
铁路大数据平台架构研究
2019-08-28 01:52马小宁
铁路计算机应用 2019年8期
邹 丹,马小宁,王 喆
(中国铁道科学研究院集团有限公司 铁路大数据研究与应用创新中心,北京 100081)
随着信息采集手段的不断发展,不同来源、不同类型的数据呈现指数级的爆发式增长[1]。政府、金融、餐饮、电力等行业都纷纷进入大数据的实用阶段[2]。对于铁路行业来说,各专业都在积极探索大数据应用,例如:客运专业在利用大数据构建客运产品360°立体画像[3]、工务专业搭建了“数字工务”平台提高设备设施维修的管理水平等[4],但是由于各系统分散建设,目前,还缺乏能够跨专业、跨领域的大数据分析。本文旨在设计一种更合理的铁路大数据架构模式,使铁路数据在集中管理后,能够统一存储、综合管理、有效利用,能够使各专业除了分析本专业的数据,还能够叠加利用其它专业数据,从数据层面挖掘潜在的经济效益,更好地发挥数据价值,提升铁路的综合竞争力。
1 铁路大数据平台架构需求
1.1 铁路数据特点
(1)缺乏数据集中管理
在铁路信息化建设逐步发展的过程中,各专业根据自身业务需求建设了大量的信息系统。然而各系统之间多为隔离状态,数据资源分散在各个数据孤岛之中,业务系统间无法进行数据的交互和统一管理[5]。
(2)缺乏企业数据视图
由于铁路数据没有集中管理,所以目前尚未形成统一的企业视图。大数据的价值体现在多系统数据的融合和跨行业数据的联合分析,没有统一的企业视图就很难实现数据的融合与分析。
(3)数据处理技术和架构不能满足需求
大数据由于数据量大、数据类型多,需要新型数据分析技术的支撑,目前铁路还是以传统的关系型数据库处理技术为主,缺乏更高效的数据处理机制和开展大数据应用的数据架构模式[5]。
1.2 铁路大数据平台架构要求
(1)平台架构需要完成数据集成整合的任务,打破各应用系统间的数据壁垒,形成数据资源的全景视图;
(2)平台架构考虑需要满足数据大容量、高可用、高扩展要求;
(3)架构设计满足海量多源复杂数据存储、计算要求;
(4)支持实时分析、动态资源共享。
2 铁路大数据平台架构设计
为了解决铁路大数据目前面临的问题,提出了面向铁路数据的大数据平台架构,目的是为了实现数据集中管理,并用大数据的理念和方法实现数据的高效处理。架构模式分为3层,如图1所示。(1)数据获取层,基于不同的数据源,区别结构化数据和非结构化数据,采用不同的采集方式和采集频度完成数据集中;(2)数据处理层,完成数据的预处理,对采集数据进行清洗、转换、加载,完成数据的颗粒化处理,形成铁路数据分类,实现数据的存储与计算分析[6];(3)数据服务层,以服务或组件等多种方式为应用方提供业务应用、数据分析和商业智能(BI)报表等智能决策支持。
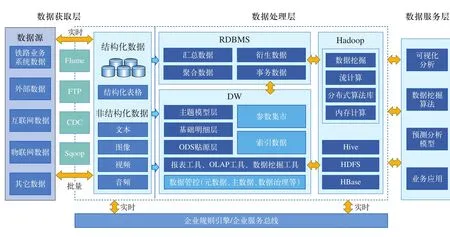
图1 铁路数据架构分层模式
2.1 数据获取层
铁路大数据平台的数据获取层,任务是进行数据采集,完成铁路数据的集中管理[5]。采集过程为:(1)确定与大数据平台对接的数据源;(2)明确数据采用哪种采集技术;(3)根据数据源特点和制定采集方案。
2.1.1 数据源
铁路大数据的数据来源包括路内业务系统数据和来自其他行业的数据、互联网数据、物联网数据和其他数据等。(1)铁路业务系统数据指来自铁路行业的基础数据、战略决策数据、运输生产数据、经营开发数据、资源管理数据等;(2)外部数据指与铁路运输、安全等相关的天气数据、地质数据、灾害预警数据、综合交通类数据等;(3)互联网数据是海量社交网络信息、铁路热点话题、搜索平台相关信息等;(4)物联网数据包括传感器、射频识别(RFID)等设备采集的数据;(5)其他数据指能够参与数据关联分析、参与深度挖掘等大数据分析、计算过程的数据。数据类型既包括结构化的数据库表、数据文件,也包括非结构化的视频、图像、文本等。
2.1.2 数据采集技术
数据源中需要采用不同的数据抽取方式,常用数据采集工具,如表1所示。
(1)对于业务应用系统中的数据,可采用分布式ETL工具将关系型数据库中的数据导入到Hadoop分布式文件系统(HDFS)中,如Sqoop和Kettle等;
(2)对 于 图片、音频、视频和日志等非结构化数据,可通过 FTP、SFTP、Chukwa等方式进行交换处理[7];
(3) 对 于 实时流式类数据,可通过分布式的海量日志系统Flume和高吞吐量的分布式发布订阅消息系统Kafka进行采集、聚合和传输;
(4)对于外部网页数据可以采取网络爬虫方式进行爬取。该方法可按照一定规则,自动地抓取网页非结构化数据,并将其存储为结构化数据文件,同时支持图片、视频等文件的采集并进行自动关联。

表1 数据采集工具
2.1.3 数据采集方案
针对不同数据源以及不同应用的分析要求,需要制定不同的采集方案,其中包括:
(1)采集频次。数据采集方案在采集频次方面采用批量或实时方式。需要根据数据实时性要求、数据所处生命周期的不同进行规划[8]。对于需要提供实时处理的数据和在数据生命周期中处于活跃期的数据,采用实时采集;对于用来支撑未来分析决策和趋势预测的数据、或历史数据等实时性要求不高的数据,可进行批量采集或准实时采集。
(2)采集方式。 采用前置机的方式,可由既有业务系统主动将数据放入前置机,也可以由数据获取层主动发起采集任务;采用数据接口方式,通过双方协定的接口服务进行数据采集;企业服务总线方式,以服务的方式进行实时数据采集。数据采集无论以何种方式进行,采集数据的任务都不能够对既有系统的生产库和系统运行产生影响。
(3)其他。汇集方案中还需要包括汇集的周期、网络通道、主要负责人等,严格按照数据汇集计划执行数据的上传或下载,尤其是实时采集数据,需要通过制度和技术手段保证数据的及时性[9]。
2.2 数据处理层
2.2.1 数据预处理
数据预处理是将数据源的数据进行整合,在这个过程中,需要完成以下几项工作。
(1)数据区分结构化与非结构化,由于结构化数据和非结构化数据处理过程完全不同,所以在数据整合的过程中,首先需要对数据进行归类。
(2)结构化数据进行数据ETL(Extract-Transform-Load,数据抽取(extract)、交互转换(transform)、加载(load)),去掉空数据、重复数据和错误数据,去掉与数据分析、挖掘无关的数据,调整数据格式,对数据进行转换和加载等工作,提高数据的正确和有效性。
(3)非结构化数据进行归类,结构化等工作。
(4)数据分类,从铁路信息化总体规划的角度出发,对铁路数据进行分类,形成铁路统一的数据视图,便于数据的共享与分析应用。
(5)数据建模,将数据进行细粒度划分,减少数据冗余。
2.2.2 数据存储与计算
在铁路大数据平台的架构设计中,数据的存储与计算需要同时具备3种模式,即:基于关系型数据库的数据存储与计算、基于大规模并行处理架构模式的数仓和基于Hadoop的大数据处理架构。
(1)关系型数据库
关系数据库部分,适用于存储实时性要求较高,经常需要进行写入的数据,适用于响应速度快、准确性较高、规模较小的数据。在铁路大数据平台的架构设计中,用来存储实时数据、计算结果数据、衍生数据等,方便服务层随时调用。
(2)基于大规模并行处理架构模式的数据仓库
在大规模并行处理架构模式的数据仓库中,每个节点都有独立的存储系统和内存系统,业务数据根据数据模型和应用特点划分到各个节点上,彼此协同计算,作为整体提供数据库服务。其特点是数据准确性较高,易于扩展,用来存放较大量结构化历史数据。将数据批量导出后执行数据分批计算任务。数据仓库中还包括数据管控模块,提供数据处理过程中的数据质量管理、数据稽查、主数据管理等。
(3) Hadoop架构
Hadoop是一个开源的编程架构,采用分布式存储系统,能够清洗、存储和处理海量数据。在Hadoop架构区域,数据存储在Hive、HDFS或者Hbase中,通过分布式系统在成千上万的节点中读取数据。由于大数据的分析计算非常复杂,因此在Hadoop架构中需要包括数据挖掘的专用工具、算法库和流式计算引擎等,用以支撑大量复杂数据的计算和分析。Hadoop架构易于扩展,具有无限的可伸缩性,适合于用存储数据量增长较快,但准确性要求相对不高的非结构化数据和部分结构化数据。
以上3种模式不存在互相取代的关系,而是彼此互为另外两部分的有益补充和促进,在数据处理层扮演着不同的角色,相互之间存在大量的数据流转。
2.3 数据服务层
数据处理层根据不同的应用场景,将大数据平台的数据处理能力以服务的形式提供给用户,主要包括以下几种服务:
(1)可视化分析。对数据进行智能分析,并将结果以可视化报表的形式展示,以直观的图表形式支持用户决策分析[10]。
(2)数据挖掘算法。大数据分析的核心就是数据挖掘算法,数据服务层为用户提供包括数据多维分析算法、决策树算法和聚类分析算法等算法服务。
(3)预测分析模型。数据服务层将数据挖掘过程中发现的数据特点和规律,形成预测分析模型,支持将用户数据带入模型,对未来结果进行预测分析。
(4)业务应用。各业务系统可利用数据服务层的大数据处理能力进行业务数据的计算和处理,支撑业务系统需要。
3 铁路大数据平台架构功能
(1)数据采集功能。完成数据采集任务,汇集全路各业务系统数据、与数据分析相关的路外数据和其他来源数据,满足各类型数据采集需求。
(2)数据处理功能。通过数据处理工具将采集后的数据进行分类,进行数据的清洗、转换等工作。
(3)数据目录功能。为平台数据建立数据的分级分类目录,形成企业数据视图,集成数据使用的申请、审批和开放权限等功能。
(4)大数据存储与分析功能。主要提供统计分析、数据模型算法、数据挖掘服务和可视化服务等功能。
(5)数据治理。实现对基础数据的管理和数据质量的管控,使平台数据质量不断提高。
4 结束语
本文通过对铁路大数据的研究,设计了一种铁路大数据架构模式,希望能够以更为合理的数据架构进行数据的组织,达到铁路数据集中管理与综合利用的要求。随着大数据技术的不断发展与完善,未来对于铁路数据资产的应用将朝着更加高效、安全、智能的方向发展。通过对铁路数据资产的合理利用,铁路行业将会更高效地管理数据、应用数据、发挥数据应有的价值,进一步提升铁路的核心竞争力,更好地服务于社会。
猜你喜欢
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
中国人民公安大学学报(自然科学版)(2020年1期)2020-05-15
小型微型计算机系统(2019年3期)2019-03-13
计算机与生活(2018年3期)2018-03-12
