
基于云计算的数字图书馆智能问答系统设计
2019-08-30 01:55李金
制造业自动化 2019年8期
李 金
(榆林学院,榆林 719000)
0 引言
随着我国智能技术的不断发展,传统图书馆由于图书众多、占据空间大、查询难度大的缺陷,已经无法适应现今社会的发展趋势。数字图书馆依据需求而产生,其主要是利用数字技术对图书等各种文献进行处理与存储的图书馆,其实质上是一种多媒体制作的分布式信息系统。数字图书馆可以将不同载体、不同位置的信息资源采用数字技术进行存储,以此为基础,便利使用者跨越对象、区域的查询与传播。数字图书馆主要包括信息资源的加工、存储、检索、传输与利用。通俗地说,数字图书馆是虚拟的、无围墙的图书馆,依据网络环境构建的知识网络系统,其具有分布式、大规模、便利性、无时空限制与智能检索的优势,已经被多所大学以及城市所应用。但是如何在数字图书馆有效的提取需求的信息成为现今数字图书馆应用的关键难题,也是目前智能领域重点研究课题之一。
就现有的研究来看,传统的基于搜索引擎的知识获取方式已经无法满足现今人们的需求,传统知识获取方式返回信息过于冗余,用户需要消耗大量的人力与时间在返回信息中寻找自己需求的信息。智能问答系统可以精准的捕捉用户的意图,理解用户的自然语言提问,可以将答案直接返回给用户,人们对智能问答系统的重视与研究也越来越多。数字图书馆传统搜索引擎存在着返回答案速率低、准确性差的缺陷,无法满足现今数字图书馆的需求,为了解决上述问题,引入云计算对数字图书馆智能问答系统进行设计。云计算实质上是分布式计算的一种,其可以在几秒钟内对数以万计的数据进行处理,从而达到强大的网络服务。通过云计算的应用可以极大的提升数字图书馆智能问答系统的性能,同时设计仿真对比实验对设计的数字图书馆智能问答系统性能进行测试与分析。
1 数字图书馆智能问答系统架构设计
为了解决传统搜索引擎存在的难题,对数字图书馆智能问答系统架构进行设计。智能问答系统架构示意图如图1所示。

图1 智能问答系统架构示意图
如图1所示,基础层主要包括的是智能问答系统构建需要的数据,将其以文本形式进行存储;
资源层主要包括问答数据、特征数据、图书资源以及知识库等数据资源;
分析层是智能问答系统的关键部分,主要是通过智能问答引擎、图书库引擎以及检索排序引擎来对智能问答系统进行构建,其中每个部分还包含优化方案;
应用层是对智能问答系统的功能进行实现,包括智能问答、相关问题推荐、图书解释、历史追踪等;
交互层指的是用户进行智能问答的硬件,主要包括Web终端与移动终端。
2 数字图书馆智能问答系统硬件设计
系统硬件设计主要包括Web终端、图书信息采集设备与图书信息转换设备。具体内容如下。
2.1 Web终端
Web终端是用户进行问答的主要设备,是一种在网络环境下的终端设备,与计算机相比较来看,其没有软驱、光驱、硬盘等存储设备,主要通过网络对资源进行获取,软件与数据存储与服务器上。其具有发热量小、无噪音、使用简便的优势,广泛的应用于学校。Web终端示意图如图2所示。
图2 web终端示意图
2.2 图书信息采集设备
数字图书馆主要是对图书馆的图书信息进行采集,将其以数字化形式进行存储。由此可见,图书信息采集设备是其重点设备。该系统主要采用图书采集器对图书信息进行采集,该设备也被称为图书盘点机,主要是通过激光技术对图书信息进行扫描,软件存储与该设备的内部,共同对采集功能进行实现。图书采集器具有体积小、携带方便的优势。图书采集器参数设置如表1所示。

表1 图书采集器参数设置表
2.3 图书信息转换设备
采集的图书信息需要通过转换设备对其形式进行转换,以此来减小存储空间。该系统主要采用转换器对图书信息形式进行转换。
转换器指的是将图书信息进行转换的装置。转换器中关键组件为电路,因此,对转换器进行设计,具体情况如图3所示。

图3 转换器示意图
通过上述过程完成了系统硬件的设计,但是硬件无法实现智能问答,因此,对软件部分进行设计,以辅助硬件实现数字图书馆的智能问答。
3 数字图书馆智能问答系统软件设计
系统软件设计主要包括数据库构建模块、问句预处理模块与检索排序模块。具体内容如下。
3.1 数据库构建模块
采用图书信息采集设备与转换设备对图书信息进行采集与转换,通过网络爬虫技术对数据库进行构建。具体过程如下。
网络爬虫技术是构建数据库的有效技术与工具。爬虫流程主要是根据图书结构,对爬取规则与策略进行设计,其次对脚本程序进行编写,最后对采集内容进行保存。
首先,对问答信息进行采集。主要采用开源爬虫框架Scrapy框架对问答信息进行爬虫采集。Scrapy框架图如图4所示。
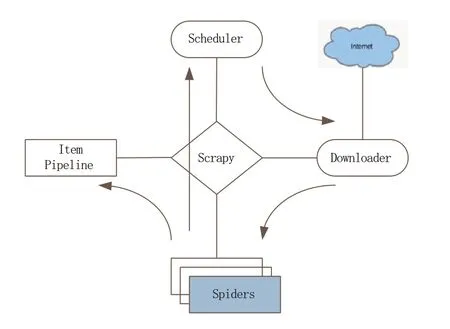
图4 Scrapy框架图
爬虫采集数据内容如表2所示。

表2 爬虫采集数据内容表
其次,对数据库结构进行优化,其优化流程如图5所示。

图5 数据库结构优化流程图
通过上述过程完成了数据库的构建与优化,为下述数据预处理提供支撑。
3.2 问句预处理模块
要想智能问答系统可以精准的对问题进行回答,首要任务就是对问句进行预处理。该系统主要采用问句分类模型对问句进行预处理。具体过程如下。
问句分类模型架构图如图6所示。

图6 问句分类模型架构图
如图6所示,xi表示的是第i个词语的嵌入词向量;hi表示的是第i个词语经过隐藏层之后的输出信息。hi计算公式为:
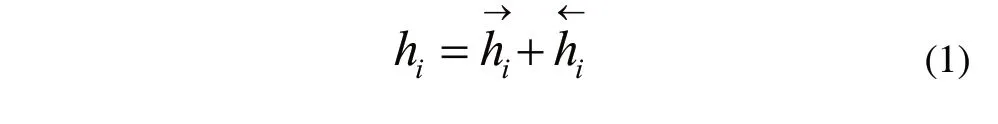
但是问句中词语有轻重之分,因此,需要对词语进行权重分配,则输出结果为:

其中,ti表示的是第i个词语的权重。
将得到的特征向量H~导入分类器中,得到类别结果为:
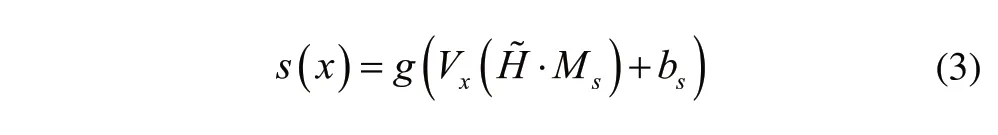
其中,g()表示的是分类器函数;Vx表示的是权值矩阵;.Ms表示的是分类器的dropout处理;bs表示的是分类器的偏置向量。
通过上述过程完成了问句的预处理,为最后的检索排序提供精准支撑。
3.3 检索排序模块
以处理好的问句为基础,通过结构化索引的方式对数字图书馆的数据进行匹配比较,依照匹配打分由高到低输出检索结果列表。检索流程如图7所示。

图7 检索流程图
如图7所示,为了提升智能问答系统的返回答案的准确性,对问句、特征以及类目进行匹配。具体过程 如下。
问句匹配检索。将输入的问句与历史问句进行匹配,对相似度进行计算,计算公式为:
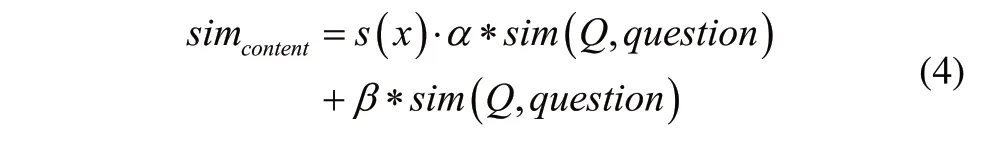
其中,simcontent表示的是问句相似度;α,β表示的是计算参数;Q表示的是用户提出的问句;question表示的是历史问句。
特征匹配检索。当检索出的答案的相似度进行计算,采用simeva进行表示,其采纳规则为:

类目匹配检索。类目匹配检索指的是对问句的类目进行判别。其判别式为:
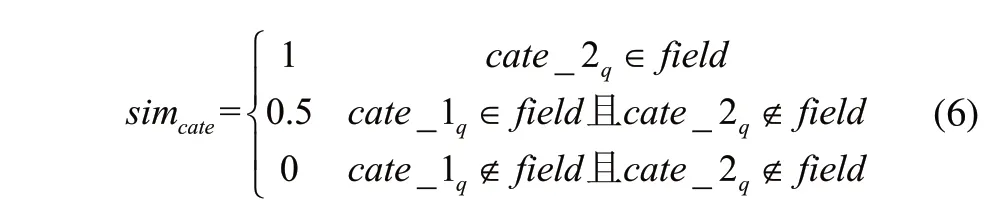
其中,simcate表示的是类目相似度;cate_1q,cate_2q分别表示的是问句分类结果;field表示的是历史问句类目。
通过上述系统硬件与软件的设计,实现了基于云计算的数字图书馆智能问答系统运行,为数字图书馆的应用提供新的技术支撑。
4 系统性能仿真测试
上述过程实现了基于云计算的数字图书馆智能问答系统的设计与运行,但是对其是否能够解决传统搜索引擎存在的问题还无法确定,为此设计仿真对比实验对设计系统的性能进行测试与分析。
在测试过程中,主要采用设计系统与传统搜索引擎进行对比实验,由于问答过程不同,其对问句进行回答的方式也存在着较大的不同,为了保障实验结论的准确性,对实验外部环境参数进行统一设置,通过返回答案速率与准确性对系统性能进行体现。返回答案速率计算公式为:

其中,TP表示的是返回答案正确的数量;t表示的是返回答案单位时间。
返回答案准确性计算公式为:

其中,FN表示的是返回答案错误的数量。
通过上述公式对系统性能指标进行计算与获取,以此为基础,对实验结果进行具体分析。
4.1 返回答案速率对比分析
通过实验得到返回答案速率对比情况如图8所示。

图8 返回答案速率对比情况图
如图8所示,设计系统的返回答案速率远远的高于传统搜索引擎,其最大值可以达到90%。
4.2 返回答案准确性对比分析
通过实验得到返回答案准确性对比情况如表3 所示。
如表3所示,设计系统的返回答案准确性远远的高于传统搜索引擎,其最大值可以达到92%。
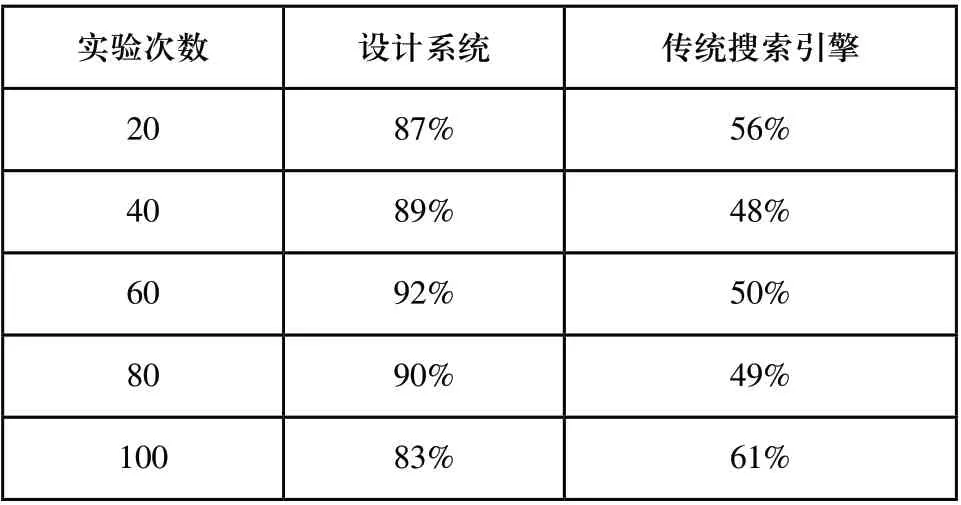
表3 返回答案准确性对比情况表
通过测试结果显示,设计的数字图书馆智能问答系统极大的提升了返回答案速率与准确性,充分说明设计的数字图书馆智能问答系统具备更好的性能。
5 结语
设计的数字图书馆智能问答系统极大的提升了返回答案速率与准确性,为数字图书馆的应用提供新的技术支撑。但是智能问答系统返回答案的准确性与速率依然还存在着较大的上升空间,因此,需要对设计系统进行进一步的研究与优化。
猜你喜欢
南风(2020年22期)2020-09-15
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
小学生优秀作文(低年级)(2019年5期)2019-04-25
小太阳画报(2018年1期)2018-05-14
小学阅读指南·低年级版(2017年12期)2017-12-26
小天使·一年级语数英综合(2014年8期)2014-06-26
