
基于深层卷积神经网络的初生仔猪目标实时检测方法
2019-09-10 01:30沈明霞CEDRICOkinda刘龙申李嘉位孙玉文
农业机械学报 2019年8期
沈明霞 太 猛 CEDRIC Okinda 刘龙申 李嘉位 孙玉文
(1.南京农业大学工学院, 南京 210031; 2.江苏省智能化农业装备重点实验室, 南京 210031)
0 引言
我国生猪养殖数量和猪肉消费量均居世界第一位,养猪业是我国农业的支柱产业[1-2]。生猪养殖主要的经济损失来源于初生仔猪的高死亡率[3],仔猪断奶前死亡率高达13%,挤压致死率占其中的15%~51%[4]。及时检测母猪起卧等高危动作、精确快速识别初生仔猪目标对提高仔猪成活率具有重要意义[5]。自然场景下,初生仔猪有明显的聚群行为[6],粘连现象严重,个体特征不明显,难以提取;分娩栏空间狭窄,仔猪目标小,容易被限位栏和母猪身体遮挡;母猪分娩多在夜间[7],初生仔猪与母猪体色相似,易融于背景色,受光线变化影响严重[8]。因此,在全天候多干扰场景下快速且准确识别初生仔猪目标是急需解决的关键问题。
近年来,科研人员对自然环境下生猪目标识别进行了深入研究。总体分为3类:①利用颜色空间差异进行图像分割识别目标[9]。采用帧间差分法和背景差分法进行仔猪目标识别易于操作[10-11],但精度低,对噪声干扰敏感;文献[12]基于改进高斯混合建模和短时稳定度的方法只适用于缓慢运动的猪只目标检测,对静止目标检测泛化能力差;文献[13]利用猪舍固定摄像背景去除法,能够较为精确地提取前景猪只目标,但检测速度较慢。②基于传统机器学习算法识别目标。文献[14]基于周长面积比、长短轴比和Hu几何距表示体态特征,采用SVM实现猪只分类;文献[15]基于SVM-HMM模型,利用Baum-Welch算法识别猪只各类姿态;文献[16]对YCrCb 色彩空间里的 Cb分量进行灰度化处理,用形态学方法去除噪声,运用色彩空间聚类算法识别猪只位置。上述方法在图像去噪特征提取阶段较为繁杂,需要丰富的领域经验设计特征,且检测速度无法满足实时要求。③利用卷积神经网络直接由数据本身驱动特征抽象化识别目标[17]。相比传统方法,深层卷积神经网络能够简化训练流程,提高识别速度和精度[18],在医学影像分析[19]、手写字体识别[20]、人脸识别以及农作物识别等领域广泛应用[21-22]。在动物目标识别领域,文献[23]基于视频分析和卷积神经网络识别奶牛个体,视频段样本识别率达到93.33%;文献[24-25]结合Faster R-CNN深层卷积神经网络框架,识别母猪5类姿态,平均识别精度达到90.14%,检测速度接近20 f/s;文献[26]利用Faster R-CNN网络识别群养猪的摄食行为,精确率为99.6%,召回率为86.93%。但类Faster R-CNN的卷积神经网络目标识别算法需要先经过ROI proposal,再分别进行分类和定位两个任务识别目标[27],影响了检测速度。
为提高对初生仔猪目标检测速度,考虑到既能对全天候多干扰场景下的仔猪目标表现出良好的泛化能力,又能同时简化复杂的图像去噪特征提取过程,本文提出一种将整幅图像作为ROI、多通道数据集融合、将分类和定位合并为一个任务的初生仔猪目标实时检测方法。该方法支持图像数据批量处理,以及视频和录像监控实时检测,并以多样化方式存储检测结果。
1 深层卷积神经网络设计
卷积神经网络(Convolutional neural networks,CNNs)主要包括卷积层、激活层和池化层。图像输入后,多个卷积核分别提取局部特征,激活层将局部特征非线性化,池化层压缩图像并将局部特征融合,抽象化为更高层的语义信息作为下个卷积层的输入。Residual block网络结构解决了准确率饱和下降的问题[28],使得深层卷积神经网络(DCNNs)可以学习图像中更为紧致的语义信息。对大量标记好的图像进行训练,通过梯度下降算法逐渐调整各层参数权重,直至损失函数下降到局部最优值,最终的权重模型可以在验证集和测试集中表现出良好的泛化能力。
深层卷积神经网络进行目标识别的方法可分为两类,流程如图1所示:①先提取图像中的兴趣域再进行分类和定位识别目标,代表网络模型是Faster R-CNN。②以整幅图像作为兴趣域将分类和定位合并为一个任务识别目标,代表网络模型是YOLOv3。本文采用类YOLOv3的网络模型,总体网络框架包含两部分:①darknet53主干网络在ImageNet数据集进行预训练[29],迁移学习结果作为仔猪目标识别的特征提取网络。②结合3种尺度预测的特征交互层利用FPN算法将不同层级的特征融合[30],增强对小目标物体的检测效果。
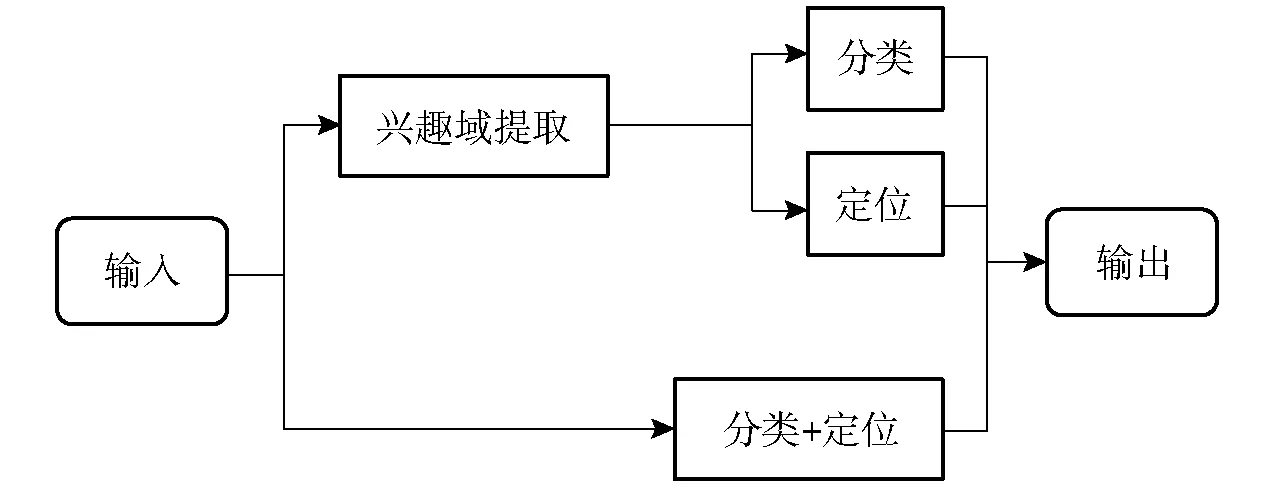
图1 两种基于深层卷积神经网络目标识别算法流程图Fig.1 Flow chart of two object detection algorithms based on deep convolution neural network
(1)输入层
经过归一化后的图像数据和标签数据,标签为PASCAL VOC格式。
(2)主干网络
以darknet53作为主干网络,如图2(上半部分)所示。卷积层结合了残差结构,可在反向传播过程中解决梯度消失问题并控制过拟合。每个残差结构块包含两个卷积层,卷积核尺寸分别为1×1和3×3。每一层卷积层后都设计有批量归一化层和非线性激活层,激活函数为LeakyReLU。省略了ROI proposal过程,以整幅图像作为特征提取的ROI,降低了假阳性的预测概率,能够加快检测速度。
LeakyReLU激活函数定义为
(1)
式中yn——激活函数输出
xn——激活函数输入
α——系数,取0.02
与ReLU相比[31],LeakyReLU能保留输入负值,更多保留目标的细节特征,这符合初生仔猪目标较小的实际情况。用卷积下采样层代替最大池化层,成倍减小特征图尺寸,节省计算资源的同时,进一步增强了特征的表达能力,却没有增加网络深度。下采样层卷积核尺寸设为3×3,滑动步长为2,边界填充为1。下采样层输出结果通过残差结构将特征进一步抽象化。
(3)特征交互层
特征交互层如图2(下半部分)所示。网络设计将识别目标分为13×13、26×26和52×52共3个尺度。采用FPN算法,将97层上采样特征与36层输出特征融合,对大尺度目标预测;将85层上采样特征和61层输出特征融合,对中型尺度目标预测;深层特征语义信息丰富,浅层特征对小目标物体的特征保留完善,深层特征与浅层特征融合,可以提高对小目标仔猪的识别精确度。
(4)输出层
输出层直接输出识别结果,即仔猪目标单类。预测框输出使用了非极大值抑制(NMS)的预测框筛选机制[32]。网络模型测试阶段,设置预测框与标注框的IOU阈值配合NMS对每个仔猪目标输出唯一预测框,IOU定义为
(2)
式中TIOU——预测框与标注框的交并比
Soverlap——预测框与标注框之间的交集
Sunion——预测框与标注框之间的并集

图2 网络模型框架图Fig.2 Network model frame diagram
2 深层卷积神经网络训练
2.1 训练样本库建立
实验数据采集于江苏省靖江市丰园生态农业园有限公司。选择两间母猪产房,面积同为7 m×9 m,每间划分成6个2.2 m×1.8 m的分娩栏,栏内均为妊娠期107 d左右的待产母猪。视频采集时间为2017年4月24日—5月31日。采用12个(每个分娩栏中都配有1个摄像头)分辨率为2 048像素×1 536像素的海康威视摄像头(DS-2CD3135F-l型,Hikvision)实时监控并备份录像,俯测高度3 m。
采用缩放、旋转(90°、180°和270°)、平移、镜像,区间内调整曝光度、饱和度、色调等数据增强技术,减轻过拟合现象。网络模型设计中定义超参数,在迭代训练的每个批次中动态随机增强数据,同一幅图像只标注1次,相对于先增强数据再统一标注的方法,能够减少标注成本。训练阶段,每10次迭代后将图像剪切,控制在320~608像素之间,每隔32像素(5次卷积下采样,图像缩放到输入的1/32)缩放1次,再次将数据量扩大10倍。
使用开源图像标注软件labelImg进行图像标注,标注图像包括3通道(白天和开启白炽灯的晚上图像)图像9 683幅,单通道图像9 683幅(夜间图像),标注格式为PASCAL VOC数据集标准格式[33],图像缩放至500像素×375像素。应对初生仔猪目标识别中的多干扰场景标注方案如下:①栏杆两侧都明显有同一仔猪身体部位,则保留范围内全部区域,若完全遮挡仔猪的头部或尾部,则保留入镜部分。②仔猪出镜,保留在视频范围内的部分。③仔猪类内粘连问题采用贝叶斯错误率为衡量指标[34],标注人眼可清楚识别的范围内仔猪部分。图3为多干扰场景的标注方案。

图3 仔猪识别数据集多干扰场景及硬性遮挡标注方案图示Fig.3 Multi-interference scene for piglet identification data set and tagging scheme for hard occlusion1.环境遮挡 2.部分出境 3.仔猪粘连
2.2 网络模型训练算法
2.2.1模型训练步骤与损失函数
模型训练步骤如下:①网络模型整体架构构建,超参数初始化。②主干网络在ImageNet数据集上的训练结果作为模型训练初始权重,开始训练进行微调。③分析训练结果,根据网络收敛特性适当调整相对应的超参数,每次重复训练使用上次训练模型作为初始化模型。④对比验证集和测试集的识别效果,定位高偏差还是高方差问题,手动统计测试集误差数据,重复步骤③、④。迭代终止条件为:①设定损失函数阈值为0.5,在预设迭代次数范围内,平均损失若不大于0.5,则停止迭代。②训练后的网络模型在验证集和测试集上的查准率和查全率浮动误差不超过3%,停止迭代。其中,损失函数定义为
Lloss=Ecoord+EIOU+Ecls
(3)
其中
(4)
(5)
(6)
式中s——整幅图像栅格划分数量
Ecoord——定位误差
EIOU——IOU误差
Ecls——分类误差
λcoord——定位误差项权重
B——每个栅格生成目标框数



xn、yn、wn、hn——标定坐标值

λnoobj——不含目标栅格的权重


A0——仔猪类别

(7)

包含目标的边界框pobject为1,否则为0。
式(6)中的栅格分类概率定义为
(8)
式中p(Dclassi|Dobject)——检测目标是仔猪的概率
相同的定位偏差对小目标影响较大,将式(4)中的w、h做开方处理,增加小目标的损失占比,提高小目标识别精度;提高定位误差项权重λcoord可增强定位精度;初生仔猪粘连现象严重,一个栅格可能包含多个目标,所以采用二元交叉熵计算分类损失;不包含目标的目标框置信度接近0,相应地放大了包含目标的目标框置信度误差对网络梯度参数的影响,可通过λnoobj权重项适当修正。
训练在一台工作站上进行,工作站配置为1块GTX1080Ti显卡,有效内存31.1 GB,2块Xeon Gold 5118CPU。训练总时长约为29 h。
2.2.2评价指标
仔猪识别的结果采用4个指标评价:精确率P(Precision)、召回率R(Recall)、精度均值A(Average precision)和精确率与召回率的调和平均数F1-S(F1-Score)。精确率是衡量模型对仔猪正样本的识别能力,是从所有识别出的样本中识别出的正样本比例(仔猪目标为正样本,其他类物体均为负样本);召回率是衡量模型对仔猪正样本的覆盖能力,是从所有正样本中识别出的正样本比例;精度均值是模型对正样本的识别准确程度和对正样本覆盖能力的权衡结果,是PR曲线与坐标轴围成的曲线下方的面积;F1-S分数是综合精确率和召回率的一个评估模型稳健度的指标。4个指标的计算公式为
(9)
(10)

(11)
(12)
式中TP——真正样本(真阳性)数量
FP——假正样本(假阳性)数量
Pos——正样本数量,包括真正样本和假负样本数量
2.2.3训练参数设计
(1)用于实验(包括3通道和单通道)的图像9 683幅,按照8∶1∶1的比例分割,其中训练集、验证集和测试集采用相同的多通道均衡分布,便于客观衡量模型的泛化能力。
(2)初次训练迭代30 000次,再训练每次迭代10 000次。
(3)采用mini-batch随机梯度下降法训练,batch值为64。
(4)学习率初始化为0.001,学习策略为步进型,momentum为0.9,学习衰减率为0.000 5。每一次迭代学习率衰减方式定义为
(13)
式中Lr_n——第n次迭代时的学习率
Lr_initial——学习率初始值
n——迭代次数Decay——学习衰减率
在训练迭代过程中,Lr_n会逐步调整学习步幅,提高模型收敛效果。
(5)损失函数中栅格数s为7,为13×13、26×26、52×52等3种预测尺度各分配3个先验框(B为9),λcoord为5,λnoobj为0.5。
3 结果分析
3.1 两类卷积神经网络目标识别模型的对比
本文采用类YOLOv3的网络框架识别仔猪目标,无兴趣域提取过程,将分类和定位合并为一个任务,相比于Faster R-CNN,对目标定位效果较差,但检测速度更快,通过加深卷积层数,能够较为理想地兼顾识别效果和检测速度。YOLOv3与Faster R-CNN网络模型在COCO公开数据集中的目标识别结果对比见表1[35],其中,AP50和AP75表示不同的IOU阈值,本研究将IOU设定为0.8;APS、APM、APL分别表示识别小型、中型和大型目标对应的AP值。由对比结果知,YOLOv3总体识别效果与Faster R-CNN相近,在小目标上(APS)的识别效果略优,更适合应对初生仔猪目标较小的问题。在检测速度方面,同在GTX 1080Ti显卡上处理COCO test-dev数据集图像,YOLOv3检测速度是Faster R-CNN的3倍。综合识别效果和检测速度,YOLOv3网络更适合应用于初生仔猪目标的实时检测。

表1 YOLOv3与Faster R-CNN在COCO test-dev数据集识别结果对比Tab.1 Comparison of recognition results between YOLOv3 and Faster R-CNN in COCO test-dev data sets
表2为采用YOLOv3与Faster R-CNN网络框架识别初生仔猪目标对比结果,图像标注类型为PASCAL VOC,GPU型号为GTX1080Ti,训练集7 747幅,测试集968幅,像素均为500像素×375像素,测试视频为MP4格式,视频分辨率为2 045像素×1 536像素,检测速度为10次输出结果的平均值(每一次输出结果包含一次瞬时检测速度)。由表2可见,YOLOv3在准确率上与Faster R-CNN(ResNet101)相差较大,其他各项指标相近,显著地提高了检测速度。

表2 YOLOv3识别与Faster R-CNN识别初生仔猪目标结果对比Tab.2 Target comparison of YOLOv3 and Faster R-CNN for recognition of newborn pig lets
3.2 不同迭代次数和通道数对模型效果的影响
3.2.1不同迭代次数的影响
网络深度对卷积神经网络模型的性能至关重要,但随着网络层数的增加,过拟合现象会加剧。在特定应用领域,数据集数量、迭代次数与卷积神经网络深度之间尚未发现普适规律。本研究中训练集有7 747幅图像,网络深度为106层(不包括输入层),根据模型训练过程中损失函数收敛过程可视化以及3种不同迭代权重模型的识别效果的对比可知,在20 000次迭代时接近模型局部最优值。分析图4,批次损失和平均损失在50~200次的迭代过程中急剧下降,整个过程在1 000收敛到0.36附近,训练效果较为理想,但在20 000次迭代附近有明显非平滑下降波动。

图4 批次损失和平均损失收敛图Fig.4 Convergence diagram of batch loss and average loss
分析图5和表3,对比3个权重模型的PR(Precision and recall)曲线。为了更清楚地显示在迭代训练过程中3种权重模型的变化情况,将召回率坐标取对数,准确率坐标取线性级数,可见在召回率较低的阶段,3个模型都有较明显的波动,尤其是WEIGHT3,急速下降后上升,说明在验证集上的收敛情况达到饱和点后迅速下降,反向传播过程中出现了梯度消失或过拟合现象。结合WEIGHT3在检测时经常将母猪的耳朵和四肢、栅栏内透进的光线、饲养人员裸露出的小腿和脖颈识别为仔猪,证明WEIGHT3权重模型出现了过拟合现象。

图5 仔猪识别PR曲线Fig.5 PR curves of newborn piglet recognition
分析表3,3个模型的检测速度基本相同,处理图像速度近似为53.19 f/s,一般MP4视频播放速度为25 f/s,可见在相应硬件配置下的检测时间能够满足实时检测要求;WEIGHT2在精确率和召回率之间达到了很好的平衡,与WEIGHT3相比,牺牲了准确率,在召回率上更有优势;在衡量模型稳定度的指标F1-S上的表现,两个模型相近;对比A,WEIGHT2明显更高。综上可知,20 000次迭代的权重模型效果最优,在接下来的检测过程中,均采用WEIGHT2的权重文件对图像数据或视频数据进行检测。
20 000次迭代权重模型在测试集中的精确率和召回率都略差于验证集,图6显示了部分识别错误的情况。模型在检测视频时,由于人的手臂和母猪的耳朵会不停的移动,保育箱口有仔猪经过时亮暗程度也会产生变化,将这些物体错误识别为仔猪。

表3 3种权重模型指标评价对比Tab.3 Evaluation comparison of three weight model indexes
其主要原因是数据量不足、初生仔猪目标小特征不明显,导致模型过拟合。

图6 过拟合现象图示Fig.6 Overfitting phenomenon diagram
3.2.2不同通道数的影响
数据集分布的均衡程度和数据集数量对深层卷积神经网络模型的泛化能力至关重要。在建立的训练样本库中,包含白天、夜间和开启白炽灯的夜间图像,夜间图像为单通道,其余为3通道。表4比较了不同通道数据集对训练结果的影响,样本数据集均为9 683幅图像,分辨率相同,在全天组中,3通道数据集5 000幅图像,单通道数据集4 683幅图像。由表4知:只有3通道的数据集和只有单通道的数据集训练的模型只在相应通道的测试数据集上表现良好,对其他场景数据集泛化能力差;当模型训练的数据集分布更加均衡时,模型的泛化能力显著提高。另一方面,全天的数据集数据分布更加均衡但白天和夜间的数据数量相对较少,所以全天数据集训练得到的模型不如单一场景下对场景内测试数据集的识别效果。

表4 不同数据集分布训练模型效果对比Tab.4 Comparison of training model effects between different data sets distribution
3.3 对图像和视频数据的检测结果
对图像数据的检测结果可以保存为图像和文本文件两种形式。图像保存形式如图7所示,这些图像在验证集中随机选择。可见,模型的识别效果较为理想,对初生仔猪目标识别过程中容易出现的粘连、硬性遮挡、光线干扰等问题能够表现出良好的泛化能力。

图7 仔猪识别模型对不同场景下的仔猪目标识别结果Fig.7 Piglet recognition model for piglet target recognition under different scenarios
文本文件的保存格式如图8所示,文本按行计数共有10条记录,表示在这幅图像中共识别出10只仔猪。第1列表示图像编号为000009;第2列表示每只仔猪通过网络模型识别的置信度,如第1条记录中识别到的目标有99.983 5%的可能性是仔猪;后4列表示仔猪目标的坐标,分别为Xmin、Ymin、Xmax、Ymax。

图8 仔猪识别模型批量识别图像的文本文件结果Fig.8 Text file result of batch recognition picture of piglet recognition model
对视频数据的检测结果可以保存为视频和文本文件两种形式。在对2 048像素×1 536像素分辨率的海康威视摄像头实时监控的视频处理时,检测速度约为10 f/s,在对清晰度720 P及以下的视频处理时,检测速度大于22 f/s,基本满足实时检测的需求。视频数据检测过程中会对每一帧进行识别,同时动态显示对应仔猪坐标、置信度和检测速度并保存到文本文件。视频检测结果如图9所示。
多样化检测结果可以用来分析仔猪的状态和行为。图10中的1号仔猪是“死胎”。文本文件分析:图10所示记录1、2、3分别表示3幅图像中1号仔猪的识别结果。分析3条记录可知,1号仔猪的坐标基本保持不变,引起坐标变化的主要原因是模型的定位误差和人工标注时的误差,配合视频检测结果,1号仔猪预测框未移动,其他仔猪争抢吃奶预测框不断变化,判断1号仔猪为死胎。

图9 仔猪识别模型视频检测输出结果Fig.9 Output of piglet recognition model video detection1.检测速度 2.目标与置信度 3.仔猪坐标

图10 仔猪死胎判断方法图示Fig.10 Determination of stillbirth in piglets
4 结论
(1)基于深层卷积神经网络,提出一种以整幅图像作为兴趣域的初生仔猪识别算法,简化了图像去噪特征提取的复杂过程,采用FPN算法将高层与底层特征融合,准确、快速地检测到初生仔猪目标。在配备单块显卡GTX1080Ti下,对清晰度720P及以下的视频能够达到实时检测的效果,对500像素×375像素的图像检测速度达到53.19 f/s。
(2)对比了不同通道数数据集以及不同迭代次数对模型性能的影响,发现在3通道与单通道数据均衡采样9 683幅的情况下,训练迭代20 000次时接近模型最优效果,在验证集和测试集上的精确率分别达到95.76%和93.84%,召回率分别为95.47%和94.88%。
(3)该方法支持图像批量处理,也可以对视频和监控录像实时检测,并将识别结果以图像、视频和文本文件的形式保存,多样化的识别结果相结合可以对仔猪的状态和行为作出准确判定。
猜你喜欢
现代电力(2022年2期)2022-05-23
今日农业(2021年5期)2021-11-27
今日农业(2021年13期)2021-11-26
今日农业(2021年21期)2021-11-26
今日农业(2021年20期)2021-11-26
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
