
高校网站日志分析系统的研究与应用
2019-09-09 07:39尹鑫种兰祥杨建锋
中国教育信息化·高教职教 2019年7期
尹鑫 种兰祥 杨建锋
摘 要:针对高校网站管理者对网站访问情况及时、直观了解的需求,本文提出了一种以SparkStreaming为核心的分布式网站访问日志分析系统。本系统使用Flume实时收集网站被访问时产生的日志,使用Kafka对收集到的日志进行缓存,使用Spark中的Streaming流处理框架按批次提取缓存的数据,并通过其中的Translation和Action算子对流量、站点、地区、终端信息进行分析,使用MySQL数据库对分析结果进行存储。使用Echarts设计界面并结合Ajax等前端技术对分析结果进行实时可视化处理。在分布式平台下实现了一个实时可扩展的日志数据分析系统。有效地支持了高校网站的管理工作。
关键词:高校网站日志;分布式集群;SparkStreaming;可视化
中图分类号:TP311 文献标志码:A 文章编号:1673-8454(2019)13-0064-04
一、引言
在“互联网+教育”的时代背景下,作为高校信息化建设基础的网站已经成为高校对内信息公开、对外开展交流、宣传自身特色、彰显办学优势的最重要途径和最便捷手段,其服务对象主要是校内和校外学生、校友、普通公众、政府、企事业单位和社会团体。网站建设者和网站管理者最为关心的是网站的效果如何、访问者是否找到所需信息,此时,网站访问日志几乎就成为获取这些信息的唯一来源。传统收集用户访问信息的方法是通过JavaScript脚本埋点的方式进行收集。在用户发送页面请求时JavaScript添加用于追踪的cookie,服务器端据此收集用户的访问信息并写入数据库中。每当用户发送一次请求都会进行一次数据库写入,所以此方法拖延了网站的响应速度,增大了服务器的开销。直接对Web服务器自动记录的网站访问日志数据处理可以很好地解决这一问题。日志文件中记录了访问者浏览每个网站的基本信息、访问状态和访问行为。但是,这些内容是以非结构化的文本形式存储的,数据结构较不规则。所以采用适合处理大规模的非结构化数据的大数据处理技术对网站访问日志进行处理。[1-3]
随着互联网的快速发展,出现了许多大数据相关技术。网站访问日志具有量大、实时和真实等大数据特征,适合采用Flume、Kafka、Spark等大数据技术和方法对其进行处理分析,辅助其它技术手段将分析结果可视化加工处理,以直观、友好的形式予以展示,有助于网站建设者和网站管理者及时准确地了解网站的受访情况,包括用户的分布状况和用户的访问倾向等,以便做出适当调整,对于新时代下推动学校信息化发展具有重要的现实意义。[4-6]
二、关键技术简介
大数据处理是一种对大规模数据进行分析处理的技术,包括数据采集、数据缓存、数据分析、分析结果存储、数据可视化几部分,通常基于分布式架构进行计算,以应对具有较强的实时性、连续性和自然性的数据。
1.Flume
Flume,即日志收集系統。Flume是由Cloudera公司提供的用于收集海量日志数据的开源的分布式采集系统,具有高可用、高可靠特性,同时提供对数据做简单处理,可十分灵活地对日志数据进行传输,并写到各种数据接受方。现为Apache基金会Hadoop生态系统的项目之一。Flume被用于将分布在不同服务器上的站点产生的网站日志数据实时统一收集到集群当中。
2.Kafka
Kafka,即消息发布订阅处理系统。Kafka最初是由LinkedIn公司为了处理高吞吐量的消息发布和订阅而专门开发的一套分布式消息缓存队列系统,现已成为Apache软件基金会顶级的分布式开源项目之一。Kafka能够承受每秒10万级以上的并发量,还可以横向扩展以增加吞吐量。由于它以多副本方式进行数据的缓存,故有较为完善的数据恢复机制。目前已成为处理网页浏览、搜索以及其他动态数据流的首选系统。
3.Zookeeper
Zookeeper,即开源的分布式应用程序协调服务。Zookeeper是Hadoop生态系统中的一个重要组件,能提供配置服务、名字服务、分布式同步、组服务等,具有简单、丰富、高可靠、松耦合和资源库等特点,主要用于当Kafka进行数据缓存时进行Broker和Topic的注册,同时对程序进行监听以存储当前的消费进度信息。
4.Spark
Spark,即大规模数据处理通用并行计算引擎。是使用Scala开发的类MapReduce的数据处理框架,具有计算速度快、容错性强、易于扩展的特性。相比Hadoop,它能将相同条件下的计算结果提高10~100倍。并且将计算结果存入内存当中,减少了将计算结果存于磁盘的读写开销。Streaming是Spark框架中的分布式流式批处理大数据组件。它支持交互式计算和复杂算法,可用于分析和计算大规模流式数据。适合对实时性强的大量网站访问日志数据进行分析。[4][7]
5.可视化技术
Echarts是百度开源的图表框架。Ajax是一种Web前端技术,可以在不完全加载网页的情况下实现局部界面的动态刷新。首先通过Echarts设计需要进行展示的效果图,再通过Ajax技术实时提取分析结果并对图表中的数据进行局部更新。
三、系统设计
1.系统总体架构
高校网站访问日志数据分析系统的总体架构包括数据采集、数据传输、数据分析、分析结果存储、结果可视化几部分。系统总体架构如图1所示。其中Flume是数据收集系统,Kafka是数据缓存系统,Spark Streaming 是数据分析系统,DataBase代表存储分析结果的关系型数据库,本系统采用的是MySQL。最后搭建网站将分析结果进行可视化展示。

2.数据采集
本系统使用Flume对Web服务器产生的网站访问日志数据进行实时采集。搭建的数据采集架构如图2所示。由于学校网站数量较多、数据量较大,所以本系统搭建两层Flume来应对網站分布在不同Web服务器上的情况。继而将不同Web服务器上产生的日志数据汇集到一起。使用其中的Agent机制对指定Web服务器目录下的日志文件进行实时监控采集。Agent主要由source、channel、sink三个组件组成。source从数据发生器接收数据,并将接收的数据以event的格式传递给channel;channel是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着桥梁的作用;sink将数据传输到存储器或者缓存器中。
本系统中的第一层Flume作为日志获取节点,把Agent搭建在产生日志数据的Web服务器上,以每个网站所在Web服务器的日志文件生成端作为第一层Flume中Agent的source端,配置连接channel,将第一层Flume的sink端类型设置为avro,即输出到下一层Flume的指定端口。第二层Flume作为日志汇集节点,将所有第一层Flume的sink端对接第二层Flume的source端。再将第二层Flume的sink端指定到Kafka集群的Topic,即将采集到的日志数据传输到Kafka。完成对实时产生的日志的收集。

3.数据缓存
为了防止集群服务器意外宕机造成的数据丢失以及访问并发量特别高时日志数据量大对服务器计算产生冲击的情况,本系统采用Kafka对Flume采集到的日志数据进行短暂缓存。数据缓存集群的整体架构如图3所示。主要包含消息的生产者(Producer)、存储消息事件内容的集群服务器节点(Broker),以及消息的消费者(Consumer)三大部分。Peoducer生产消息到Topic中,Consumer提取消息进行消费。

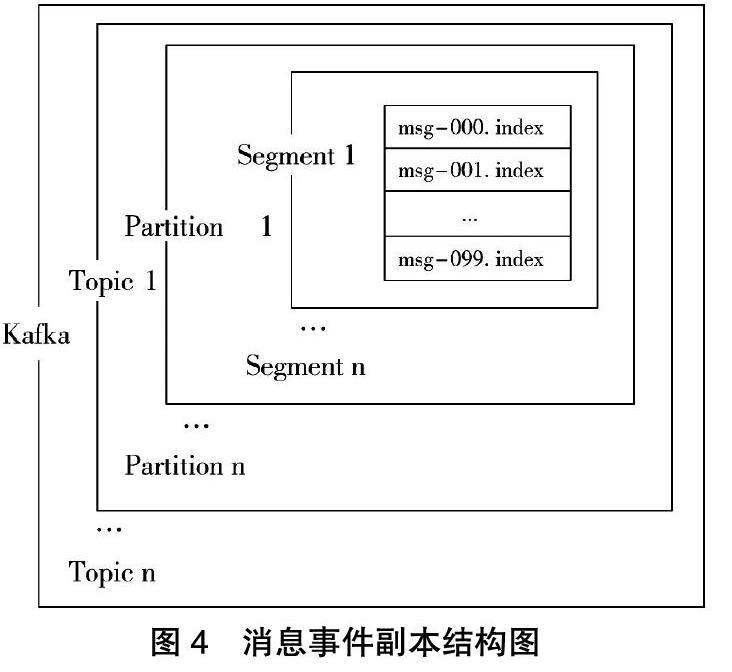
本系统将Flume中传输过来的日志数据创建为消息事件Topic,为不同类型的Web服务器产生的日志数据创建不同的Topic。将日志收集系统中第二层Flume的sink端作为生产者,生产者将产生的消息发送到指定的Topic中。每个Topic的具体内容存储在图3所示的Broker中。为了保证系统的容错性,将每个Topic设置多副本(Partition)存储,Partition又分散存储在不同的Broker中,每个Partition又划分为多个Segment,其中存储了Topic中的所有相关信息,当集群发生错误时可据此进行恢复,具体存储结构如图4所示。
Topic的消费者对应分析数据的Spark的Streaming端,提取Topic中的数据进行消费。在此过程中采用Zookeeper对相应的服务器节点信息和不同的消息事件进行注册,并且在整个缓存过程中使用Zookeeper监听程序并存储当前的消费进度信息。
4.数据分析
(1)数据预处理
每条原始的日志文件数据具体包含客户端IP地址、客户请求发生的时间、请求的方式、请求的网页地址、请求所遵循的协议、请求返回的http状态码、页面的字节大小、客户的端代理几部分信息。设计正则表达式对每行日志数据进行切分并过滤,以某条Nginx产生的日志数据为例,各部分对应正则表达式如表1所示。

(2)流量分析
过滤出对应的IP地址,以IP地址为key,调用ReduceByKey算子对IP地址进行聚合操作生成新的RDD,遍历最终的RDD将结果保存到数据库中。[8]
(3)站点分析
切分出对应请求的网站部分。使用filter算子过滤掉访问不成功的站点数据,对相应部分进行进一步切分,过滤掉HTTP的请求头以及具体的请求信息,提取出对应的站点域名并以域名为键值,使用ReduceByKey算子进行聚合操作生成新的结果RDD,并存储。
(4)地区分析
提取出切分后对应IP地址的部分,采用QQwry通过二分法进行IP地址定位,以识别出的所在地为key,使用ReduceByKey算子对所在地进行聚合操作生成新的RDD,遍历RDD将结果存入数据库中。
(5)终端分析
提取出对应的客户端代理信息,采用uasParser函数解析出所用的操作系统类型和版本信息、浏览器类型以及版本信息。
5.数据存储
由于所存储的数据为经过计算的分析结果,所以表结构相对简单,表结构如图5所示。

以日期为单位,当具体信息存在时则累加,不存在则新增。
四、系统的实现
高校网站日志分析系统的实现关键在于,运用大数据相关技术搭建集群,完成数据的采集、缓存和分析,将分析结果以可视化的形式进行展示。
1.开发语言与运行环境
本系统采用分布式架构,以Linux作为操作系统搭建集群,共创建5个节点。采用Flume1.7.0搭建日志采集系统,采用Kafka0.10.0.0搭建日志缓存系统,以Zookeeper3.8.2对日志缓存系统进行分布式协调,以Spark2.2.0作为日志分析系统,以Scala作为日志分析语言设计分析方法,以MySQL5.7.13作为数据库存储分析结果。采用SpringBoot2.0框架搭建网站进行可视化展示,采用MyBatis对接数据库,网站以Tomcat作为Web服务器,采用CSS、JavaScript等前端语言进行开发。
2.实现可视化
调用Echarts的地图框架分别绘制全国各省市地图。构建坐标轴,匹配当前所在地对应的经纬度坐标并在图上进行标记。在标记点处添加其对应的访问量。当有新增的访问地时,添加当前访问地区到所访地区的访问发起曲线。并在旁边绘制柱状图表示访问量Top10的地区。使用Echarts的柱状图对今天到当前为止Top10的站点及其访问量进行统计,并结合饼状图和排序函数显示访问量占比。使用Echarts的坐标图框架以时间为单位对总的PV和UV数量进行可视化展示,并显示某一时段内访问量的最大值、最小值、平均值。采用Ajax技术对数据进行实时刷新。
3.分析结果
高校网站日志分析系统以秒为单位对高校实时产生的网站日志数据同时进行了流量分析、站点分析、访问终端分析、访客归属地分析,并将每批次数据的分析结果累计存储到当天已产生的分析信息中。将当天的分析信息进行实时动态展示,系统最终的动态可视化效果如图6所示。信息部门的网站管理者通过本系统的展示页面,可以实时获取到当天到当前时刻为止本校网站的总访问量以及访客的数量、当前最热门的前10个受访站点以及每个站点的访问量、当日发生访问行为的地区以及各个地区的访问量,还有用户发起访问时所用终端的类型以及各种类型的占比。

五、结语
本系统采用Spark、Flume、Kafka大数据技术结合Echarts等可视化技术开发了高校网站日志实时分析系統。实现了对高校网站访问日志这一特殊的文本数据进行分析展示。相比传统的通过JS前端埋点的分析方式,本系统极大地减少了浏览器与服务器之间的交互,从而提高了分析的效率,使管理者能够及时直观地了解学校网站的受访情况。同时采用分布式架构降低了硬件设备的成本。
参考文献:
[1]胡水星.教育数据挖掘及其教学应用实证分析[J].现代远距离教育,2017(4):29-37.
[2]陈凤.大数据下的高校学生管理可视化平台研究[J].软件工程,2017(6):48-51.
[3]裴莹,付世秋,吴锋.我国教育大数据研究热点及存在问题的可视化分析[J].中国远程教育,2017(12):46.
[4]李慧芳,白珊,马强,贾鑫.基于Spark的智慧校园数据挖掘研究[J].智能计算机与应用,2016(6):106.
[5]陈桂香.大数据对我国高校教育管理的影响及对策研究[D].武汉大学,2017.
[6]张胜,赵珏,陈荣元.网络安全日志可视化分析研究进展[J].计算机科学与探索,2018(5):681-696.
[7]韩德志,陈旭光,雷雨馨,戴永涛,张肖.基于Spark Streaming的实时数据分析系统及其应用[J].计算机应用,2017(5):1263-1269.
[8]Ilias Mavridis,Helen Karatza.Performance evaluation of cloud-based log file analysis with Apache Hadoop and Apache Spark[J].The Journal of Systems & Software,2017(125):133-151.
(编辑:王天鹏)
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
小学生(看图说画)(2017年6期)2017-11-06
活力(2016年9期)2016-08-01
活力(2016年9期)2016-08-01
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
电子设计工程(2014年19期)2014-02-27
