
基于Spark的水泥厂煤耗特性分析与实时诊断
2019-09-03 07:45:10吴敬兵唐汉卿蔡思尧
自动化与仪表 2019年8期
吴敬兵,唐汉卿,蔡思尧
(武汉理工大学 机电学院,武汉 430070)
水泥制造业是中国建材的重要产业,虽然我国水泥生产消费量居世界首位,但在能耗管控方面与世界先进水平相差甚远。我国生产每吨水泥的煤耗比世界先进水平要高出20%,电耗高出23%。为响应我国绿色发展的号召,国内水泥行业需要着重加强能耗管控。当今世界进入了大数据时代,大数据技术在互联网领域得到了广泛的应用,各种传统行业也都在顺应大数据的潮流,应采用相关技术从海量数据中挖掘有价值的信息以改善生产。制造业的数据量虽然不是特别巨大,但数据之间的相关性极为复杂,而且智能制造设备的数据需要实时处理[1],任务极为艰巨。
在此背景下开展了水泥厂大数据应用的研究,搭建了大数据计算平台,建立了煤耗特性的数学模型,对实时采集的水泥厂设备运行数据进行煤耗预测与诊断,得出具备指导意义的分析结果。
1 大数据平台架构
1.1 大数据生态圈介绍
1)Hadoop Hadoop是分布式系统的基础架构,是大数据技术的基础,其核心部分是HDFS和MapReduce。HDFS为分布式文件系统,设计用于部署在低廉的硬件上并提供高吞吐量;MapReduce是一款大批量计算的模型,目前已很少使用。Spark,Flink等新兴的计算引擎速度更快,但它们均基于Hadoop的计算框架。
2)Spark Spark是当前最流行的大数据内存计算框架,可以基于Hadoop上存储的数据进行计算;提供了大量的库,包括 SQL,DataFrames,MLlib,GraphX,Spark Streaming。开发者可以在同一个应用程序中无缝组合使用这些库,以完成复杂的流处理、机器学习算法、数据库存取等功能[2]。
3)HBase HBase是一个分布式的、面向列的开源数据库。它不同于一般的关系数据库,是一个适合于非结构化数据存储的NoSQL数据库。其小批量查询速度快,适合作为查询功能的媒介。
4)Flume Flume是一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统;支持在日志系统中定制各类数据发送方用于收集数据。同时,Flume提供对数据进行简单处理,并写到各种数据接受方的功能。
5)Kafka Kafka是一种高吞吐量的分布式发布订阅消息系统,运行在普通硬件上的Kafka也可以支持每s百万条消息,具备高吞吐量,支持通过Kafka服务器和消费机集群来分区消息,支持Hadoop并行数据加载。
1.2 平台架构
平台采用架构如图1所示。数据处理流程如下:
步骤1采集水泥厂过往稳态运行数据与煤耗数据存储到HBase以及HDFS中。
步骤2使用Spark提取过往数据,调用MLlib机器学习算法库中的算法对数据进行处理以及建立煤耗特性模型。
步骤3采用Flume对接Kafka的方式采集实时数据到Spark Streaming,输入到煤耗特性模型以及诊断模型中计算后将结果写入HBase和MySQL。
步骤4在Web端读取HBase中的结果数据并使用Echarts实现数据的可视化处理。

图1 平台架构Fig.1 Platform architecture
2 煤耗特性建模
2.1 数据计算流程
步骤1采集、清洗数据。采集水泥生产设备的稳态运行数据10000条,并进行数据清洗,剔除错误或异常数据,以防止其带来的模型精度误差[3]。
步骤2特征选择。由于水泥生产设备的运行数据种类繁多,即对于煤耗指标来说特征值过多,严重影响计算速度与模型精度[4]。因此,需要先使用降维算法中的特征选择算法对特征进行筛选,计算出各特征对煤耗变化的权重并按大小排列,剔除对煤耗影响较小的特征。
步骤3计算各特征的基准值。使用聚类算法将筛选出来的特征计算出基准值,为后续煤耗诊断提供参考指标。
步骤4建立煤耗特性模型。将清洗、筛选后的数据分为训练数据和测试数据两部分,使用训练数据建立煤耗特性的数学模型,使用测试数据评定模型的精度并反复调优。
2.2 特征选择
2.2.1 特征选择的意义
水泥生产设备数量多且体积庞大,运行参数繁多,设备内部还布置有很多的传感器监测点。每一种数据都是煤耗的一个特征值,而过多的特征会带来较大的模型精度误差,因此要使用特征选择算法选出对煤耗影响较大的一部分特征。
特征选择的意义如下:①减少所需的存储空间;②加快计算速度;③去除冗余特征,即对煤耗完全没有影响的特征;④提高模型精度,太多的特征或太复杂的模型可能导致过拟合。
2.2.2 Stability selection 稳定性选择算法
将采用Stability selection稳定性选择算法来实现水泥厂高维数据的特征选择。
Stability selection稳定性选择算法是特征选择类型中较为新颖的算法,将2次抽样和选择算法相结合,具有很高的精度。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断地重复,最终汇总特征选择结果,结果用得分的形式来表示各特征的影响系数大小。理想情况下,重要特征的得分会接近1,稍微弱一点的特征得分会是非零数,而最无用的特征得分将会接近于0。
2.2.3 特征选择结果
稳定性选择算法执行的部分结果见表1。特征选择将选取影响得分>0.5的32个特征。

表1 特征对煤耗的影响系数Tab.1 Coefficient of characteristic influencing coal consumption
2.3 基准值计算
2.3.1 K-means||聚类算法
将采用K-means||聚类算法计算各特征的基准值。
K-means是一种被广泛使用的聚类算法,原理简单,计算快并且精度较高,但必须提前确定聚类中心的个数。而煤耗的特征数量是已知的,特征数量即为聚类中心的个数。K-means||是K-means的一种改良版,在并行计算的同时还改变了每次遍历时的取样策略,大大提升了效率。
K-means算法的原理是基于相似度将数据样本划分到距离最近的类中,每个类由其类中心的位置代表,因此算法的本质是将每个数据样本划分到与其相似度最大的类中心所对应的类中[5]。
计算相似度即为计算距离,使用欧式距离进行判定,即

算法的主要步骤如下:
步骤1初始化k个类中心,k即特征数量;
步骤2计算数据样本与各类中心的距离,将数据样本划分到最近的类中;
步骤3更新类中心;
步骤4重复前2个步骤直到满足收敛条件。
2.3.2 聚类结果
聚类仅对特征选择出来的15种特征进行计算,部分结果见表2。

表2 选定特征的基准值Tab.2 Baseline values of selected features
2.4 建立煤耗特性模型
2.4.1 Random Forest随机森林算法
将采用随机森林算法的回归功能建立水泥厂煤耗特性模型。
Random Forest随机森林算法是一种集成算法(Ensemble Learning),具有速度快,模型精确度极高,功能多样等诸多优点。随机森林算法主要用于分类与回归问题,属于Bagging类型,通过组合多个弱分类器,通过投票进行分类,通过取均值进行回归[6],使整体模型的结果具有较高的精确度和泛化性能。随机森林算法原理如图2所示,执行原理及步骤如下:
1)从训练数据中随机抽取部分样本,作为每棵树的根节点样本。
2)在建立决策树时,随机抽取部分候选属性,从中选择最合适的属性作为分裂节点。
3)建立好随机森林后,对于测试样本,进入每一棵决策树进行类型输出或回归输出。若为分类问题,以投票的方式输出最终类别;若为回归问题,每一棵决策树输出的均值作为最终结果。

图2 随机森林原理Fig.2 Principle of random forest
2.4.2 数据预处理
在Spark中,随机森林回归所采用的数据格式为LIBSVM格式,因此在训练模型之前需要先将采集到的数据转换为此格式。LIBSVM的每一条数据类型为LabeledPoint,其格式为
label index1:value1 index2:value2 index3:value3…
其中:label为目标值即煤耗;index为特征索引;value为特征值。
2.4.3 煤耗特性模型
建立回归模型首先将数据分为2份,70%作为训练数据,30%作为测试数据。训练完成后,代入测试数据计算均方误差以评估模型准确度,通过改变参数、对比误差对模型进行调优。随机森林回归算法的部分Scala代码如下:


3 煤耗的实时预测与诊断
3.1 计算规划
煤耗特性建模各步骤均为离线计算,无需部署在服务器端,直接编写代码调用Spark API运行在IDE上即可,只需在计算完成后将基准值存为一个Array[Double]类型的变量,将模型保存在项目resource目录下以便煤耗预测与诊断时进行快速调用。
煤耗预测与诊断需要实时计算,将使用Spark Streaming进行流处理,并且需要将项目打包提交到服务器端运行,以实时的接收数据。
3.2 实时数据的采集
在大数据技术中,采集实时数据常用Fume-Kafka-Spark Streaming的方式,相较于Flume直接对接Spark Streaming的方式,具有数据推送稳定,数据丢失率低的优点[7]。
1)配置 Flume的 conf文件,主要参数设置:sources.command=tail-F 加水泥厂日志文件名称,追踪文件,将新增数据发送给 Kafka,将 sinks.type设置为 org.apache.flume.sink.kafka.KafkaSink,将 sinks.kafka.topic设置为项目名,提交任务后flume就会将数据传输给Kafka。
2)在启动Kafka的consumer时传入 topic名,这样Kafka就会接收到Flume的数据。
3)在Spark提交的项目程序包中使用KafkaUtils.createStream()方法并传入topic名,就可以获取由Kafka推送来的数据。
Flume配置文件部分内容如下:


3.3 煤耗预测
在项目程序中,使用 RandomForestModel.load()方法读取煤耗特性模型,并传入从Kafka接收到的数据,即可实时预测在当前工况下将会产生的煤耗。由于仅得到预测的煤耗值对于水泥厂调整煤耗没有太大的实际意义,因此需要建立诊断模型以计算出具有价值的结果。
3.4 煤耗诊断
采用控制变量法计算每一特征造成的煤耗偏差,以该值与其所占总煤耗偏差的比重来表示该特征实时值的优劣,据此判断该特征对应的运行参数是否需要调整。煤耗诊断结果存储到HBase和MySQL中。煤耗诊断模型为
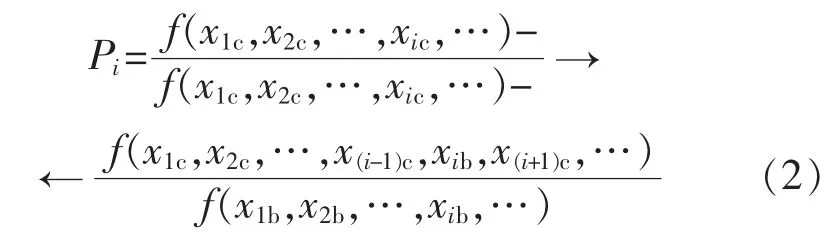
式中:Pi为第i个特征造成的煤耗偏差占总煤耗偏差的比重;f(x)为煤耗特性模型,计算结果为预测煤耗;xc为特征的实时值;xb为特征的基准值。
4 数据可视化
数据可视化能够使复杂的计算结果变得一目了然,大大提升观感和信息理解速度。
使用Echarts提取HBase中的诊断结果来生成图表的方式实现数据可视化,使用ajax实现图表的实时更新,可视化效果如图3所示。
由图可见,分解炉出口温度这一参数的当前数值处于较差的状态,会导致吨熟料煤耗增加3.57 kg,占此时总煤耗增值的23.11%。
5 结语

图3 煤耗实时诊断结果可视化Fig.3 Visualization of real-time diagnosis results of coal consumption
将大数据、数据挖掘技术引入水泥厂的煤耗管控中,为水泥厂搭建大数据计算平台,建立煤耗特性模型,实时采集设备运行参数进行煤耗诊断,判断可能引起较大煤耗偏差的参数,从而为水泥厂调整煤耗提供参考。还研究了煤耗特性模型的建模方法、实时采集数据和实时诊断的方法,为将要应用大数据技术的水泥厂提供一些技术思路和参考。
猜你喜欢
能源工程(2021年2期)2021-07-21 08:39:48
湖南电力(2021年1期)2021-04-13 01:36:28
热力发电(2020年9期)2020-12-05 14:16:08
上海建材(2019年3期)2019-09-18 01:50:50
江西建材(2018年2期)2018-04-14 08:00:06
电子制作(2017年23期)2017-02-02 07:17:06
三峡大学学报(自然科学版)(2016年6期)2016-04-16 05:02:52
西北工业大学学报(2015年4期)2016-01-19 03:31:47
江苏建材(2014年6期)2014-10-27 06:01:37
振动工程学报(2014年4期)2014-03-01 01:15:41
