
基于条码识别的标签信息智能检索方法
2019-08-29 02:30景月娟张晓丽
西安工程大学学报 2019年4期
景月娟,张晓丽
(西安航空学院 计算机学院,陕西 西安 710077)
0 引 言
条形码技术是在计算机应用和实践中产生并发展起来的一种广泛应用于商业、邮政、图书管理、仓储、工业生产过程控制、交通等领域的自动识别技术,具有输入速度快、准确度高、成本低、可靠性强等优点,在当今的自动识别技术中占有重要地位。如今条码辨识技术已相当成熟,其读取的错误率约为百万分之一,首读率大于98%,是一种可靠性高、输入快速、准确性高、成本低的资料自动收集技术。传统的信息单机检索模式已经无法适应现如今的网络数据系统[1-2],智能检索方法在检索的性能与检索的能力上虽然得到很大的提升,但依旧无法满足人们对所检索的信息的准确性的需求。在大数据发展的当今世界,应提升数字化信息智能检索技术,充分发挥大数据系统在智能检索方法中的优势,提高信息智能检索的能力和效率[3-4]。
文献[5]提出基于云计算环境下的信息检索及智能融合的方法,通过逻辑结构及加密过程的设计,搭建云计算的电子环境,通过ASP与ADO相结合完成信息检索,改进TF-IDF算法完成信息的智能融合,实现基于云计算环境下的信息检索及智能融合的研究;文献[6]提出一种带约束的语义相似模型和隐性反馈修正机制,探索特定条件下智能信息搜索的实现途径。通过地理环境应用领域的原型实验数据分析,发现基于知识图谱与语义计算的信息搜索准确率可达85%,具有较强的实用性,可为垂直搜索应用领域的技术优化提供参考思路;文献[7]引入文本时间信息的抽取和标注并融合时间信息的检索模型的基础上,以时态语义的技术为整体脉络,从3个方面综述研究信息需求中隐含的时间意图分析,加入时间因素的检索模型构建,实现检索结果的生成;文献[8]以时态语义检索的本源问题和其在学术文献上的相关应用为切入点,提出时态语义检索未来的发展趋势:识别多源异构信息下的时间表达,构建能识别查询的时间预测模型,搭建能精准检索时间意图的检索平台和开发基于深度学习的隐含时间意图自动分类模型;还有部分文献重点介绍了时间温度显示器和RFID技术的研究现状及其应用,并分析在实际应用中所受到的制约因素及可能的解决办法[9-10]。但上述方法均存在检索准确率不高,涵盖范围较小等问题。
为解决上述文献存在的问题,本文提出一种基于条码识别的标签信息智能检索方法,并通过实验验证了所提方法的性能,为进一步研究数据检索提供参考依据。
1 标签信息检索架构设计
利用新型计算机程序,在数量庞大的数据中整合出最具使用价值的信息资源,利用网络系统以及计算机程序,经由一定的处理方式,对标签信息进行检索处理[11]。
搜索引擎也大多是通过对信息关键字及信息主题等较为基础方式进行信息检索,此种信息检索形式较为简单,并且仅对关键词进行搜索,导致检索得到的信息数据量较为庞大繁杂,进而导致检索的结果精确度相对较低[12-14]。
在互联网大数据模式下,信息检索形式发生了变化,标签信息呈现出多样化的趋势,不同结构与形式的信息数据只能通过传统的关系型数据库进行存储,无法达到对标签信息的实际存储需求,因此必须建立云存储系统才可以更好地存储不同种类且数量庞大的标签信息,这就要求数据的检索不能仅靠单一的系统服务器进行处理,而需要利用搜索引擎,与多个存储服务器共同作用完成检索[15]。标签信息检索架构如图1所示。

图 1 标签信息检索架构示意图
2 多源标签信息融合
通常使用的信息检索方法主要为串行检索模式[16-17],此种检索方式可以很好地处理文字数据、普通图片等简单数据信息,进而完成信息检索,但对于音频改造、视频分析等数据信息的处理较为困难。虽然现有信息检索平台较多,但由于各种检索方式与方法的不同,这些平台对于数据信息的检索范围具有一定的局限性,容易出现使用者在对数据检索后得到不同检索结果的情况,对检索的信息难以辨认,无法有效使用。
本文通过构建大数据系统,在海量大数据背景下,对多源标签信息进行融合处理,突破信息源之间存在的界限,使其能够在同一运算方法中使用。即按时序序列,利用计算机技术对获得的多源标签信息进行传输、过滤等处理,并以统一多源标签信息形式与结构为准则,进行标签信息地融合处理。同时,注重标签数据的个性化处理与智能化处理,特别是大数据环境下,改变传统的信息融合模式,将用户作为信息融合的核心,解决其个性化需求,提供智能化的信息融合服务。
3 条码识别的标签信息排序
自动检索技术存在检索得到的关键信息与检索信息结果相关程度符合较低的问题,在标签信息检索过程中,对待处理标签信息进行记录,按照用户的喜好程度有效排列待检索信息,以此来提高信息检索方式的智能化水平。
条码识别利用各种数字图像处理技术,对标签图像中的条码进行特征提取、分析,高效识别图像中的条码内容,根据识别内容检索需要的标签信息。条码是由一组按照一定的编码规则排列的条、空符号,用来表示一定的字符、数字以及符号组成的信息。条码技术是由条码符号设计、制作以及扫描阅读组成的自动识别方法,具有准确度高的特点。本文采用条码识别的方式进行标签信息排序,进而有效检索得到物品信息。
对待检索数据信息进行排序,首先对信息进行相关性分析,按照相关程度大小自动排列。 在大数据系统中,对排序模型进行进一步地分类处理,这是实现快速、准确并可靠采集有效标签信息的重要手段。 由于排序数据呈现出多样化的形式,由此可以在进行信息排序的同时,将所排序的信息结果可视化地表示出来,进而更加客观和全面反映排序信息。
排序模型 (见图2) 在主要的排序中, 以一个独立的四元组的形式存在, 主系统根据排序信息形式的差异, 自主选择排序模型, 并根据排序算法进行排序计算, 信息排序主要对相关度进行高低排序, 要利用排序模型选择一个定值来计算信息的相关程度[18]。
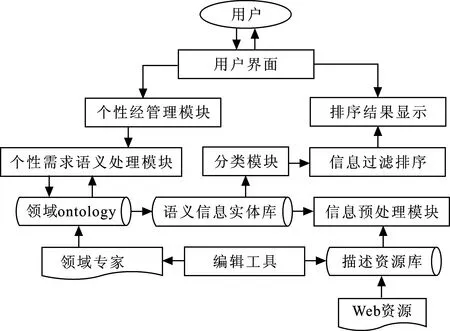
图 2 排序模型示意图Fig.2 Schematic diagram of sorting model
设定待检索的关键信息为A,待检索的主要信息为G,J≥0为A与G的定值,此值作为主要数值提供待检索信息的相关程度。具有关键字的J通常情况下应该是互相单独存在的,待检索的信息文档会被系统自动设置为2个关键句。所以,2个相关程度较高的关键句在同一信息文档中出现的时候,定值会由此显示出两者之间的相关度。利用排序算法计算得到的信息结果更为准确,更加能被用户查询使用。排序算法进行自动排序计算后,将显示结果根据相关程度进行排序,一定程度上提高了信息检索结果的准确性,同时也有利于用户对于标签信息的辨认和使用。
4 实验研究
在利用条码识别获取得到标签信息排序结果后,对标签信息进行智能检索分析,构建智能检索模式图,智能检索模式可以大致分为用户交流层、数据应用与数据处理层、数据处理使用层3个方面。
仅仅在数据查询平台上对数据信息进行检索查询是不够的,还需要使用者在检索过程中联系多种检索词量,对待检索信息进行综合检索,汇集整合所要检索的标签数据信息,对信息的发展动态做出较为准确掌握[19-20]。由于数据信息关键字是数据信息检索的关键,因此要选择准确的信息关键字。信息关键字查询的准确,既可以提高检索的速度,也可以提升信息检索的准确度,更有利于用户检索到所需要的信息。
为了检测本文标签信息智能检索方法的有效性,需要进行实验分析,设置实验环境和参数,与传统检索方法进行比较,设计对比实验。
在大数据互联网形态检索背景下,在数据检索平台进行检索查询,检索数据来源于Mysql数据库信息源,检索算法为排序算法,检索间隔为等分,信息字节为24bit。将本文标签信息智能检索方法与传统标签信息检索方法进行比较,在相同时间内,分别记录本文方法与文献[5]和文献[6]方法得出信息检索准确率,以及检索结果涵盖面范围对比结果。不同方法的信息检索准确率对比结果如图3所示。

图 3 检索结果准确率对比
从图3可知,随着检索时间的增加,3种方法的标签信息检索准确率均不断上升,且在检索时间为30 s时,3种方法的检索准确率均较高,本文方法的准确率约为95%,文献[5]方法的检索准确率约为90%,文献[6]方法约为80%,可见本文方法具有一定的优势。因为本文方法在检索之前,对标签信息进行了排序处理,根据排序结果完成了标签信息的智能化检索,排序处理这一步骤使得本文方法的检索结果更为准确。
对本文方法与文献[5]方法的检索结果涵盖面范围进行对比。依据检索信息量,通过计算期望以及标准差,期望加上或者减去0.43倍的标准差表示的检索结果属于中区间,在中区间的概率为三分之一,中区间两边的为高区间以及低区间。检索结果对比图如图4所示。
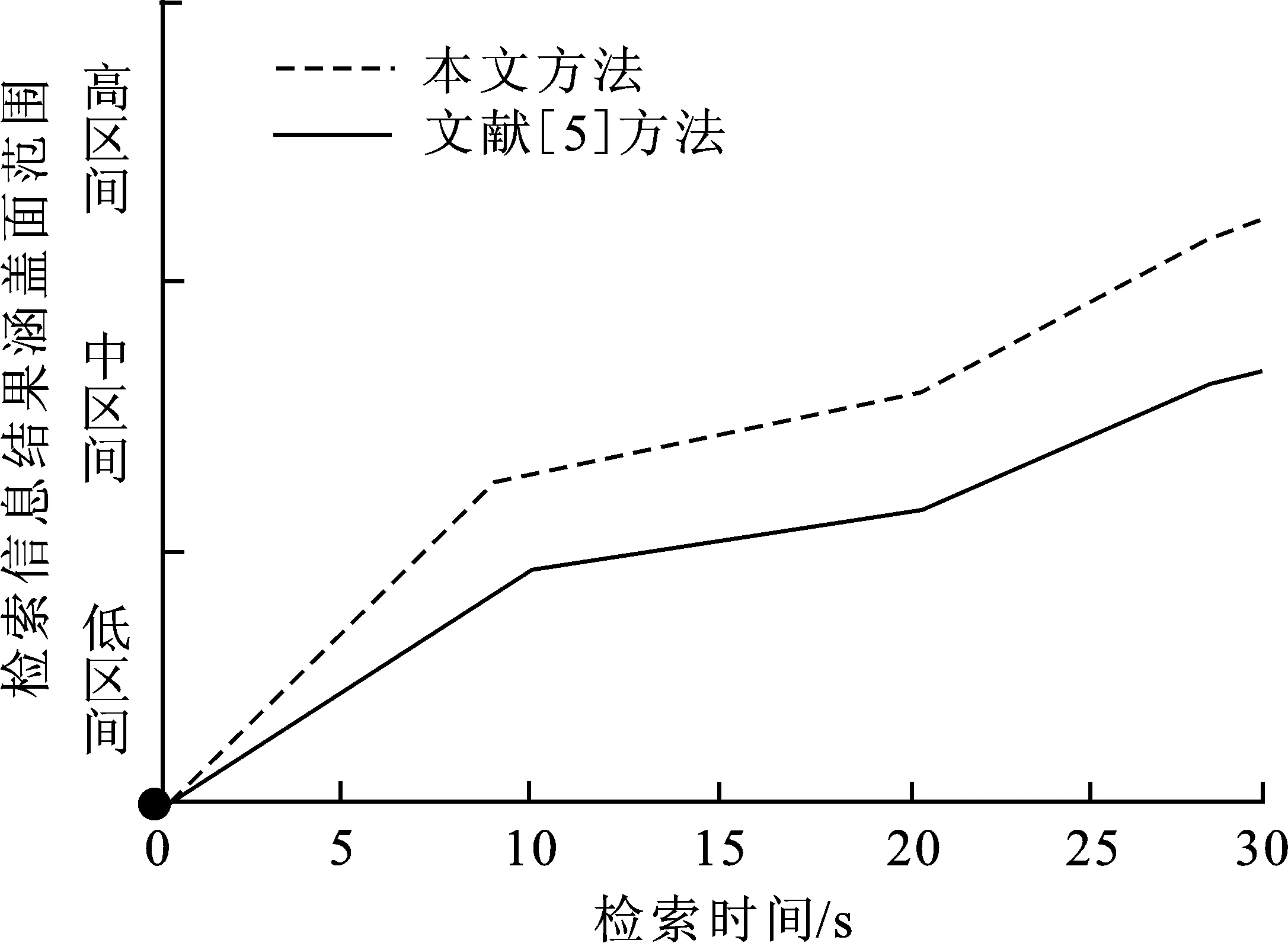
图 4 检索结果涵盖面范围对比Fig.4 Comparison of coverage range of search results
从图4可知,检索信息处于高区间证明检索范围较广泛,检索效果较好。检索时间为10 s时,传统方法检索的信息结果涵盖面范围在低区间,本文方法检索的信息结果涵盖面范围在中区间。检索时间为20 s时,传统方法检索的信息结果涵盖面范围有所提升,但仍在在低区间,本文方法检索的信息结果涵盖面范围在中区间。检索时间为30 s时,传统方法检索的信息结果涵盖面范围在中区间,本文方法检索的信息结果涵盖面范围有所提升,在高区间。
5 结 语
本文在传统检索方法研究的基础上,研究了一种基于条码识别的标签信息智能检索方法,对多源标签信息进行融合处理,突破信息源之间存在的界限,使其能够在同一运算方法中使用。基于条码识别对标签信息进行排序,进而实现标签信息的智能检索。实验结果表明,本文所提方法具有较高地检索准确率,且能够大范围检索得到标签信息。
在后续的研究中需要进一步分析排序后的数据特征,以及其对检索效果的影响,为大数据分析提供可参考依据。
猜你喜欢
条码与信息系统(2021年1期)2021-12-05
名家名作(2021年4期)2021-05-12
科教导刊·电子版(2021年30期)2021-01-03
商品与质量(2020年46期)2020-11-26
条码与信息系统(2020年5期)2020-06-07
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
山西青年(2018年5期)2018-01-25
现代计算机(2016年11期)2016-02-28
印刷技术·数字印艺(2014年7期)2014-08-27
