
基于机器学习算法的社交数据挖掘与用户偏好的建模
2019-08-23 02:45崔懿心
电子技术与软件工程 2019年14期
文/崔懿心
随着社交网络的蓬勃发展,人们对社交网络的需求已经不仅仅是为了获取资讯,还很大程度上地利用社交网络来表达自我,宣泄情感。就在去年,脸书陷入了私下和广告商交易用户社交数据的丑闻当中,以便广告商通过分析社交数据得出用户的不同偏好,并将广告针对性下放。这说明了社交数据具有巨大的可研究性,如果该特征能够被正当利用,那么我们将可以提取出很多有用的信息。本文将会解决以下三个问题:
(1)利用文本挖掘技术对社交数据进行预处理,并选出最优特征提取模型;
(2)采用积极的机器学习算法、传统邻近分类算法和集成学习算法训练时事类微博二分类模型,对比选出最优模型;
(3)阐述本研究所得的结论,包括最终模型的描述和多种算法间的对比;并讨论时事偏好评估模型在实际生活上的应用
1 文本挖掘技术与机器学习算法
中文分词算法可以分为三种类型:基于字符串匹配的分词方法,基于统计的分词方法以及基于理解的分词方法。基于统计的分词方法,通常会统计相应词串的组合出现的频率,进而评估组合间词串的紧密程度,如果达到一定标准则认为组成了一个词汇。该方法常用的统计模型包括隐马尔科夫模型,最大熵模型以及N-gram模型等等。本文采用的是基于统计的分词方法中的N-gram模型。
本文数据挖掘的研究过程将使用9种机器学习算法,包括朴素贝叶斯算法,逻辑回归算法,支持向量机SVM算法,决策树算法,AdaBoost(自适应增强)算法,随机森林RF算法等等。
2 基于机器学习文本挖掘的时事偏好评估模型
2.1 研究数据
利用网络爬虫获取微博名为头条新闻和新浪娱乐的微博各5000条,对数据进行去异常值和人工标注:定义“头条新闻”所发微博为时事偏好强微博,标注tag=1;“新浪娱乐”发表的微博则为科研偏好弱数据,标注tag=0。最终获取到的数据包括content和tag两个变量,其中content为文本数据,tag为布尔型变量。同时,对content变量进行中文分词后,利用TF-IDF技术进行文本特征提取并对特征进行过滤。
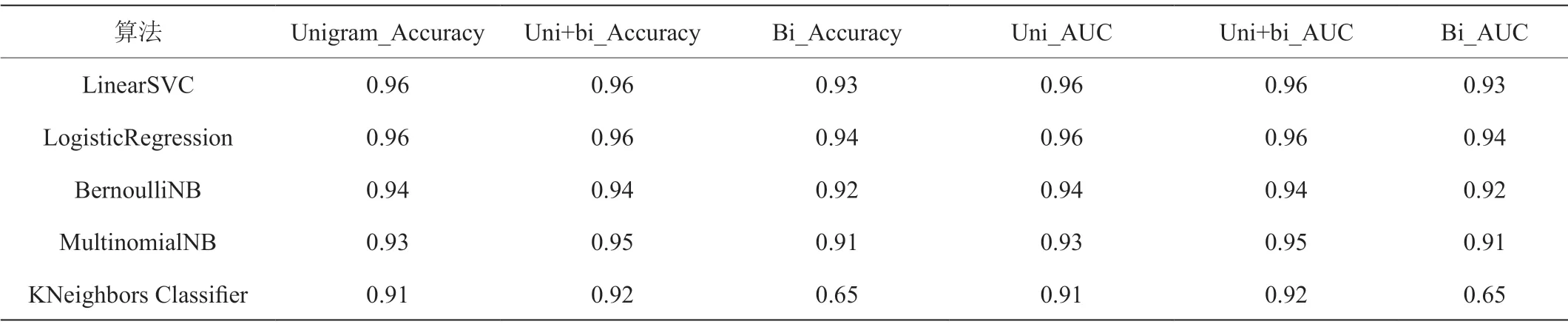
表1:各特征提取算法实验结果
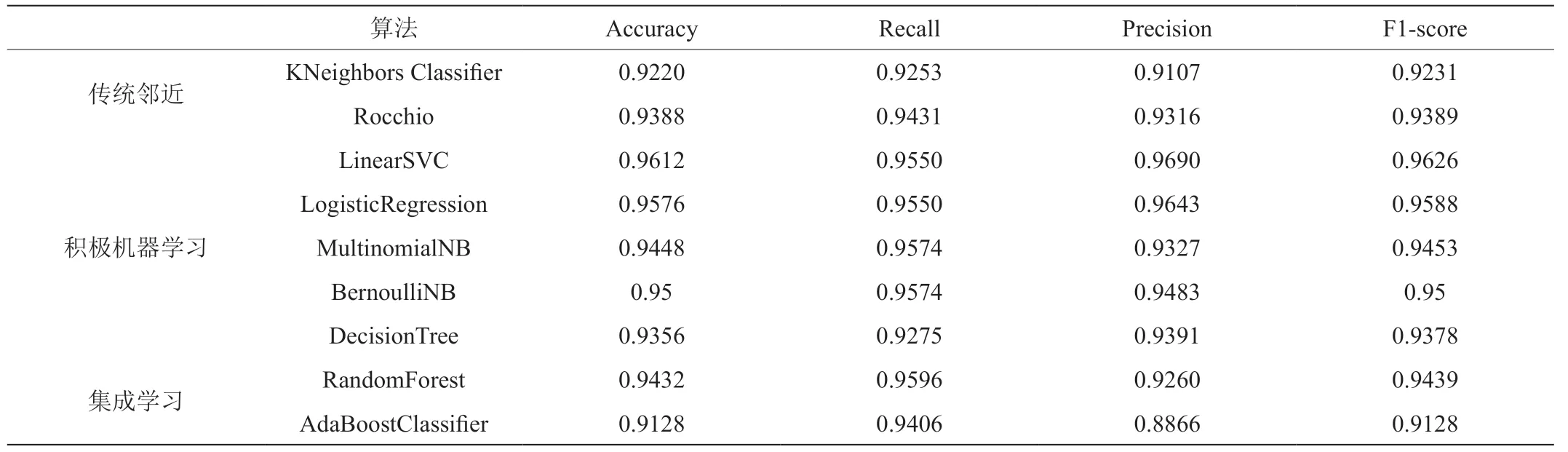
表2:分类算法对比
2.2 文本特征提取模型对比择优
本文采用N-grams算法进行中文分词,通过调参得到三种分词模型:unigram(单词)模型、unigram+bigram(单双词)模型、bigram(双词)模型,经过机器学习算法训练后进行分词模型的对比,结果如表1所示。
由表1可得,在各个积极机器学习算法训练中,单双词模型在准确率和AUC值的指标对比中都要更胜一筹。因此选取单双词模型作为最优分词模型,加入TF-IDF特征提取技术组成最优文本特征提取模型,最终提取出15562个文本特征向量。
2.3 分类算法对比择优
本文共采取九种机器学习算法进行时事类微博分类器的训练,共分成三类分类算法进行对比。基础评价指标对比如表2所示。
Rocchio和KNN属于传统的邻近分类算法,其评价指标普遍比机器学习算法要差。Rocchio算法和KNN邻近算法的准确率均低于其他四个机器学习算法,甚至低于4种机器学习算法的平均准确率95.34%。说明积极机器学习算法优于传统邻近分类算法。积极的机器学习算法之间,线性SVC的准确率,F1分数,AUC值达到了96%以上的。而决策树模型在积极的机器学习算法中属于分类效果最差的模型。
集成学习算法的模型分类效果显示,AdaBoost的各个模型指标都不理想,甚至低于传统邻近算法。而将随机森林算法与强单分类器——线性支持分类机模型对比发现,线性支持分类机算法在各方面都要更胜一筹。
2.4 分类模型改进
对线性支持分类机进行调参,包括惩罚项、惩罚项参数和成本函数类型。最终通过模型评价指标的对比得到,最优分类器为惩罚项为l2范数,成本函数类型为square hinge,惩罚项系数为1的线性SVC模型。因此,在分类结果基础上,得到以“时事类微博/总微博数”为时事偏好评估指标的用户时事偏好评估模型。
3 结语
本文重点研究如何从社交数据提取出用户的时事偏好属性,并将该属性指标用于学生评价体系当中。总结全文得到以下研究成果:以单双词模型为分词模型,结合TF-IDF技术作为最优文本特征提取模型;对比9种机器学习算法,得出最优分类算法为线性支持分类机;最优时事类微博分类器为惩罚项为l2范数,成本函数为square hinge,惩罚项系数为1 的线性SVC模型。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
电子制作(2018年19期)2018-11-14
领导决策信息(2018年24期)2018-09-27
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
时事报告(职教版)(2014年2期)2014-07-28
时事报告(职教版)(2014年1期)2014-07-28
外语学刊(2011年3期)2011-01-22
轴承(2010年2期)2010-07-28
