
面向高光谱影像分类的显著性特征提取方法
2019-09-04 01:55:28余岸竹邢志鹏杨其淼
测绘学报 2019年8期
余岸竹,刘 冰,邢志鹏,杨 帆,杨其淼
1.信息工程大学,河南 郑州 450001;2.32023部队,辽宁 大连 116000
近年来,随着遥感平台和传感器的不断进步,人们获取高光谱遥感影像的能力不断提高。但在完成数据获取以后,数据的处理与分析将真正决定地物探测的水平。高光谱影像分类能够为高光谱影像的进一步应用提供基础,是高光谱遥感中的关键技术和研究热点之一[1]。高光谱影像中可以获取每个像素近似连续的光谱曲线,这些光谱曲线能够较好地反映地物的属性信息,这就为地物的精细分类提供了可能。但近似连续的光谱曲线导致了高光谱影像具有高维的数据特点,且在高光谱影像中获取标记数据较为困难,可用于训练的标记样本数量较少。高维的数据结构和较少的训练样本数量给高光谱影像分类带来了极大的挑战[2]。
早期的高光谱影像分类方法通过提取光谱特征,并结合支持向量机、决策树、逻辑回归等分类器进行分类[3]。但在高光谱影像中“同谱异物”和“同物异谱”的现象广泛存在,这就导致仅仅利用光谱信息进行分类具有一定的局限性。高光谱影像具有“图谱合一”的特点,在提供光谱特征的同时,也提供了丰富的空间信息。而大量的研究表明,在分类过程中引入空间信息能够降低地物分类的不确定性,从而能够提高高光谱影像分类的精度[4]。拓展形态学属性剖面[5](extended morphological profile,EMP)通过形态学操作提取高光谱影像的空间结构信息,并与光谱特征结合进行分类,有效地改善了高光谱影像的分类效果。除了EMP,还可以应用滤波半径依次增加的引导滤波器来获得影像不同尺度的结构信息,进而提高分类精度[6]。纹理特征也是一种能够有效利用空间信息的方法,常用于高光谱影像分类的纹理特征有Gabor特征[7]、局部二值模式[8]纹理特征等。除了上述在特征提取过程中考虑空间邻域信息,也可以利用聚类获得的空间信息来提高高光谱影像的分类精度。文献[9]利用聚类信息对支持向量机的分类结果进行后处理,进一步提高了高光谱影像的分类精度。文献[10]在利用支持向量机对Gabor特征进行分类的基础上,采用多数投票策略进一步融合超像素分割结果,在训练样本数量较少的情况下取得了较为理想的分类精度。文献[11]提出利用边缘保持滤波对分类结果进行处理,既能滤除分类结果中孤立的分类噪声,又能较好地保持分类结果的边缘,因此能够提高分类精度。
近年来,随着计算能力和数据获取能力的不断提高,深度学习方法得到了快速发展,已经被广泛应用于自然语言处理、图像分类识别、高分辨率遥感影像处理、高光谱影像分类等领域。最早用于高光谱影像分类的深度学习模型是堆栈式自编码器,该方法先利用主成分分析对高光谱影像进行降维处理,然后选取一定的邻域范围,并展成一维特征向量输入到堆栈式自编码器中进行分类[12]。随后,利用光谱特征的一维卷积神经网络模型也被引入到了高光谱分类领域中[13]。为了进一步提高高光谱影像的分类精度,二维卷积神经网络被用于提取高光谱影像的空间特征,并将空间特征与光谱特征结合进行分类,取得了较为理想的分类结果[14-16]。此外,研究人员还利用三维卷积神经网络[17]和循环神经网络[18]提取高光谱影像的空-谱特征进行分类。基于深度学习的高光谱影像分类方法能够自动从数据中学习如何提取特征,简化了高光谱影像分类的处理流程,但仍然面临小样本问题的挑战。
视觉显著性是人类视觉系统的重要机制,其能够快速准确地提取场景中最感兴趣的区域,并忽略冗余的信息[19]。视觉显著性估计已经被广泛应用于遥感图像处理和分析中,例如文献[20]联合显著性和多层卷积神经网络进行高分辨率遥感影像场景分类;文献[21]对高光谱影像进行显著性波段选择,从而提高高光谱影像的分类精度。为充分利用空间信息提高高光谱影像分类精度,本文以显著性滤波器为基础,提出了一种用于高光谱影像分类的显著性特征提取方法,并进一步结合光谱特征进行分类。最后利用Pavia大学、Indian Pines和Salinas 3组高光谱数据集验证了本文算法的有效性。
1 高光谱影像显著性特征提取与分类
视觉显著性估计中通常以彩色图像为输入[22],因此,本文以3个相邻波段的高光谱影像为输入,进行显著性特征提取,然后沿光谱维度利用滑窗法获取各个波段的显著性特征,最后将各个波段的显著性特征进行堆叠形成最终用于分类的显著性特征。如图1所示,3个相邻波段的高光谱影像显著性特征提取主要包括超像素分割、对比度计算和显著性分配3个步骤。
1.1 SLIC超像素分割
基于像素的视觉显著性估计方法对噪声较为敏感,而超像素以相对简单的方式表示图像并能减少图像的冗余,同时每个超像素块具有相同的性质[23]。为了更加有效地提取显著性特征,首先将输入的三波段高光谱影像根据颜色相似性分割为若干个超像素,每个超像素由区域内的颜色均值表示,进而以超像素为基础进行视觉显著性估计。本文采用SLIC[24](simple linear iterative cluster)方法对输入的三波段高光谱影像进行超像素分割。

(1)
式中,l、a、b为CIE LAB颜色空间对应的3个通道变量;i和j为超像素的索引;Nc和Ns分别为最大的颜色距离和种子点之间最大的距离。
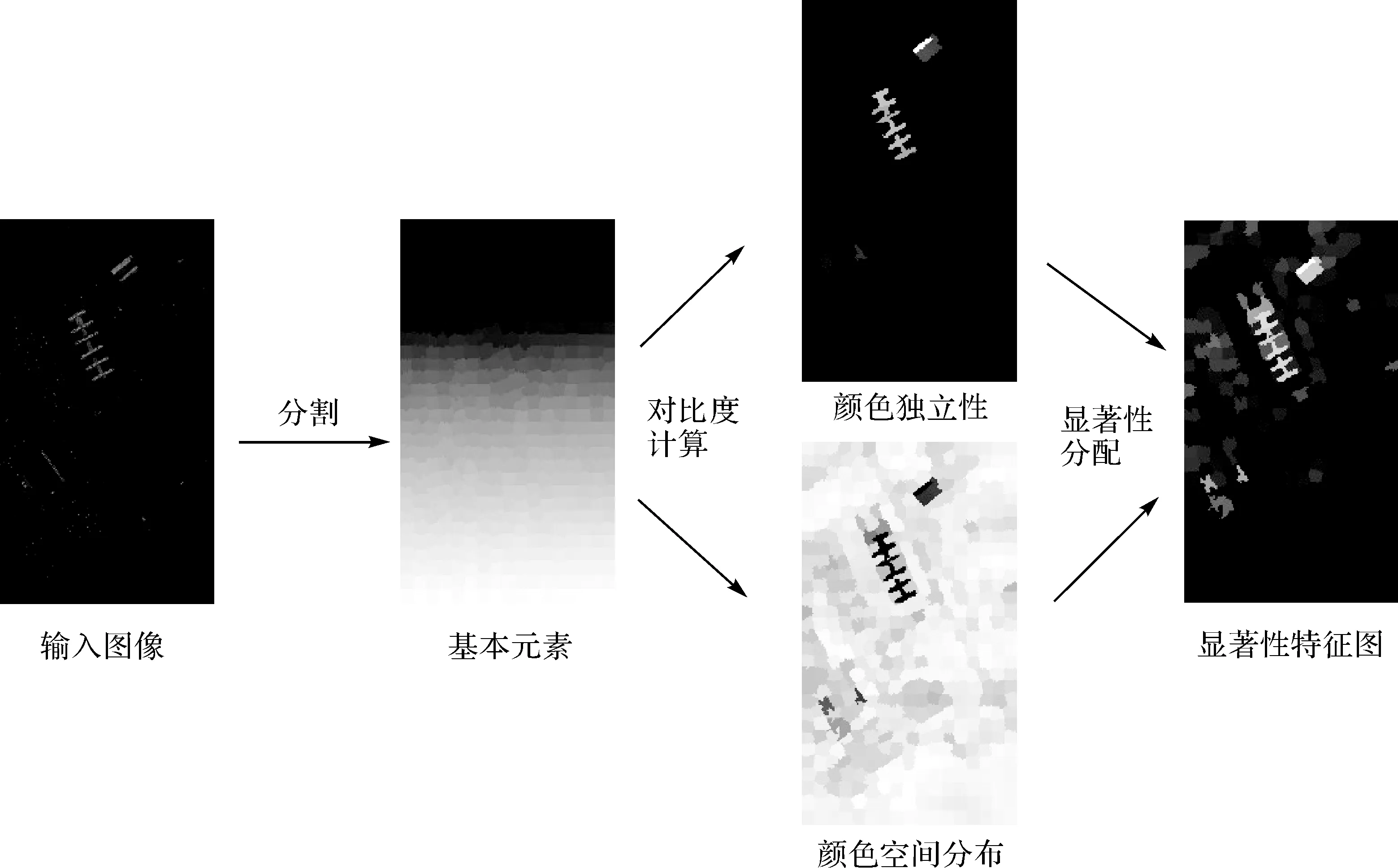
图1 3个波段显著性特征提取流程Fig.1 Salient feature extraction of three adjacent bands
SLIC算法能够有效地将图像分割为若干个超像素块,每个超像素块内部像素属性趋于一致,并由颜色均值表示。这样可以在特征提取的过程中充分考虑像素周围的局部空间信息,同时能够降低噪声对特征提取的影响。
1.2 对比度计算
视觉显著性检测中通常通过计算对比度来进行显著性估计,为了更加充分地利用全局空间信息,以分割后的超像素为基础,定义颜色独立性和空间颜色分布两种对比度。颜色独立性定义如下
(2)

进一步可将式(2)改写为
(3)
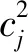
空间颜色分布定义如下
(4)

式(4)可以改写为

(5)
1.3 显著性分配
根据颜色独立性和空间颜色分布计算每个超像素的显著性为
Si=Uiexp(-kDi)
(6)
由式(6)可知空间颜色分布Di越大即颜色分布越广,对应显著性值越小;颜色独立性Ui越大,则对应显著性值越大。最终定义每个像素的显著性如下
(7)

1.4 高光谱影像显著性特征提取与分类
由于高光谱影像具有众多波段,因此需要沿光谱方向依次获取各个波段的显著性特征。最后将各个波段获得的显著性特征图进行堆叠,形成维度为B-2的显著性特征向量,其中B为波段数。为进一步提高分类精度,将每个像素的显著性特征向量和光谱特征向量进行连接形成最终用于分类的特征。
大量的研究已经表明支持向量机是一种快速可靠的分类器,因此本文采用支持向量机作为最终的分类器。其中支持向量机的核函数采用高斯核函数,核函数参数和惩罚系数在2-2,2-1,…,27范围内通过5折交叉验证确定。
2 试验结果与分析
2.1 试验数据
参照文献[26],采用Pavia大学、Indian Pines和Salinas 3组高光谱数据集进行分类试验来验证显著性特征提取方法的有效性。Pavia大学数据集由ROSIS传感器获得,Indian Pines和Salinas数据集由AVIRIS传感器获得。Pavia大学数据集的影像大小为610×340像素,空间分辨率为1.3 m,光谱覆盖范围为430~860 nm,有103个有效波段可用于分类试验。Indian Pines数据集的影像大小为145×145像素,空间分辨率为20 m,光谱覆盖范围为400~2500 nm,有200个有效波段可用于分类。Salinas数据集的影像大小为512×217像素,空间分辨率为3.7 m,光谱覆盖范围为430~860 nm,有204个有效波段可用于分类。3组高光谱影像数据集的地物类别、选取的训练样本数量和测试样本数量分别如表1—表3所示。

表1 Pavia大学数据集样本信息Tab.1 The information of samples on the University of Pavia dataset
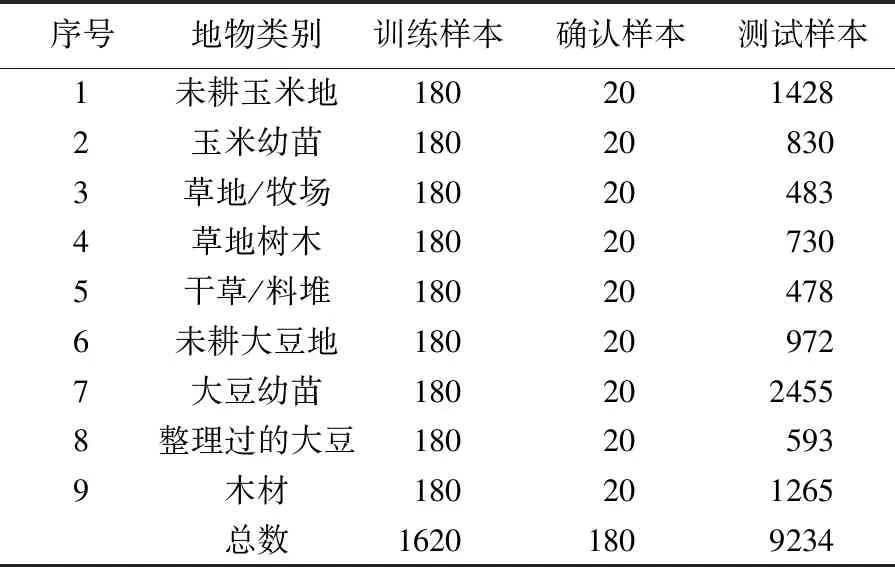
表2 Indian Pines数据集样本信息Tab.2 The information of samples on the Indian Pines dataset
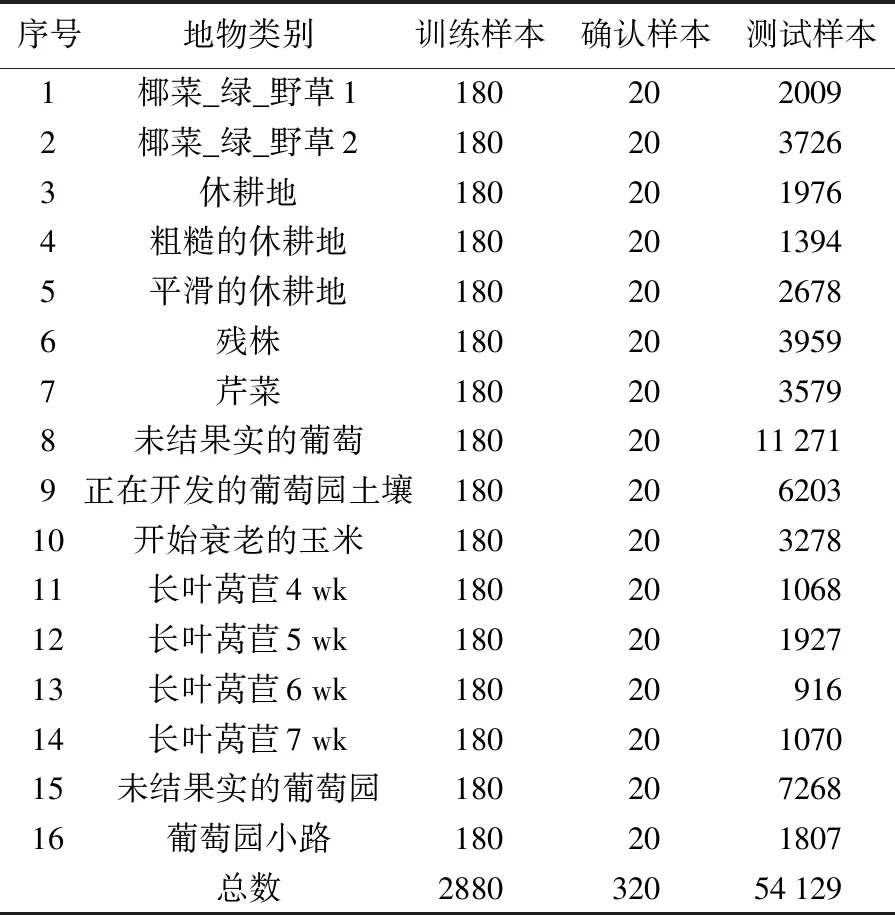
表3 Salinas数据集样本信息Tab.3 The information of samples on the Salinas dataset
2.2 参数设置
本文提出的高光谱影像显著性特征提取涉及的参数主要包括:颜色独立性调节参数σp、空间颜色分布调节参数σc和分割超像素的个数K。本小节以Pavia大学数据集为例分析不同的参数设置对最终分类结果的影响。需要指出的是本小节的分类试验没有结合光谱特征,仅采用了显著性特征。
图2所示为在Pavia大学数据集中设置不同的K值对应的总体分类精度和特征提取所需时间。由图2可知,当K值较少时(例如100、200),分类精度较低;而当K值大于500时,均能够取得较为理想的分类精度;但随着K值的增大,特征提取所需时间也相应增加,而分类精度提升却不明显。在实际应用过程中应该根据高光谱影像大小适当增大K。本文综合考虑分类精度和计算效率统一设置K=500。
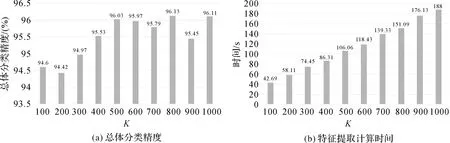
图2 Pavia大学数据集不同的K值对应的总体分类精度和计算时间Fig.2 Overall accuracy and computing time with different number of elements decomposed by SLIC on the University of Pavia dataset
为了分析σc和σp对最终分类精度的影响,分别设置σc和σp为0.25、1、5、10、20。图3所示为在Pavia大学数据集中设置不同的σc和σp值对应的总体分类精度。分析图3可知,当σp值固定时,总体分类精度随着σc的增加而增加,而当σc固定时,总体分类精度大体上随着σp的减小而增加。这说明为了获取更高的分类精度,应该设置较大σc的值和较小σp的值。根据图3,最终设置σc=20、σp=0.25。
通过以上分析,本文提出的高光谱影像显著性特征提取方法对于分割超像素的个数K、颜色独立性调节参数σp、空间颜色分布调节参数σc3个参数较为敏感。实际应用中应该根据高光谱影像的大小适当调节K值的大小,即影像越大,K的值也越大。需要指出的是,过小的K值会导致精度下降,根据本文结果建议设置K≥500较为合理。对于σc和σp,应该设置较大的σc值和较小的σp值。根据本文试验结果设置σc=20、σp=0.25较为合理。
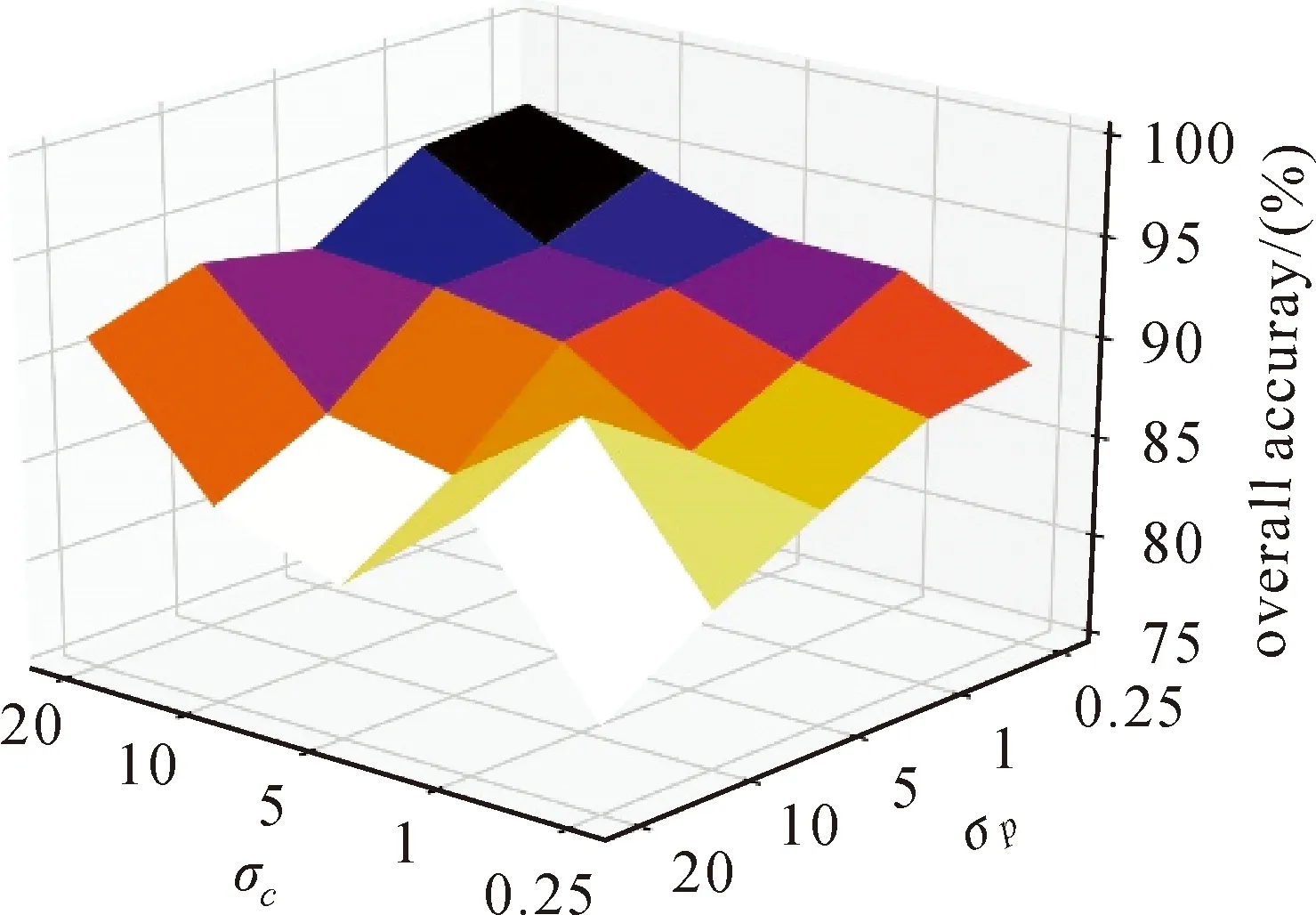
图3 Pavia大学数据集不同的σc和σp值对应的总体分类精度Fig.3 Overall accuracy with different σc and σp on the University of Pavia dataset
表4给出了分别利用颜色独立性和颜色空间分布特征以及综合利用颜色独立性和颜色空间分布特征进行分类的总体分类精度。由表4可知综合利用两种对比度有利于提高分类精度。

表4 Pavia大学数据集中采用不同的特征进行分类的总体分类精度Tab.4 Overall accuracy with different features on the University of Pavia dataset (%)
通常来说对高光谱影像进行特征提取前,可以进行波段随机排序、PCA变换等预处理操作,以期进一步提高分类精度。表5给出了采用不同的波段数量进行超像素分割和采用不同预处理操作,进而提取显著性特征对应的总体分类精度。其中“PCA”表示对高光谱数据进行PCA变换后,再选取相邻波段进行显著性特征提取;“随机排列”表示对高光谱影像不同波段进行随机排列后再选取相邻波段进行显著性特征提取。
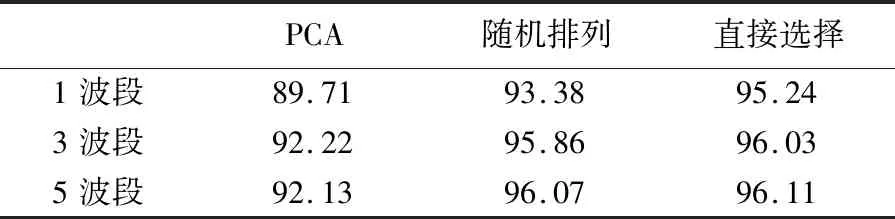
表5 Pavia大学数据集中采用不同的波段数进行特征提取的总体分类精度Tab.5 Overall accuracy of feature extraction using different band numbers in the University of Pavia dataset (%)
观察表5可知采用单波段进行显著性特征提取的分类精度略低于采用3个连续波段进行显著性特征提取的分类精度。这是由于采用单波段进行显著性特征提取仅仅考虑了空间邻域信息,而采用3个连续的波段进行显著性特征提取不仅在特征提取的过程中引入了邻域空间信息,还能够充分考虑相邻波段的影响。进一步采用5个相邻波段进行显著性特征提取对于分类精度的提升效果不明显,且会极大地增加特征提取的时间。此外,事先对高光谱数据进行PCA变换,使各波段相互独立,再进行显著性特征提取,会极大地降低分类精度。而波段随机排列操作对于分类精度的提升并没有帮助。为了简化特征提取过程,本文不对高光谱影像进行随机排序或PCA变换等预处理操作。且最终采用3个连续的波段进行显著性特征提取,即沿着光谱方向采用大小为3、步长为1的滑窗法获得所有波段的显著性特征。
2.3 试验结果与分析
为了验证显著性特征(SF+SVM)的有效性,分别与SVM、EMPs[5]、Gabor[27]、2D-CNN[11]和3D-CNN[26,28]、Gabor+SVM+SLIC[10]算法进行对比分析,并进一步将显著性特征和光谱特征结合输入到SVM中进行分类(Spec-SF+SVM)。SVM采用光谱特征进行分类;EMPs取前3个主成分波段进行特征提取,每个波段分别利用4个开运算和4个闭运算构建形态学属性剖面特征,开闭运算的半径分别为3、5、7、9;Gabor滤波器的带宽设置为1,波长设置为1.4,方向角分别取0°、30°、60°、90°,偏移相位为0,滤波窗口大小为11×11;2D-CNN采用3个卷积层和3个池化层,3个卷积层的卷积核大小分别为5×5、6×6、4×4;3D-CNN采用7个三维卷积层、2个三维池化层和1个全连接层,且引入了两个残差模块,三维卷积层的卷积核大小设置为3×3×3;Gabor+SVM+SLIC中的SLIC分割数设置为500。SVM、EMPs、Gabor、Gabor+SVM+SLIC、SF+SVM和Spec-SF+SVM均采用支持向量机作为分类器,支持向量机核函数采用高斯核函数,核函数参数和惩罚系数通过5折交叉验证确定;2D-CNN和3D-CNN均从训练样本中随机选取10%的样本作为确认样本,并选择在确认样本上分类精度最高的模型进行测试。
表6—表8给出了不同算法在3组高光谱数据集上的分类结果。观察分类结果可知,采用空间特征进行分类的EMPs、Gabor、2D-CNN、3D-CNN和SF+SVM的总体分类精度、平均分类精度、Kappa系数均优于仅利用光谱特征进行分类的SVM,这说明在分类过程中引入空间信息有助于提高高光谱影像分类精度;2D-CNN和3D-CNN由于训练样本数量较少,其分类精度较EMPs和Gabor并无明显优势;Gabor+SVM+SLIC除了使用SVM对Gabor特征进行分类,还利用SLIC超像素分割结果采用多数投票的策略对分类结果进行修正,因此能够获得较其他对比方法更高的分类精度。SF+SVM在Pavia大学数据集上的分类精度高于SVM、EMPs、Gabor和2D-CNN,略低于3D-CNN和Gabor+SVM+SLIC,且在Indian Pines和Salinas数据上均能获得较其他方法更高的分类精度。这说明了本文所提出的显著性特征是一种有效的特征提取方法,能够提高高光谱影像的分类精度,且将显著性特征与光谱特征结合(Spec-SF+SVM)能够进一步提高高光谱影像的分类精度。

表6 不同算法在Pavia大学数据集的分类结果Tab.6 The classification results with different methods on the University of Pavia dataset (%)
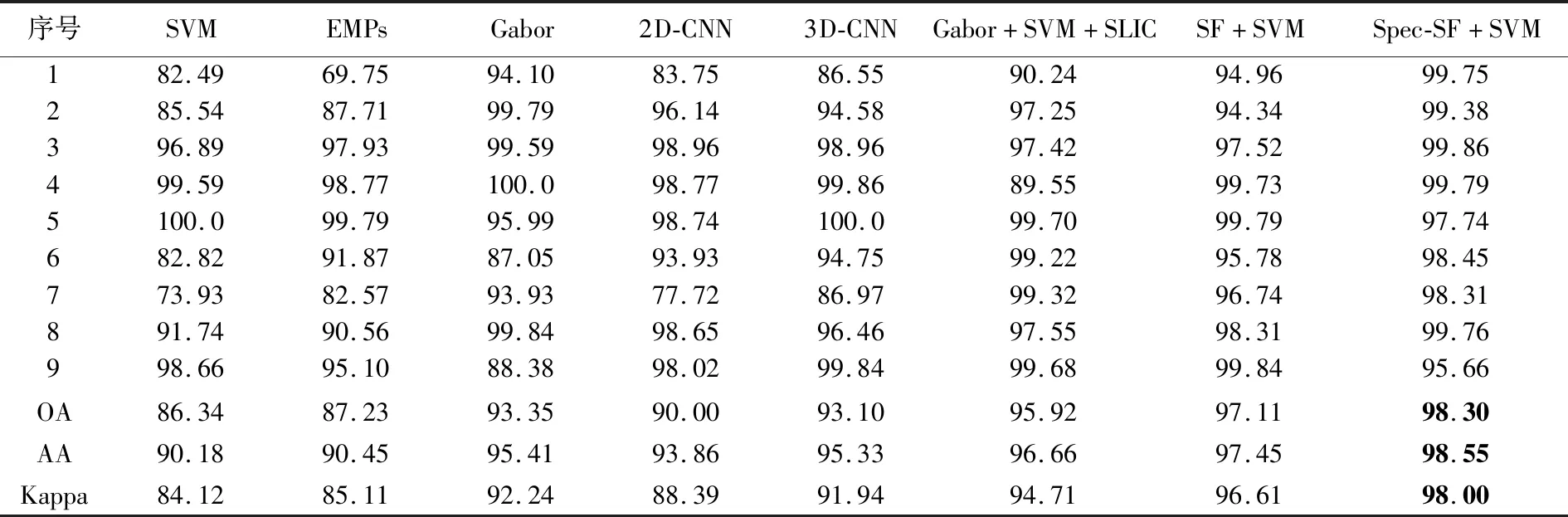
表7 不同算法在Indian Pines数据集的分类结果Tab.7 The classification results with different methods on the Indian Pines dataset (%)
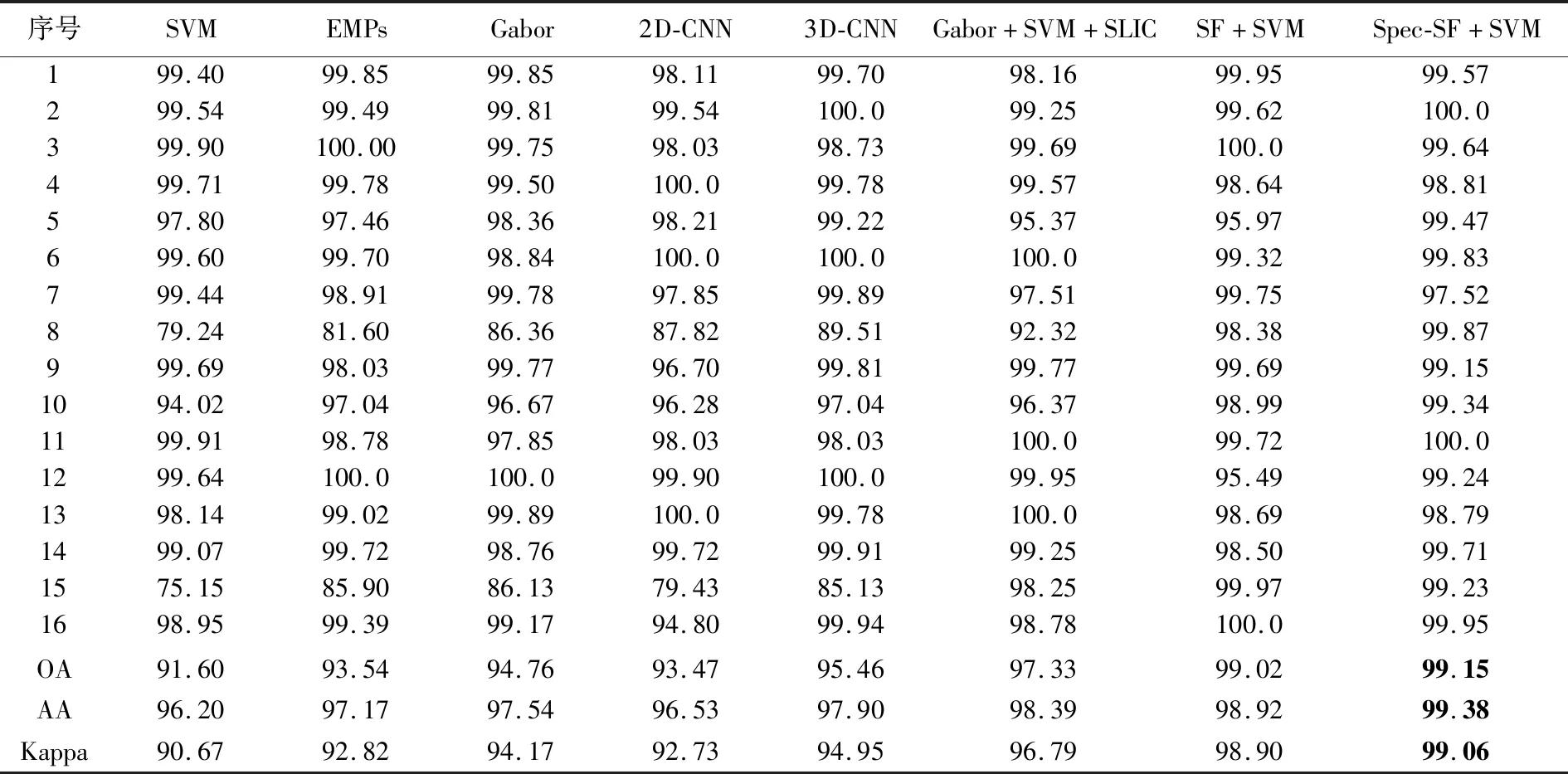
表8 不同算法在Salinas数据集的分类结果Tab.8 The classification results with different methods on the Salinas dataset (%)
为了更好地观察分类结果,图4—图6给出了3组高光谱影像数据采用不同的算法获得的分类图。观察图4—图6可知,SF+SVM和Spec-SF+SVM获得的分类图噪声明显少于其他对比算法,具有更好的视觉效果。这也进一步说明了本文算法的有效性。
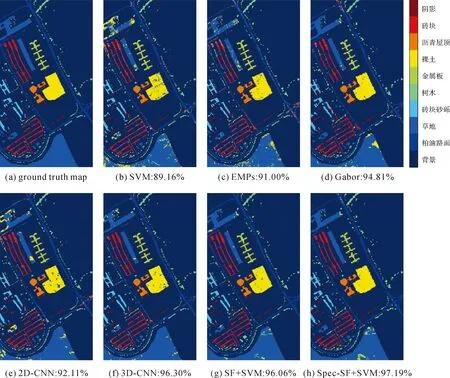
图4 各算法在Pavia大学数据集上的分类结果及其对应的总体分类精度Fig.4 Classification maps and overall accuracy with different methods on the University of Pavia dataset
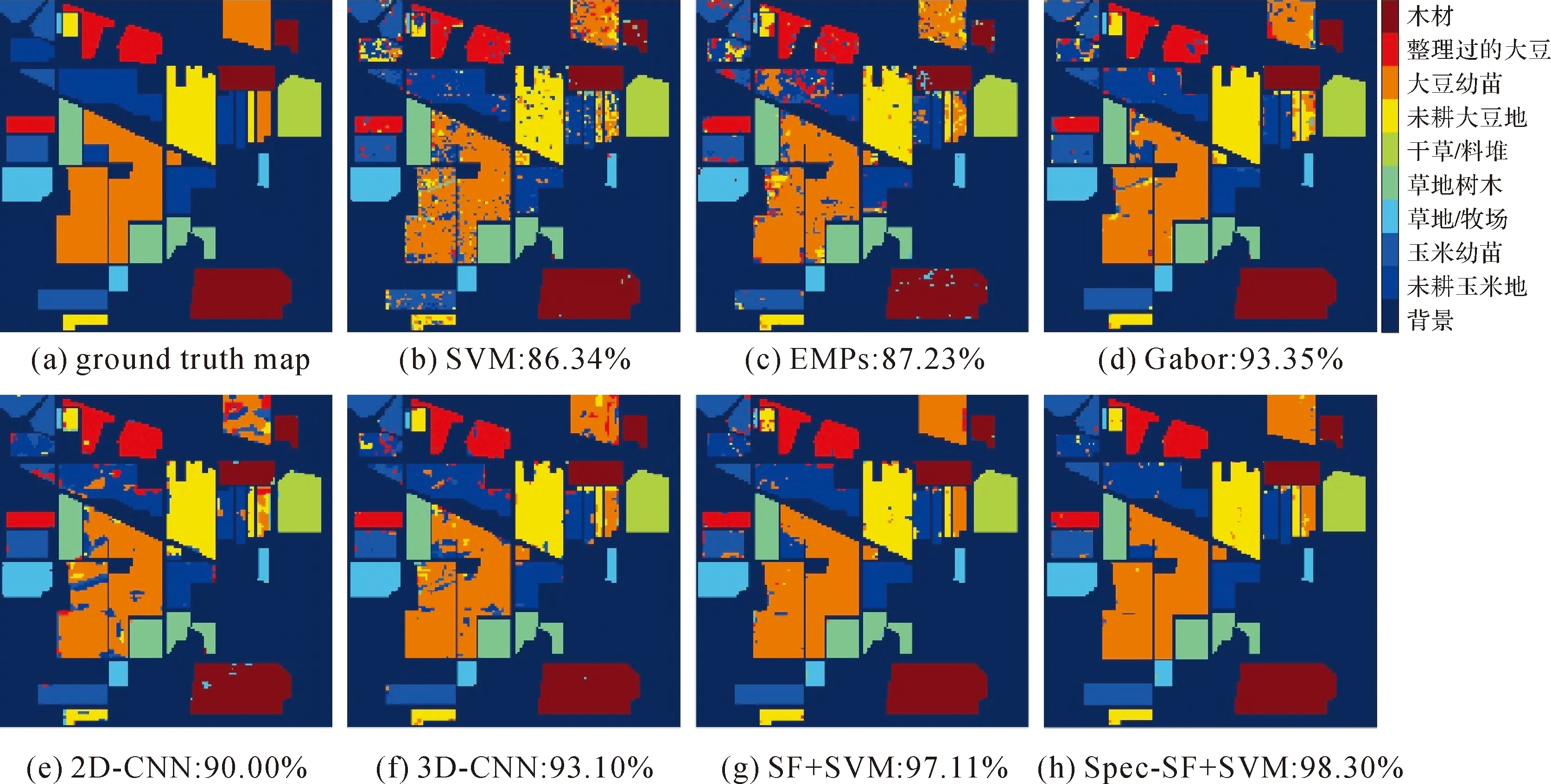
图5 各算法在Indian Pines数据集上的分类结果及其对应的总体分类精度Fig.5 Classification maps and overall accuracy with different methods on the Indian Pines dataset
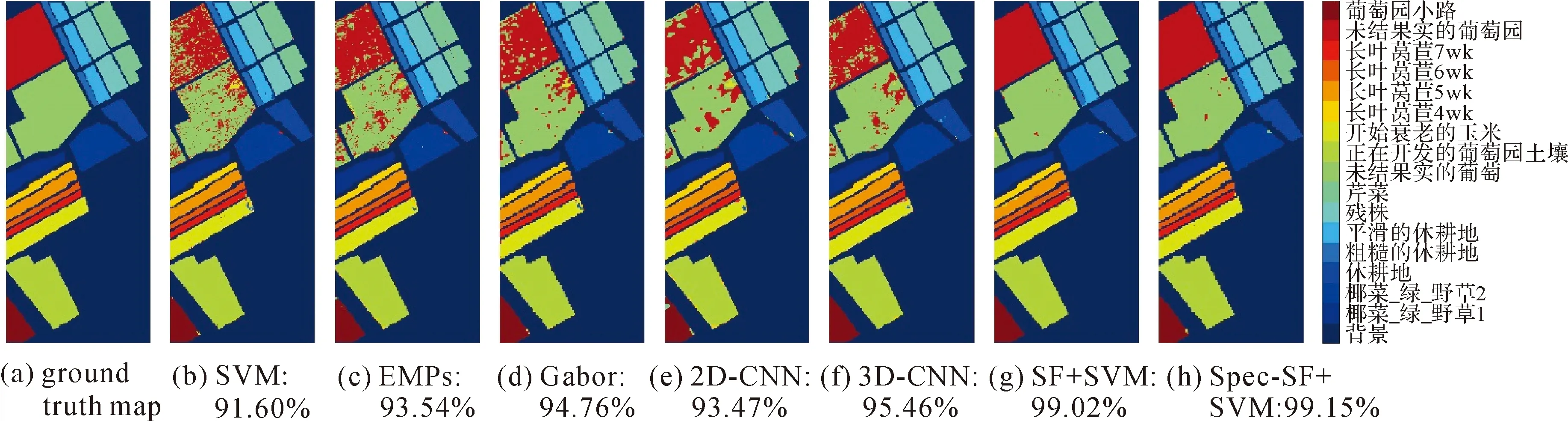
图6 各算法在Salinas数据集上的分类结果图及其对应的总体分类精度Fig.6 Classification maps and overall accuracy with different methods on the Salinas dataset
2.4 训练样本数量适宜性分析
高光谱影像中可用于分类的标记样本数量通常较少,因此小样本问题是高光谱影像分类面临的主要挑战之一。本小节进一步减少训练样本数量进行试验分析,以验证所提出算法在小样本情况下的有效性。如图7所示为3组高光谱数据集中选取不同数量的训练样本对应的分类结果。观察图7可知,不同算法的分类精度均随着训练样本数量的减少而降低,但SF+SVM和Spec-SF+SVM均能取得较SVM、EMPs、Gabor、2D-CNN和3D-CNN更高的分类精度,尤其是当每类地物选取20个训练样本时,SF+SVM和Spec-SF+SVM的分类精度依然高于其他对比算法,这证明了所提出方法在小样本情况下的有效性。

图7 不同训练样本数目对应的总体分类精度Fig.7 Overall accuracy with different number of training samples
3 总结与展望
本文提出了一种高光谱影像显著性特征提取方法,能够充分地利用局部和全局的空间信息来提高高光谱影像分类的精度。采用Pavia大学、Indian Pines和Salinas 3组高光谱影像数据集进行试验验证。试验结果表明:①与EMPs、Gabor、2D-CNN、3D-CNN等空间特征提取方法相比,采用显著性特征进行分类能够获取更高的分类精度,且将显著性特征与光谱特征结合能够进一步提高分类精度;②本文提出的显著性特征提取方法对小样本有较好的适应性,在训练样本较少的情况下,采用显著性特征进行分类仍然能够取得较为理想的分类结果。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
高师理科学刊(2016年8期)2016-06-15 20:27:45
中国光学(2015年5期)2015-12-09 09:00:28
西藏科技(2015年4期)2015-09-26 12:12:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
食品工业科技(2014年23期)2014-03-11 18:18:54
无机化学学报(2014年1期)2014-02-28 17:30:08
