
基于LDA模型与语义网络对评论文本挖掘研究*
2019-08-27 10:39王涛,李明
重庆工商大学学报(自然科学版) 2019年4期
王 涛, 李 明
(重庆师范大学 计算机与信息科学学院,重庆 401331)
0 引 言
随着人民生活水平的日益提高,旅游已成为生活的基本需求。人们往往通过互联网完成旅途中的各种自助服务(如预定景点门票、预定住宿等),同时也产生了许多行为数据,住宿时消费者对酒店的评论文本就是其中的一种,评论文本呈多维海量特征,对此类文本进行有效特征分析不仅可以帮助消费者进行决策,还可以帮助商家对服务进行改善。已有部分网站为用户提供酒店预选标签项,如携程旅行、去哪儿网等,用户通过点击预设标签项来选择酒店,此方法所获取酒店的特征具有一定的时限性和局限性,真实的客观评价信息不能从预选标签中反映出来。因此,要想深入了解用户评价倾向,就需要对评价文本进行文本主题挖掘[1-2]和情感分析[3-7]。文本主题挖掘常用的方法是隐含狄利克雷分布模型,徐戈等[1]阐述了主题模型在自然语言中的应用。陈晓美等[2]使用LDA模型结合舆论主题与情感因素对网络舆情观点进行了提取,从海量舆情中揭示用户主要观点。情感分析的主要方法有基于情感词典和基于机器学习的方法,周咏梅等[6]通过获取新闻评论语料在已有基础情感词典上抽取评论情感词集和种子词,使用图排序模型构建新闻领域的情感词典,对评价文本进行情感分析。王新宇[7]通过构建旅游情感词典结合机器学习的方法,分析了旅游网络点评的情感倾向。刘志明等[8]使用支持向量机、贝叶斯分类算法、n元模型对微博情感分类进行了实证研究。巴志超等[9]提出将关键词表示为词向量模型,通过计算关键词的语义相似度构建关键词语义网络。刘敏等[10]使用社交化网络方法与情感分析对在线手机评论文本进行研究。王盈等[11],通过构建社交化网络,对竞赛内容进行了挖掘。
酒店评价文本数量庞大且时常伴随着各种评价噪音,用户很难通过阅读所有评价文本从中筛选特征词来形成有效信息,仅对评论文本的情感分析所得的结果未能更好的挖掘出评论蕴含的深层语义信息。在酒店评论领域,已有部分学者利用内容分析法对酒店评论文本进行研究,但方法对于长时间累积的大数据量不能很好地进行批处理,因此分析的结果未很好地表达用户的真实信息;熊伟等[12]以高档商务酒店的评论文本进行词频统计与情感分析,并结合时间序列对未来发展情况进行预测。吴维芳等[13]利用情感分析法对酒店评论的满意度进行分析;石强强等[14]通过增加情感词典种类来提高系统对网络词汇、表情符号进行分词的准确性,进而利用SVM对酒店客户评论进行情感分析。李胜宇等[15]通过构建酒店评论领域特定情感词典, 结合酒店评论信息的句式、语法特征,补充了酒店情感分析模型。李鸣等[16]对酒店评论进行了细粒度情感分析,以酒店评论的特征属性和情感分类作为研究目的,通过情感词典匹配和Apriori算法,挖掘出在线评论数据用户最关注的酒店特征。以上研究仅从完善酒店领域情感词典或对酒店评论文本进行情感分析,而未进一步深度挖掘评论文本分类后用户评价的主题形成有效的知识信息,如挖掘“房间”、“环境”、“位置”等属性词所对应的情感词,形成有效的文本意见反馈信息,对商家及消费者进行改良与决策。
基于以上分析,提出一种基于LTC-SNM的方法对在线评论文本进行挖掘。研究内容如下:通过网络爬虫获取景点酒店的评价语料,对数据进行预处理并生成Word2vec特征词向量;使用机器学习分类器对预处理后的文本进行情感二分类,通过LDA模型聚类得到主题属性词;通过抽取主题属性词-情感词,运用ROSTCM生成语义网络,使得评论文本更具可解释性。
1 相关理论分析
1.1 Word2vec
向量空间模型[17]和基于统计的方法常用作文本表示与特征提取。使用Word2vec[18]进行关键特征提取,Word2vec其原理是将每一个词映射到一个特定维度的实数空间中,越相似的词在向量空间中越相近,将每个词看作一个随机K维向量通过训练后输出对应每个词的最优向量。不仅能避免使用向量空间模型带来的特征向量“维度灾难”,同时考虑了文本中的同义词问题。Word2vec的两种模型分别为连续词袋模型和连续阶跃文法,连续词袋模型是由给定上下文来预测中心词的后验概率,而连续阶跃文法模型是根据当前中心词wt来预测上下文出现的后验概率,Word2vec其模型如图1所示。

图1 Word2vec的两种模型Fig.1 Two models of Word2vec
两种模型训练过程类似,都运用了人工神经网络,仅介绍CBOW模型的训练过程。其原理是给定上下文信息预测中心词,当己知上下文词c(一般c取2个),则给定词序列wt-2、wt-1、wt+1、wt+2预测wt的后验概率为
p(wt)p(wt|context(wt))p(wt|wt-2,wt-1,wt+1,wt+2)
(1)
由图1可知,由上下文词向量累加器和单层神经网络构成CBOW模型,输入层是词wt的上下文中的c个词向量,而映射层向量是这c个词向量的累加和,作为神经网络的输入。输出层为中心词wt出现的后验概率,作为神经网络的输出。
1.2 LDA模型
LDA是由Bleide等[19]提出的包含文档-主题-词3层贝叶斯文档主题生成模型。Griffiths等[20]在此模型基础上对参数施加先验分布,使之成为完整的概率生成模型。LDA作为一种无监督机器学习方法,用来识别隐藏在文档集或语料库中的主题信息。LDA中的各种符号说明见表1,图2为LDA模型,图2中LDA模型对于整个文档M,假设其中有K个独立的主题,对于每一篇文档m都是由K个主题随机生成,且m对于K个主题呈多项式Dirichlet分布,每个主题K是词语上的多项分布。

表 1 LDA模型中各符号说明

图2 LDA主题模型图形表示Fig.2 Graphic representation of LDA topic model
LDA模型中隐含多个未知变量的复杂性,通常使用估计方法计算,常有变分贝叶斯推理、期望传播算法、吉布斯抽样。采用Gibbs抽样提取,Gibbs抽样为马尔可夫链蒙特卡尔理论算法的一种简单形式,其采样过程推理如下:
由图2 LDA模型可得出所有参数的联合分布概率为

(2)
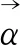

(3)

(4)
(5)
且有

(6)
依据主题参数θ和词参数Φ以及Dirichlet的性质求解分布期望为
(7)
将φk,t和ϑm,k的结果代入式(7)可得:

(8)
式(8)中,右半部分为p(topic|doc)·p(word|topic),上述过程即为Gibbs Sampling推理的整个过程。
2 数据处理与过程分析
2.1 特征提取与情感分类
景点酒店评价文本多为用户对酒店房间、环境、服务、价格、位置等方面作出的主观评价,用户在表达自己的观点其语言多样化,且规范性较差,存在用户评价噪音。将爬取得到的评论文本首先去掉评价中的用户ID、评价时间等信息,保留评价文本并进行数据清洗,删除重复评价和少于4个汉字的评论,使用jieba分词工具在知网基础情感词典上添加自定义情感词典对文本进行分词处理,分词后根据词表进行去停用词。利用同义词字典做归一化处理,降低文本信息的维度。在评论信息中,一般的消极评价为否定形式(如“不是很好”,分词后为不是/很好),这类词严重影响情感判断,因此,本文在自定义情感词典中加入歧义词字典。在处理同义词时,利用基础情感词典中的同义词词典找到情感词的同义词来扩展基础情感词典,此外自定义情感词典中还加入酒店名、景点名。通过构建景点酒店情感词典、网络新词词典、歧义词词典来提高分词的准确性,如表2所示。

表 2 自定义情感词典
最后,对分词后的文档进行Word2vec训练生成特征词向量,利用机器学习中的分类器对评价的情感二分类。特征提取与情感分类过程如图3所示。

图3 特征提取与情感分类Fig.3 Feature extraction and sentiment classification
2.2 主题建模与共现矩阵
评论文本经过情感分类被分为积极、消极文本,依据LDA模型进行文本聚类生成酒店主题词分布概率,选取前N个高频关键词(服务、位置、环境、价格等相关词汇)作为每个景点酒店的评论的主题属性信息,利用文献[21]的方法自动抽取酒店评论文本的属性词与关键词,属性词主要由名词构成,情感词主要由形容词构成,如由高频词“环境”、“房间”和情感词“干净”、“整洁”,形成共现词“环境-干净”、“房间-整洁”,将得到的共现词转换为共现矩阵,使用ROSTCM软件生成语义网络图,其过程如图4所示。

图4 主题聚类与语义网络模型Fig.4 Topic clustering and semantic network model
3 实验结果与分析
3.1 实验数据
通过python网络爬虫技术获取携程旅行、去哪网、大众点评等平台关于重庆市武隆景区、黑山谷景区、桃花园景区多家酒店、客栈、共计5万余条评价文本信息。限于学术研究,为保护商家信息,对酒店的全称部分使用“*”代替。实验筛选武隆景区酒店、客栈各3家,每条评价信息作为一个文本文档。将评论数据按4∶1的比例分成训练集和测试集,人工对训练集的评论文本进行情感正、负打标签。具体数据信息如表3所示。
3.2 情感分类
由于不同的分类器算法在不同的数据集上的分类精度不同,为了确保分类精度的准确率,实验首先使用k-近邻(k-Nearest Neighbor,KNN)、逻辑回归(Logistic Regression,LR )、随机森林(Random Forest,RF)、决策树(Decision Tree,DT)、支持向量机(Support Vector Machine,SVM)、梯度提升决策树(Gradient Boosting Decison Tree,GBDT)多种分类器算法对景点酒店评论数据集进行情感分类,然后选择在酒店评论这一类数据集上泛化能力较好的分类器来作为数据的情感分类器。

表 3 实验数据
(1) 通过计算准确率fPrecision、召回率fRecall和F1值来评价分类模型的准确度。
(9)
(10)
(11)
(2) 使用ROC曲线来衡量分类器,计算曲线围住的面积(AUC)来评价分类器性能优劣。fFpr为假正率,fTpr为真正率,fauc为准确率。
(12)
(13)
(14)
其中,tp表示正类被预测为正类的数据量。fp表示负类预测为正类的数据量,fn表示正类被预测为负类的数据量。tn表示负类被预测成负类的数据,如表4所示:

表 4 分类结果混淆表示
多种分类算法实验结果如图5(a)所示,图5(a)中横坐标0~5表示表3中酒店、客栈的名称,纵坐标为F1的值。图5(b)取GBDT在最佳分类时的ROC曲线。

(a) 几种分类算法比较
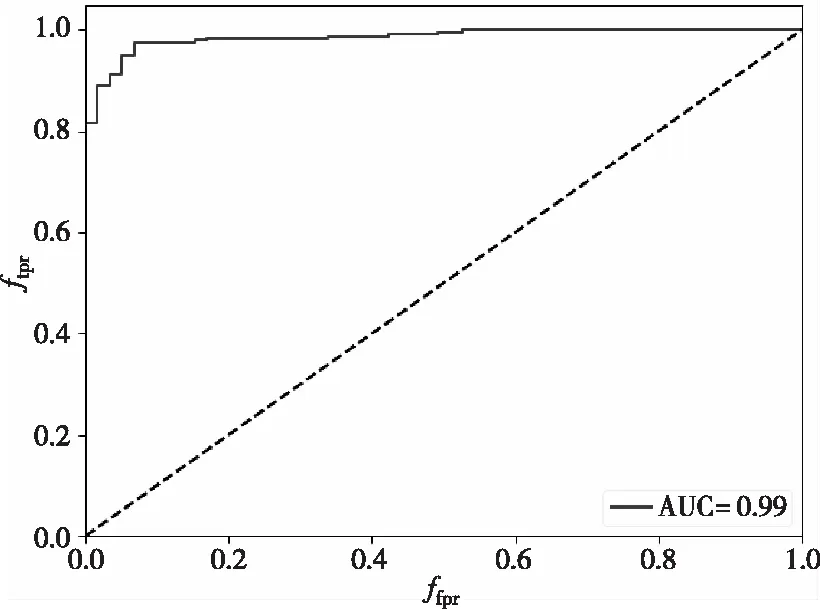
(b) GBDT的ROC曲线
从图5可以看出梯度提升决策树(GBDT)分类算法在这个数据上的泛化能力较好,因此选择GBDT分类算法对酒店评论数据进行情感分类,其准确率、召回率、F1、AUC的值如表5所示。

表 5 GBDT算法分类结果
由表5可知,6家酒店评论数据的平均准确率为86.09%,平均召回率为84.44%,平均F1为92.77%,可以看出分类效果较好。
3.3 主题建模
下面列出对各个酒店分类后为正面评论的数据进行LDA模型聚类,经过多次试验,依据经验值设置LDA模型中参数α=0.14,β=0.01,迭代次数为1 000次。根据得到的p(topic|doc)概率对文本进行聚类。对于k个主题列出了p(word|topic)的概率分布如表6所示。

表 6 LDA-Gibbs模型下的p(word|topic)
从表6可以看出:使用LDA模型进行主题聚类的效果较好。从表5中得知Topic4、Topic5、Topic6是客栈,Topic1、Topic2、Topic3是酒店。通过选取各个酒店的前N个高频词即可看出用户在实际体验中所关注的主要信息。其中Topic6是武隆** 客栈、Topic5中是武隆** 福客栈、Topic4是武隆** 客栈、Topic3是仙女山** 度假酒店、Topic2是仙女山山** 度假酒店、Topic1是武隆** 花园度假酒店。
3.4 语义网络
由于使用语义网络分析时,所产生的节点较多,为使经过LDA主题聚类后的评论关键属性词与情感词通过ROSTCM生成评论文本语义网络图,只选取与主题相关属性词和情感词所构成的前几个节点,选取Topic5中的数据实验所抽取的部分形容酒店的属性词与属性情感词短语如表7所示。其积极评论与消极评论的语义网络如图6所示。

表 7 抽取属性与评论短语实例

(a) 积极评论语义网络

(b) 消极评论语义网络
通过积极评论语义网络可以看出对于语义关键节点,从主题属性词(如:位置、房间、服务)与情感词(满意、干净、热心)可根据语义指向出客栈的交通便利,位置距离火车站汽车站近、老板娘和老板服务态度热情、卫生干净、性价比高,可以向需求为出行便利、性价比高的游客推荐住宿。而消极评论主要集中在客栈房间、硬件设施等方面,商家可依据语义网络所得的结果进行改善,消费者也可快速通过语义网络了解所需信息。
4 结 语
通过获取网络在线评价文本进行数据预处理,在多个分类算法中选择GDBT分类算法对文本情感分类,将主题模型与语义网络相结合,实现了一种基于SN-LTMC评论文本挖掘方法。从海量用户评价文本快速挖掘用户关注的主题属性词与情感词信息,使用语义网络将消费者评论进行语义化表示,不仅方便用户快速浏览,还可以帮助商家实现酒店推荐服务。实验结果表明,方法具有可行性和良好的实用价值,能够推动在线旅游智能电商的发展。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
开放教育研究(2020年2期)2020-03-31
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
