
基于层次注意力机制神经网络模型的虚假评论识别
2019-09-04 10:14颜梦香姬东鸿任亚峰
计算机应用 2019年7期
颜梦香 姬东鸿 任亚峰


摘 要:针对虚假评论识别任务中传统离散模型难以捕捉到整个评论文本的全局语义信息的问题,提出了一种基于层次注意力机制的神经网络模型。首先,采用不同的神经网络模型对评论文本的篇章结构进行建模,探讨哪种神经网络模型能够获得最好的篇章表示;然后,基于用户视图和产品视图的两种注意力机制对评论文本进行建模,用户视图关注评论文本中用户的偏好,而产品视图关注评论文本中产品的特征;最后,将两个视图学习的评论表示拼接以作为预测虚假评论的最终表示。以准确率作为评估指标,在Yelp数据集上进行了实验。实验结果表明,所提出的层次注意力机制的神经网络模型表现最好,其准确率超出了传统离散模型和现有的神经网络基准模型1至4个百分点。
关键词:注意力机制;虚假评论;离散特性;神经网络;长短期记忆网络
Abstract: Concerning the problem that traditional discrete models fail to capture global semantic information of whole comment text in deceptive review detection, a hierarchical neural network model with attention mechanism was proposed. Firstly, different neural network models were adopted to model the structure of text, and which model was able to obtain the best semantic representation was discussed. Then, the review was modeled by two attention mechanisms respectively based on user view and product view. The user view focused on the users preferences in comment text and the product view focused on the product feature in comment text. Finally, two representations learned from user and product views were combined as final semantic representation for deceptive review detection. The experiments were carried out on Yelp dataset with accuracy as the evaluation indicator. The experimental results show that the proposed hierarchical neural network model with attention mechanism performs the best with the accuracy higher than traditional discrete methods and existing neural benchmark models by 1 to 4 percentage points.
Key words: attention mechanism; deceptive review; discrete feature; neural network; Long Short-Term Memory (LSTM) network
0 引言
随着电子商务的兴起,越来越多的个人和商业组织开始阅读和参考在线评论来作出购买决策,例如,在哪里住宿,去哪里就医,购买哪些产品,去哪个餐厅,等等。积极的评论可以为企业和个人带来显著的经济收益和名声,这为虚假评论的产生提供了强大的动力。在过去几年中,虚假评论的问题已经变得极为普遍,新闻中也报道了众多引人注目的案例。许多企业已经开始通过现金、优惠券和促销活动等手段刺激虚假评论的产生,用以增加销售,获取经济效益。虚假评论检测是一个紧迫而且重要的话题,它对于确保网络平台上信息的可信度至关重要,如果不识别它们,线上商城就可能成为谎言、假货和欺骗的地方,因此,设计有效的模型来自动检测虚假评论是非常必要的。
虚假评论识别通常被建模为一个文本分类问题[1]。基于标记的真实和虚假样例,利用监督学习来构建分类器,然后将未标记评论预测为虚假评论或真实评论。现有大多数方法遵循Jindal等[2]的开创性工作,采用全监督学习来构建分类器。这些研究主要侧重于设计有效特征以提高分类性能,如语言学和心理语言学相关的典型特征,但未能从全局篇章结构的角度有效地表示文档。例如,Ott等[1]使用了二一元词组(Unigram)、词性(Part Of Speech, POS)和LIWC(Linguistic Inquiry and Word Count)特征。尽管这些特征给出了良好的性能,但是它们的稀疏性使得难以在篇章层面捕获全局的语义信息。
最近,神经网络模型已被广泛用于自然语言处理(Natural Language Processing, NLP)众多任务的语义表示,并取得优异的性能。神经网络应用在虚假评论检测方面有两点潜在的优势。首先,神经网络模型使用隐藏层进行自动特征组合,可以捕获到传统离散特征难以表达的复杂全局语义信息,这可以解决离散模型的限制;其次,神经网络模型采用分布式词向量作为输入,词向量可以从大规模原始文本中训练得到,从而在一定程度上缓解标注数据的稀缺性。基于这个方向,一些创新性的工作已经被提出,例如,Ren等[3]提出使用神經网络模型来学习评论文本的表示,用以识别虚假评论。具体的,他们采用卷积神经网络(Convolutional Neural Network, CNN)模型从单词向句子层面建模,使用长短期记忆(Long Short-Term Memory, LSTM)网络模型从句子向文档层面建模,实验结果证明了所提模型的有效性。
本文发现,一个评论文本通常包括两部分信息:一部分信息表达用户的偏好,另一部分信息表达产品的特性。基于此,本文探索了一种基于层次注意力机制的神经网络模型,从用户和产品两个角度来对评论文本进行建模,并对两部分信息进行整合,将其用于虚假评论识别任务。基于Yelp数据集的实验证实了所提算法的有效性。同时,对样例的可视化分析也验证了本文所提方法的有效性和可解释性。
1 相关工作
Jindal等[2]最先引入虚假评论识别问题,他们抽取评论内容、评论者和产品本身的特征来训练模型识别虚假评论;Yoo等[4]收集了40条真实和42条虚假的酒店评论,并手动比较了它们之间的语言差异;Ott等[1]通过亚马逊众包平台,雇用Turkers撰写虚假评论构建了一个基准数据集。该数据也被一系列后续研究工作所采用[5-6]。例如,Feng等[5]研究了上下文无关语法解析树的语法特征,以提高识别性能。Feng等[6]从评论集合中建立了酒店简介,衡量了客户评论与酒店简介的兼容性,并将其用作虚假评论检测的一个特征。Mukherjee等[7]认为基于众包平台构建的虚假评论跟现实中虚假评论的真实分布存在一定差异,基于分布更真实的Yelp评论,他们使用Boolean、词频(Term Frequency, TF)、词频逆文本频率指数(Term Frequency-Inverse Document Frequency,TF-IDF)等特征来对虚假评论进行了分类和分析,由于该数据集中虚假评论的分布更为真实,后续的一些工作都是基于该数据集进行研究和分析。
上述工作主要集中于评论文本进行特征建模,也有工作研究了评论内容本身之外的特征。除了Jindal等[2],Mukherjee等[8]研究了客户行为的特征来识别欺骗。Qian等[9]确定了同一作者生成的多个用户ID,因为这些作者更有可能产生欺骗性评论。任亚峰等[10]和Rout等[11]提出了一种半监督学习方法,并建立了一个准确的分类器来识别欺骗性评论。此外,Ren等[12]提出了一种新方法,从纠正错误标记样例的角度发现虚假评论。Kim等[13]引入了基于FrameNet框架的语义特征,实验结果表明语义框架特征可以提高分类精度。Wang等[14]建议学习评论的表示,而不是以数据驱动的方式识别欺骗性的垃圾评论。任亚峰等[15]基于遗传算法对评论的语言结构及情感极性特征进行优化选择,并使用两种简单的聚类方法进行虚假评论识别。Zhang等[16]提出了一种称为递归卷积神经网络识别欺骗性评论(Deceptive Review Identification by Recurrent Convolutional Neural Network, DRI-RCNN)的方法,通过使用单词上下文和深度学习来识别欺骗性评论。最近,Noekhah等[17]提出了一种新颖的多重迭代网络结构,该结构考虑了亚马逊上实体之间最有效的特征以及内部和内部关系。不同于这些工作,本文关注对评论文本内容进行建模,但上述模型的功能可在本文提出的模型中進行扩展。
现有方法大多使用传统的离散特征,这些特征是稀疏的并且不能有效地编码来自整个文档的语义信息。最近,神经网络模型已被用于各种NLP任务中[18]。分布式词表示已被大多数NLP模型用作基本构建块[19]。同时,众多方法已被提出用于学习短语和较大文本片段的表示。例如,Yessenalina等[20]使用迭代矩阵乘法从词表示中学出短语表示。Le等[21]引入段落向量来学习文档表示。Socher等[22]引入了一系列递归神经网络来表示句子级语义组合。后来,这项工作从不同方面进行了扩展,其中包含全局反馈机制、深度递归层、特征权重调整、自适应组合函数和组合分类语法。CNN已被广泛用于语义合成[23],自动捕获语法信息。序列模型,如循环神经网络(Recurrent Neural Network, RNN)或LSTM也被用于语义合成[24]。同时,受人类视觉注意的启发,Bahdanau等[25]在机器翻译中提出了注意力机制,将其引入编码器—解码器框架,以选择目标语言中单词的源语言参考词。它也用于图像标题生成、解析、自然语言问答。此外,Yang等[26]和Chen等[27]探索层次注意力机制,为文档的语义选择信息性词语或句子。
不同于上述工作,基于Yelp数据集,本文提出一种基于层次注意力机制的神经网络模型,从用户和产品两个角度来对评论文本进行建模,并将其用于虚假评论识别任务。
2 基于层次注意力机制的神经网络模型
一个评论文本通常包含两种信息:一部分信息表达用户的偏好,另一部分信息表达产品的特性。如何对这两种信息进行建模,对学习评论文本的篇章表示至关重要。本文探索了一种基于层次注意力机制的神经网络模型,从用户和产品两个角度分别对评论文本进行建模,学习评论文本的篇章表示,用于识别虚假评论。
2.1 总体框架
本文所提的模型称为HNNUPA(Hierarchical Neural Network with User and Product Attention)。如图1所示,所提框架主要由四部分组成:长短期记忆网络、用户注意力网络、产品注意力网络和篇章表示。首先,实验地探讨了不同神经网络结构(CNN、RNN和LSTM)对评论文本的篇章结构建模,即哪种神经网络模型能获得最好的篇章表示;然后,基于用户视图和产品视图的两种注意力机制,用户视图关注评论文本中用户的偏好,而产品视图关注评论文本中产品的重要特性;最后,将两个视图学习的评论表示拼接,整合两种视图的信息,作为预测虚假评论的最终表示进行预测。
2.2 长短期记忆网络
LSTM因其在序列建模方面的出色表现而被广泛用于文本建模。为了解决长距离依赖的问题,LSTM架构引入了能够长时间保持单元状态的存储器单元。具体地,每个LSTM单元有三个门来保护和控制单元状态,分别是“遗忘门”“输入门”和“输出门”。在每个时间周期t,给定输入向量xt,则当前单元状态ct和隐藏状态ht可由之前的单元状态ct-1和隐藏状态ht-1更新如下:
这里it, ft和ot是门激活,σ是sigmoid函数,⊙代表元素乘法。直观地,忘记门ft控制前一存储器单元的遗忘程度,输入门it控制每个单元的更新程度,输出门ot控制内部存储器状态的输出。隐藏状态ht表示LSTM单元的内部存储器单元的输出信息。
2.3 用户注意力机制
从用户的角度来看,并非所有单词都能反映用户的偏好或情绪,为此本文设计用户注意力机制来选取对句子含义有重要意义的用户特定词。形式上,句子表示sui 是用户视图中的词级隐藏状态的加权和:
其中:huij是第i个句子中第j个单词的隐藏状态;αuij是huij的注意力权重,用于衡量第j个单词对当前用户的重要性。将每个用户u映射到连续的实值向量u∈Rdu,其中du表示用户嵌入的维度。具体地,每个隐藏状态的注意权重αuij定义为:
2.4 产品注意力机制
对于不同的产品,每个单词或句子对文本语义贡献度也不同。基于常识可知,产品注意力机制可将产品信息整合到类似于用户注意力机制类似的评论表示中。在产品视图中,评论的句子表示spi和文档表示dp可计算如下:
这里αpij和βpi分别是单词级隐藏状态hpij和句子级hpi的权重,其计算方式跟用户注意力机制中的权重计算一样,不需要人工调节和干预。
2.5 文档表示
du和dp分別表示用户视图和产品视图学习的表示,为了获得较为全局的篇章表示,首先整合这两个视图的表示,将其拼接在一起作为一个最终的评论表示:
拼接后,可以直接使用线性层和softmax层将评论表示d投影到C类的评论类别分布中:
在提出的模型中,评论类别的基本事实分布与p之间的交叉熵误差被定义为:
其中:pgc表示分类标签c的概率,T代表训练集。
之前,对两个视图的表示直接进行了拼接作为最终表示,但是,这种表示不一定能给出最优的全局篇章表示,因为两个表示的构造方式基本相同,因此,为了获得更优的篇章表示,在损失1中以一定权重整合评论表示du和dp,具体地,分别在du和dp中添加softmax分类器,其相应的损失定义如下:
其中:pu是用户视图的预测结果分布,pp是产品视图的预测结果分布,因此,模型的最终损失可以表示为损失1,损失2和损失3的加权和:
损失2和损失3作为监督信息引入,以帮助进一步从用户视图和产品视图来探索虚假评论识别,因此,最终根据分布p预测评论分类标签,因为它包含用户信息和产品信息。
3 实验设置
3.1 数据集
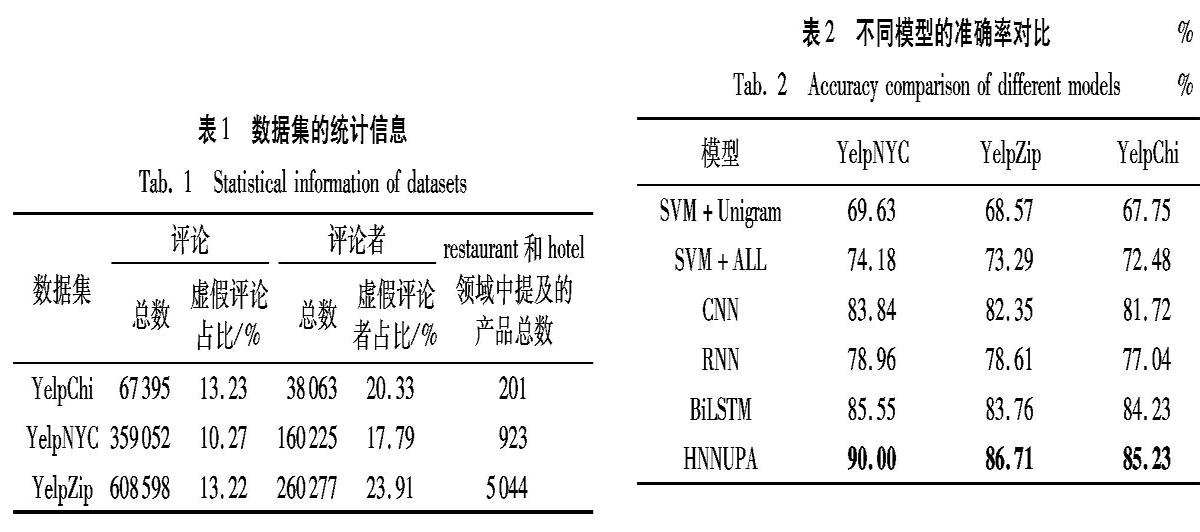
本文使用来自美国最大点评网站Yelp.com收集到的三个数据集,表1是三个数据集的统计信息。这三个数据集都是非平衡数据集。第一个数据集是YelpChi,它包含对芝加哥地区餐馆和酒店的评论,该数据集最早来自于文献[28]。另外两个数据集分别是YelpNYC和YelpZip。YelpNYC包含位于纽约市的餐馆的评论;YelpZip数据量更大,提供了美国部分区域的餐馆的评论,这些地区包括NJ、VT、CT和PA。这两个数据集最早来自于文献[29]。
表1中,第一列表示数据集;第二列中的all表示评论总数, fake%表示虚假评论占比;第三列中的all表示评论者总数,spammer%表示虚假评论者占比;第四列表示restaurant和hotel领域中提及的产品总数。
在实验过程中,每个数据集以80/10/10的比例被划分为训练/测试/开发集。开发集用于优化神经网络结构的超参数。实验中,采取Accuracy、F1值和均方根误差(Root Mean Square Error, RMSE)来评价算法的性能。
3.2 超参数
在实验中,使用Skip-Gram模型学到200维的词向量。用户词向量的维度和产品词向量的维度都设置为200,使用均匀分布U(-0.01,0.01)对其随机初始化。LSTM单元格中隐藏状态的维度设置为100,因此,双向LSTM输出单词/句子表示为200维。这里,限制每个评论文本最多有40个句子,每个句子不超过50个单词。使用Adam更新参数,初始学习率设置为0.005。最后,根据开发集上的性能选择最佳参数,用于测试集中。
3.3 基准模型
支持向量机(Support Vector Machine, SVM): 支持向量机在众多文本分类任务中获得了优异的性能,也被用于虚假评论识别工作中。这里,不仅整合SVM和传统的词袋特征,也使用了Bigram、POS、LIWC等各种语言学和心理语言学的特征。
4 实验结果
4.1 结果比较
基于Yelp的数据集,表2给出了不同模型的实验结果。以YelpNYC数据集为例,传统的离散模型SVM,结合unigram特征,仅仅给出了69.63%准确率,当融合POS、LIWC等更多更复杂的语言学和心理语言学特征后,识别准确率被提升到74.18%,这展示了丰富的特征建模对虚假评论识别的重要性。对于神经网络的基准模型,CNN完成了83.84%的准确率,远远地超出了离散的SVM模型,显示了神经网络模型的有效性。RNN给出了78.96%的准确率,BiLSTM给出了85.55%的准确率,远远地超过了RNN模型,主要原因是因为RNN受长距离依赖问题的困扰,而BiLSTM通过门机制的设置,可以避免长距离依赖导致的梯度弥散问题,从而完成了较好的性能。基于BiLSTM模型,从用户视图和产品视图两个角度分别整合了注意力机制,即本文提出的HNNUPA模型,完成了90%的准确率,超出了离散的SVM模型和神经网络的基准模型CNN和BiLSTM。基于数据集YelpZip和YelpChi上,模型间的性能比较可以观察到同样的趋势,上述分析证实了本文所提算法的有效性。
4.2 模型分析
4.2.1 用户注意力和产品注意力的影响
为了证明同时使用用户注意力和产品注意力的有效性,这里,独立地实现了两个注意力机制并进行探讨。具体地,首先实现了独立的用户注意力网络(Hierarchical Neural Network with User Attention, HNNUA),然后实现了独立的产品注意力网络(Hierarchical Neural Network with Product Attention, HNNPA)。表3给出了不同模型的具体结果。基于表3可知,与未使用注意力机制的普通神经网络模型BiLSTM相比,HNNUA和HNNPA对模型的性能有一定的提升,这验证了通过注意力机制将用户和产品纳入虚假评论识别的合理性。结果还表明,无论从用户视图还是产品视图来对评论文本进行建模都是有效的。
同时,本文发现,比起产品角度,从用户视图的角度对文本进行建模更有效。原因可能归结于评论中的一些单词或句子虽然一定程度上描述了产品的特征,但对产品的态度描述最终由用户主观决定。比起单独的用户视图或者产品角度建模,对两者进行整合获得了更好的性能,主要原因是因为一个评论文本通常由两种信息构成,一部分信息表达用户的偏好,另一部分信息表达产品的特性,对这两种信息同时建模才是获得全局表示的关键。本文的实验结果也证实了这一点。
另外,在表3中,本文也統计了模型的F1值和RMSE,这里F1值是两个类别的宏平均。本文发现比起模型的Accuracy,F值相对较低,进一步分析了每个类别的Precision和Recall,发现真实评论这个类别的Precision和Recall都很高,而虚假评论类别的Precision较高,Recall只有0.4左右,这说明模型在虚假评论这个类别上性能要差于真实评论类别,其主要原因是数据集不均衡导致的,基于表1中的数据集统计信息可知。在未来的工作中,也将探索更好的模型来解决这个问题。
4.2.2 不同加权损失的影响
λ1、λ2和λ3分别代表损失1、损失2和损失3的权重。通过调整它们的比例来验证不同加权损失对最终结果的影响。当λ2设置为0时,表示不使用损失2来增强评论表示。类似地,将λ3设置为0,表示不单独使用损失3。实验结果如表4。
从表4可知,无损失2和损失3此处“无损失2和损失3”的表述对吗?请明确的模型在三个数据集上给出了一致的趋势,即缺乏每一部分损失都会影响最终的性能,从表4可知,三个数据集上的实验结果给出了一致的趋势,即缺乏损失2或者损失3都会影响模型最终的性能,而本文提出的HNNUPA模型,从用户和产品两个角度建模,同时考虑两方面的损失。获得了性能上的一些提升。很明显,完整的HNNUPA模型可以获得最佳性能。结果表明,通过设计的组合策略,可以从篇章角度实现更好的评论表示,用于虚假评论识别中。
4.2.3 样例可视化
为了验证本文所提的注意力机制的有效性,以YelpNYC数据集为例进行分析。基于提出的HNNUPA模型,这里分析单词级别的注意力权重。两个样例如图2所示,图中上半部分表示评论1,下半部分表示评论2。注意,颜色越深意味着权重越大。
评论1是虚假评论,“love”一词在用户视图上具有最高权重,“love”表达出了作者对食物的喜爱,说明作者试图鼓吹、夸大该产品;“casual”和“surrounding”等词在产品视图上具有较高的权重,其中“surrounding”一词描述了餐馆空间特征,表示评论作者本身也许并未有真实的消费经历,缺乏真实的体验,所以选择使用抽象的表示空间方位的词。
评论2是虚假评论,“disappointed”一词在用户视图上具有最高权重,“disappointed”表达出了作者的负面情感,说明作者试图通过这种消极情绪来诋毁该产品,“bland”一词在产品视图上具有较高的权重,“bland”意为乏味的,是贬低食物的一种通用词汇,作者可能根本就没有吃过这家店的意大利面,试图通过“bland”来诋毁该产品。
现实中的情况正是如此。为了鼓吹产品的质量,虚假评论者会使用积极正面的情感词;同理,在贬低产品时,必然会使用消极负面的情感词。另外,由于对产品或服务缺乏真实的消费体验或经历,虚假评论者往往会使用抽象的词来描述空间信息或者地理位置,因为过于具体的词汇可能会由于跟事实不符而暴露其欺骗意图。
5 结语
本文提出了一种基于层次注意力机制的神经网络模型,从用户和产品两个角度分别来学习评论文本的表示,将两个表示进行整合作为评论文本的最终表示,用于虚假评论识别。基于Yelp数据集的实验结果表明,本文所提模型超过了传统的离散模型和神经网络基准模型。未来的工作中,将探索更有效的模型,提升非平衡数据下的虚假评论识别效果。
参考文献 (References)
[1] OTT M, CHOI Y, CARDIE C, et al. Finding deceptive opinion spam by any stretch of the imagination [C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2011: 309-319.
[2] JINDAL N, LIU B. Opinion spam and analysis [C]// Proceedings of the 2008 International Conference on Web Search and Data Mining. New York: ACM, 2008: 219-230.
[3] REN Y F, ZHANG Y. Deceptive opinion spam detection using neural network [C]// COLING 2016: Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers. Osaka, Japan: COLING, 2016: 140-150.
[4] YOO K H, GRETZEL U. Comparison of deceptive and truthful travel reviews [C]// Proceedings of the 2009 International Conference on Information and Communication Technologies. Berlin: Springer, 2009: 37-47.
[5] FENG S, BANERJEE R, CHOI Y. Syntactic stylometry for deception detection [C]// Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2. Stroudsburg, PA: Association for Computational Linguistics, 2012: 171-175.
[6] FENG V W, HIRST G. Detecting deceptive opinions with profile compatibility [C]// Proceedings of the 6th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2013: 338-346.
[7] MUKHERJEE A, VENKATARAMAN V, LIU B, et al. Fake review detection: classification and analysis of real and pseudo reviews [R]. Chicago: University of Illinois, Department of Computer Science, 2013: 3.
[8] MUKHERJEE A, KUMAR A, LIU B, et al. Spotting opinion spammers using behavioral footprints [C]// Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2013: 632-640.
[9] QIAN T Y, LIU B. Identifying multiple userids of the same author [C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2013: 1124-1135.
[10] 任亞峰,姬东鸿,尹兰.基于半监督学习算法的虚假评论识别研究[J].计算机科学与探索,2014,46(3):62-69.(REN Y F, JI D H, YIN L. Deceptive reviews detection based on semi-supervised learning algorithm [J]. Advanced Engineering Sciences, 2014, 46(3): 62-69.)
[11] ROUT J K, SINGH S, JENA S K, et al. Deceptive review detection using labeled and unlabeled data [J]. Multimedia Tools and Applications, 2017, 76(3): 1-25.
[12] REN Y F, JI D H, YIN L, et al. Finding deceptive opinion spam by correcting the mislabeled instances [J]. Chinese Journal of Electronics, 2015, 24(1): 52-57.
[13] KIM S, CHANG H, LEE S, et al. Deep semantic frame-based deceptive opinion spam analysis [C]// Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2015: 1131-1140.
[14] WANG X P, LIU K, HE S Z, et al. Learning to represent review with tensor decomposition for spam detection [C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2016: 866-875.
[15] 任亞峰,尹兰,姬东鸿.基于语言结构和情感极性的虚假评论识别[J].计算机科学与探索,2014,8(3):313-320.(REN Y F, YIN L, JI D H. Deceptive reviews detection based on language structure and sentiment polarity [J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(3): 313-320.)
[16] ZHANG W, DU Y H, YOSHIDA T, et al. DRI-RCNN: an approach to deceptive review identification using recurrent convolutional neural network [J]. Information Processing and Management, 2018, 54(4): 576-592.
[17] NOEKHAH S, SALIM N B, ZAKARIA N H. A novel model for opinion spam detection based on multi-iteration network structure [J]. Advanced Science Letters, 2018, 24(2): 1437-1442.
[18] REN Y F, ZHANG Y, ZHANG M S, et al. Context-sensitive twitter sentiment classification using neural network [C]// Proceedings of the 13th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2016: 215-221.
[19] REN Y F, ZHANG Y, ZHANG M S, et al. Improving twitter sentiment classification using topic-enriched multi-prototype word embeddings [C]// Proceedings of the 13th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI, 2016: 3038-3044.
[20] YESSENALI A A, CARDIE C. Compositional matrix-space models for sentiment analysis [C]// Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2011: 172-182.
[21] LE Q, MIKOLOV T. Distributed representations of sentences and documents [J]. Journal of Machine Learning Research, 2014, 32(2): 1188-1196.
[22] SOCHER R, PERELYGIN A, WU J, et al. Recursive deep models for semantic compositionality over a sentiment treebank [C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2013: 1631-1642.
[23] JOHNSON R, ZHANG T. Effective use of word order for text categorization with convolutional neural networks [C]// Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2015: 103-112.
[24] LI J W, LUONG M T, JURAFSKY D, et al. When are tree structures necessary for deep learning of representations [EB/OL]. [2017-08-04]. http://www.emnlp2015.org/proceedings/EMNLP/pdf/EMNLP278.pdf.
[25] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. [2017-10-20]. https://arxiv.org/abs/1409.0473.
[26] YANG Z C, YANG D Y, DYER C, et al. Hierarchical attention networks for document classification [C]// Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1480-1489.
[27] CHEN H M, SUN M S, TU C C, et al. Neural sentiment classification with user and product attention [C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1650-1659.
[28] MUKHERJEE A, VENKATARAMAN V, LIU B, et al. What yelp fake review filter might be doing [C]// Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media. Menlo Park, CA: AAAI, 2013: 409-418.
[29] RAYANA S, AKOGLU L. Collective opinion spam detection: bridging review networks and metadata [C]// Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2015: 985-994.
猜你喜欢
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2021年2期)2021-11-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
