
基于遮挡系数和区域划分的人群数目估计方法
2019-09-02 09:17韩征彬王宇孟涛涛
长春理工大学学报(自然科学版) 2019年4期
韩征彬,王宇,孟涛涛
(长春理工大学 电子信息工程学院,长春 130022)
近年来,随着经济的发展,城市化进程的加快,大城市的人口密度急剧增加,人群密度过高可能造成群体性的事件,尤其像一些如火车站,地铁站,旅游景点等人群密集区域。因此,对公共区域进行监测和人数估计是十分有必要的。
基于视频图像的人群密度估计目前主要有两个研究方向,主要有基于像素特征统计[1-4]和基于纹理特征[5,6]的人群密度估计算法。基于像素统计的人群密度估计方法速度快,实时性好,可以实时处理视频图像,在人群密度较小时,可以取得较好的效果,但随着密度变大,人群之间出现遮挡,检测误差变大。基于纹理特征的估计算法适合处理人群密度较高场景,但方法速度慢,实时性较差。本文是基于像素特征统计方法的人群数目估计,通过统计人群前景像素数量进行人数估计,但当人群密度过高时,由于遮挡的影响,方法准确性急剧下降。针对遮挡造成的误差,卢晓威[7]提出了一种遮挡系数计算方法,对行人进行边缘检测,设定一条与行人垂直的虚拟线,当出现遮挡情况时,同一虚拟线上的相邻边缘点距离的期望将会缩小,同时,遮挡情况下边缘点的数量也随之变大。结合边缘间隔和边缘点数量计算遮挡系数,此方法容易受到背景边缘的影响,边缘检测需要比较精确,且无法处理上下遮挡的影响。针对此问题,本文提出一种新的遮挡系数的计算方法,根据行人在图像中的高度,行人前景像素的数量等特征来计算遮挡系数,以此来弥补遮挡造成的漏算,同时,本方法结合图像区域划分来消除摄像机透视效应的影响,提高了人群计数的准确度。
1 算法
通过统计前景像素进行人群数目估计,首先提取视频帧的前景图像,根据行人在图像中的高度对图像进行区域划分,分别统计前景图像中每一个连通区域的人数,相加得到最终的人数。
1.1 前景提取
以行人为前景的区域是本文的关注点,视频图像是以静止的相机拍摄的,因此背景是静态的,需要在静止的背景下提取前景,常用的静止背景下的前景目标提取方法主要有静态差分法,混合高斯模型GMM(Gaussian Mixture Model)和基于时空背景随机更新的ViBe(Visual Background Extractor)模型等。
静态差分法需要自主选择一张没有前景的图像作为背景,然后将要测试的图像减去背景图像,就可以得到前景,该方法比较简单,但是背景是固定的,无法更新[8],不适应背景变化的情形。
混合高斯背景模型是由Stauffer等[9]提出的经典的自适应背景建模方法,假设每个像素在时域上符合正态分布,在一定阈值范围内的像素判定为背景,并用来更新模型,不符合该分布的像素即为前景。高斯背景模型通过不断地背景更新来适应环境的变化。可以适用于背景缓慢变换的场景中,但是高斯背景模型对噪声较为敏感,对背景复杂的场景不太适用。
ViBe算法[10]主要特点是随机背景更新策略,由于像素的变化存在不确定性,很难用一个固定的模型来表征,ViBe算法基于这样一个假设:在无法确定像素变化的模型时,随机模型在一定程度上更适合模拟像素变化的不确定性。在模型中,背景模型为每个背景点存储了一个样本集,然后将每一个新的像素值和样本集进行比较来判断是否属于背景点。可以知道如果一个新的观察值属于背景点那么它应该和样本集中的采样值比较接近。该算法性能优于混合高斯背景模型,并且具有很好的抗噪能力。算法主要分为以下部分:
(1)模型的初始化
像素(m,n)表示某帧图像的一个像素点,像素(m,n)的样本集可以表示为S(m,n)={p1,p2,p3,...,pn},每个样本集的大小为n,一般取n=20。模型初始化,就是初始化样本集,一般初始化在视频的第一帧完成。每个像素有n个样本集,初始化样本集的方法不是唯一的,最直观的方法就是根据像素(m,n)和像素(m,n)的领域来初始化,即将(m,n)的像素值和(m,n)的几个领域值随机赋给(m,n)对应的n个样本。
(2)像素的分类过程
初始化结束后需要检测每一帧的前景图像,要根据当前帧的像素值和样本集里的像素值进行比对,得出当前帧的某个像素值是不是前景图像的像素值。具体过程如下:
设当前帧为第k帧,pk(m,n)表示第k帧图像(m,n)位置的像素值。如图1,表示的是(m,n)位置像素集,p1至p4为(m,n)的样本集,坐标轴C为像素灰度值,图1针对的是单通道灰度图像。如果是RGB图像,那么就需要是一个三维立体坐标系,三个轴分别表示R,G和B。选定一个r,在距pk(m,n)值半径r距离范围内的样本值有p2,p3,在半径r范围内的样本值总数计为L,那么下图L=2。依次处理所有像素,就能得出前景图像了。其中min和r值需要预先设定的,本文中给出的值是2和10。

图1 像素分类判别示意图
(3)模型的更新策略
随着环境的变化,例如光照或者背景物体的更新,需要更新背景模型。具体的更新策略:每一帧对当前像素最多只更新一个样本值,更新的概率为1/φ。如果要更新,那么更新的这个样本值随机抽取。同样除了更新当前像素,还有1/φ的更新概率要更新当前像素的邻域值,更新方法跟当前像素相同。简单地说,就是除了更新当前像素的样本值,也要更新邻域的样本值,只是是否更新是有一定概率的。
在选择要替换的样本集中的样本值时候,一般是随机选取一个样本值进行更新,这样可以保证样本值平滑的生命周期。由于是随机的更新,这样一个样本值在时刻t不被更新的概率是(n-1)/n,假设时间是连续的,那么在dt的时间过去后,样本值仍然保留的概率是

这表明样本值在模型中的更新与时间t无关,更新策略是合适的[11]。
图2(a)为原图像,(b)为ViBe前景提取后的前景图像,可以计算每个人平均所占有的前景像素数,前景像素总数除以平均人前景像素数即可得到总人数,但由于透视效应的影响,远离相机的行人所占的前景像素数相对少一些,直接根据正比关系计算出的人数会出现比较大的误差。

图2 原图像和前景检测图像
1.2 区域划分
如果不考虑透视效应,例如文献[4]中局部特征估计算法,未考虑透视效应,没有进行区域划分,整个场景用一个平均行人前景像素数SP,统计前景图像中所有前景像素数,再除以SP即可得到场景中的人数,但因为透视效应,靠近相机的行人前景像素数比较多,远离相机的前景像素数比较少,求得的人数会偏小。

图3 不同位置的行人高度图
针对透视效应的影响,Donatello等人[12]提出一种以行人在图像中的高度作为尺度基准进行区域划分,该方法用在了不同子区域每个行人所占的角点数量不同,本文借鉴了文献[12]的方法,根据行人高度进行区域划分,即跟踪识别一个平均身高的人,统计他在不同位置的图像高度,如图3(a)(b)(c),行坐标位置为158,116和75,高度为32,27和20,通过跟踪统计,在坐标系中描出位置和高度关系如图4所示。
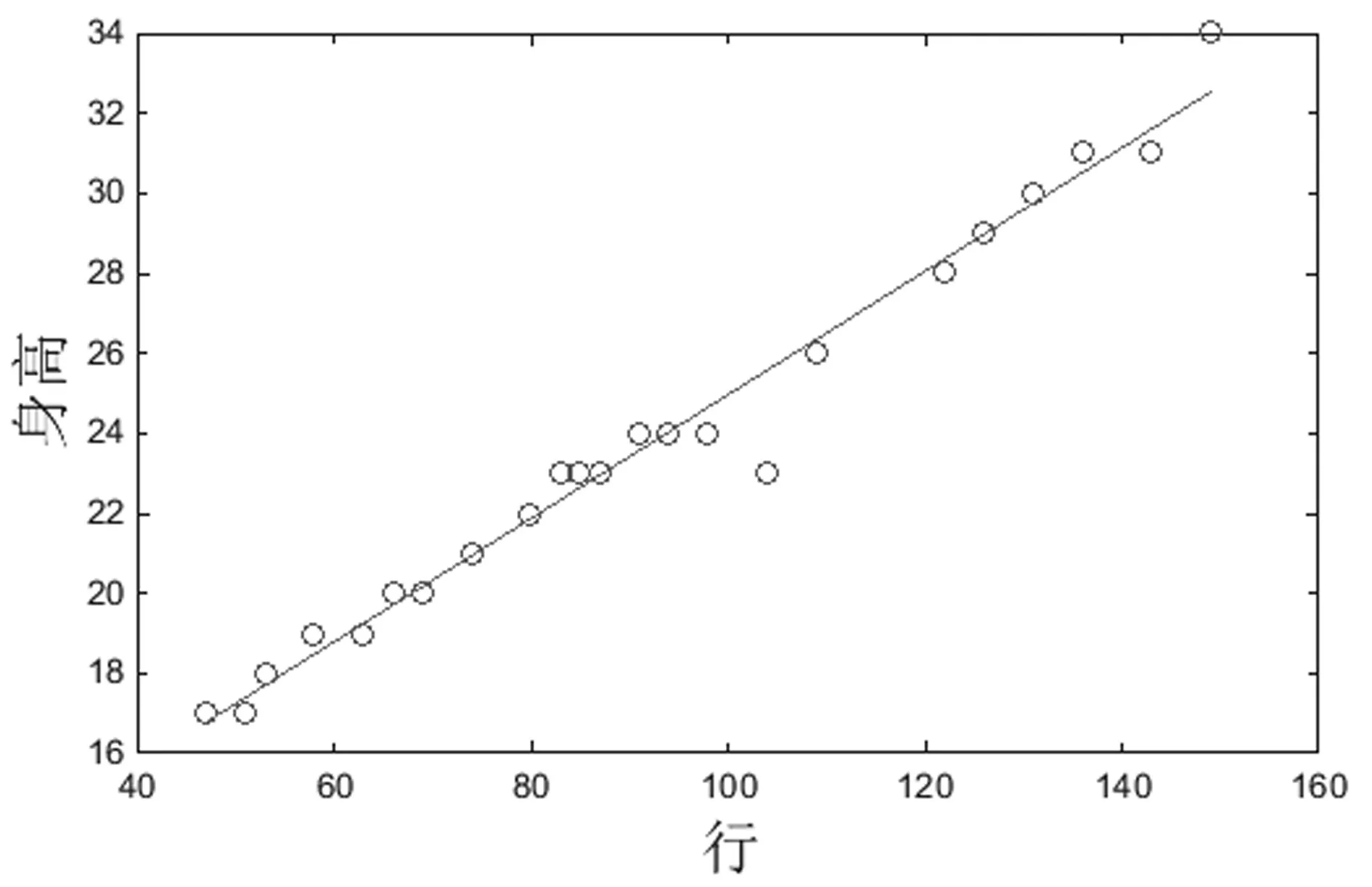
图4 位置和身高关系图
图4中x轴表示行人的所在图像的行坐标row,单位为像素。y轴表示行人高度height,单位为像素,从图4中可以看出位置和身高近似成一个线性关系,通过回归拟合,位置和身高的线性关系为:
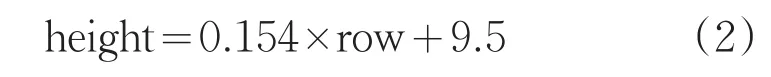
因此按照此公式进行区域划分,首先划分靠近图像底部的区域,在划分上方区域,当宽度小于人的高度时不再划分。如图5,可以看出划分的子区域高度近似人在图像中的高度。在此场景中,按照图像从上到下,子区域编号1-n。

图5 图像区域划分示意图
每一个子区域前景像素数和人数的比例关系不同。统计一个平均身高的人在不同区域的前景像素数SP。统计人数是时,统计每个区域的像素数,再除以SP即可以得到各个区域的人数,相加可以得到总的人数。如公式(3):
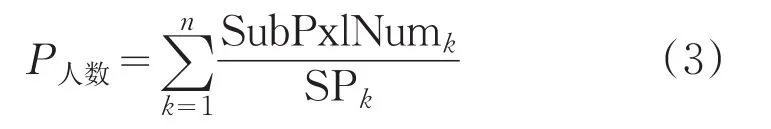
式中,SubPxlNumk表示第k个子区域的前景像素数,SPk表示第k个子区域的平均行人像素数。在行人互相无遮挡的情况下,按照公式(3)可以得出一个比较准确的人数估计,当行人之间互相遮挡时,由于遮挡的影响,按照公式(3)估计得到人数会偏小一些。
1.3 计算遮挡系数
公式(3)按照子区域进行人数统计,无法消除由于遮挡引起的误差。因此,本文在得到前景图像后,依次处理每一个连通区域,如果行人之间互相没有遮挡,可以得到:
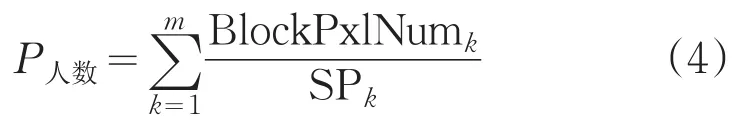
式中BlockPxlNumk表示第k个连通区域前景像素数量,SPk表示连通区域质心所在子区域的平均行人像素数,m表示共有m个连通区域。
如果存在遮挡,可以得知公式(4)得到的人数会偏小一些,因此可以乘以一个比1大的系数,如公式(5):
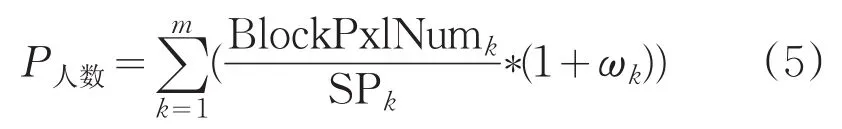
式中ωk为第k个连通区域的遮挡系数,计算过程如下。
一般的监控相机都是斜向下安装的,包括本文用到的视频数据,经过实验观察,在此情形下大部分遮挡为以下形式,示意图为图6,虚线框为前景图像的外接矩形,高宽为BlockHeight和BlockWidth,两个矩形为行人示意,阴影为遮挡部分。图7为行人遮挡原图像和前景图像连通区域图。
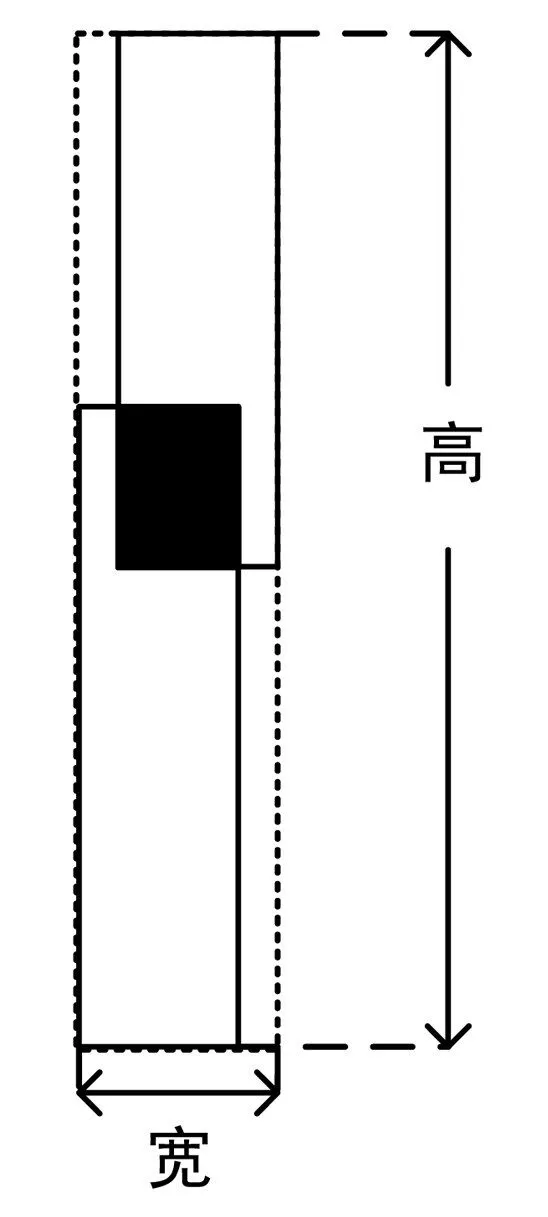
图6 行人遮挡示意图

图7 行人遮挡原图像和前景图像连通区域图
从图6可以看出遮挡部分的高度越大,遮挡的越多,即BlockHeight越小,遮挡的越多,遮挡系数越大。当行人位置在图像靠上位置时,行人高度较低,相同的遮挡高度,遮挡人的面积较大,遮挡系数较大,BlockHeight一般是大于行人高度,且越接近,遮挡越多。在上下遮挡的情况下,当上方行人偏左或者偏右也会影响遮挡部分的大小,针对单独的人群前景区域,前景像素数所占他们外接矩形的比例越大,遮挡系数越大。根据以上分析,本文计算遮挡系数时,综合考虑外接矩形高度、行人高度、前景像素数所占外接矩形的比例三个因素,如公式(6)所示,

式中SubHeight是行人的高度,也是行人所处的子区域高度,C为前景像素所占外接矩形的比例。
当SubHeight固定时,BlockHeight越小,遮挡系数ω越大。当行人位置在图像中靠上时,遮挡高度不变时,SubHeight变小,BlockHeight变小,ω越大。当C越大时,ω越大。分析得知,公式(6)符合遮挡系数与外接矩形高度、行人高度、前景像素数所占外接矩形比例三个要素的变化关系。
2 实验结果和分析
为了验证本文的算法,在UCSD公共人群数据库上进行了测试。UCSD公共数据库是美国加州大学圣地亚哥分校建立的,数据库拍摄了两个不同人行横道。本文验证时采用其中的人行横道1中的数据。
本文测试了5000帧图像,并选取了3个人数区间不同的时间段1,2,3,人数分别在8至16,12至27,16至38之间,如图8(a),(b)和(c)所示。时间段1是第4605帧到4870帧,时间段2是第15帧到第280帧,时间段3是第845帧到第1110帧。

图8 各区间人数示意图
将文献4中未考虑透视效应的局部特征估计算法,考虑透视效应的区域划分算法(公式3)和本文考虑透视效应和遮挡的算法(公式5)进行对比测试,分别对以上的三个时间段进行测试,实验结果如图9所示。
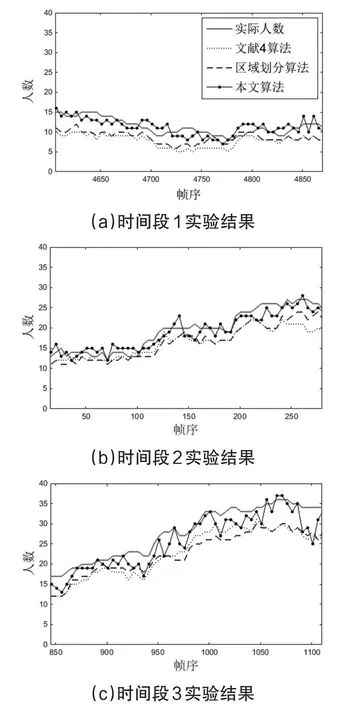
图9 结果对比
由图9可以看出,通过对不同人数区间段做对比测试,划分区域的算法比不分的算法结果要好,本文考虑到遮挡的算法是最接近实际人数的。对三种算法计算标准差(MSE),得到结果如表1所示。

表1 标准差结果比对
由表1可以看出,本文算法计算的MSE在三个时间段上都是最小的,一定程度上减少遮挡的影响,提高了检测的准确率,但随着人数增多,人群密度增大,MSE也逐渐变大,但仍然比其他两种算法准确。
3 结论
本文通过统计人群前景像素数进行人数估计,并且提出了一个新的遮挡系数的计算方法,用于减少行人之间相互遮挡引起的误差。结合了区域划分,根据行人在图像中的高度对图像进行区域划分处理,减少了因为透视效应的影响。对5000帧图像实验结果对比,本文算法提高了人群数目估计的准确性,减少了因为行人遮挡和透视效应引起的误差。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
建材发展导向(2021年6期)2021-06-09
意林(2021年5期)2021-04-18
今日农业(2020年17期)2020-12-15
红领巾·萌芽(2019年8期)2019-08-27
中国外汇(2019年11期)2019-08-27
扬子江(2019年1期)2019-03-08
中国与非洲(法文版)(2017年10期)2017-11-23
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
