
基于HadooP的交通物流数据仓库构建技术研究
2019-09-10 01:16赵继新
西部交通科技 2019年10期
关键词:数据仓库
赵继新


摘要:随着社会经济的高速发展,交通物流行业对交通数据存储、管理和分析的要求越来越高。文章在对比Hadoop与MPP等技术的基础上,基于对MapReduce并行计算、HDFS分布式文件系统、数仓工具Hive和Sqoop采集组件等架构的分析,研究了Hadoop交通物流数据仓库的构建技术,建设了交通物流数据仓库,实现了海量交通物流数据文件的元数据管理、分布式存储和交通物流数据查询。经测试验证:利用交通物流数据仓库进行大型交通物流数据文件的存储和操作时,能有效提高数据吞吐率及其读写效率。
关键词:交通物流数据;数据仓库;Hadoop
中图分类号:U492.3 文献标识码:A DOI:10.13282/j.cnki.wccst.2019.10.045
文章编号:1673-4874(2019)10-0162-04
0引言
随着交通物流现代化水平的提高、业务体系的发展和信息化能力的增强,已逐步累积了海量、多源、动态、异构的交通物流信息资料,全量交通物流数据所蕴含的信息非常丰富。如何将如此海量异构的信息资源进行有效利用,是现阶段交通物流管理部’刁的迫切需要。
传统的交通物流数据库是基于关系型数据库开发的,不管是否采用分布式架构,都无法实现对交通物流海量异构数据的高效处理。而Hadoop集群技术能够为海量、异构的交通物流数据提供高效的数据存储、筛选、加工和分析挖掘,其分布式的系统基础架构,可以通过增加Hadoop数据节点提高系统处理的容量,且对部署的硬件设备性能要求不高,能够有效節约存储成本。
本文基于Hadoop分布式系统架构,设计并实现了支持海量、异构的交通物流数据仓库.Hadoop集群可以方便地扩充存储容量,分布式计算可以高效地处理数据,基于Hive可以便捷地管理元数据,完全满足了海量交通物流数据存储管理和分析应用的实际要求。
1交通物流数据仓库构建方法
针对交通物流数据存储管理和分析的实际需要,对MPP和Hadoop两种技术进行系统的分析和比较。
1.1 MPP技术
MPP(Massivel parallel processing)是面向结构化的数据进行处理和设计的数据库管理系统,是一种大规模并行处理数据库。该系统中的每个节点CPU均无法对另一节点内存进行直接访问,节点之间通过互联网络来实现信息的交互。基于共享资源架构,易于实现资源的水平扩展。该数据库具有统一的SQL接口,适用于结构化数据的复杂查询、深度分析及自主分析类应用。
MPP数据库在灵活查询、复杂关联汇总、深度分析等方面性能出众,适合交通物流数据中心场景中的数据挖掘、自助分析、数据关联等复杂逻辑加工场景,但是MPP数据库在大规模数据及半结构化、非结构化数据处理方面性能会下降,无法满足交通物流中的多源异构数据的应用场景需要。
1.2Hadoop技术
Hadoop是一个开源的分布式计算架构,由Apache基金会开发,核心部件包括两部分:分布式文件系统HDFS和分布式数据处理MapReduce。HDFS既可以支持结构化数据,也可以支持半/非结构化数据,能够存储、查询和分析所需的数据,文件按照块进行划分存储在多台机器上,并通过副本的方式保证高可用;MapReduce通过Map的方式将计算任务扩展到多台机器上,进而通过Reduce的方式将多个节点上的结果进行合并。
Hadoop基于HDFS及MapReduce之上的SQLon Hadoop组件Hive,通过定义类SQL语言,可以大幅简化SQL用户进行数据查询的过程。Hive查询操作的过程必须严格遵循Hadoop MaCReduce的作业执行模型,用户的Hive SQL语句通过解释器能够转换成MapReduce作业,并提交到Hadoop集群,Hadoop对作业执行过程进行监控,并将作业执行结果返回用户。
在Hadoop架构中,Hive只能用于结构化数据,而更底层的MaCReduce可用于结构化与非结构化数据。在调优、性能方面,Hive不如MapReduce,尤其是MapReduce可以针对性地对某些应用进行算法优化。此外,Hive还具备类SQL语言实验的机制,可以大幅提高开发人员工效,并降低工作量。
1.3 对比分析
由于MPP与Hadoop分别采用了不同的理论依据和技术路线,虽同属分布式计算,但各自的优缺点及适用范围不同。Hadoop具有对非结构化和半结构化数据的处理优势,适用于海量数据的批量化处理。而MPP适合进行大数据的高效处理,能有效替代现有的关系数据库,但其可用性在大规模集群数据下会降低。MPP适用于数据集市和多维数据分析等,Hadoop则更适用于批量数据ETL及海量数据查询存储等。
交通物流数据往往呈现多源、异构及海量等特征,除了结构化的业务数据还包含各类半结构化、非结构化的GIS数据、影像数据及视频流媒体数据等,在分析多源异构的海量交通物流数据时,需要联合结构化与半/非结构化数据一起分析。因此,通过综合比较与对比分析,本文采用Hadoop集群技术构建交通物流数据仓库。
2 交通物流数据仓库设计与实现
本文基于Hadoop分布式架构进行交通物流数据仓库的设计,目标是实现海量交通物流数据的分布式存储,以满足交通物流管理部门对交通物流数据的备份、恢复、管理、存储和共享等各项需求。
交通物流数据仓库体系结构由集群上的HDFS分布式存储、YARN资源调度、Sqoop数据采集、Ma-pReduce并行计算及Hive数据访司组件组成。基于不同的数据源,收集并汇聚到统一的数据仓库,由数据仓库来高效集中地进行存储和管理,并为交通云提供数据基础和分析、挖掘及预报预测等支持和服务。
2.1交通物流分布式文件存储设计与实现
HDFS(Hadoop Distributed File System,基于Ha-doop的文件系统)可以进行分布式计算,其容错性能好、数据吞吐率高、易于部署实施,非常适用于信息量大、且读写频繁的交通物流数据存储。
集群中主控管理层里有一个交通物流主控节点(NameNode),存储层有4个数据节点(DataNode)。主控节点主要负责文件系统命名空间(NameSpace)的维护、协调客户端文件访司、记录命名空间内的改动及命名空间的属性变化。数据节点主要负责进行其物理节点的存储管理。
数据仓库中的物流数据采用“一次写入、多次读取”的方式,通常以64MB规格切分为不同的数据块(Block),并尽量将每个数据块分散存储到不同的数据节点,同时完成多重备份,确保任意节点的故障都不会对数据的可操作性与完整性产生影响。数据仓库在执行作业的过程中,会将MapReduce的每个作业处理结果直接写入数据仓库文件系统。执行作业时,基于HDFS的容错性能,若某节点出现故障,则只需重新调度执行该节点的任务即可,无需重新提交查询。
2.2 交通物流数据MapReduce任务设计与实现
在本文建设的物流数据仓库中,元数据管理和海量数据处理采用了基于Hadoop的开源数据工具Hive。海量的物流数据直接存储在HDFS中,利用类SOL语言进行自动化处理和存儲管理。按分布式存储的方式在HDFS中对物流数据进行物理存储,利用Hive转换和解析元数据,形成一系列MapReduce任务,最后通过这些任务的执行来完成数据处理。
基于Hive提供的数据存储与处理机制,能够把物流数据的元数据和日志映射为表结构,并形成Ma-pReduce任务,从而完成数据和日志的处理。基于浏览器端的Hive接口,能大幅降低MapReduce作业难度,从而节省数据开发工作量。
通过分离简化管理元数据等,各数据节点可以直接访司并具有计算性能,从而达到数据共享和高性能分析的要求。元数据是数据质量、内容、条件等数据的数据,是数据质量水平和来源的描述,也是数据适用范围及可信度的判别依据。Hive完成了Hadoop与关系数据库的结合,由MapReduce完成数据转换与装载等,由关系型数据库来管理元数据并进行密集型任务的查询。
3 交通物流数据仓库数据性能分析
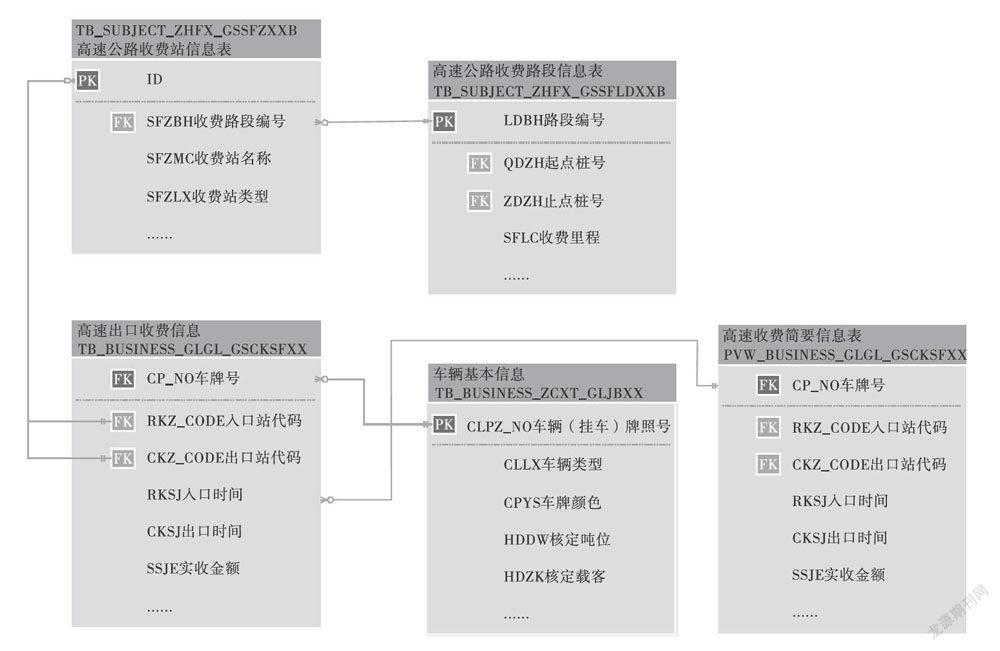
本文基于已设计构建的数据仓库,利用已汇聚的5.8亿条实际交通物流信息数据,进行数据仓库的性能分析。数据包含每一辆通过高速公路收费站的车辆相关收费信息,包括车牌号、入站口及入站时间、出站口及出站时间、实收金额等信息,其关系示意如图1所示。基于同一数据集,分别在Hadoop平台以及SQL Server上完成数据采集、数据查询、数据转换以及数据导出的测试,比较其性能。
基于Hadoop架构的交通物流数据仓库中的Sqoop数据采集组件,能够解决Hadoop和关系型数据库之间的数据传递,基于Sqoop组件能快速实现关系型数据库和HDFS之间的数据导入与导出。Sqoop数据采集组件是采用MapReduce任务的形式分布式并行进行的。在Hadoop平台上使用Sqoop组件对数据进行采集,测试结果如表1所示。
实验中,基于Hadoop和Hive进行数据组合训练后,复制到MapReduce上,再把测试数据集的文件映射为数据库表,并提供完成的类SQL查询功能,可以将Hive转换为MapReduce任务执行。对测试数据集进行Hive查询操作,结果如表2所示。
在数据转换测试中,使用类SQL的Hive脚本进行Group By操作,统计每天的收费金额,其结果如表3所示。
本实验主要目的在于测试基于Hadoop架构的交通物流数据仓库在不同数据量下系统的采集、转换和导出功能的性能。
在相同的实验环境下SQL Server在执行5.8亿条数据转换脚本时,经过3h的运算,最终由于内存溢出而导致脚本执行失败。在Hadoop集群中计算相同数据,仅耗时29min13S便完成转换任务。由此可见大数据平台在此数据量下的计算能力优于传统数据库。
在实验过程中,基于Hadoop的交通物流数据仓库资源占用率不到80%。本次实验环境使用的交换机设备为H3C S1208和H3C$5130-28S-SI,实验数据持续2h不间断地向HDFS文件系统中写入数据,在写入的过程中,测试数据集流量达到网络链路承载上限,即占满整个千兆以太网链路,平均速率为154.59Mbps,在满负荷的情况下,仍能以最快速度完成此任务,性能表现良好。
4 结语
本文对构建交通物流数据仓库的必要性和重要性进行了系统阐述,分析对比了Hadoop与MPP两种技术构建交通物流数据仓库的优劣性,通过利用Ha-doop集群技术在海量异构数据处理性能上的优势,设计架构完成了交通物流信息的数据仓库,并利用实际物流数据对其性能进行分析评测。实践证明,该数据仓库能够对海量交通物流数据进行分布式存储、分布式处理、元数据管理和备份,具有优越的容错性和安全性,任何一个或几个节点出现故障,都不会对整个系统集数据造成较大影响,其综合性能具有明显优势。此外,集群节点均为普通计算机,其成本低廉,且易于架构实现。
猜你喜欢
电子乐园·下旬刊(2021年3期)2021-02-08
计算机与网络(2019年20期)2019-09-10
国外科技新书评介(2016年8期)2016-11-16
卷宗(2014年12期)2014-04-02
法制与社会(2009年26期)2010-06-29
档案管理(2009年3期)2009-05-22
