
基于蜕变关系的贝叶斯分类器测试数据集生成器的设计与实现
2019-08-26 01:35贾明华徐月王晓东
数字技术与应用 2019年5期
贾明华 徐月 王晓东

摘要:蜕变测试方法是一种科学有效的软件测试方法,数据集的生成是人们一直以来的研究重点,本文提出了一种基于蜕变关系的贝叶斯分类器测试数据集生成器。该工具首先将数据集作为输入;其次,依次按照不同的蜕变关系对数据集进行蜕变;最后,输出各个衍生的数据集。该工具实现了针对贝叶斯分类器的测试数据集生成器,提高了贝叶斯分类器测试数据的生成效率,并解决了数据集数量少且质量不高问题。
关键词:蜕变关系;贝叶斯分类器;数据集生成器
中图分类号:TP18 文献标识码:A 文章编号:1007-9416(2019)05-0166-02
0 前言
随着智能化软件的普遍应用,机器学习应用程度越来越广。机器学习是人工智能技术的重要研究领域,机器学习算法为模式识别、生物信息学、计算机语言学等许多领域提供了核心功能。构建准确度高的分类、预测或聚类机器学习模型是机器学习研究的核心目标之一。随着机器学习算法应用在金融、自动驾驶、工业控制等领域越来越普遍的应用,基于机器学习的程序模块已成为软件系统的核心组件,这对机器学习程序的安全性和可靠性提出了更高的要求,必须测试和验证基于机器学习的应用程序,以保证其正确性。而贝叶斯分类算法是一类常见的机器学习方法,对贝叶斯分类器的训练测试需要大量的数据集,但是数据集常常数据量少并且不符合程序的要求。
贝叶斯分类算法是统计学的一种分类方法,它是一类利用概率统计知识进行分类的算法。在许多场合,朴素贝叶斯(Nave Bayes,NB)分类算法可以与决策树和神经网络分类算法相媲美,该算法能运用到大型数据库中,而且方法简单、分类准确率高、速度快。首先是贝叶斯网络分类器的学习,即从样本数据中构造分类器,包括结构学习和CPT学习。其次是贝叶斯网络分类器的推理,即计算类结点的条件概率,对分类数据进行分类。[1]其中Naive Bayes、TAN、BAN、GBN就是其中较典型、研究较深入的贝叶斯分类器。随着贝叶斯分类器应用的逐渐增多,对贝叶斯分类器的训练测试需要不断加强,这就需要更加优质的数据集来进行训练测试,目前大部分数据集都存在数据量少,并且不符合程序的要求质量不高的问题。
1 工具简介
针对上述提到的一些问题,本文提出了基于蜕变关系的贝叶斯分类器测试数据集生成器。该工具基于蜕变关系,能够解决数据集数据量少,并且不符合程序的要求质量不高的问题。生成器工具具体包括输入数据集、蜕变操作、输出衍生数据集三大功能。用户通过这个数据集生成器可以将原始数据集输入,点击不同的蜕变关系按钮进行不同的蜕变操作,最后输出对应的衍生数据集。
2 设计流程
该数据集生成器整体分为三个部分,分别是输入数据集、蜕变操作、输出衍生数据集。其中,蜕变操作包括蜕变关系1、蜕变关系2、……、蜕变关系n,设计框架如图1所示。
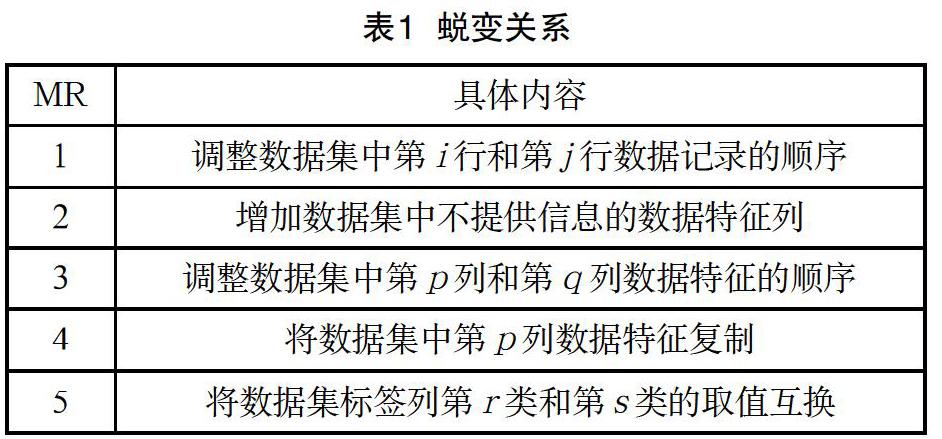
输入数据集是将贝叶斯分类器测试数据集作为文件上传至数据集生成器工具即可。蜕变操作包括5种蜕变关系,如表1所示。[2]点击不同的蜕变操作按钮,进行相应的数据集蜕变操作。MR1是将数据集中第i行和第j行数据记录的顺序进行交换;MR2是在数据集中增加不提供信息的数据特征列;MR3是在将数据集中第p列和第q列数据特征的顺序交换;MR4是将数据集中第p列数据特征复制变成新的一列;MR5是将数据集标签列第r类和第s类的取值互换。输出衍生数据集是将生成的数据集在工具中进行展示。
贝叶斯分类器测试数据集生成器界面设计如图2所示。用户点击上传数据,选择数据集文件即可。选择相应的蜕变关系,点击数据生成,即可完成对应的蜕变关系的数据蜕变操作。在右侧列表展示了每一种蜕变关系对应的操作内容。用户可以点击查看结果弹出衍生数据集所生产的数据文件所在位置弹框。
3 实现方案
3.1 蜕变关系1
MR1是调整数据集中第i行和第j行数据记录的顺序。通过row_content=file.readline()将数据集中的每一行row_content添加一维数组中,再通过二重循环进行交换任意两行数据记录,蜕变后的文件命名为mr1_row_i_j.txt,整个数据集经过蜕变关系1生成的衍生数据集命名为mr1_data,其中包含所有生成的蜕变后的数据集文件。实验采用隐形眼镜数据集[3],它包含了很多患者眼部状况的观察条件以及医生推荐的隐形眼镜类型,隐形眼镜的类型包括硬材质、软材质和不适合佩戴隐形眼镜。[4]针对实验采用的隐形眼镜数据集,由于该数据集共有24行数据记录,因此生成的mr1_data中共有258个衍生数据集。
3.2 蜕变关系2
MR2是增加数据集中不提供信息的数据特征列。通过split方法将数据集进行切分,循环对每个列间的位置添加无关列形成新的蜕变集,蜕变后的文件命名为mr2_col_i.txt,整个数据集经过蜕变关系2生成的衍生数据集命名为mr2_data。对于隐形眼镜数据集,由于该数据集有4列数据特征列,因此生成的mr2_data中共有5n个衍生数据集,n指不提供信息的數据特征列的数量。
3.3 蜕变关系3
MR3是调整数据集中第p列和第q列数据特征的顺序。方法仍然是通过split方法切分数据集,将我们需要调整的顺序定义在顺序数组中,通过循环进行每种顺序的重组,形成新的蜕变集,蜕变后的文件命名为mr3_col_p_q.txt,整个数据集经过蜕变关系3生成的衍生数据集命名为mr3_data。对于隐形眼镜数据集,由于该数据集有4列数据特征列,因此生成的mr3_data中共有6个衍生数据集。
3.4 蜕变关系4
MR4是将数据集中第p列数据特征复制。在切分数据集之后得到本数据集的列数n,通过循环将每一列的信息复制一遍添加到本列之后,得到n个不同的蜕变集,蜕变后的文件命名为mr4_p_n.txt,整个数据集经过蜕变关系4生成的衍生数据集命名为mr4_data。对于隐形眼镜数据集,由于该数据集有4列数据特征列,因此生成的mr4_data中共有20个衍生数据集。
3.5 蜕变关系5
MR5是将数据集标签列第r类和第s类的取值互换。对于数据集中的每条数据都有它自己的标签值,将不同类型的标签进行变换,例如:某数据集中的标签有两种,分别是a和b,那么将a换成b,b换成a,这样蜕变之后的数据集用于测试测试的结果也应该是转换之后的结果,将切分后的数据集中的标签列提取出来,如果符合转换关系,那么对于这一条数据的特征信息不变,标签列转化为相应的结果,在这里需要表格记录蜕变前后的转换关系,蜕变后的文件命名为mr5_r_s.txt,整个数据集经过蜕变关系5生成的衍生数据集命名为mr5_data。对于隐形眼镜数据集,由于该数据集有3种数据标签,因此生成的mr5_data中共有3个衍生数据集。
4 结语
本文通过对基于蜕变关系的贝叶斯分类器测试数据集生成器的研究,实现了一种对贝叶斯分类器测试数据集生成的工具。该工具基于蜕变关系,解决了数据集数据量少,并且不符合程序的要求质量不高的问题。生成的衍生数据集用来对贝叶斯分类器进行训练,还可以对贝叶斯分类器进行更加有效的测试。
参考文献
[1] 李芸.基于贝叶斯信念网络的数据分类挖掘算法[J].计算机科学,2006,33(9):157-158.
[2] Xie X , Ho J W K , Murphy C , et al. Testing and validating machine learning classifiers by metamorphic testing[J]. Journal of Systems and Software,2011,84(4):544-558.
[3] Benoit Julien.: UCI machine learning repository.http://archive.ics.uci.edu/ml/machine-learning-databases/lenses/ (2013).Accessed January,2019.
[4] 李锐,等译.机器学习实战[M].人民邮电出版社,2103.
