割理论的郊外大视场建筑物疑似区快速提取示意图所示。
2 基于双层语义分类网的建筑疑似区精准鉴别
遥感图像中的郊外建筑物虽然属于同类遥感目标,但类内差异较大,影响鉴别的准确性,需要对提取获得疑似区的初级特征进行中层语义描述才能有效鉴别。本文首先通过视觉词袋对疑似区的局部描述子特征进行中层语义描述,形成对典型建筑构件的表征。接着,对中层语义特征的频次分布进行编码,形成较为抽象的直方图编码特征,建立典型建筑构件间的上下文联系。
2.1 典型建筑构件中层语义特征提取
将疑似区样本集分为视觉单词训练样本集和特征编码训练样本集。对疑似区视觉单词训练样本集进行SIFT特征提取,并由欧氏距离聚类其视觉单词,视觉单词对应建筑物典型构件。具体为:对疑似区中每个关键点邻域提取SIFT特征为描述特征,并以K-means聚类为视觉单词;接着,基于OC-SVM进行视觉单词判断准则的训练,获得视觉单词判断准则;然后,对每个疑似区样本中的所有关键构件进行视觉单词判别,并将判别结果按出现的频次统计为视觉单词直方图,每个疑似区样本对应一个视觉单词直方图,具体步骤为如下。
2.1.1 局部描述子初级特征提取。本文采用SIFT[1]算法对建筑物疑似区切片进行特征关键点提取。提取步骤包括:极值点检测、关键点精确定位、关键点方向分配及局部描述子的生成。将提取到的建筑物疑似区的SIFT初级图像特征,利用K-means聚类的方法形成视觉单词,选取k个聚类中心,其中每一个聚类的中心为一个视觉单词。
2.1.2 建立基于OC-SVM的视觉单词判断准则。为实现对样本中关键点进行典型构件属性的准确判别,考虑到属性类别数k在不同场景应用时构件类别会有增减,因此判别时选择one-class SVM对每类构件属性进行判别。基于每个关键点的局部描述子特征,利用one-class SVM建立训练准则进行判别。通过样本训练得到OC-SVM决策函数为:
2.1.3 视觉单词频次直方图构建。对每个疑似区样本中的所有关键点进行局部描述子特征提取,并进行视觉单词属性判别,则每个候选区的所有关键点将对应得到表征典型构件的中层BOW特征描述。接着,将目标及对应周域场景中的BOW特征分別利用对应的视觉词典表示为视觉词汇,对每个视觉单词出现的频率构成视觉单词直方图,提取得到的目标视觉直方图(维度为M),场景视觉直方图为[hsen](维度为N),则对疑似区域的视觉直方图可表示(。上述目标多层次上下文信息统一融合编码可以通过式(6)构建:
上下文信息统一编码[Hreg]包括多种不同层次的上下文,可以被分解为三类:目标上下文直方图、邻域场景上下文直方图以及目标与周域场景间的上下文直方图,就此完成中层特征编码。
2.2 基于典型构件中层语义特征的疑似区鉴别
2.2.1 疑似区中层语义特征的SVM分类器构造。对中层编码训练样本集中的每个建筑物疑似区样本,按上述方法提取视觉单词频次直方图特征,并利用多类SVM分类器进行训练,形成郊外建筑物与三类虚警的分类判决准则。其中,虚警目标划分为路田区域、复杂山脉区域和植被覆盖区域。
2.2.2 基于双层分类网的疑似区鉴别。对待预测的疑似区样本,经过上述“基于图割理论的郊外大视场建筑物疑似区快速提取”和“典型建筑构件中层语义特征提取”两个步骤,获得预测样本的视觉单词频次直方图特征。接着,采用上一步获得的疑似区多类SVM判断准则进行判别,获得建筑物疑似区的鉴别及分类结果。
3 实验
3.1 数据和评价方法
本文的实验数据集来自于Google Earth的北京周边郊区的大视场遥感图像,分辨率为1~2m,数据的像素大小为3 000×3 000到12 000×12 000。实验需要SVM训练样本集,故将数据集中的200副样本作为多分类样本集,其中要区分正负样本种类,最后的测试集设定为150副,用来验证本方法的有效性。
本文所用编程平台是MATLAB2016a,实验测试平台为Intel 3.6G CPU,64G 内存的服务器。
本文认为,算法检测边界框与人工标记边界框重叠比例超过70%,则检测是正确的;否则,检测是错误。并且,若存在多个算法检测边界框同时与某一个人工标记边界框重叠率符合确认的标准,则只认为其中重叠率最高的为正确检测目标。本文采用查准率Precision、查全率Recall作为实验评估指标。
3.2 实验结果分析
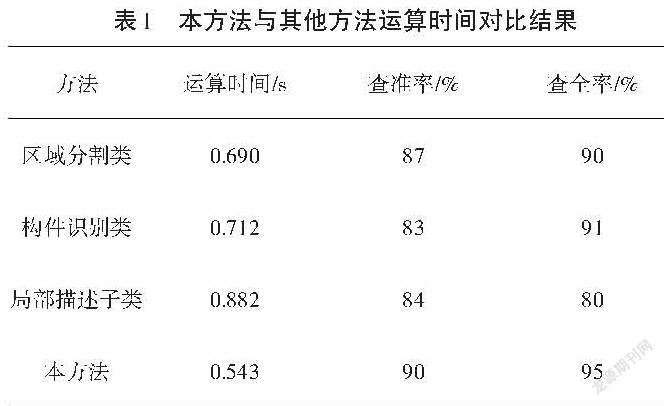
笔者将本文提出的算法与基于局域差异分割的方法[2]、基于人工指定典型建筑部位辨识方法[3]、局部描述子辨识类[4]进行比较,并记录检测结果,结果如表1所示。
在效率提升方面,由于笔者采取了候选区的快速筛选策略,因此算法用时最少,效率最高。性能方面,本文算法构建了双层分类网模型,因此能更好地描述关键部位及关键部位间的语义信息,適应建筑区这样的分布式目标检测,克服其他方法中指定关键部位或者缺乏语义描述的问题,在查准率Precision、查全率Recall两个性能指标上都优于对比的典型算法。
4 结论
根据已有研究的不足,本文提出了一种基于双层上下文语义网的遥感郊外建筑物检测方法。利用疑似区筛选加鉴别的提取框架,克服已有处理方法中计算效率低的问题。在鉴别阶段,采用基于词包视觉上下文中层语义特征提取的方法,克服由于建筑物区域形态各异、类内差异大导致的无法获取完整可靠建筑区的情况;同时,构建双层分布网络,对关键部位之间进行上下文语义描述,克服已有方法因缺乏语义描述导致建筑区提取效果不佳的问题。
参考文献:
[1]易飞,许珊珊.基于SIFT的图像匹配方法改进[J].计算机系统应用,2018(10):261-267.
[2]孙萍,邓磊,聂娟.一种基于区域分割的多尺度遥感图像融合方法[J].遥感技术与应用,2012(6):844-849.
[3] Izadi M, Saeedi P. Three-Dimensional Polygonal Building Model Estimation From Single Satellite Images[J]. IEEE Transactions on Geoscience & Remote Sensing,2012(6):2254-2272.
[4] Jung C R, Schramm R. Rectangle Detection based on a Windowed Hough Transform[C]// Brazilian Symposium on Computer Graphics & Image Processing. 2004.
猜你喜欢
湖北农业科学(2017年1期)2017-03-09 15:35:48
科技资讯(2016年26期)2017-02-28 11:27:54
商(2016年25期)2016-07-29 20:50:14
商(2016年22期)2016-07-08 14:32:30
商(2016年22期)2016-07-08 14:05:14
科技资讯(2015年32期)2016-05-25 21:41:16
环球时报(2016-05-16)2016-05-16 07:53:46
中国科技博览(2016年8期)2016-04-25 06:13:43
湖北农业科学(2015年17期)2015-10-09 21:33:30
湖北农业科学(2015年15期)2015-09-09 22:01:17
