
编码器中自注意力机制的替代方案
2019-09-10 07:22周祥生林震亚郭斌
现代信息科技 2019年19期
关键词:编码器
周祥生 林震亚 郭斌



摘 要:本文针对Transformer中编码器进行改进,尝试了包括RNN(recurrent neural network)、CNN(convolu-tional neural network)、动态路由等多种结构,对比其特征提取能力及对解码器的影响。实验表明,在编码器中引入RNN、IndRNN结构可以在一定程度上增加编码器对源语言的特征提取能力,而采用CNN替代编码器中的自注意力机制(self-attention)可以在不明显影响结果的情况下显著降低参数量,提升模型性能。由于考虑参数量和执行时间,动态路由在该任务下效果不好,这也说明了动态路由结构虽然是很强的特征提取器,但并不适合进行堆叠。
关键词:自注意力机制;CNN;RNN;动态路由;编码器
中图分类号:TN914;TP18 文献标识码:A 文章编号:2096-4706(2019)19-0064-05
Abstract:In this paper,we try to improve the encoder in Transformer,including RNN(recurrent neural network),CNN(convolutional neural network),dynamic routing and other architectures,and compare their feature extraction capabilities and the impact on decoder. Experiments show that the introduction of RNN and IndRNN architecture in the encoder can increase the feature extraction ability of the source language to a certain extent,while the use of CNN instead of self-attention in the encoder can significantly reduce the number of parameters and improve the performance of the model without obvious impact on the results. Considering the parameters and execution time,dynamic routing does not work well in this task. This also shows that dynamic routing architecture is a strong feature extractor,but it is not suitable for stacking.
Keywords:self-attention;CNN;RNN;dynamic routing;encoder
0 引 言
神经机器翻译(NMT)的目的是利用神经网络解决机器翻译(MT)问题,近年来已显示出不错的成果。在机器翻译中,序列到序列结构已经被证明在很大程度上优于传统的基于短语的模型[1]。一个主要的挑战是如何将可变长度的文本序列编码成一个固定大小的张量,且这个张量能够完全捕获文本的语义。文本编码方法通常包含三个关键步骤:(1)将文本序列中的每个单词转换为嵌入(Embedding)特征;(2)将单词嵌入序列作为输入,并使用神经网络进行特征抽取与转换;(3)通过聚合(Aggregation)将句子含义总结为固定大小的张量,然后通过监督或无监督的方式组合下游任务。如今,针对模型结构,已经有大量研究,例如RNN[2,3]、CNN[4,5]和Self-attention Network[6-8]。一些研究人员发现,不同的层能够捕获不同类型的语法和语义信息[9-11],例如本地和全局的源语言句法都是由NMT编码器学习的,且在不同的层捕获的语法信息不同。
近年来,许多研究者将重点放在了聚合步骤上,有几项工作在重复或卷积编码层之上采用了自我关注机制[12,13],以取代简单的池化和全连接。最近的一些研究表明,同时公开所有层表示优于仅利用顶层进行自然语言处理任务的方法[10,14-16]。然而,它们的方法主要集中在静态聚合上,因为聚合机制在序列的不同位置上是相同的。随后,Dou等人[17]受迭代路由文献[18]、[19]的思想启发,将其思想应用于层聚合,从而提取多层表征所共享的最活跃特征。
然而,之前的结构过于独立,并没有设计成可重复堆叠的模型单元。本文基于前人思想,將CNN、RNN、动态路由等结构分别巧妙应用于Transformer结构[6]的Encoder单元中,在保证其并行能力、运行效率的同时在机器翻译领域的公开数据集UNv1.0中英测试集上取得了超越传统Transformer的效果,并为模型蒸馏[20]学生模型的设计提供了新思路。此外,本文还针对传统训练语料的不足,提供了新的训练语料,该语料是从各处搜集的五千多万语料中整理出的六百万条高质量语料,实测采用该语料训练充分的模型可媲美全量语料充分训练后的结果。
1 编码器中自注意力机制替代方案的背景知识
1.1 NMT结构
通过两个独立的网络将源序列映射到目标序列,编码器网络计算源序列的表示,解码器网络根据编码器输出自动回归生成目标序列。下文中,表示第i步第l层的隐状态,Exi表示xi的嵌入,epos,i表示位置i的位置表征。
1.2 基于RNN的NMT
RNN是一种状态网络,当新的输入被输入时,它会发生变化,并且每个状态都只与以前的状态有直接的连接。因此,RNN中距离为n的任意两个单元的路径长度正好是n。图1是RNN的示意图。
在深度结构中,两个相邻层通常通过残差操作进行连接。在第l层编码层中,由式(1)生成,其中frnn是RNN(包括GRU、LSTM等)函数。在第一层中,。此外,编码器和解码器之间可通过注意力机制连接,解码器初始状态通常由编码器最后一个隐状态或者其均值得到。
1.3 基于CNN的NMT
CNN是层次化网络结构,卷积层用于捕获局部相关性。本地上下文大小取决于内核的大小和层数。为了使输出与输入保持相同的长度,CNN模型在输入序列中添加了Padding符号。对于内核大小为k的l层CNN,最大的上下文关联长度是l(k-1)。
传统CNN结构如图2所示,Multi-head attention[6]中的切头操作说明执行全连接后词向量是可分的,因此文本处理中也可在全连接后采用传统CNN结构。
在該结构下,内核大小为3的2层CNN可以“看到”5个词的有效本地上下文。卷积核宽度越大,可关联的上下文信息越多;卷积核长度越大,单次操作可捕捉的词向量信息就更全。由于CNN无法推断元素在序列中的位置,因此需要引入位置嵌入。
式(2)中所示的隐藏状态与同一卷积中的隐藏状态以及上一层中的隐藏状态有关,k表示CNN的核大小,fcnn是非线性的函数,W l称为卷积滤波器。在输入层中, 。
1.4 基于Transformer的NMT
Transformer严重依赖于Self-attention。每个标记都通过Self-attention直接连接到同一句话中的任何其他标记。此外,Transformer还采用了多头注意力机制。与传统的单头注意机制相比,多头注意机制更加精细。图3说明了任意两个单元是直接连接的:第一个(x1)和第五个(x5)单元之间的路径长度是1。与CNN类似,位置信息也需要保存在位置嵌入中,或者记录词与词之间的相对位置关系[21]。
Transformer编码器中的隐藏状态是根据前一层的所有隐藏状态计算出来的。自注意网络中隐藏状态的计算如式(3)所示。
其中f表示一个前馈网络,在输入层中,,与编码器不同,解码器在Self-attention基础上还有融合编码器与解码器内容的多头注意力机制计算。
1.5 动态路由
动态路由将胶囊分组形成父胶囊,并计算胶囊的输出。对于一个胶囊来说,输入ui和输出vj都是向量。首先,将变换矩阵Wij与前一层胶囊的输出ui相乘,将ui转换为uj|i,然后根据权重cij计算加权和sj,如图4所示。
cij为耦合系数,通过迭代的动态路由过程计算得到。从概念上讲,cij衡量胶囊i有多大可能激活胶囊j。对于激活函数,这里采用Squashing而不是ReLU,所以胶囊的最终输出向量vj的长度在0到1之间,该函数将小向量压缩为零,大向量压缩为单位向量。
动态路由并不能完全替代反向传播。转换矩阵W仍然使用成本函数通过反向传播训练。我们只是使用动态路由来计算胶囊的输出。通过计算cij来量化胶囊与其父胶囊之间的连接。这个值很重要,但生命周期很短暂。对于每一个数据点,在进行动态路由计算之前,我们都将它重新初始化为0。在计算胶囊输出时,无论是训练或测试,都需要重新做动态路由计算。
2 编码器中自注意力机制的替代方案模型的改进
2.1 结构改进
在Transformer结构中,Decoder部分设计精妙,通过合理的Mask操作,从而让一轮反向传播计算学习了目标语句每个位置上的信息。本文涉及的所有模型不改变Decoder部分流程,目的是观察如何设计Encoder结构可以让Decoder部分更好地使用源语句信息。
从根本上来说,Self-attention结构的目的是采用所有原始向量的加权和对新的向量进行表征,其中权重通过注意力计算得到,而RNN结构更关注每个位置与上一个位置的依赖关系。基于此,我们优先想到的是如何将RNN思想用于改进Self-attention结构,具体见式(9):
其中l表示层数,Wl与Ul都是参数矩阵,bl是参数向量, 是 经过Self-attention计算后的结果。受IndRNN[22]启发迭代式子可变更为式(10),从前一个单元至后一单元的传递过程中,由哈达玛积运算替代传统矩阵乘法。
除了引入RNN结构,本文还尝试采用卷积网络更好地捕捉文本局部特征。
文中采用的CNN结构如图5所示,可以看到与传统CNN的唯一区别在于不采用两边等长的卷积核。对于文本来说,长度更大的卷积核可以捕捉更长距离的上下文信息,宽度更大的卷积核可以更充分的捕捉词语信息。本文分别在计算和不计算Self-attention的情况下加入卷积结构,并详细对比了不同参数下的结果。
除了引入RNN和CNN结构,本文还在Self-attention的基础上加入动态路由。由于本文程序中采用动态词长,所以动态路由没有设计成用一句话中所有词的加权和来表征每一个词,即ui为某句话的第i个词,vj为动态路由计算后这句话的第j个词;而是把每个词通过不同的参数矩阵变换为新词,再由这些新词的组合来表征原始词,即ui为某个词的第i个表征,vj为动态路由计算后这个词的第j个表征。然后再将v通过拼头的操作合并(同Self-attention中的多头还原操作),并通过全连接计算进行维度还原。
2.2 流程改进
为了更好地翻译特殊字符,本文采用特殊字符保留操作。具体操作如下:
(1)找到源语言与目标语言中相同的词,并且采用&SEPX的形式进行标记。
如源语句:中国在2001年加入WTO的时候承诺加入GPA。
目標语句:China has the commitment to join the GPA when she accessed to the WTO in 2001.
则将源语句标记为:中国在&SEP1年加入&SEP2的时候承诺加入&SEP3。
目标语句标记为:China has the commitment to join the &SEP3 when she accessed to the &SEP2 in &SEP1.
(2)将处理后的语句加入原始数据集,即若源语句与目标语句中出现相同的词,则新增处理后的该句,原始句保留。
(3)将新语料用于训练,得到最终模型。
可以预见这类标记大多为实体和数字,经此训练后的模型可在一定程度上掌握特殊实体对齐能力。使用时,可以选择性的将需要保留的数字或者关键词用特殊符号代替,再在翻译结果中将词填入对应的位置中。对于一些训练集中的低频词或者经Subword后左右熵较大的词,也可以选择性的将其标记,再通过查字典的方式得到更为准确的结果。
3 编码器中自注意力机制的替代方案模型的结果分析
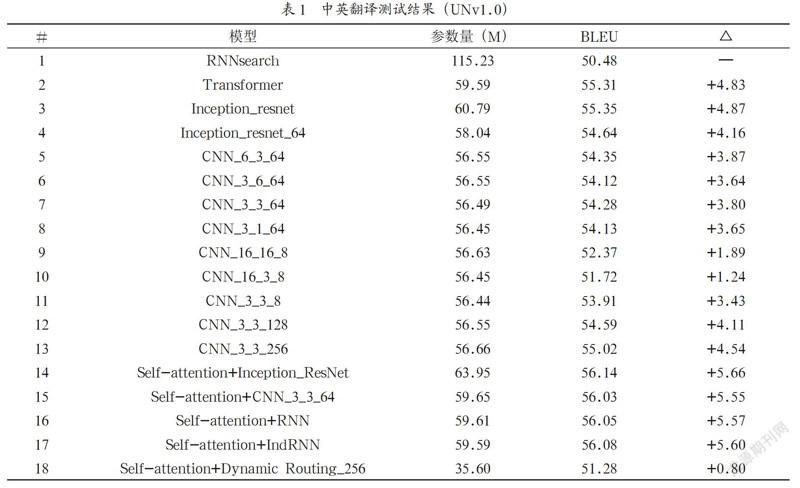
本文采用的数据集根据公司内部语料整理得到,共有六百万条,句长期望22.25词,在保证源语句与目标语句长度接近的情况下,尽可能的遍历各种句长,从而保证训练后的模型对长短句均有不错的翻译效果。实验证明基于该语料充分训练后的模型,翻译效果与五千万条语料训练得到的模型差距不大(Transformer-base模型下BLEU值约差1.5)。验证集和测试集均采用UNv1.0。本文模型采用动态Batch和动态句长,使用4块M40卡训练,激活函数均采用GELU[23],学习率及Adam优化器超参数均按照Transformer[6]中的方法设置。为了加快实验速度及突出Encoder部分特征的重要性,Decoder层数均设为4层(在实际解码过程中,Encoder只需要计算一次得到隐藏状态,而Decoder需要计算多次,直到出现截止符号,故而在实际使用中,Decoder部分的复杂度直接影响翻译系统的性能)。RNNsearch[24]采用文献中的参数,其它模型隐藏层、全连接层维度均与Transformer-base一致。各个实验结果对比如表1所示。
表1为各项实验结果,共训练100万个Batch,结果均取验证集上表现最好的模型。可见在该测试集上,采用Transformer解码器的模型明显优于传统的RNNsearch结构。Inception-resnet[25]结构是测试模型中效果最好的CNN特征提取器,但参数量也最大,为了减少参数,在进入Inception-resnet前进行降维至64维,出模型后恢复至512维,即使在这种情况下,依旧取得了不错的结果。对于CNN结构,第一个参数表示卷积核长度,第二个参数表示卷积核宽度,第三个参数表示Filter数量,可见增加卷积核长度起到的效果略好于增加卷积宽度,用太大的卷积核并不能像预想中那样提取更多上下文及词表征信息,反而会降低模型效果,如果不知道怎么设计卷积核大小,3*3的卷积核依旧是不错的选择。增大Filter数量可以在一定程度上提升特征提取质量,同时能增加模型训练时的稳定性,使其在训练中后期(30万步后)波动减小。此外,CNN结构比Self-attention结构具备更慢的训练收敛速度,这也可能是没针对其进行超参数调优导致,如要解决这个问题,可在Self-attention的计算结果上加入CNN结构,该操作也会在一定程度上提升模型效果。
在Self-attention结构上加入RNN和IndRNN结构均可在一定程度上提升模型效果,但也会略微增加参数量和收敛时间,说明Self-attention虽然在原理上可以学习到任意位置间的交互关系,但没有特别捕捉与前一层的交互作用,额外引入每一层和前一层之间的关联性也是有必要的。动态路由采用8维胶囊,输出的胶囊也为8维,循环次数为6次,最后通过“拼接头部+全连接”的方式还原维度。虽然参数量不多,但是按照上述方法加入到每次Self-attention计算后执行过程很复杂,有大量中间结果,故而隐层设为512维时显存不够,这里将隐层设为256维。在该情况下,参数量大幅减少,但是无论是效果还是解码时间都不尽如人意,在之后的论文中,会重点探讨文献[18]、[19]中路由结构在翻译模型中的合理使用方法。
4 结 论
本文针对Transformer中编码器进行改进,尝试了包括RNN、IndRNN、CNN、动态路由等多种结构,对比其特征提取能力及对解码器的影响。实验表明,在编码器中引入RNN、IndRNN结构可以在一定程度上增加编码器对源语言的特征提取能力,而采用CNN替代编码器中的Self-attention可以在不明显影响结果的情况下显著降低参数量,提升模型性能,为模型蒸馏任务中学生模型的设计提供了新思路。由于考虑参数量和执行时间,动态路由在该任务下效果不好,这也说明了动态路由结构虽然是很强的特征提取器,但并不适合进行堆叠。此外,本文通过特殊字符替换方式解决了特殊字符或是非常用词翻译问题,还针对传统训练语料的不足提供了新的训练语料,为商用翻译系统设计提供了帮助。
参考文献:
[1] Sennrich R,Haddow B,Birch A .Edinburgh Neural Machine Translation Systems for WMT 16 [C]//Proceedings of the First Conference on Machine Translation,2016:371-376.
[2] Jie Z,Ying C,Xuguang W,et al. Deep Recurrent Models with Fast-Forward Connections for Neural Machine Translation [J].Transactions of the Association for Computational Linguistics,2016,4:371-383.
[3] Wu Y,Schuster M,Chen Z,et al. Google’s neural machine translation system:Bridging the gap between human and machine translation [J].arXiv preprint arXiv:1609.08144,2016.
[4] Gehring J,Auli M,Grangier D,et al. Convolutional sequence to sequence learning [C]//Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org,2017:1243-1252.
[5] Bradbury J,Merity S,Xiong C,et al. Quasi-recurrent neural networks [C]//Published as a conference paper at ICLR 2017.
[6] Vaswani A,Shazeer N,Parmar N,et al. Attention is all you need [C]//Advances in neural information processing systems(NIPS 2017).
[7] Chen M X,Firat O,Bapna A,et al. The best of both worlds:Combining recent advances in neural machine translation [J].arXiv:1804.09849v2,2018.
[8] Dehghani M,Gouws S,Vinyals O,et al. Universal transformers [J].arXiv preprint arXiv:1807.03819,2018.
[9] Shi X,Padhi I,Knight K. Does string-based neural MT learn source syntax? [C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing,2016:1526-1534.
[10] Peters M E,Neumann M,Iyyer M,et al. Deep contextualized word representations [J].arXiv preprint arXiv:1802.05365,2018.
[11] Anastasopoulos A,Chiang D. Tied multitask learning for neural speech translation [J].arXiv:1703.03130,2017.
[12] Lin Z,Feng M,Santos C N,et al. A structured self-attentive sentence embedding [J].arXiv preprint arXiv:1703.03130,2017.
[13] Yang Z,Yang D,Dyer C,et al. Hierarchical attention networks for document classification [C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2016:1480-1489.
[14] Shen Y,Tan X,He D,et al. Dense information flow for neural machine translation [C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2018(3):1294-1303.
[15] Gong J,Qiu X,Wang S,et al. Information aggregation via dynamic routing for sequence encoding [J].arXiv preprint arXiv:1806.01501,2018.
[16] Dou Z Y,Tu Z,Wang X,et al. Exploiting deep representations for neural machine translation [J].arXiv preprint arXiv:1810.10181,2018.
[17] Dou Z Y,Tu Z,Wang X,et al. Dynamic Layer Aggregation for Neural Machine Translation with Routing-by-Agreement [J].arXiv preprint arXiv:1902.05770,2019.
[18] Sabour S,Frosst N,Hinton G E. Dynamic routing between capsules [C]// 31st Conference on Neural Information Processing Systems (NIPS 2017),2017:3856-3866.
[19] Sabour S,Frosst N,Hinton G. Matrix capsules with EM routing [C]//Published as a conference paper at ICLR 2018.
[20] Hinton G,Vinyals O,Dean J. Distilling the knowledge in a neural network [J].arXiv preprint arXiv:1503.02531,2015.
[21] Shaw P,Uszkoreit J,Vaswani A,. Self-attention with relative position representations [J].arXiv preprint arXiv:1803.02155,2018.
[22] Li S,Li W,Cook C,et al. Independently recurrent neural network (indrnn):Building a longer and deeper rnn [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018:5457-5466.
[23] Hendrycks D,Gimpel K. Bridging nonlinearities and stochastic regularizers with gaussian error linear units [J].arxiv:1606.08415,2016.
[24] Bahdanau D,Cho K,Bengio Y. Neural machine translation by jointly learning to align and translate [J].arXiv preprint arXiv:1409.0473,2014.
[25] Szegedy C,Ioffe S,Vanhoucke V,et al. Inception-v4,inception-resnet and the impact of residual connections on learning [J].arxiv:1602.07261,2016.
作者簡介:周祥生(1980-),男,汉族,江苏涟水人,资深研发经理,硕士,研究方向:自然语言处理。
猜你喜欢
科技视界(2018年27期)2018-01-16
科学与财富(2018年34期)2018-01-15
科技与创新(2017年5期)2017-03-28
现代电子技术(2009年14期)2009-09-05
电子设计应用(2004年6期)2004-07-27
